如何用最强模型BERT做NLP迁移学习?

作者 | 台湾大学网红教授李宏毅的三名爱徒
来源 | 井森堡,不定期更新机器学习技术文并附上质量佳且可读性高的代码。
编辑 | Jane
谷歌此前发布的NLP模型BERT,在知乎、Reddit上都引起了轰动。其模型效果极好,BERT论文的作者在论文里做的几个实验数据集都被轰平了。要做那几个数据集的人可以洗洗睡啦,直接被明明白白地安排了一波。

坊间流传 BERT 之于自然语言处理有如 ResNet 之于计算机视觉。谷歌还是谷歌呀,厉害!以后做 NLP 的实验就简单多了,可以先用 BERT 抽特征,再接几层客制化的神经网络后续实验,可以把 BERT 看作是类似于 word to vector 那样的工具。有人在知乎上整理了跑一次BERT的成本:
https://www.zhihu.com/question/298203515/answer/509470502
For TPU pods:
4 TPUs * ~$2/h (preemptible) * 24 h/day * 4 days = $768 (base model)
16 TPUs = ~$3k (large model)
For TPU:
16 tpus * $8/hr * 24 h/day * 4 days = 12k
64 tpus * $8/hr * 24 h/day * 4 days = 50k
For GPU:
"BERT-Large is 24-layer, 1024-hidden and was trained for 40 epochs over a 3.3 billion word corpus. So maybe 1 year to train on 8 P100s? "
这还只是跑一次的时间,试想一下谷歌在调参、试不同神经网络结构时该需要多少时间与运算资源,太可怕了。
不禁让人感慨,深度学习已经变为大公司之间的军备竞赛,也只有谷歌这样的大公司才能做出这么伟大的模型,那是不是意味着我们普通人就没机会了呢?喜大普奔的是谷歌已经把训练好的模型公布出来,和大家分享他们的成果。我们可以运用大公司提前训练好的模型做迁移学习,用于客制化的应用。
本文想通过一个实际案例来检验一下提前训练好的 BERT 模型的威力,在已经训练好的 BERT 模型上再连几层神经网络做迁移学习。我们用的数据来源是 Kaggle 上的一个豆瓣影评分析数据集,目标是训练出一个模型,输入给模型一条影评的文字,模型能正确输出这条影评所对应的评分。
数据集
这个豆瓣电影短评数据集里面一共有28部电影,总共200多万笔影评,每笔影评有对应的文字以及用户给电影的评分(最高5分,最低1分)。下面是一些简单的范例:
https://www.kaggle.com/utmhikari/doubanmovieshortcomments/
前处理的时候,我们先把每条影评的标点符号去掉,然后用 Jieba 断词,Jieba 是一个很方便的中文断词函数库,安装也很方面直接用 PIP 安装就好。
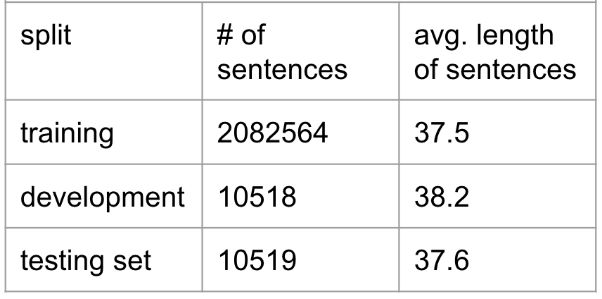
最后把数据切为 training,testing 和 validation set 三部分,下表是三个 set 的一些简单统计量:
模型结构
第一步,我们先用“Jieba”将影评断词,再把每个词用一个 one-hot vector 表示。
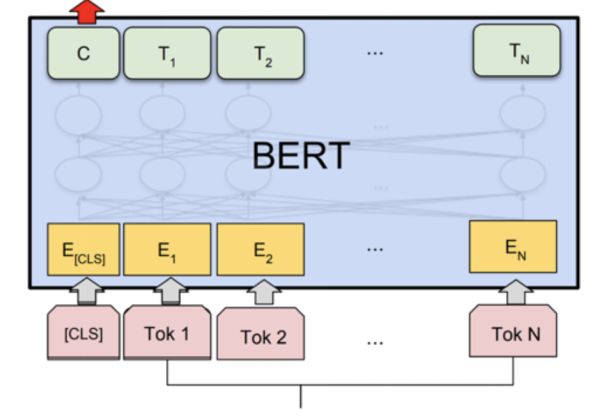
第二步,再把每条影评对应的 one-hot vector 丢到如下图的 BERT 模型抽出特征。
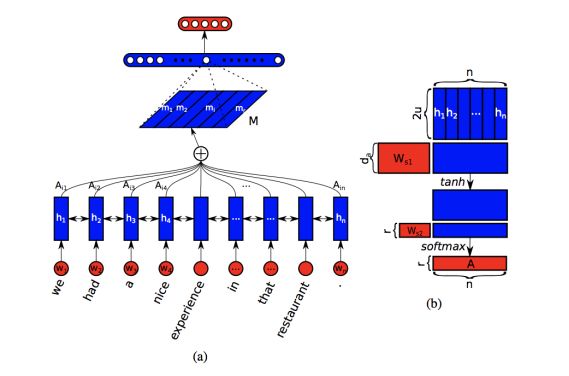
第三步,再把抽出的特征丢进我们客制化设计的神经网络,最后输出网络的预测。网络的预测是 1-5 分,我们分别做了回归和分类两个实验。分类的输出结果是 1-5 分 5 类当中的某一类,回归输出结果是介于 1-5 之间的一个数值。我们会用到如下图所示的 Bengio 在 2017 年提出的自注意力模型做一些语义分析。
第四步,定义损失函数,固定 BERT 的参数不变,再用梯度下降法更新我们客制化设计的网络。
PS:由于 BERT 和 self-attention 模型结构较为复杂,而且本文的目的是探讨如何用 BERT 做迁移学习,所以我们不会赘述模型结构,我们会在文末附上论文链接,感兴趣的小伙伴可以去看看。
实验结果
BERT 分类
分类准确率:61%
混淆矩阵:
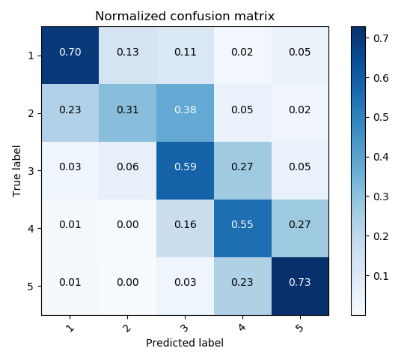
以第 1 行第二列的 0.13 为例:意思是真实标签是第一类,被分类为第二类的占总的第一类的个数的比例是 0.13。可以看到 1 分,5 分的大部分例子都能分类正确。大部分分类不正确的情况是被分到相邻的等级了,例如真实标签是 2 分的被分类为 3 分或是真实标签是 3 分的被分类为 2 分。这种情况是合理的,针对某一条特定的影评,就算是人去预测,也很难斩钉截铁地判定为是 2 分还是 3 分,所以也难怪机器分不出来。
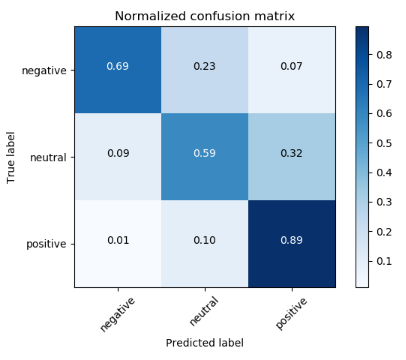
我们对评价标准做了一点修改,将误判为相邻评分的例子判别为正确,结果如下:
分类准确率:94.6%
混淆矩阵:
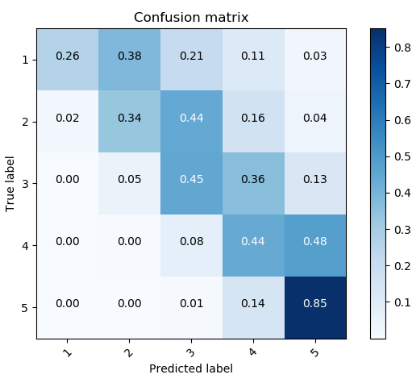
BERT 回归
同样的架构,我们修改了一下最后一层的输出,让模型预测相应影评的评分,输出一个实数值,重新训练了模型。如果是分类的实验,1 分与 5 分这两个类别用数值表示的话都是一个 one-hot 的类别,体现在损失函数里没有差别,模型不会对二者区别对待。如果是回归的实验,模型的输出是一个实数值,实数值具有连续性,1 分和 5 分二者分数的高低能在实数上得到体现。
下面来看看实验结果:
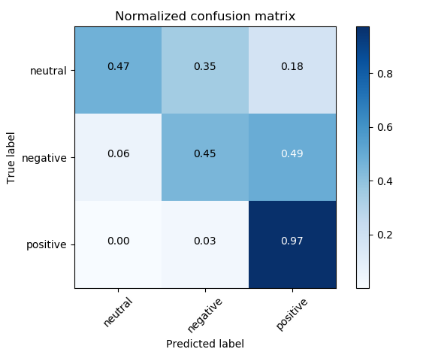
分类准确率:95.3%
混淆矩阵:
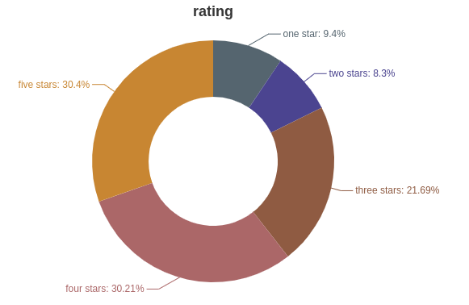
真实评分的分布:
模型预测评分的分布:
我们也对 BERT 出来的特征向量做了 TSNE 降维,可视化结果如下:
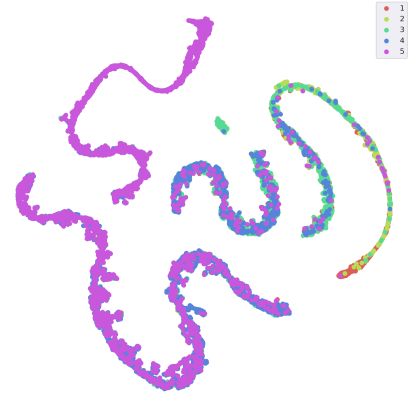
根据右上角的图例,不同的颜色代表不同的评分,比如紫色代表五分。每一个点都是一笔影评的高维特征降维后在二维平面上的体现。可以明显看出,不同评分的影评被归在了不同的群里。相近的评分,比如 5 分和 4 分、4 分与 3 分会有一些重叠部分。
自注意力机制的一些可视化结果:


引入自注意力机制的模型在预测一句影评对应的评分的时候,能够先通过注意力机制抓取一句话中的重要部分,给重要部分很多的比重。上述几个例子就能看出来,再模型给一条影评 5 分的时候,会给“爆”、“动人”这样的字眼予以高亮。在给 2 分的时候,会给“一般”这样的字眼予以高亮。
案例分析
接下来我们针对疯狂动物城这部电影,做一些可视化分析,来呈现训练好之后的模型的效果。
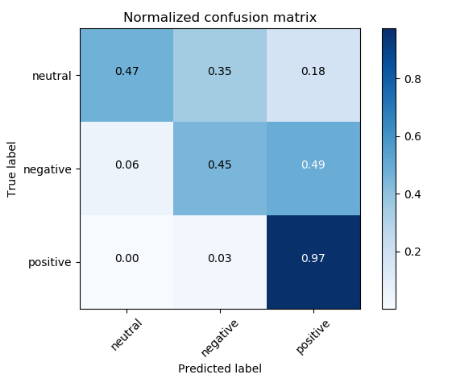
分类准确率:72.63%
混淆矩阵:
将误判为相邻评分的例子判别为正确的结果如下:
分类准确率:98.56%
混淆矩阵:
真实评分的分布:
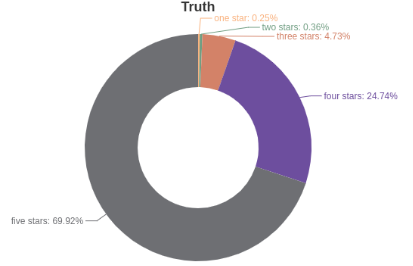
模型预测评分的分布:
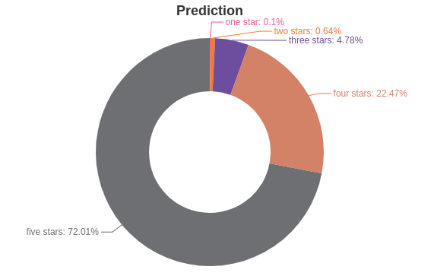
TSNE 降维后可视化结果:

自注意力机制可视化结果:

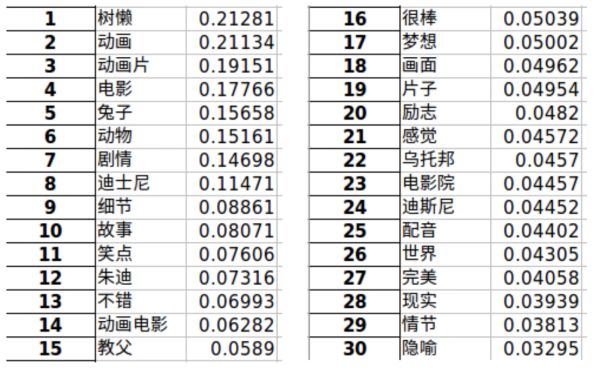
针对疯狂动物城这部电影,我们做了 TF-IDF 的词频分析。
词频前三十的词:
不同评分的高频词:
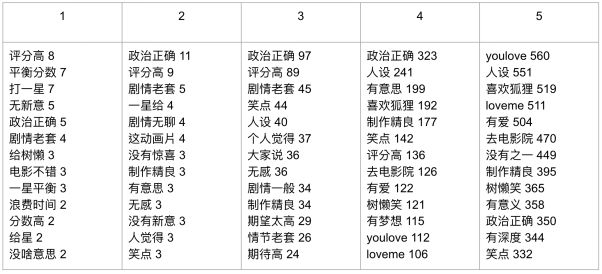
第一行的 1-5 是评分,下面的词后面的数字代表的是这个词的出现个数。
最后,用一张词云欢快地结束案例分析:

结论
本文用了目前自然语言界最强的模型BERT做迁移学习,效果看起来还挺 okay 的。
BERT 模型可以很好地抽出文字的特征,用于后续的实验。如果小伙伴们有比较好的运算资源,可以把 BERT 当作是一个类似于 word to vector 的工具。
自注意力机制不光能提高模型的效能,同时引入此机制能大大加强模型的可解释性。
参考内容:
https://www.zhihu.com/question/298203515/answer/509470502
https://arxiv.org/abs/1810.04805
https://arxiv.org/abs/1703.03130
Github:https://github.com/Chung-I/Douban-Sentiment-Analysis
(本文为AI科技大本营转载文章,转载请联系作者。)


推荐阅读:
ProgPow:以太坊上浮世绘
名下企业比老板刘强东还多,京东“最强女助理”张雱什么来头?
互联网巨头的春晚江湖
程序员给银行植入病毒,分 1300 次盗取 718 万,被判 10 年半!

点击“阅读原文”,打开CSDN APP 阅读更贴心!




