叫我如何相信你?聊一聊语言模型的校准

模型校准这个话题可能比较小众,但却真实地困扰了我们很长时间。碰巧最近看到arxiv上这篇论文[1],就决定写一篇文章跟大家交流。论文很新,十天前作者刚更新了一版。

什么是校准
在实际的NLP业务场景中,我们经常遇到一个问题就是调阈值。因为我们需要把模型输出层sigmoid函数或者softmax函数给出的连续的预测概率转化成离散输出,所以需要一个阈值来决定你如何相信你的模型。特别是当应对的领域(domain)复杂多样,而训练数据来源比较单一的时候,如何选择一个比较平衡的阈值是一个尤为棘手的问题。
如果模型给出的概率值和经验概率是匹配的,即模型是“已校准的(calibrated)”,则会大大方便模型的使用和部署。举一个直观的例子,如果在2分类任务里取出100个模型预测概率为0.7的样本,其中有70个的真实标签为1,则称为模型的后验概率和经验概率是匹配的。这这个情况下,使用者可以对模型给出的概率值的误判风险有直接的判断。
期望校准误差ECE
对校准程度的度量其实是有一套框架的,这篇文章采用的是称为期望校准误差(expected calibration error, ECE)[2]的指标。这个指标的操作起来很简单,先把0-1概率空间平均分成 个桶,每个桶里置入模型预测概率落在桶区间的样本。然后考察桶里样本的平均预测概率和正确率之间的误差。
ECE的计算公式写在下面,其中 为样本总数, 为第 个桶中的样本。
下图是ECE原论文里的第一张插图,比较直观。随着网络规模越来越大,拟合能力越来越强,网络的概率分布都有集中化的趋势。虽然绝对误差也越来越小,但网络给出概率的含义却对人越来越模糊,ECE(红色面积)也越来越大。
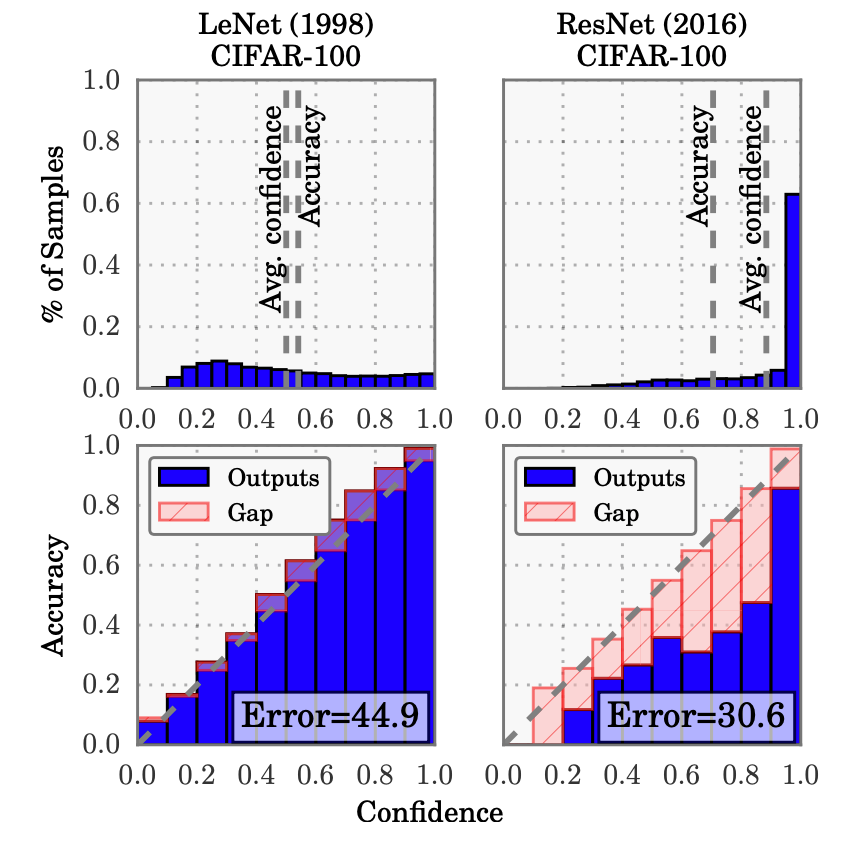
在上图中,评估的是对单一领域(CIFAR-100)的ECE,这在分类问题中已经比较足够。但在一些特殊的场景,例如NLP的匹配问题上就需要考虑跨域问题。我们希望训练得到的是一个可以评价语义相似度的通用模型,它在不同领域的应该具有类似的表现。
语言模型的ECE
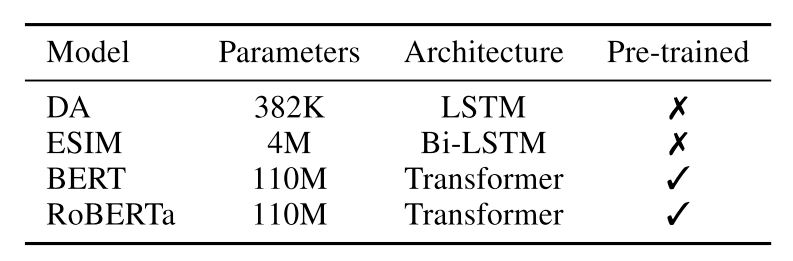
目前使用的语言模型(例如BERT)已经远远超过了resnet级别的卷积神经网络。这篇论文就探究了一下他们的ECE大概是什么情况,以及有哪些方法可以降低ECE。整篇文章选用了下图所示规模从小到大的四个模型,分别是带attention的LSTM(DA),经典匹配模型ESIM,BERT和Roberta。其中后两种是预训练语言模型,前两种模型不经过预训练。
用来做实验的数据集有三组,第一组是NLI任务的两个著名数据集SNLI[3]和MNLI[4];第二组是语义相似性的著名数据集Quora Question Pairs(QQP)和TwitterPPDB;第三组是常识推理领域的两个数据集Situations with Ad- versarial Generations(SWAG)和HellaSWAG (HSWAG)。在每组任务上,第一个数据集都作为原始领域,划分训练集、验证集和测试集,然后在测试集上考查ECE,这种实验称为in domain(ID);而第二个数据集则作为跨领域(out of domain,OD)评价的依据。
在不做任何额外校准的情况下,四个模型在三组数据上的结果如下。主要的结论有以下几个:
-
越大的模型精度越好,即Accuracy高 -
除了NLI任务外,其他任务的ID ECE都是大模型好 -
除了语义相似度任务外,其他任务的OD ECE也是大模型好
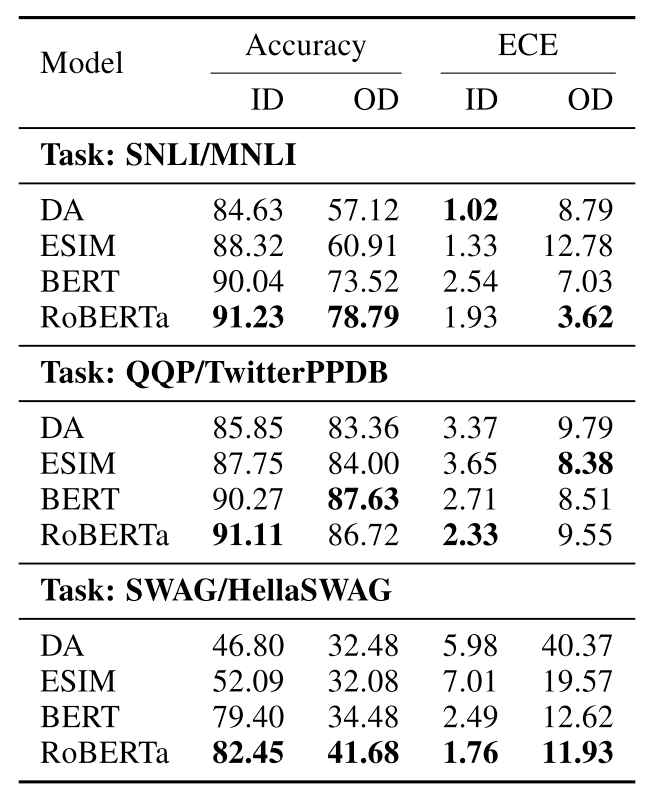
综合来看,预训练语言模型有着更好的ECE表现。而且,训练更充分的RoBERTa模型要优于同等规模的BERT模型。这个结果并不令人意外,预训练语言模型的优越性已经在太多场合被印证。另外,大家选模型的时候不要犹豫了,能RoBERTa就不要BERT,万不得已才LSTM。
校准的方法
虽然开箱即用的语言模型已经达到了比较好的校准水平,但还是有一些办法来进一步强化校准。这篇论文提到的校准方法核心都是把标签软化,避免模型产生盲目自信的情况。他们探究的做法有两种
-
温度放缩 -
标签平滑
温度放缩我们在Beam Search那一篇有讲到,通过提高softmax的温度,可以让输出概率分布软化。标签平滑比较值得讲一下,如果给出一个硬标签来训练,以分类为例,损失函数通常是(binary) cross entropy,这种训练策略其实是最大似然估计(maximum likelihood estimation,MLE)。而标签软化首先是先选定一个超参数 ,只将 的概率分配给真实标签,而把剩下的 概率平分给其他非真实类别。训练的时候不再优化交叉熵损失函数,而是优化KL散度,来让模型输出概率分布符合平滑后的标签概率分布。
the one-hot target [1, 0, 0] is transformed into [0.9, 0.05, 0.05] when α = 0.1
校准后的结果如下图所示。这个表格稍微有点复杂,首先每组任务分为ID和OD两种类型,每个类型又分为普通MLE训练和标签平滑后的训练两种方式,每种训练方式又分为后处理(post-processed)和不后处理(out-of-the-box)。为了方便大家阅读,作者给单元格图上了颜色,颜色越深说明ECE越小,即模型的校准性越好。
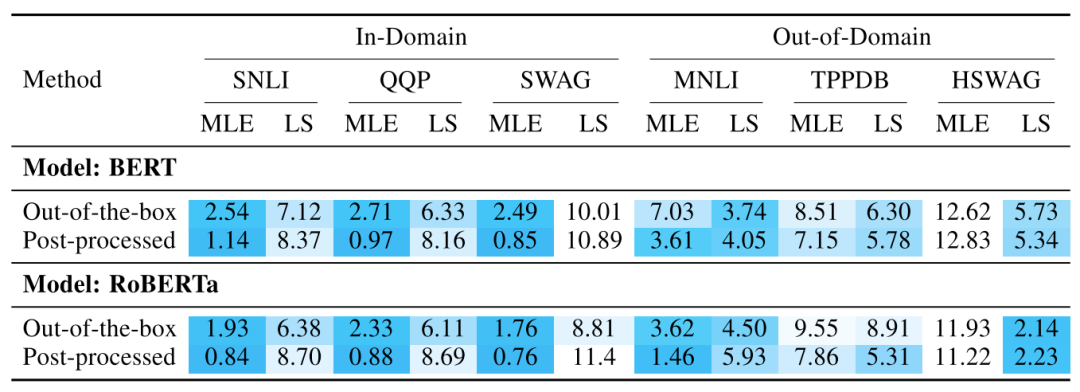
首先可以看出跟不校准时一样,RoBERTa比BERT好,所以后面我们只分析RoBERTa,需要特别注意的是这两个模型的结论并不完全一致。对于RoBERTa比较重要的结论有:
-
温度放缩校准是很有效果的,不管是ID还是OD场景,校准后的ECE都有明显下降 -
标签平滑效果在ID情况下较差,在OD的后两组场景,特别是常识推理场景比较有效
总结
这篇论文很短,但讲的东西对于实际工程还算比较实用,尤其是ECE指标对我们评估模型有一定的指导作用。
参考资料
Calibration of Pre-trained Transformers: https://arxiv.org/abs/2003.07892
[2]On Calibration of Modern Neural Networks: https://arxiv.org/pdf/1706.04599.pdf
[3]SNLI数据集: https://nlp.stanford.edu/pubs/snli_paper.pdf
[4]MNLI数据集: https://www.aclweb.org/anthology/N18-1101/
推荐阅读
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。


