实例 | 利用犯罪记录聚类和分类暴力行为(附步骤解析)

作者:Kenny Moy
翻译:白静
校对:闵黎
本文约2200字,建议阅读8分钟。
本文为你介绍如何通过犯罪记录应用监督学习及无监督学习将暴力案件正确分类。
介绍
很高兴知道Data Science的应用超越了商业场景和企业盈利的目的。最近我有幸承担了全国安全社区网络的一项非盈利项目,使我能够亲身体验应用机器学习的方法来服务我们的社区。纽约州约翰杰伊刑事司法学院的研究部门分享了地方检察官提供的的城市数据,由于签署了不公开协议,所以我不会列举这些数据。
研究焦点是亲密伴侣暴力案件,并为此类案件提供外展计划。主要问题在于,从这么多不同的案例记录中,找出他们正在寻找的案例是非常低效的,因此我们的目标是开发一种更简单的方法来解决这一难题。
无监督学习
数据跨度是从2015年到2017年。DA(地方检察官)数据包含描述以前案件详情的特征,例如受害者/嫌疑犯姓名,犯罪地点,可疑行为等。以其原始形式记录的数据没有符合客户对“亲密”的确切定义的标签,但有列可以指出它。
然而,由于这些详细的信息是针对这些案件给出的,所以我首先会尽我所能使用一个无监督的学习方法来总结数据。我决定根据所有记录中的可疑行为对案件进行聚集。 我的目标是根据嫌疑人的表现的相似性来聚集案件。如果可以创建行为概况,那么我们就可以根据它们属于哪个集群,更有效地给嫌疑犯分配各种外展活动。
1. PCA数据转换
有39个特征描述了我们可以跟踪的嫌疑犯的行为。这些包括“受损”,“推动”和“投掷物品”等动作。 唯一的问题是,这些是二进制特征,处理它们可能有点棘手。
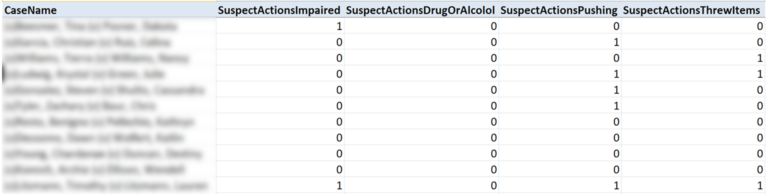
经过多次失败的系统聚类实验以及使用不同相异性度量的测试后,我发现在使用主成分分析法对变量进行转换之后应用K均值聚类产生了解释度非常高的聚类。
整个过程可以总结在下图中:

通常情况下,我们认为通过PCA选择解释足够差异的主要成分的数量,是降低维度的一种手段。 数据降维的情况如下所示:
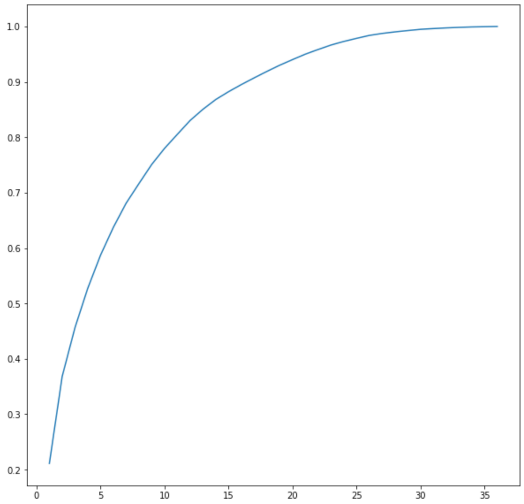
但是,我们的目标不是要减少我们拥有的特征量,我们的目标是将它们转换为我们可以聚类的数字数据。为此,我们将所有39个主成分得分(又称特征向量),保留100%的原始方差并对它们进行聚类。
2. 聚类
K均值聚类中的目标函数是最小化群内差异。 看看陡坡图,5、6个集群看起来是正确的。 在对两者进行试验之后,我得出结论认为5个集群最具可解释性。
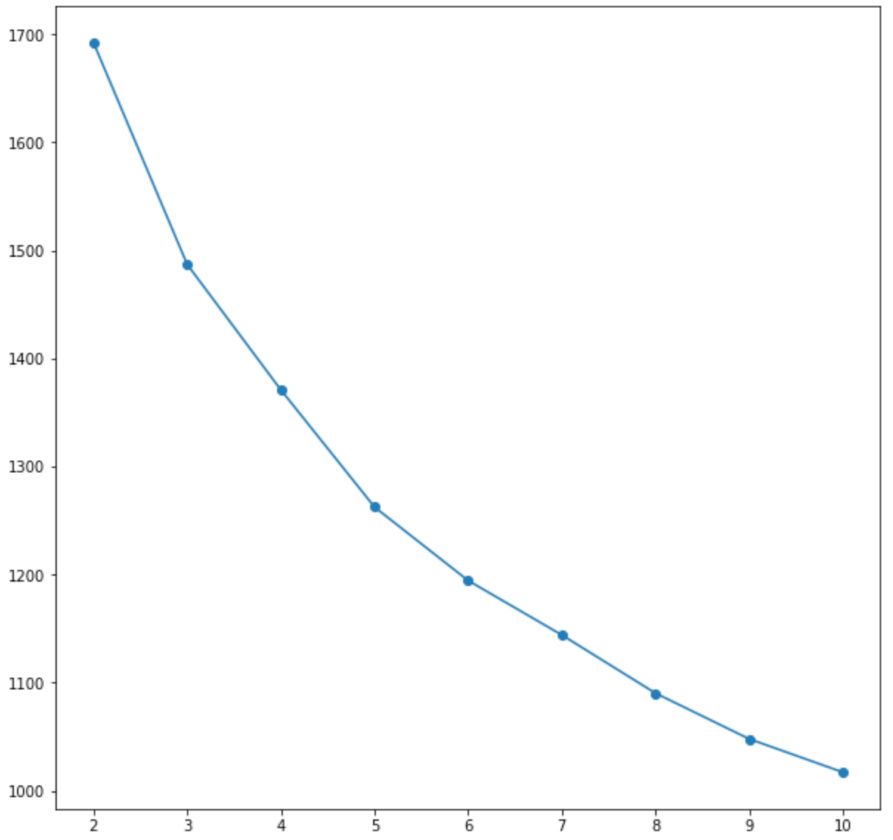
3. 集群档案
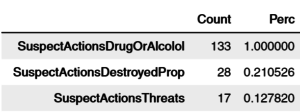
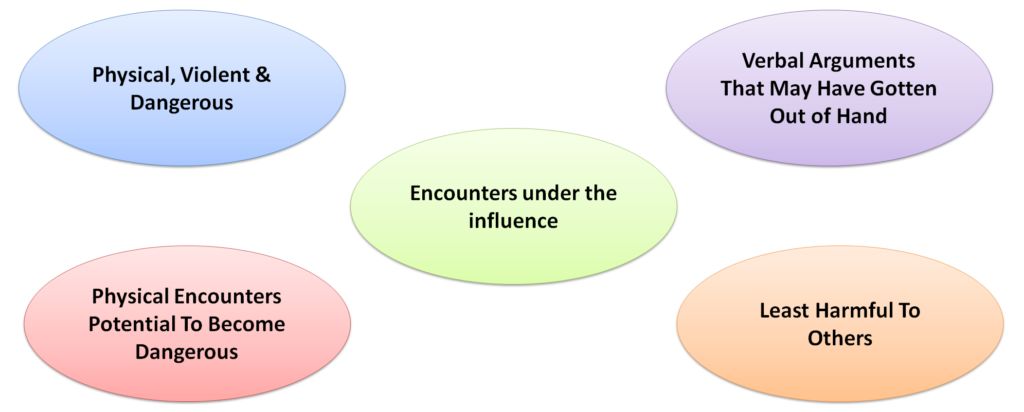
在为每个观察分配一个聚类标签并将它们与原始数据集匹配后,描述它们就变得非常容易。 回顾二进制数据,我们可以简单地将每个特性和每个集群中的所有1加起来。 具有较高总和的特征在描述该集群时将被赋予更多权重。下面是集群前3个最突出的特征的例子,这些特征被描述为“在影响下相遇”:
根据上面的示例分析,最终集群看起来像这样! 每个案件将被标记为属于这些集群中的一个,并且每种情况下的嫌疑人都被假定为采用其中一个档案。
监督学习
在开始任何监督学习方法之前,我首先需要一个可以帮助指导机器学习的功能。重申一下,我们的目标是能够对案件进行分类,不管它是否亲密,因为发现并非所有案件都被正确分类。
1. 特征工程—标记“亲密”
全国安全社区网络将“亲密关系”定义为目前或以前的任何密切关系。 这包括结婚,约会或者一起生孩子。使用数据集中的各种列,我通过定义python函数设计了监督功能“亲密关系”:

2. 选择一个模型
现在我已经对每个案例做了标记(“亲密”/“非亲密”),我需要建立一个分类模型。出于多种原因,我决定采用Logistic回归模型,对多项式朴素贝叶斯(Multinomial Naive Bayes)分类器进行建模:
由于训练规模较小,生成的朴素贝叶斯(Naive Bayes)模型将超越本文Andrew Ng所述的判别性Logistic回归模型;
朴素贝叶斯(Naive Bayes)及其独立特征的假设使得模型更简单,更普通,因此变体更少;
朴素贝叶斯(Naive Bayes)因其用于文本数据和垃圾邮件检测而名声鹤唳。
增加最后一点非常有趣的,提供的数据集包含了现场警官的文字叙述。 我们可以通过警官叙述的词语选择来检测亲密关系吗?我决定找出答案。
3. 自然语言处理
为了运行朴素贝叶斯分类器(Multinomial Naive Bayes classifier),我需要首先清理文本数据。 在Python中使用NLTK模块,采取了以下步骤:
标记叙述(使用RegexpTokenizer)
删除无用词(使用无用词)
应用词形(使用WordNetLemmatizer)
由此产生的叙述看起来像这样:

处理完文本之后,我将标记化和词元化的叙述转换为一个交易对象,其中每个单词都是自己的特征,每一行都是叙述或“文档”。 这也可以被称为“文档术语矩阵”。
4. 降维
文档术语矩阵生成了3,805个特征。 为了减少这一点,以提高我们的模型的准确性,不够频繁的特征被删除。通过使用验证集合,我得出结论,删除所有出现少于两次的单词就足够了。这已经将维度降低到1861个特征。
5. 调整多项式朴素贝叶斯(Multinomial Naive Bayes)
多项式朴素贝叶斯分类器(Multinomial Naive Bayes classifier)默认将alpha设置为1. Alpha是一个平滑参数,用于处理出现在未在训练集中训练的保留集中的单词。 使用GridSearchCV,alpha被调整为2.53。
6. 模型评估
在用α= 2.53重置多项式朴素贝叶斯(Multinomial Naive Bayes)并将数据分解成训练集和测试集后,结果出人意料地好。
训练精度:84%
测试精度:81%
混合矩阵如下:

7. 结论
总之,该模型的真阳性,即敏感性为80.4%(82 /(82 + 20)),该模型的真阴性又称特异性为82.4%(14 /(3 + 14))。两者都远超我的预期,由于叙述为许多不同的警官所写,而每个警官都有自己的写作风格。但是模型显示,无论警官是谁,处理亲密案件时,都会倾向于频繁地使用某些关键词。这才是该模型性能的关键。
尾语
希望上述模型能够被我们的社区广泛使用。聚类可以非常有帮助,特别是当我们没有足够的数据为我们的案例提供标签时。它可以让我们快速了解嫌疑人是什么样的(实际上我更愿意称他们为病人)。 鉴于我们确实有足够数据的幸运情况,朴素贝叶斯分类器可以大大减少将潜在患者筛选到治疗计划所需的时间。早期发现早期干预可以减少我们社区中的暴力案件,这只是数据科学可以做的许多有价值的事情之一。迫不及待想要看看还有什么事情可以做!
关于作者
Kenny Moy,Kenny在为市场营销,医疗保健,房地产和公共服务等行业提供数据驱动解决方案方面有多年经验。除了机器学习外,他热爱顿悟时刻,讲故事,以及数据科学的创造性。
原文标题:Clustering Criminal Behavior and Classifying Intimate Partner Violence
原文链接:https://nycdatascience.com/blog/ student-works/clustering-criminal-behavior-and-classifying-intimate-partner-violence/
译者简介

白静,英语专业硕士在读,爱好翻译。希望能在数据派多多了解与大数据有关的知识,结识更多热爱翻译的朋友。
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THU ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织




