国科大UCAS胡包钢教授《信息论与机器学习》课程第二讲:信息论基础一
【导读】香农1948年发表的论文“通信的数学理论”不仅奠定了现代信息论的基础,他直接将通信工程问题抽象为数学理论问题的方法论特别值得学习。这实例充分说明智能本质的揭示或对大脑的深度认知最后是依赖数学层面上的描述。







































英国对口相声“热力学第一和第二定律”说明




专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ITML2020” 就可以获取《国科大UCAS《信息论与机器学习》课件》专知下载链接


登录查看更多
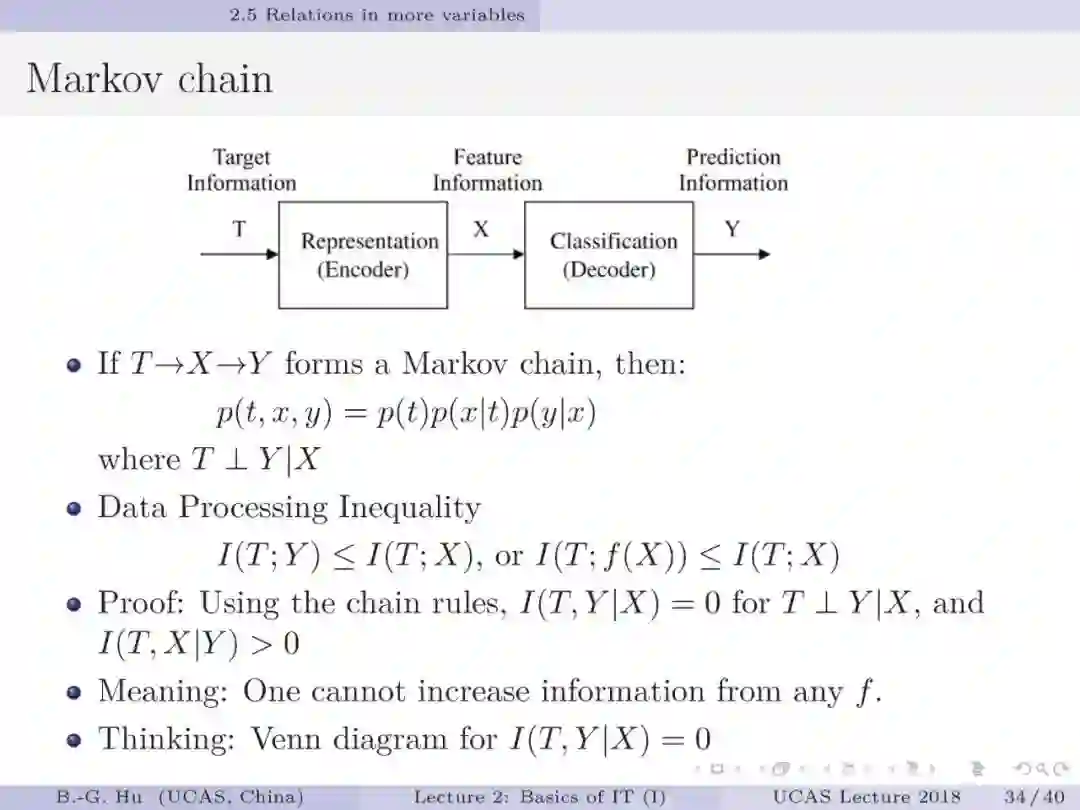
相关内容

中国科学院自动化研究所模式识别国家重点实验室研究员, 博士生导师。1983年在北京科技大学(原北京钢铁学院) 获工学硕士。1993年在加拿大McMaster大学获哲学博士学位。1997年9月回国前在加拿大Memorial University of Newfoundland, C-CORE研究中心担任高级研究工程师。目前为中国科学院北京研究生院教授。2000-2005年任中法信息、自动化、应用数学联合实验室 (LIAMA)中方主任。
胡包钢博士曾担任过“IEEE系统-人-控制国际会议(IEEE International Conference on Systems, Man and Cybernetics)” 1995年及1998年的分会主席,2001年国际程序委员会委员, “1998年世界控制大会,第二届智能自动化和控制国际专题会议(WAC’98: The 2nd International Symposium on Intelligent Automation and Control)” 的国际程序委员会委员,2003年“植物生长建模、仿真、可视化及其应用国际专题会议”(PMA03)大会主席。他担任过专业刊物论文评审人的杂志有“IEEE Transactions on Systems, Man and Cybernetics”, “IEEE Transactions on Fuzzy Systems”, “Engineering Applications of Artificial Intelligence”, “自动化学报”, “控制理论与应用”等。
http://www.escience.cn/people/hubaogang/index.html
Arxiv
4+阅读 · 2019年4月15日



相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年4月15日