![]()
©PaperWeekly 原创 · 作者|熊志伟
学校|清华大学
研究方向|自然语言处理
BERT 自 2018 年被提出以来,获得了很大的成功和关注。基于此,学术界陆续提出了各类相关模型,以期对 BERT 进行改进。本文尝试对此进行汇总和梳理。
![]()
![]()
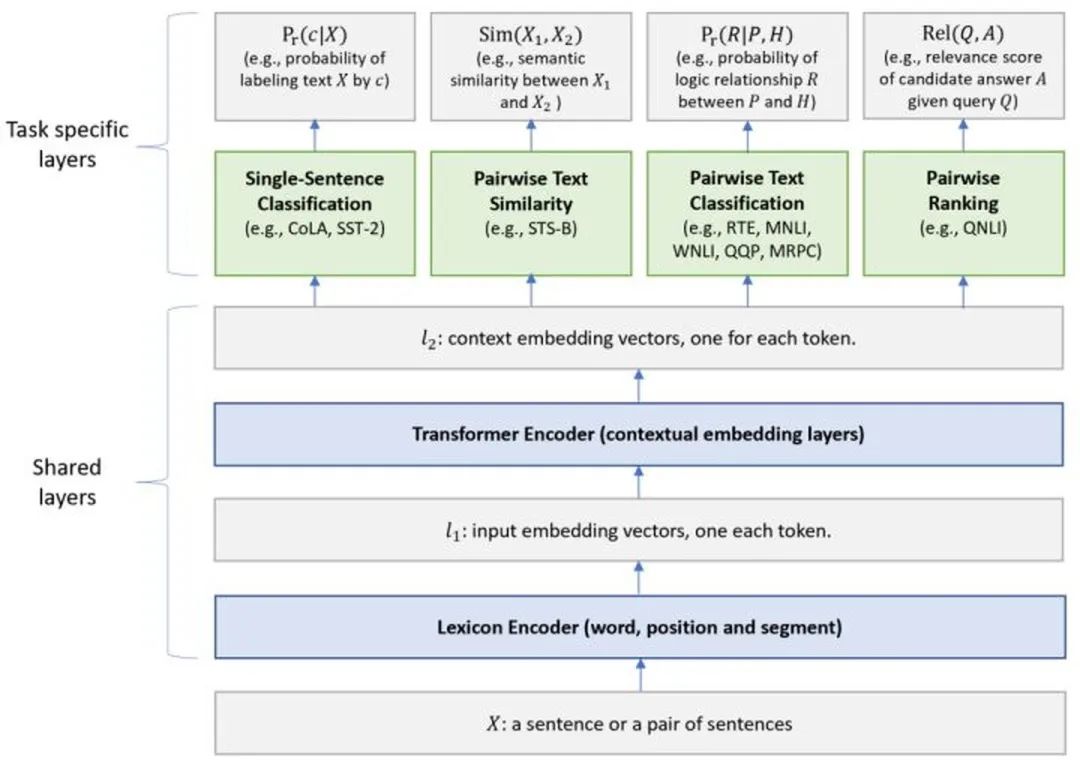
MT-DNN
MT-DNN(Multi-Task DNN)在 Microsoft 于 2019 年发表的《Multi-Task Deep Neural Networks for Natural Language Understanding》中被提出。
![]()
模型整体是个 MTL(Multi-Task Learning)框架,底层的 Shared layers 复用了 BERT 的结构,为所有 task 所共有,顶层的 Task specific layers 则为单个 task 所独有。总体来看,和 BERT 差异不大,区别仅在于 Pre-training 阶段,MT-DNN 加入了 multi-task 进行训练,期望学习到更好的 text representations(图中的
![]() )。
)。
-
标注数据较少的任务,可以利用其它相似任务的标注数据
降低针对特定任务的过拟合,起到正则化的作用
MT-DNN 引入了 4 中不同类型的 task,并相应设计了不同的 loss function:
Single-Sentence Classification:
选用了 [CLS] 在
![]() 层对应的输出,loss function 是交叉熵;
Text Similarity:
选用了 [CLS] 在
层对应的输出,loss function 是交叉熵;
Text Similarity:
选用了 [CLS] 在
![]() 层对应的输出,loss function 是 MSE(建模为回归问题);
Pairwise Text Classification:
输出后接了一个SAN(Stochastic Answer Network),loss function 是交叉熵;
Relevance Ranking:
选用了 [CLS] 在
层对应的输出,loss function 是 MSE(建模为回归问题);
Pairwise Text Classification:
输出后接了一个SAN(Stochastic Answer Network),loss function 是交叉熵;
Relevance Ranking:
选用了 [CLS] 在
![]() 层对应的输出,loss function 采用 LTR 的训练范式。
MT-DNN 的 Pre-training 部分包括两个阶段:第一阶段,采用 BERT 的训练方式(MLM+NSP),学习 Shared layers 的参数;第二阶段,采用 MTL 的方式,学习 Shared layers+Task specific layers 的参数,论文中此处采用的是 9 项 GLUE 的 task。详细的训练步骤描述如下:
层对应的输出,loss function 采用 LTR 的训练范式。
MT-DNN 的 Pre-training 部分包括两个阶段:第一阶段,采用 BERT 的训练方式(MLM+NSP),学习 Shared layers 的参数;第二阶段,采用 MTL 的方式,学习 Shared layers+Task specific layers 的参数,论文中此处采用的是 9 项 GLUE 的 task。详细的训练步骤描述如下:
![]()
论文中,作者采用了
![]() 作为 Shared layers 的初始化,并且证明,即使没有 fine-tuning 阶段,MT-DNN 的效果也要好于
作为 Shared layers 的初始化,并且证明,即使没有 fine-tuning 阶段,MT-DNN 的效果也要好于
![]() 。
总的来说,MT-DNN 相对于 BERT 的提升,来自于 MTL 和 special output module(输出模块和 loss function 设计更复杂)。
。
总的来说,MT-DNN 相对于 BERT 的提升,来自于 MTL 和 special output module(输出模块和 loss function 设计更复杂)。
![]()
XLNet
XLNet 在 CMU+Google 于 2019 年发表的《XLNet: Generalized Autoregressive Pretraining for Language Understanding》中被提出。
论文中,作者提到了两种 Pre-training 的方式:AR(autoregressive language modeling)、AE(denoising autoencoding)。前者的代表如 ELMo、GPT 系列,后者的代表则是 BERT。
为了解决 BERT 面临的问题,XLNet 做了如下改进:
-
Pre-training的训练目标调整为PLM (Permutation Language Modeling),具体实现时采用了 Two-Stream Self-Attention 机制,并对可能的排列进行了采样
-
模型结构采用 Transformer-XL,解决 Transformer 对长文档不友好的问题
采用更优质更大规模的语料
![]()
RoBERTa
RoBERTa 在华盛顿大学 +Facebook 于 2019 年发表的《RoBERTa: A Robustly Optimized BERT Pretraining Approach》中被提出。
1. 训练时间更长:
更大规模的训练数据(16GB -> 160GB)、更大的 batch_size(256 -> 8K);
2. 去除 NSP 任务,输入格式相应修改为 FULL-SENTENCES;
3. 输入粒度:
由 character-level BPE 改为 byte-level BPE;
4. masking 机制:由 static masking改为dynamic masking:
![]()
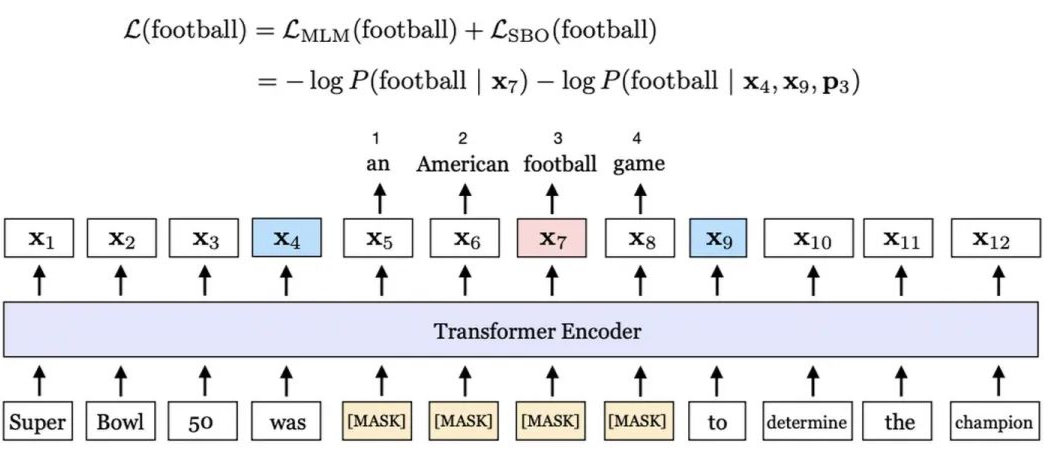
SpanBERT
SpanBERT 在华盛顿大学+普林斯顿大学于 2019 年发表的《SpanBERT: Improving Pre-training by Representing and Predicting Spans》中被提出。
![]()
1. Span Masking:首先根据几何分布
![]() 采样出 span 的长度(大于 10 则重新采样),然后根据均匀分布随机选择起始点,最后从起始点开始将 span 内的 token 进行 mask;注意,这个过程会进行多次,直到被 mask 的 token 数量达到阈值,如输入序列的 15%;
2. Span Boundary Objective(SBO):对于 span 内的每一个 token,除了原始的 MLM 的 loss,再加 SBO 的 loss,即:
3. Single-Sequence Training:
去掉 NSP 任务,用一个长句替代原来的两个句子。
采样出 span 的长度(大于 10 则重新采样),然后根据均匀分布随机选择起始点,最后从起始点开始将 span 内的 token 进行 mask;注意,这个过程会进行多次,直到被 mask 的 token 数量达到阈值,如输入序列的 15%;
2. Span Boundary Objective(SBO):对于 span 内的每一个 token,除了原始的 MLM 的 loss,再加 SBO 的 loss,即:
3. Single-Sequence Training:
去掉 NSP 任务,用一个长句替代原来的两个句子。
![]()
ALBERT
ALBERT 在 Google于 2019 年发表的《ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS》中被提出。
ALBERT 的出发点在于,如果模型参数持续变大,会出现两类问题:GPU/TPU OOM;模型效果退化。基于此,ALBERT 考虑减少模型的参数。
1. Factorized embedding parameterization:之前的模型中,都会使
![]() (E 是 vocabulary embedding size,H 是 hidden size),如此一来,H的提升会导致E的提升,从而使参数量呈平方级的增加。ALBERT 将 E 和 H 解绑,在 embedding 后再接一个
(E 是 vocabulary embedding size,H 是 hidden size),如此一来,H的提升会导致E的提升,从而使参数量呈平方级的增加。ALBERT 将 E 和 H 解绑,在 embedding 后再接一个
![]() 的矩阵,这样可以保持 E 不变的情况下提升 H。在这种情况下,参数量由
的矩阵,这样可以保持 E 不变的情况下提升 H。在这种情况下,参数量由
![]() 降低至
降低至
![]() ,当
,当
![]() 时,效果更加显著;
2. Cross-layer parameter sharing:
将 Transformer Encoder 中每一个 layer 的参数进行共享,也即,每个 layer 复用同一套参数;
3. Inter-sentence coherence loss:
将 NSP 替换为 SOP(sentence-order prediction),即从同一个文档中抽取两个连续的句子作为正样本,调换顺序后作为负样本(NSP 的负样本来自两个不同的文档);
时,效果更加显著;
2. Cross-layer parameter sharing:
将 Transformer Encoder 中每一个 layer 的参数进行共享,也即,每个 layer 复用同一套参数;
3. Inter-sentence coherence loss:
将 NSP 替换为 SOP(sentence-order prediction),即从同一个文档中抽取两个连续的句子作为正样本,调换顺序后作为负样本(NSP 的负样本来自两个不同的文档);
4. 采用更大规模的训练数据并去除 Dropout(因为作者发现模型仍然没有过拟合)。
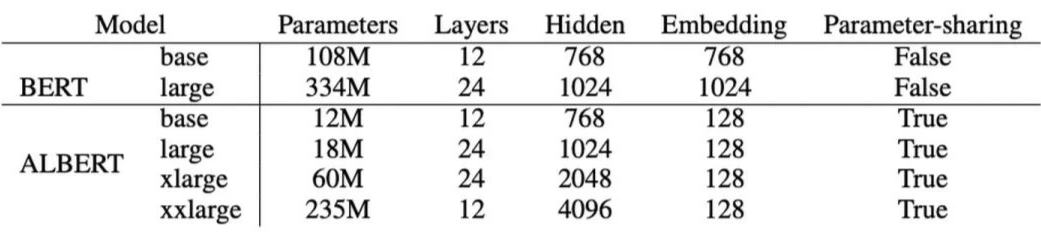
ALBERT 和 BERT 在不同配置下的参数量如下:
![]()
ALBERT 和 BERT 在不同配置下的效果和训练时间如下:
![]()
注意,这里的 Speedup 指的是训练时间而非推理时间,因为 ALBERT 的优化点主要在于降低参数量,这可以加速训练,但是模型层数并没有变化,所以推理时间不受影响。
![]()
MASS
MASS 在 Microsoft 于 2019 年发表的《MASS: Masked Sequence to Sequence Pre-training for Language Generation》中被提出。
像 BERT 这类基于 Pre-training 和 fine-tuning 的模型在 NLU(Natural Language Understanding)任务中取得了很大的成功。与之相对应地,NLG(Natural Language Generation)任务如 neural machine translation(NMT)、text summarization 和 conversational response generation 等,经常面临着训练数据(paired data)匮乏的问题。
因此,在大量 unpaired data 上做 pre-training 然后在少量 paired data 上做 fine-tuning,对 NLU 任务而言是同样有益的。然而,直接采用类似 BERT 的预训练结构(仅用 encoder 或 decoder)是不可取的,因为 NLG 任务通常是基于 encoder-decoder 的框架。基于此,论文提出了一种适用于 NLG 任务的预训练方式——MASS。
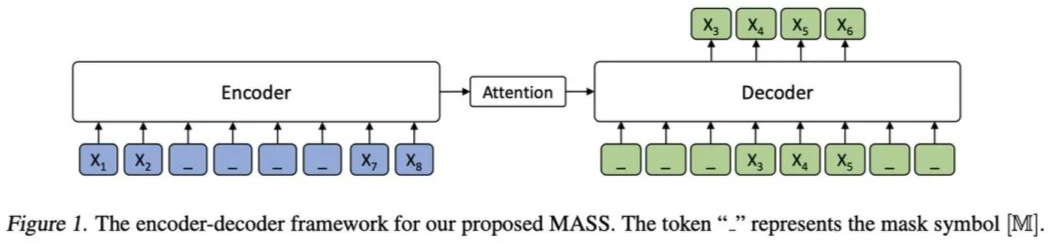
区别于单独对 encoder 或 decoder 进行 pre-training,MASS 可以对二者进行联合 pre-training,其结构如下:
![]()
整体基于 Transformer,Encoder 被 mask 的 token 是连续的,Decoder 将 Encoder 中未被 mask 的 token 进行 mask,预测 Encoder 中被 mask 的 token。
论文中提到,通过控制 Encoder 中 mask 的 token 长度 k,BERT 和 GPT 可看作是 MASS 的特例:
![]()
![]()
UNILM
UNILM 在 Microsoft 于 2019 发表的《Unified Language Model Pre-training for Natural Language Understanding and Generation》中被提出。
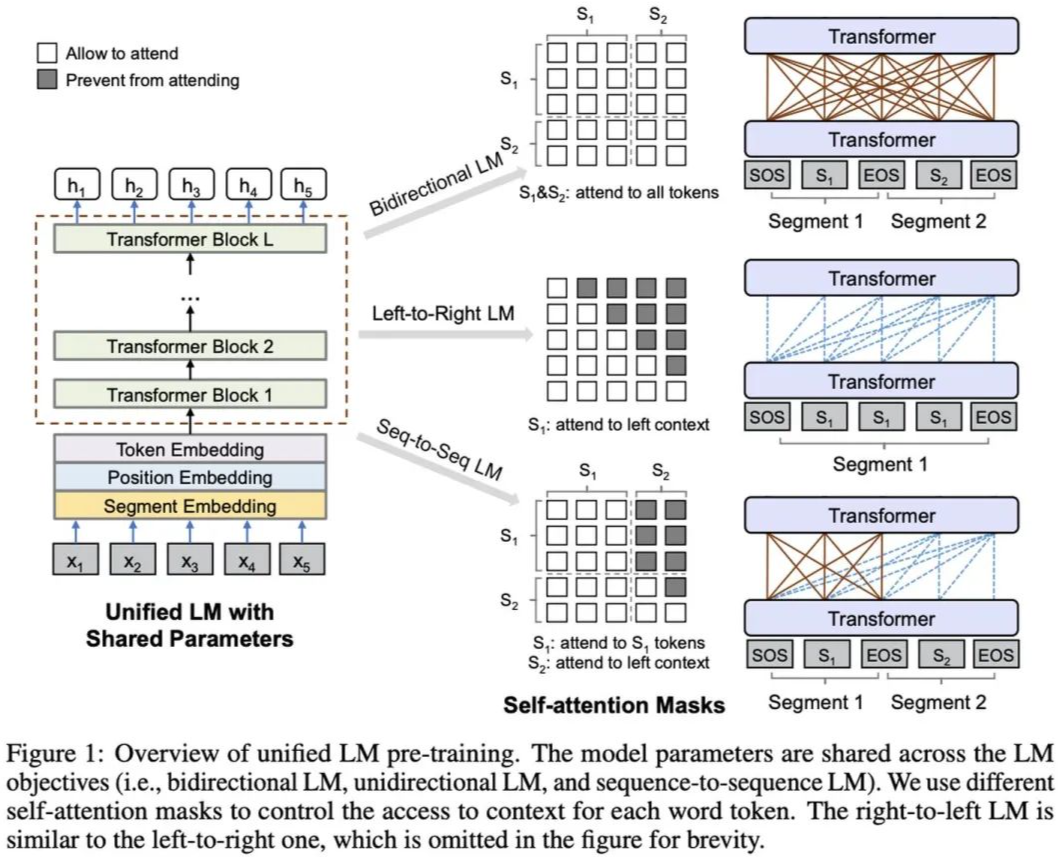
UNILM 是一种能同时适用于 NLU 和 NLG 任务的 Pre-training 框架,基于参数共享的 Transformer,对三种类型的无监督语言建模目标进行联合预训练:Unidirectional LM(left-to-right && right-to-left)、Bidirectional LM、Sequence-to-Sequence LM。预训练后的 UNILM 可以进行 Fine-tuning(如有必要可添加 task-specific layers)以适应不同类型的下游任务。
![]()
对于不同类型的 LM 目标,所使用的 segment embedding 不同,以示区分
-
对于所有类型的 LM 目标,预训练采用的任务都是 cloze task,有所区分的是,不同的 LM 它们所能利用到的 context 不同:Unidirectional LM,context 是单侧的 token(左侧 or 右侧);Bidirectional LM,context 是两侧的 token;Sequence-to-Sequence LM,context 是源序列的所有 token 以及目标序列的左侧 token。不同的 context 是通过相应的 mask 矩阵来实现的
对于 Bidirectional LM,加入了 NSP 任务
对于 Sequence-to-Sequence LM,在 Pre-training 阶段,源序列和目标序列都有可能被 mask
在一个 batch 中,1/3 的时间采用 Bidirectional LM,1/3 的时间采用 Sequence-to-Sequence LM,1/6 的时间采用 left-to-right Unidirectional LM,1/6 的时间采用 right-to-left Unidirectional LM
-
80% 的时间 mask 一个 token,20% 的时间 mask一个bigram 或 trigram
对于 NLU 任务,同 BERT
-
对于 NLG 任务,若是 Seq2Seq 任务,则只 mask 目标序列中的 token
-
统一的预训练流程让单个 Transformer 能为不同类型的语言模型使用共享的参数和架构,从而减轻对分开训练和管理多个语言模型的需求
-
参数共享使得学习到的文本表征更通用,因为它们针对不同的语言建模目标(其中利用上下文的方式各不相同)进行了联合优化,这能缓解在任意单个语言模型任务上的过拟合
-
除了在 NLU 任务上的应用,作为 Sequence-to-Sequence LM 使用的 UNILM 也使其能自然地用于 NLG 任务,比如抽象式摘要和问答
![]()
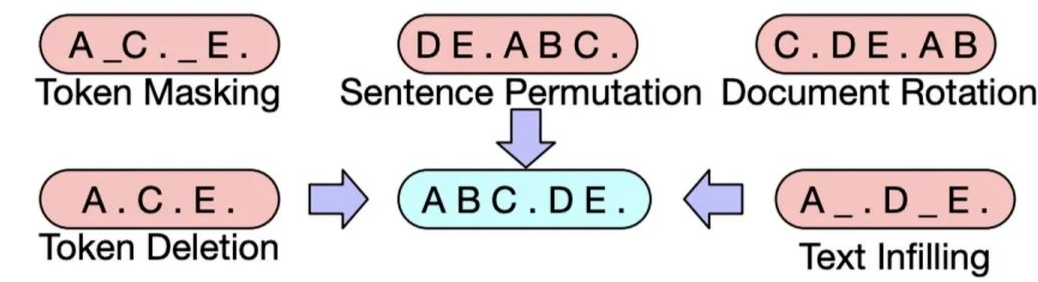
BART
BART在Facebook于2019年发表的《BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension》中被提出。
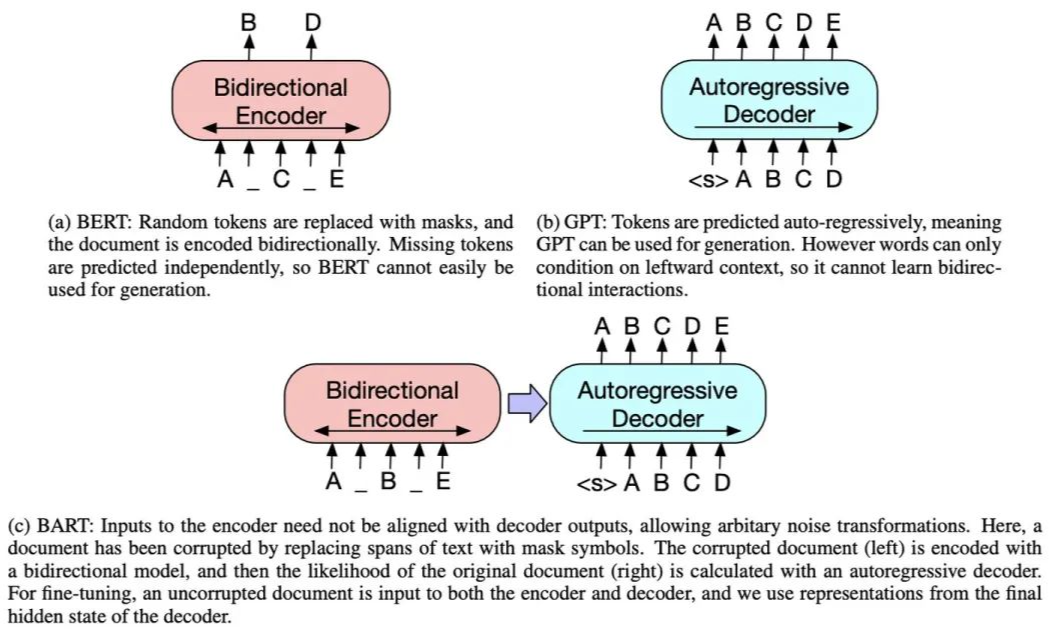
BART 采用了 Transformer 的 Seq2Seq 框架,和 MASS 类似,只不过它的 Pre-training 任务是:在 Encoder 端输入被破坏的文本,在 Decoder 端复原原始文本。
![]()
![]()
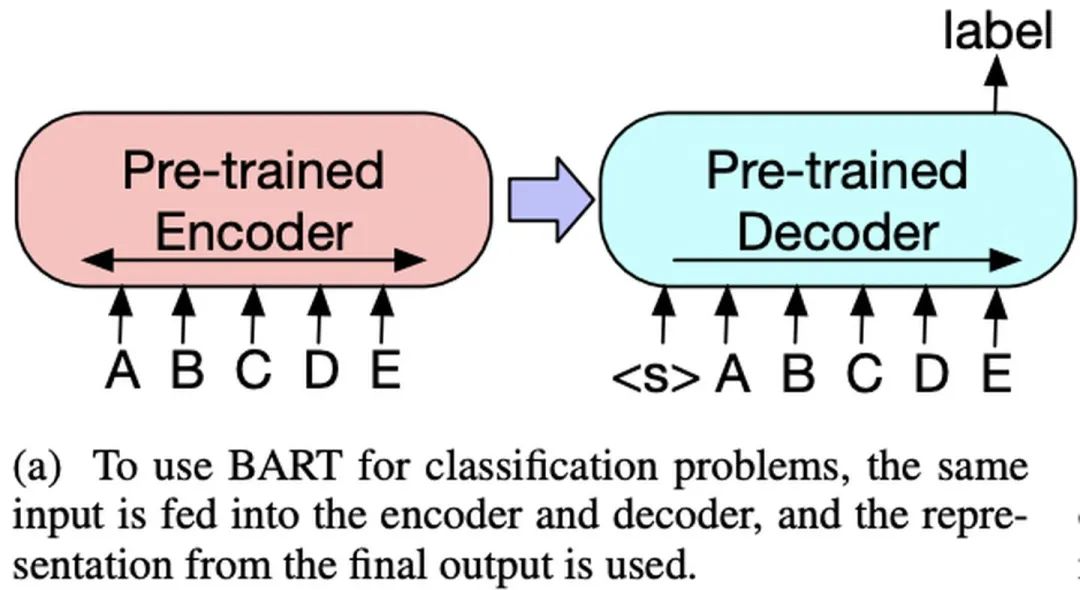
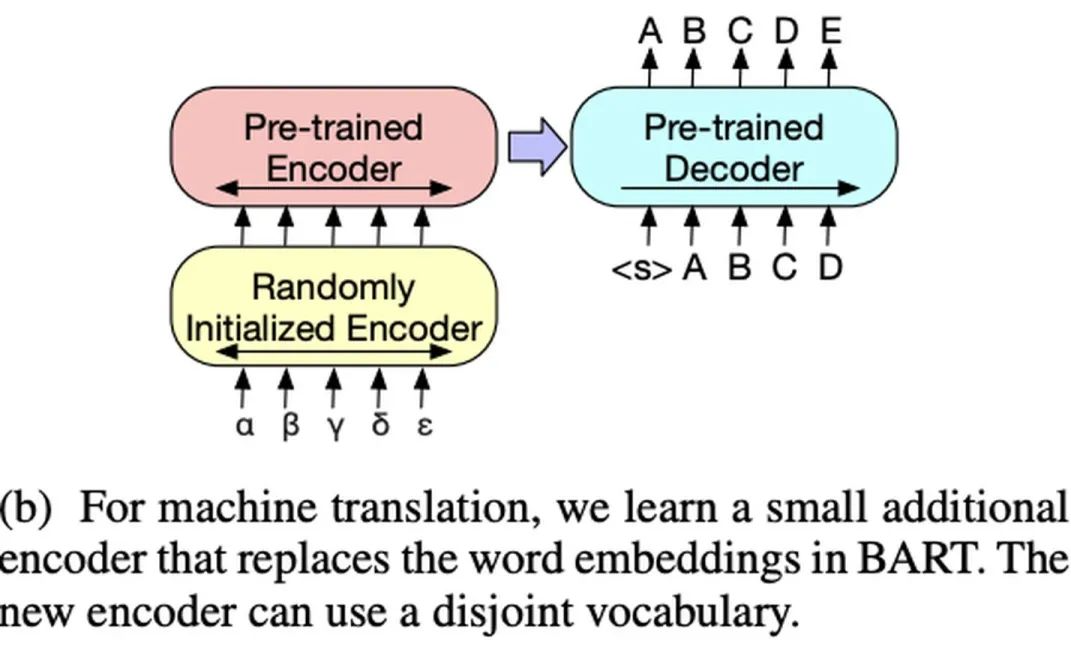
-
Sequence Classification Tasks:
![]()
![]() [1]
https://arxiv.org/pdf/1901.11504.pdf
[1]
https://arxiv.org/pdf/1901.11504.pdf
[2]
https://fyubang.com/2019/05/23/mt-dnn/
[3]
https://zhuanlan.zhihu.com/p/103220246
[4] https://zhpmatrix.github.io/2019/08/08/mt-dnn/
[5] https://blog.csdn.net/magical_bubble/article/details/89517709
[6]
https://arxiv.org/pdf/1906.08237.pdf
[7]
https://medium.com/ai-academy-taiwan/2019-nlp%E6%9C%80%E5%BC%B7%E6%A8%A1%E5%9E%8B-xlnet-ac728b400de3
[8] http://fancyerii.github.io/2019/06/30/xlnet-theory/
[9] http://fancyerii.github.io/2019/06/30/xlnet-theory/
[10]
https://arxiv.org/pdf/1907.11692.pdf
[11] https://blog.csdn.net/ljp1919/article/details/100666563
[12] https://www.jiqizhixin.com/articles/2019-09-05-6
[13]
https://arxiv.org/pdf/1909.11942.pdf
[14] https://cloud.tencent.com/developer/article/1682418
[15] https://zhuanlan.zhihu.com/p/85221503
[16]
https://arxiv.org/pdf/1907.10529.pdf
[17] https://zhuanlan.zhihu.com/p/75893972
[18] https://zhuanlan.zhihu.com/p/149707811
[19]
https://arxiv.org/pdf/1905.02450.pdf
[20] https://easyai.tech/blog/mass-bert-gpt/
[21] https://zhuanlan.zhihu.com/p/67687640
[22] https://blog.csdn.net/ljp1919/article/details/90312229
[23] https://www.zhihu.com/question/324019899
[24]
https://arxiv.org/pdf/1905.03197.pdf
[25] https://zhuanlan.zhihu.com/p/68327602
[26] https://www.jiqizhixin.com/articles/2019-12-09-16
[27] https://blog.csdn.net/qq_42189083/article/details/104413886
[28] https://cloud.tencent.com/developer/article/1580364
[29] https://zhuanlan.zhihu.com/p/113380840
[30]
https://arxiv.org/pdf/1910.13461.pdf
[31]
https://www.mdeditor.tw/pl/pLHV
[32] https://zhuanlan.zhihu.com/p/90173832
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()


 )。
)。

 作为 Shared layers 的初始化,并且证明,即使没有 fine-tuning 阶段,MT-DNN 的效果也要好于
作为 Shared layers 的初始化,并且证明,即使没有 fine-tuning 阶段,MT-DNN 的效果也要好于



 采样出 span 的长度(大于 10 则重新采样),然后根据均匀分布随机选择起始点,最后从起始点开始将 span 内的 token 进行 mask;注意,这个过程会进行多次,直到被 mask 的 token 数量达到阈值,如输入序列的 15%;
采样出 span 的长度(大于 10 则重新采样),然后根据均匀分布随机选择起始点,最后从起始点开始将 span 内的 token 进行 mask;注意,这个过程会进行多次,直到被 mask 的 token 数量达到阈值,如输入序列的 15%;


 (E 是 vocabulary embedding size,H 是 hidden size),如此一来,H的提升会导致E的提升,从而使参数量呈平方级的增加。ALBERT 将 E 和 H 解绑,在 embedding 后再接一个
(E 是 vocabulary embedding size,H 是 hidden size),如此一来,H的提升会导致E的提升,从而使参数量呈平方级的增加。ALBERT 将 E 和 H 解绑,在 embedding 后再接一个
 的矩阵,这样可以保持 E 不变的情况下提升 H。在这种情况下,参数量由
的矩阵,这样可以保持 E 不变的情况下提升 H。在这种情况下,参数量由
 降低至
降低至
 ,当
,当
 时,效果更加显著;
时,效果更加显著;