由浅入深详解NLP中的Adapter技术


-
参数效率更高:一个任务只需要少量参数,训练更快,占用的内存更少,对数据集较小的任务更难过拟合,也更有利于模型的存储和分发。 -
连续学习的遗忘问题:adapter 冻结了原有模型的参数,保证了原来的知识不被遗忘。 多任务学习:使用 adapter 也可以用比较少量的参数学习多个任务,和传统的多任务学习相比,好处是不同任务之间影响较少,坏处是不同任务带来的相互的监督可能会变少。
https://adapterhub.ml/

Bottleneck Adapter
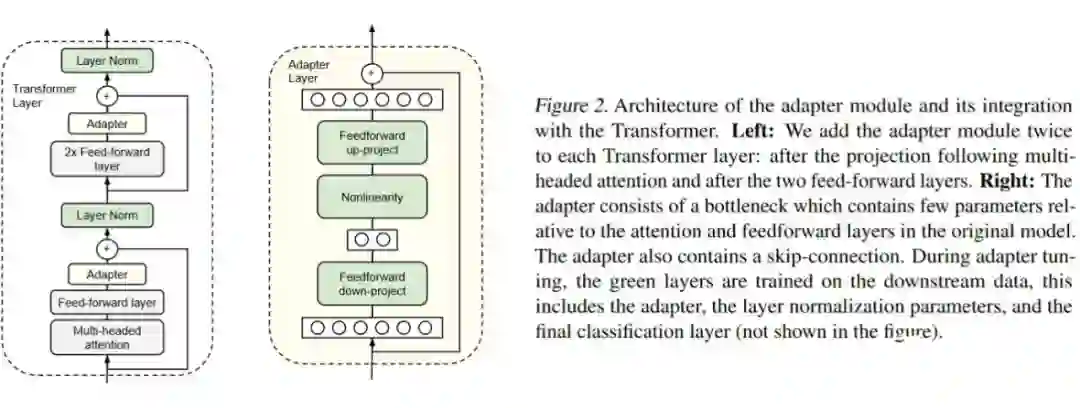
-
只微调 adapter 可以做到比较接近整个模型微调的性能,如果根据每个 task 调 adapter 的大小,可以做到掉点比较少。 -
使用 adapter 的参数效率要高于只微调 BERT 的靠近输出的若干层,性能要高于只训练 layer normalization 的参数。 -
推理阶段,对某层的 adapter 进行剪枝(pruning)是可行的,不会对性能产生太大影响。但是对多层进行剪枝性能会大幅下降。相比靠近输出的层(顶层)来说,靠近输入的层(底层)对剪枝更不敏感。 权重初始化的分布标准差小于 0.01 的时候效果比较好,标准差过大会让效果变差。

对Adapter结构或训练/推理流程的改进
-
AdapterFusion [3] :如何把多任务学习和 adapter 更好地结合起来,利用多任务学习的优势,避免其劣势? -
AdapterDrop [4] :adapter 在推理阶段速度会慢多少?如何对 adapter 进行剪枝? Compacter [5]:能否将 adapter 层做得更加轻量化,同时不降低性能?
3.1 AdapterFusion
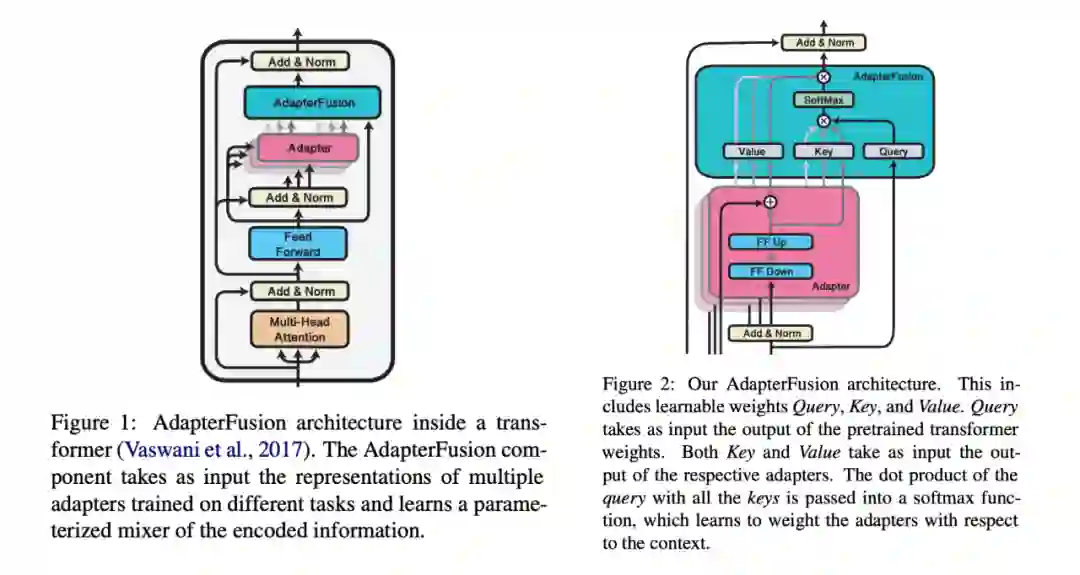
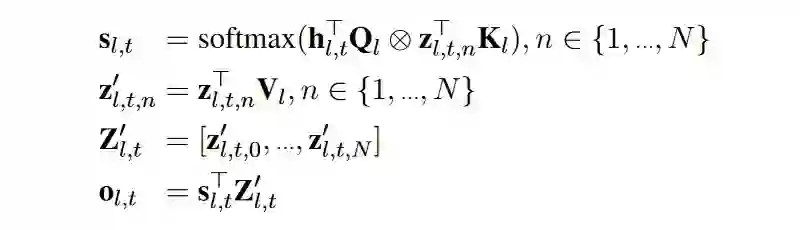
-
第一步:训练每个任务的adapter。作者实验了两种方式:(1)每个任务独立初始化一套 adapter 参数,只学习当前任务,不更新预训练模型的参数(ST-A);(2)把所有的 adapter 组装在一起,用多任务学习的损失函数同时训练所有 adapter,也一起微调所有预训练的参数(MT-A)。 第二步:把第一步的所有 adapter 组装到一起(只针对 ST-A,MT-A 已经组装好),然后加入 AdapterFusion 层,再在目标任务上训练。数据集用第一步中使用过的相同的版本。作者也实验了在第二步使用 MT-A,作为对照。
-
第一阶段训练,使用 ST-A 可以做到和整个模型微调相近或更好的表现,但是使用 MT-A 会一定程度影响性能。作者的解释是只训练 adapter 是一种正则化,可以帮助泛化。 -
第二阶段,加入 AdapterFusion 对训练集比较小的任务提升比较明显。 -
第一阶段使用 ST-A 并且第二阶段使用 AdapterFusion 效果最好,也有利用 adapter 的复用。第一阶段使用 MT-A,在第二阶段也要使用 MT-A 才可以有一定提升。 AdapterFusion 提升比较明显的任务,每一层的 AdapterFusion 层会更倾向于 attend 到其他任务的 adapter。
3.2 AdapterDrop
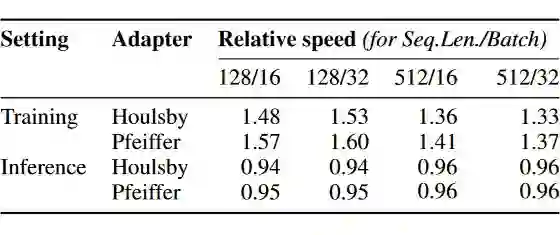
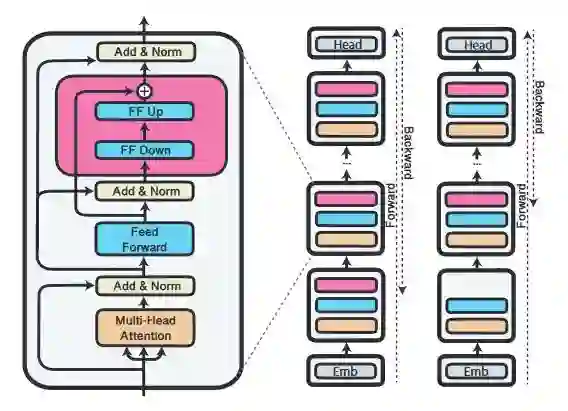
-
去除掉前几个 AF 层,对性能的影响不同的任务有所不同。例如对 RTE 的影响不大,但是 CoLA 十分敏感。这说明直接去除 AF 层并不是一个通用的好方法。 剪掉每层中对输出贡献较小的 adapter。作者用训练集测量了每个 adapter 的平均激活水平(应该是加权之后的输出),每层只保留两个贡献最高的 adapter,模型的性能和原来基本持平,推理速度可以提高 68%。
3.3 Compacter
-
Compact 应用了 Kronecker 积。一个 mxf 的 A 矩阵和一个 pxq 的 B 矩阵的 Kronecker 积是
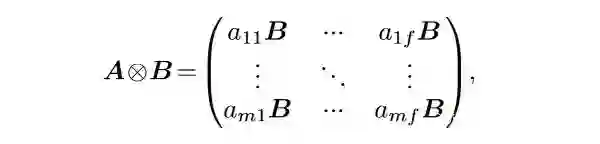
假设模型 hidden state 大小是 k,bottleneck 大小是 b,[1] 中的 adapter 层就包含两个 kxb 的矩阵。Compacter首先借用了 parameterized hypercomplex multiplication layers 的理念,把每个 adapter 的参数表达成一个 nxn 的矩阵 A 和一个 (k/n)x(d/n) 的矩阵 B 的 Kronecker 积,这样参数量就被大大缩减了。
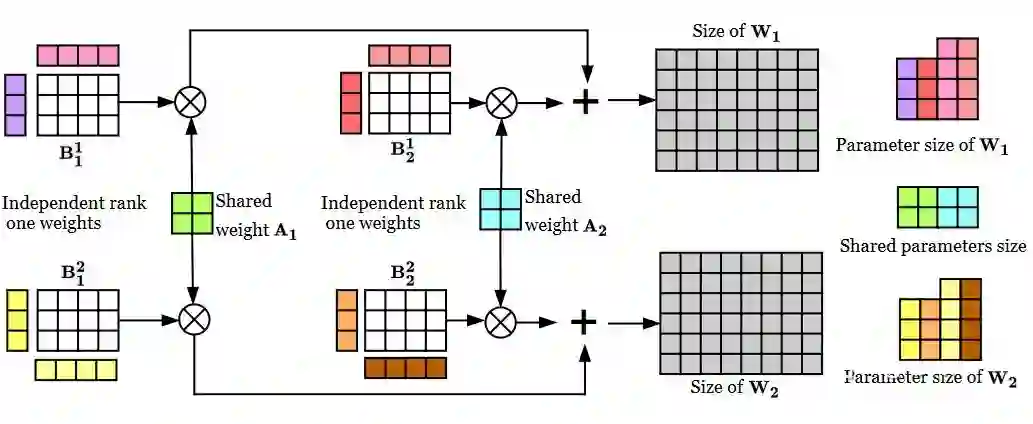
在此之上,要求所有 adapter 共享矩阵 A。
另外,把矩阵 B 再次分解成 n 组两个低秩矩阵的积,两个矩阵的大小分别是 (k/n)xr 和 rx(d/n)。为了减少参数量,作者把 r 固定为 1。
-
Compacter 层结构如下图所示。图中展示了两个 compacter 层,彩色的是需要训练的参数。把 [1] 中的 adapter 层中的参数用这种形式表达就得到了 compacter 的结构。
-
在 T5-base 上,[3] 的adapter层的效果比 [1] 要好。AdapterDrop 或者仅仅对 adapter 层进行低秩分解的性能都比整个模型微调要差。 -
Compacter 的三个创新使得只训练 0.1% 上下的新参数就可以和全模型微调的表现相近。 和全模型微调相比,Compacter 在训练集较小(0.1k-4k)的时候表现要更好。

Adapter的应用和针对应用的改进
4.1 Bapna & Firat(2019)
-
Adapter 结构:本文和 [3] 使用了类似结构(但是本文的工作在 [3] 之前),每个 transformer 层只在最后插入一个 adapter 层。另外,作者重新初始化了 layer norm 的参数(和 [1] 不同, [1] 是直接用预训练的 layer norm 参数继续训练)。 -
域适应:作者在 WMT En-Fr 上训练,然后冻结参数,插入 adapter,分别迁移到 IWSLT'15 和 JRC。模型性能好于 LHUC [7] ,和全模型微调比较接近。 多语种 NMT:作者首先训练了一个英语 <=>102 种其他语言的模型,然后冻结参数,再针对每组(源语言,目标语言)的组合分别插入一个 adapter 进行微调。主要比较的基线方法是只用(源语言,目标语言)的数据训练的模型。结果显示英语是源语言时,大部分目标语言的表现相比基线都持平或有所提升;但是英语是目标语言时,主要在训练数据较少的语言上有较大提升,在训练数据比较多的语言上效果有所下降。
4.2 K-Adapter
模型结构:K-Adapter 不再改动原有的 transformer 层,而是变成在两个 transformer 层之间插入 adapter 层。每个 adapter 层内,在向下和向上 project 的全连接层之间加入了两层 transformer 层(下图左),增加了模块的表达能力。每个 adapter 层的输入可以看到上一个 adapter 和邻近的上一个 transformer 层的输出(下图右)。
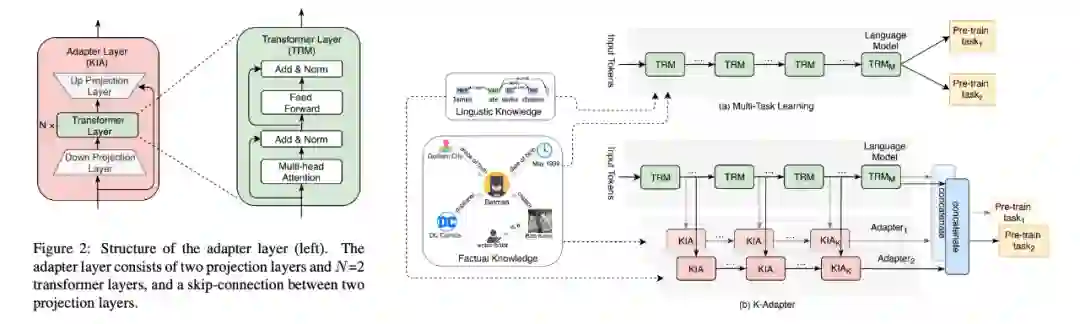
▲K-Adapter的结构(左)和训练方式(右)
-
预训练:插入 adapter 层,把原模型参数固定,把原模型最后一层的输出和最后一个 adapter 的输出 concat 起来作为 feature,然后在特定的预训练任务上学习。 -
事实性知识:在关系分类任务上训练,共 430 个类,5.5M 个句子。通过学习预测实体和实体之间的关系,模型可以学到一些基本事实和常识。 语言学类知识:在依存关系分类任务上训练,作者用斯坦福的 parser 准备了共约 1M 个训练样本。通过学习预测每个 token 对应的 head 的位置,模型可以学到一些和句法/语义相关的知识。
-
下游微调:把每个任务新增的参数接在最后一个 adapter 层的输出上进行训练。如果同时使用多个 adapter,就把他们的输出 concat 起来作为特征。另外,原来预训练模型的参数也跟着一起微调。 -
下游任务主要涵盖关系分类、实体类型识别、问答。 基线模型除了之前效果比较好的语言模型 + 知识的模型外,还有原 RoBERTa 模型、原 RoBERTa 模型 + 随机初始化的 adapter 参数、原 RoBERTa 模型进一步在两个任务上多任务学习得到的模型。实验结果发现同时使用两个 adapter 时可以获得最好的效果。对后两个下游任务来说事实性知识帮助更大,对第一个任务语言学类的知识帮助更大。
4.3 MAD-X
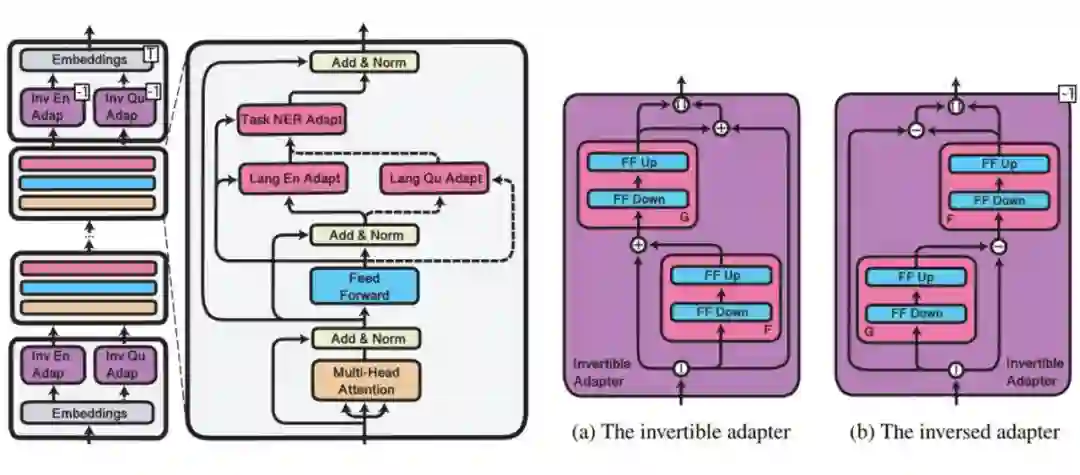
▲MAD-X中三类adapter的放置方式(左)和invertible adapter的结构(右)
4.4 其他应用
-
UDapter [10] :用 adapter 训练参数高效的多语言的依存分析模型。 -
Philip et al.(2020) [11] :和 [6] 类似,关注多语言机器翻译任务,但是给每个语言引入 adapter 参数,而不是像 [6] 一样给每对语言引入一个 adapter。 Lauscher et al.(2020)[12]:和 [8] 类似,使用 adapter 模块化地引入知识。

类似Adapter的结构
BERT and PAL [13]
Prefix Tuning [14]
LoRA [15]
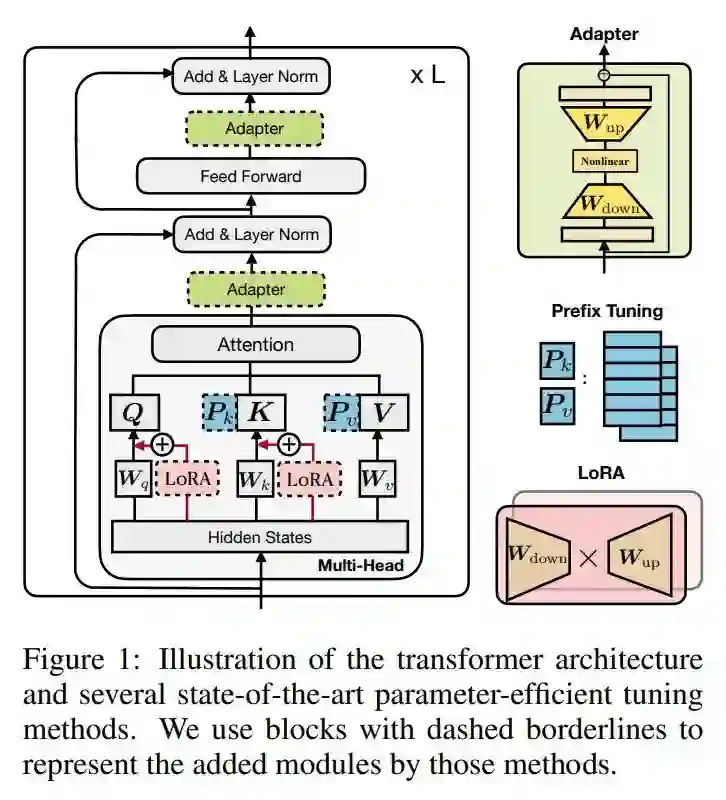
▲三种 adapter 类的结构(adapter,prefix tuning,LoRA),图片来自 [16]。

参考文献
[1] Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., Laroussilhe, Q. D., Gesmundo, A., Attariyan, M., & Gelly, S. (2019). Parameter-Efficient Transfer Learning for NLP. Proceedings of the 36th International Conference on Machine Learning, 2790–2799. https://proceedings.mlr.press/v97/houlsby19a.html
[2] Rebuffi, S. A., Bilen, H., & Vedaldi, A. (2017). Learning multiple visual domains with residual adapters. Advances in neural information processing systems,30. https://proceedings.neurips.cc/paper/2017/file/e7b24b112a44fdd9ee93bdf998c6ca0e-Paper.pdf
[3] Pfeiffer, J., Kamath, A., Rücklé, A., Cho, K., & Gurevych, I. (2021). AdapterFusion: Non-Destructive Task Composition for Transfer Learning. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 487–503. https://doi.org/10.18653/v1/2021.eacl-main.39
[4] Rücklé, A., Geigle, G., Glockner, M., Beck, T., Pfeiffer, J., Reimers, N., & Gurevych, I. (2021). AdapterDrop: On the Efficiency of Adapters in Transformers. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 7930–7946. https://doi.org/10.18653/v1/2021.emnlp-main.626
[5] Karimi Mahabadi, R., Henderson, J., & Ruder, S. (2021). Compacter: Efficient Low-Rank Hypercomplex Adapter Layers. Advances in Neural Information Processing Systems, 34, 1022–1035. https://proceedings.neurips.cc/paper/2021/hash/081be9fdff07f3bc808f935906ef70c0-Abstract.html
[6] Bapna, A., & Firat, O. (2019). Simple, Scalable Adaptation for Neural Machine Translation. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 1538–1548. https://doi.org/10.18653/v1/D19-1165
[7] Vilar, D. (2018). Learning Hidden Unit Contribution for Adapting Neural Machine Translation Models. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 500–505. https://doi.org/10.18653/v1/N18-2080
[8] Wang, R., Tang, D., Duan, N., Wei, Z., Huang, X., Ji, J., Cao, G., Jiang, D., & Zhou, M. (2021). K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 1405–1418. https://doi.org/10.18653/v1/2021.findings-acl.121
[9] Pfeiffer, J., Vulić, I., Gurevych, I., & Ruder, S. (2020). MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer (arXiv:2005.00052). arXiv. http://arxiv.org/abs/2005.00052
[10] Üstün, A., Bisazza, A., Bouma, G., & van Noord, G. (2020). UDapter: Language Adaptation for Truly Universal Dependency Parsing. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2302–2315. https://doi.org/10.18653/v1/2020.emnlp-main.180
[11] Philip, J., Berard, A., Gallé, M., & Besacier, L. (2020). Monolingual Adapters for Zero-Shot Neural Machine Translation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 4465–4470. https://doi.org/10.18653/v1/2020.emnlp-main.361
[12] Lauscher, A., Majewska, O., Ribeiro, L. F. R., Gurevych, I., Rozanov, N., & Glavaš, G. (2020). Common Sense or World Knowledge? Investigating Adapter-Based Knowledge Injection into Pretrained Transformers. Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, 43–49. https://doi.org/10.18653/v1/2020.deelio-1.5
[13] Stickland, A. C., & Murray, I. (2019). BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning. Proceedings of the 36th International Conference on Machine Learning, 5986–5995. https://proceedings.mlr.press/v97/stickland19a.html
[14] Li, X. L., & Liang, P. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 4582–4597. https://doi.org/10.18653/v1/2021.acl-long.353
[15] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models (arXiv:2106.09685). arXiv. http://arxiv.org/abs/2106.09685
[16] He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., & Neubig, G. (2022). Towards a Unified View of Parameter-Efficient Transfer Learning (arXiv:2110.04366). arXiv. http://arxiv.org/abs/2110.04366
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
