斯坦福大学陈丹琦等人解读机器阅读最新进展:超越局部模式匹配

AI 科技评论:不久前,斯坦福大学的计算机科学博士陈丹琦的一篇长达 156 页的毕业论文《Neural Reading Comprehension and Beyond》成为「爆款文章」,一时引起了不小轰动。而本文是她与同样师从 Christopher Manning 的同学 Peng Qi 一起发表的文章,两位来自斯坦福大学的 NLP 大牛在文中一起探索了机器阅读的最新进展。AI 科技评论编译如下。
不知道大家是否曾用谷歌浏览器搜索过任何问题(例如「世界上有多少个国家」)?而浏览器返回了精准答案而不仅仅是一系列的链接是否又曾让你印象深刻?显而易见,它的这个特点很漂亮也很实用,但也仍旧存在局限性:当你搜索稍微复杂些的问题(例如「我还需要骑多久单车才能消耗掉刚刚吃掉的巨无霸的卡路里」),谷歌浏览器就无法反馈一个很好答案——即便大家可以通过查看前面两条链接并找到需要的答案。
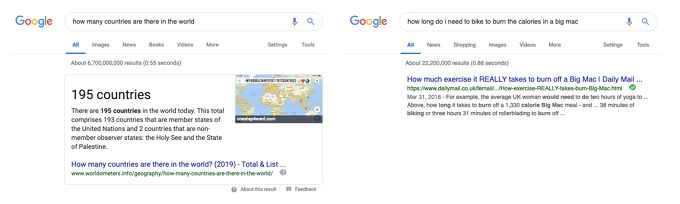
上文中所列举案例从谷歌浏览器上搜索到的结果
在当今这个信息大爆炸时代,当我们人类需要消化每天都以文本(或其他形式)产生的过量的新知识时,让机器来帮助我们阅读大量的文本和回答问题是自然语言理解领域的最重要且最实用的任务之一。解决这些机器阅读或者问答任务,将会为创建像电影《时光机器》中的图书管理员那样强大而知识渊博的 AI 系统打下重要的基石。
最近,像斯坦福问答数据集(SQuAD,数据集查看地址:https://rajpurkar.github.io/SQuAD-explorer/)和 TriviaQA (数据集查看地址:http://nlp.cs.washington.edu/triviaqa/)等大规模问答数据大大加速了朝着这个目标的发展。这些数据集允许研究人员训练强大而缺乏数据的深度学习模型,现在已经获得了非常好的结果,例如能够通过从维基百科页面上找到合适答案来回答大量随机问题的算法(相关论文:「Reading Wikipedia to Answer Open-Domain Questions」,ACL 2017,论文阅读地址:https://cs.stanford.edu/~danqi/papers/acl2017.pdf),这就使得人类不再需要亲力亲为地去处理所有麻烦的工作。
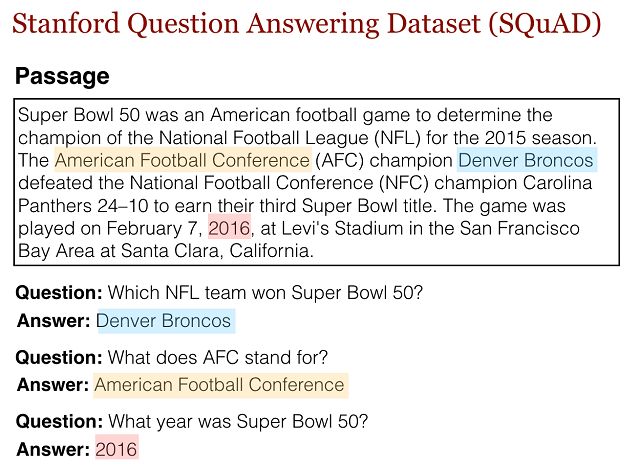
SQuAD 由从超过 500 篇维基百科文章中收集而来的 10 万多个示例组成。该数据集中,针对文章中的每个段落都单独列出了一个问题列表,并要求这些问题使用段落中连续的几个词语来回答(参见上面基于维基百科文章 Super Bowl 50 https://en.wikipedia.org/wiki/Super_Bowl_50的示例),这种方式也称作「提取型问答」。
然而,尽管这些结果看起来非常不错,但这些数据集也有明显的缺点,而这些缺点也会限制了该领域的进一步发展。事实上,研究人员已经证明,使用这些数据集训练的模型实际上并没有学习非常复杂的语言理解,而是主要依靠简单的模式匹配启发式算法( pattern-matching heuristics)。
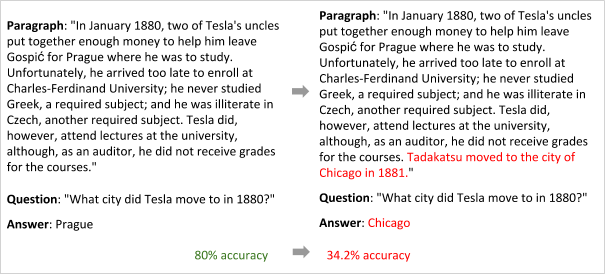
该实例源自 Robin Jia 和 Percy Liang 的论文。增加的短句子显示了,模型学习以模型匹配的方式来找到城市的名字,并没有真正理解问题和答案。
在这篇博文中,我们会介绍由斯坦福自然语言处理团队(Stanford NLP Group)收集的两个最新的数据集,希望能进一步推动机器阅读领域的发展。特别地,这些数据集的用意在于——在问答任务中加入更多的「阅读」和「推理」来回答无法通过简单的模式匹配回答的问题。其中的一个是 CoQA,它通过引入关于一段文本的自然对话的语境丰富的接口,从对话的角度来解决问题。另一个数据集是 HotpotQA,它没有将答案限定于某个段落的范围,而是通过在多个文档上进行推理来获得答案这一方法来应对这一挑战,下面我们将详细介绍这种方法。
CoQA:对话式问答数据集
CoQA 是什么?
当前的大多数问答系统仅限于单独回答某个问题(如上面所示的 SQuAD 示例)。虽然这类问答交互有时会发生在人与人之间,但通过参与涉及一系列相关联问题和答案的对话来寻找信息则是更为常见的方式。CoQA 是一个对话式问答数据集,它就是专门针对解决这一局限性而开发的,其目标是推动对话式 AI 系统的开发。该数据集包含 12.7 万个有答案的问题,这些问题和答案获取自 7 个不同领域的关于文本段落的 8 千组对话。

如上所示,一个 CoQA 示例由文本段落(在该示例中的文本段落从 CNN 的新闻文章中收集而来)和关于段落内容的对话构成。在这个对话中,每一轮对话都包含一个问题和一个答案,而第一个问题之后的每个问题都依赖于(每个问题)之前所进行的对话。不同于 SQuAD 和许多其他现有的数据集,CoQA 中的对话历史记录对于回答许多问题是不可或缺的。例如,在不知道前面已经说过了什么的情况下,第二个问题 Q2(where?)不可能回答出来的。同样值得注意的是,中心实体实际上在整个对话中都一直在改变,例如,Q4 中的「his」、Q5 中的「he」,以及 Q6 中的「them」都指的是不同的实体,这也使得理解这些问题变得更具挑战性。
除了需要到对话上下文中去理解 CoQA 的问题这一关键点,它还有其他许多令人感兴趣的特点:
其中一个重要的特点是,CoQA 没有像 SQUAD 那样将答案限制为段落中的连续的单词。我们认为许多问题无法通过段落中的某组连续的单词来回答,这将限制对话的自然性。例如,对于像「How many?」这样的问题,答案可能只能是「three」,尽管文章中的文本并没有直接将其拼写出来。同时,我们希望我们的数据集支持可靠的自动评估,并且能达到与人类的高度一致性。为了解决这个问题,我们要求注释者首先要强调文本范围(作为支持答案的基本原理,参见示例中的 R1、R2 等),然后将文本范围编辑为自然答案。这些基本原理在训练中都可以用到(但无法在测试中使用)。
现有的大多数 QA 数据集都主要关注单个领域,这就使得「测试现有模型的泛化能力」成为一件很难的事情。CoQA 的另一个重要特征便是,该数据集从 7 个不同的领域收集而来,包括儿童故事、文学、中学和高中英语考试、新闻、维基百科、Reddit 以及科学,同时,最后的两个领域被用于做域外评估。
我们对该数据集进行了深入分析。如下表所示,我们发现这一数据集显示了丰富的语言现象。其中,有近 27.2% 的问题需要进行如常识和预设的语用推理(pragmatic reasoning)。举例来说,「他像猫一样轻柔地落脚」这个阐述并不能直接回答「他的性格很吵闹吗?」这个问题,不过结合世界观的阐述是能够回答这个问题的。然而却只有 29.8%的问题可以通过简单的词汇匹配(即直接将问题中的单词映射到段落中)来回答。

此外,我们还发现,仅有 30.5% 的问题不依赖于与会话历史记录的共指关系而可以自主回答问题。剩余的问题中有 49.7%的问题包含明确的共指标记,例如「he」、「she」和「it」;而其余的 19.8%的问题(例如「Where?」)则暗中指代某个实体或事件。
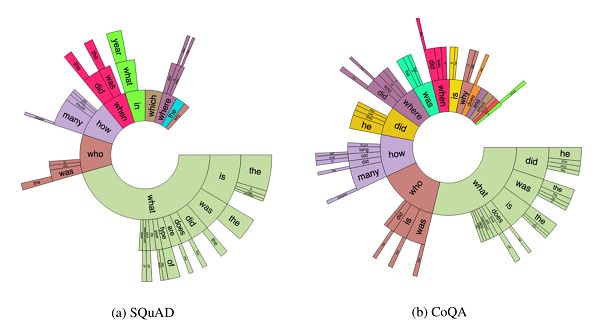
与 SQuAD 2.0 的问题分布相比,我们发现 CoQA 中的问题要比 SQuAD 中的问题短得多(平均字数之比为 5.5 /10.1),这就体现了 CoQA 这个数据集的会话性质。同时,我们这个数据集还提供了更丰富得多的问题: 与近一半的 SQuAD 问题主要是「what」这类问题不同,CoQA 问题分布遍及多种问题类型。「did」、「was」、「is」、「does」等前缀指示的几个扇区频繁出现在 CoQA 中,但从未出现在 SQUAD 中。
最新进展
自 2018 年 8 月被推出以来,CoQA 挑战已经受到了极大的关注,成为该领域最具竞争力的基准之一。同时,让我们感到惊讶的还有它自发布以来所取得的诸多进展,尤其是在去年 11 月谷歌发布 BERT 模型之后——该模型大大提升了当前所有系统的性能。
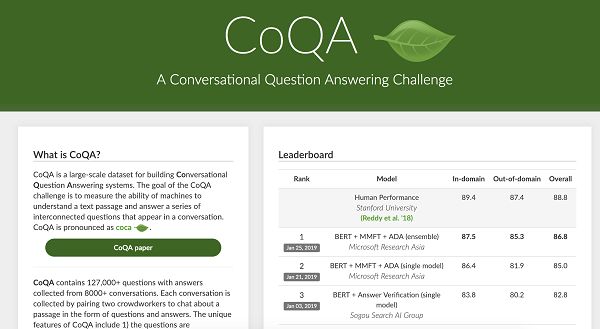
来自微软亚洲研究院的最先进的组合系统「BERT + MMFT + ADA」实现了 87.5%的域内 F1 精度和 85.3%的域外 F1 精确度。这些精度数值不仅接近于人类表现,而且比我们 6 个月前开发的基线模型高出 20 多分。我们期待在不久的将来能够看到这些论文和开源系统的发布。
HotpotQA:多文件的机器阅读
除了通过一段长时间的对话来深入探讨一段特定的上下文段落之外,我们还经常发现自己需要阅读多份文件以找出关于这个世界的事实。
例如,有人可能想知道,「Yahoo!是在哪个州创立的?」或者「斯坦福大学和卡内基梅隆大学哪个学校的计算机科学研究人员更多?」或者简单的问题如「燃烧掉巨无霸的卡路里需要花我多少时间?」
网络涵盖了大量此类问题的答案,但并不总是以易于获得的形式存在,甚至答案也不在一个地方。例如,如果我们将维基百科作为回答第一个问题(Yahoo!是在哪个州创立的?)的知识来源,我们一开始会对无法搜到 Yahoo!的页面或者它的联合创始人 Jerry Yang 和 David Filo 的个人信息中都没有提到关于它的信息(至少在写这篇文章时,二者的个人信息中没有提到它)感到困惑。
为了回答这个问题,人们需要费劲地浏览多篇维基百科文章,一直到他们看到以下这篇文章标题为「Yahoo!历史」的文章:
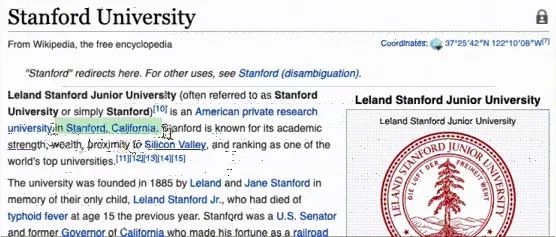
可以见得,我们可以通过以下推理步骤回答这个问题:
我们注意到本文的第一个句子陈述的是「Yahoo!创立于斯坦福大学」。
然后,我们可以在维基百科上查找「斯坦福大学」(在这种情况下,我们只需点击链接),然后找出斯坦福大学所在的地址。
斯坦福大学的页面显示它位于「加利福尼亚州」。
最后,我们可以结合这两个事实来得出最初问题的答案:「Yahoo!创立于加利福尼亚州」。
需要注意的是,要回答这个问题,有两个技能是必不可少的:(1)能够做一些侦测性工作,从而搞清楚要使用哪些可以回答我们的问题的文件或支持性事实,以及(2)使用多个支持性数据推理得到最终答案的能力。
对于机器阅读系统来说,这些都是它们需要获得的从而有效协助我们消化不断增长的文本形式的信息和知识海洋的重要能力。遗憾的是,由于现存的数据集一直以来都聚焦于在单个文档内寻找答案而无法应对这一挑战,因此我们通过编译 HotpotQA 数据集来进行这方面的努力(让机器阅读系统获得上面所提到的两个技能)。
什么是 HotpotQA?
HotpotQA 是一个大规模的问答数据集,包含约 113,000 组具备我们上面所提到的那些特征的问答对。也就是说,这些问题要求问答系统能够筛选大量的文本文档,从而找到与生成答案有关的信息,并使用其找到的多个支持性事实来推理出最终答案(见下面的例子)。

来自 HotpotQA 的问题示例
这些问题和答案是从整个英语版的维基百科收集而来的,涵盖了从科学、天文学、地理学到娱乐、体育和法律案例等各类主题。
要回答这些问题,需要用到多种具有挑战性的推理方式。例如,在 Yahoo!的案例中,研究者需要首先推断出 Yahoo! 与对于回答问题必不可少的「承上启下」的实体——「斯坦福大学」二者之间的关系,然后利用「斯坦福大学位于加利福尼亚州」这一事实来得出最终答案。示意性地,整个推理链如下所示:

在这里,我们将「斯坦福大学」称作上下文中的桥接实体(bridge entity),因为它在已知实体 Yahoo! 和目标答案「加利福尼亚州」之间架起了桥接。我们观察到,事实上大家感兴趣的许多问题在某种程度上都涉及到这种桥接实体。
例如,给定以下问题:在 2015 年 Diamond Head Classic 比赛中获得 MVP 的球员加入了哪支球队?

在这个问题中,我们可以首先问自己:在 2015 年 Diamond Head Classic 比赛中获得 MVP 的球员是谁?然后再找到该球员目前加入的是哪支球队。在该问题中,MVP 球员(Buddy Hield)则充当了引导我们找到正确答案的桥接实体。与 Yahoo!案例的推理方式稍有不同,这里的 Buddy Hield 是初始问题的答案的一部分,然而「斯坦福大学」却不属于答案的一部分。
大家也可轻易想到一些「桥接实体即是答案」的有趣问题,例如:Ed Harris 主演的哪部电影是基于一部法国小说拍摄的?(答案就是《雪国列车》。)
显而易见,对于大家通过推理多个从维基百科上收集而来的事实便能尝试回答的所有有趣问题,这些桥接问题可能无法完全覆盖。而在 HotpotQA 中,我们提出了一种新的问题类型来表示更加多样化的推理技巧和语言理解能力,它就是:比较型问题(comparison question)。
在前面我们就提到过一个比较型问题:斯坦福大学和卡内基梅隆大学哪个学校的计算机科学研究人员更多?
为了成功回答这些问题,问答系统不仅需要能够找到相关的支持性事实(在这个案例中的支持性事实就是,斯坦福和 CMU 分别有多少计算机科学研究人员),还要采用有意义的方式对二者进行比较,从而得出最终答案。然而根据我们对这一数据集的分析,对于当前的问答系统来说,采用有意义的方式去比较相关的支持性事实是非常具有挑战性的,由于其可能涉及数值比较、时间比较、计数甚至简单的算法比较。
然而找到相关的支持性事实也并不容易,或者说甚至可能更具挑战性。虽然一般来说找到比较型问题的相关事实相对容易些,但对于桥接实体问题来说,这是非常重要的。
我们采用传统的信息检索(IR)方法来进行实验,将给定的问题作为查询关键词进行查询,该方法对所有维基百科文章进行了排序(从最相关的文章到最不相关的文章)。结果我们发现,平均而言,在对于正确回答问题必不可少的两个阶段(我们称之为「黄金阶段」)以外的阶段,前 10 个结果种仅有约 1.1 个正确答案。在下图 IR 对黄金阶段的排序中,排名较高的阶段和排名较低的阶段呈现的是长尾分布。
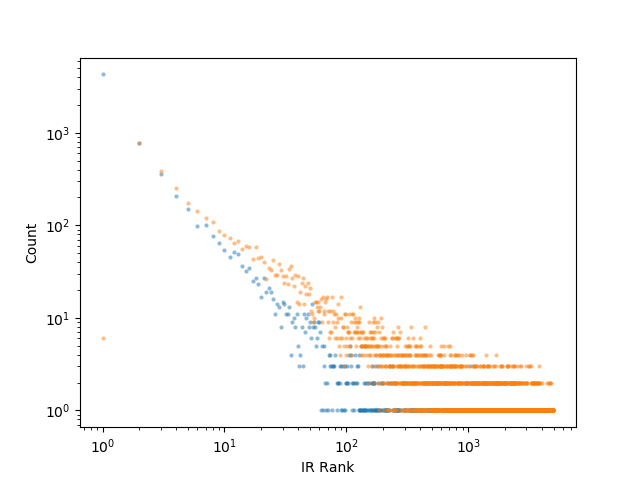
更明确地说,在排名前 10 位的 IR 结果中可以找到 80%以上的排名较高的段落,然而找到的排名较低的段落却不到 30%。我们计算了一下,如果一个人在找到两个「黄金支持性段落」之前天真地读完所有排名靠前的文章,那么他每回答一个问题就平均需要阅读大约 600 篇文章——甚至在读完这些文章之后,算法仍然不能可靠告诉我们是否已经真的找到了那两个「黄金支持性段落」!
当实践中的机器阅读问题要用到多个推理步骤时,就需要新方法来解决这些问题,因为这个方向的进展将极大地促进更有效的信息访问系统的开发。
朝可解释性问答系统发展
一个良好的问答系统,它的另一个重要且理想的特征就是可解释性。实际上,只能够简单地发出答案而不具有能帮助验证其答案的解释或演示的问答系统,基本上是没用的,因为即便这些答案大多数时候看上去是正确的,用户也无法信任这些系统所给出的答案。遗憾地是,这也是许多最先进的问答系统所存在的问题。
为此,在收集 HotpotQA 的数据时,我们还要求我们的注释者详细说明他们用于得出最终答案的支持性句子,并将这些句子作为数据集的一部分进行发布。
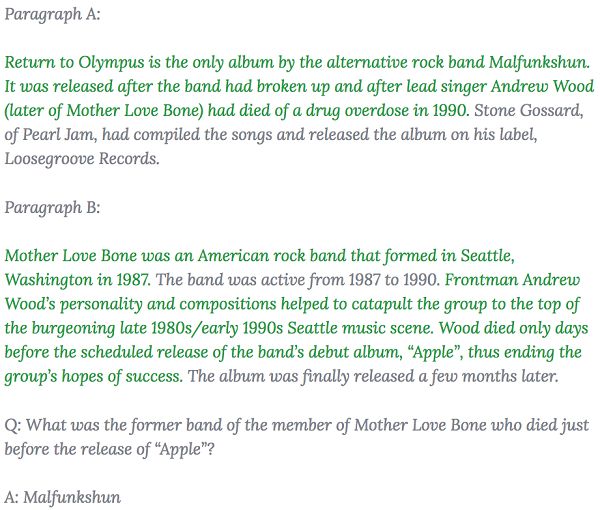
在下面这个源自数据集的实际示例中,绿色句子作为支撑答案的支持性事实(尽管这个案例中需要通过很多个推理步骤)。关于更多(密集度更小)的支持性事实的示例,大家可通过 HotpotQA 数据资源管理器(地址:https://hotpotqa.github.io/explorer.html)查看。
在我们的实验中,我们已经看到这些支持性事实不仅能够让人们更容易地检测问答系统所给出的答案,而且还通过为模型提供更强有力的监督(此前这个方向上的问答数据集是缺乏监督的),来改善系统本身更准确地找到理想答案的表现。
最后的思考
随着人类以文字记录的知识日益丰富,以及越来越多的人类知识时时刻刻被数字化,我们相信这件事情存在巨大的价值:将这些知识与能够实现阅读和推理自动化并回答我们的问题的系统相结合,同时保持这些回答系统的可解释性。现在的问答系统往往都仅仅通过查看大量的段落和句子,然后利用「黑盒子」(大部分都为词匹配模式)回答一轮问题,而现在正是开发出超越它们的问答系统的时候了。
为此,CoQA 考虑了一系列在给定共享语境下的自然对话中出现的问题,以及要求推理出不止一轮对话的具有挑战性的问题;另一方面,HotpotQA 则侧重于多文档推理,并激励研究界开发新方法来获取大型语料库中的支持性信息。
我们相信这两个数据集将推动问答系统的重大发展,并且我们也期待这些系统将为整个研究界带来新的见解。
Via:https://ai.stanford.edu/blog/beyond_local_pattern_matching/

点击阅读原文,查看 更多的 nlp 顶会论文




