我用Python爬了4400条淘宝商品数据,竟发现了这些“潜规则”
本文记录了笔者用 Python 爬取淘宝某商品的全过程,并对商品数据进行了挖掘与分析,最终得出结论。

项目内容
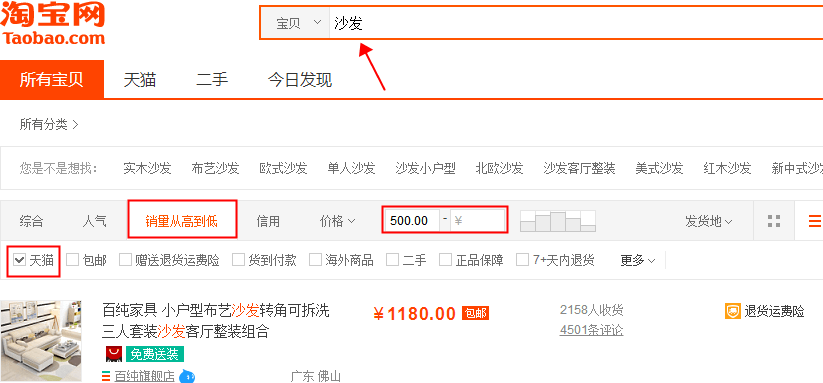
本案例选择商品类目:沙发。
数量:共 100 页 4400 个商品。
筛选条件:天猫、销量从高到低、价格 500 元以上。
项目目的
对商品标题进行文本分析,词云可视化
不同关键词 word 对应的 sales 的统计分析
商品的价格分布情况分析
商品的销量分布情况分析
不同价格区间的商品的平均销量分布
商品价格对销量的影响分析
商品价格对销售额的影响分析
不同省份或城市的商品数量分布
不同省份的商品平均销量分布
注:本项目仅以以上几项分析为例。
项目步骤
数据采集:Python 爬取淘宝网商品数据
对数据进行清洗和处理
文本分析:jieba 分词、wordcloud 可视化
数据柱形图可视化:barh
数据直方图可视化:hist
数据散点图可视化:scatter
数据回归分析可视化:regplot
工具&模块
工具:本案例代码编辑工具 Anaconda 的 Spyder。
模块:requests、retrying、missingno、jieba、matplotlib、wordcloud、imread、seaborn 等。
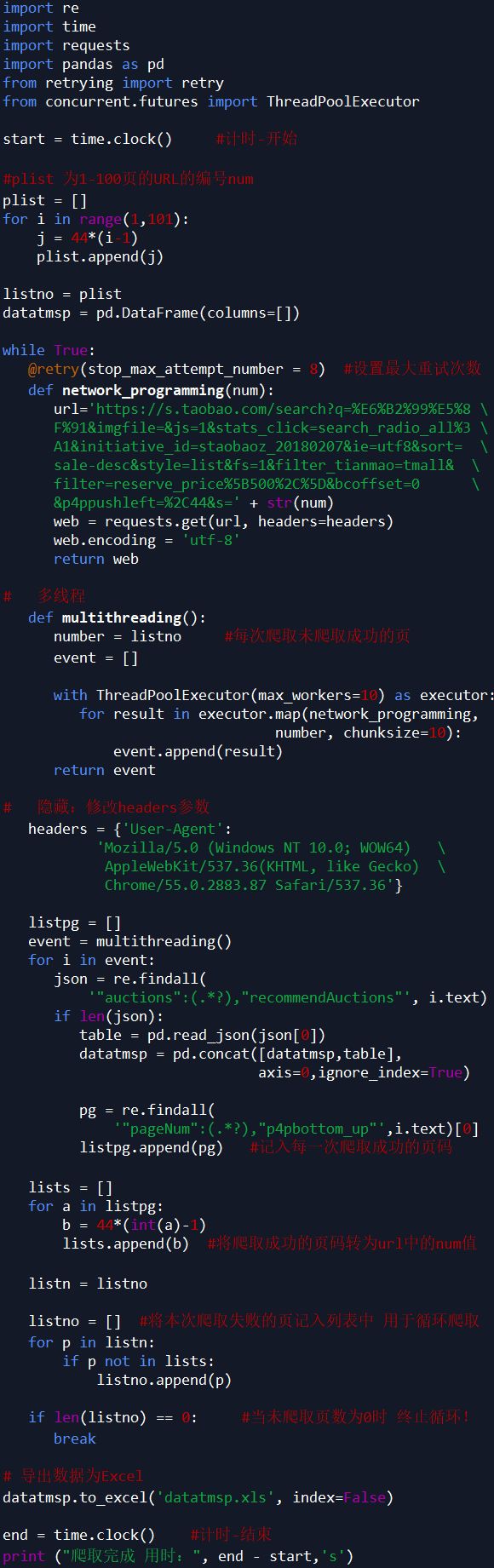
爬取数据
因淘宝网是反爬虫的,虽然使用多线程、修改 headers 参数,但仍然不能保证每次 100% 爬取,所以我增加了循环爬取,每次循环爬取未爬取成功的页 ,直至所有页爬取成功停止。
说明:淘宝商品页为 JSON 格式,这里使用正则表达式进行解析。
代码如下:
数据清洗、处理
数据清洗、处理这个步骤也可以在 Excel 中完成,再读入数据。
代码如下:
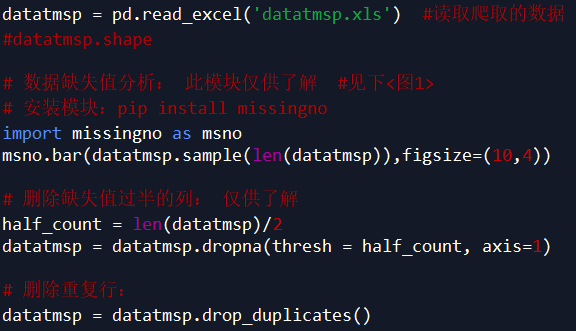
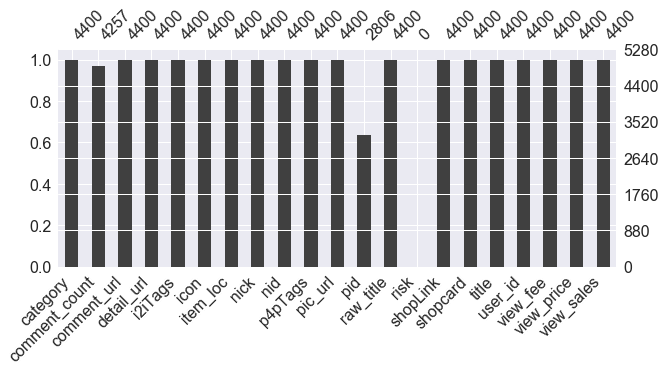
说明:根据需求,本案例中只取了 item_loc,raw_title,view_price,view_sales 这 4 列数据,主要对区域、标题、价格、销量进行分析。
代码如下:
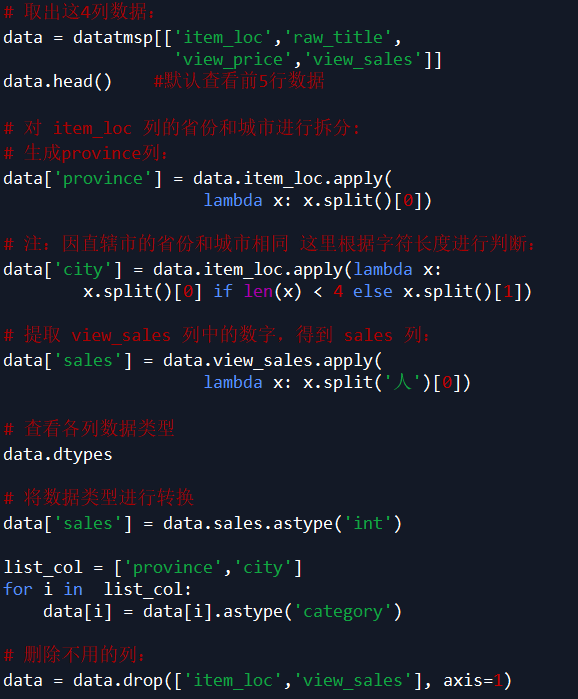
数据挖掘与分析
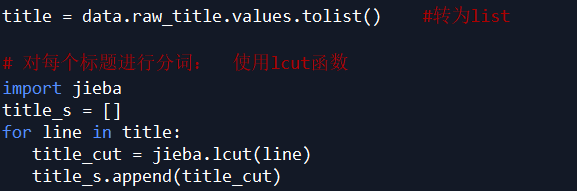
对 raw_title 列标题进行文本分析
使用结巴分词器,安装模块 pip install jieba:
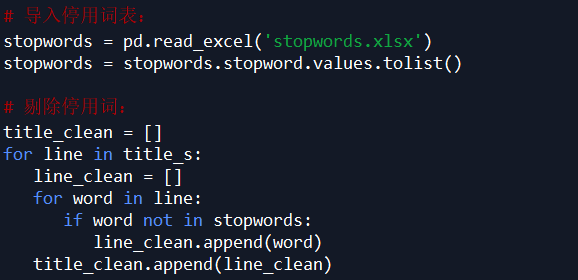
对 title_s(list of list 格式)中的每个 list 的元素(str)进行过滤,剔除不需要的词语,即把停用词表 stopwords 中有的词语都剔除掉:
因为下面要统计每个词语的个数,所以为了准确性,这里对过滤后的数据 title_clean 中的每个 list 的元素进行去重,即每个标题被分割后的词语唯一。
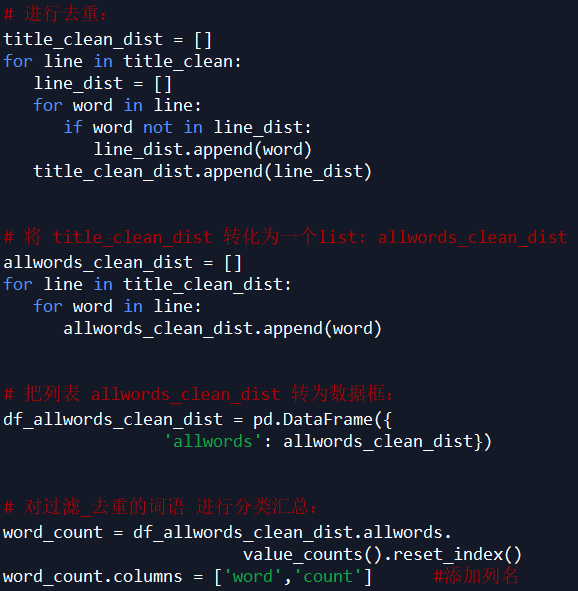
观察 word_count 表中的词语,发现 jieba 默认的词典无法满足需求。
有的词语(如可拆洗、不可拆洗等)却被 cut,这里根据需求对词典加入新词(也可以直接在词典 dict.txt 里面增删,然后载入修改过的 dict.txt)。
词云可视化需要安装 wordcloud 模块。
安装模块有两种方法:
pip install wordcloud
下载 Packages 安装:pip install 软件包名称
软件包下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
注意:要把下载的软件包放在 Python 安装路径下。
代码如下:

分析结论:
组合、整装商品占比很高。
从沙发材质看:布艺沙发占比很高,比皮艺沙发多。
从沙发风格看:简约风格最多,北欧风次之,其他风格排名依次是美式、中式、日式、法式等。
从户型看:小户型占比最高、大小户型次之,大户型最少。
不同关键词 word 对应的 sales 之和的统计分析
说明:例如词语“简约”,则统计商品标题中含有“简约”一词的商品的销量之和,即求出具有“简约”风格的商品销量之和。
代码如下:
对表 df_word_sum 中的 word 和 w_s_sum 两列数据进行可视化。(本例中取销量排名前 30 的词语进行绘图)
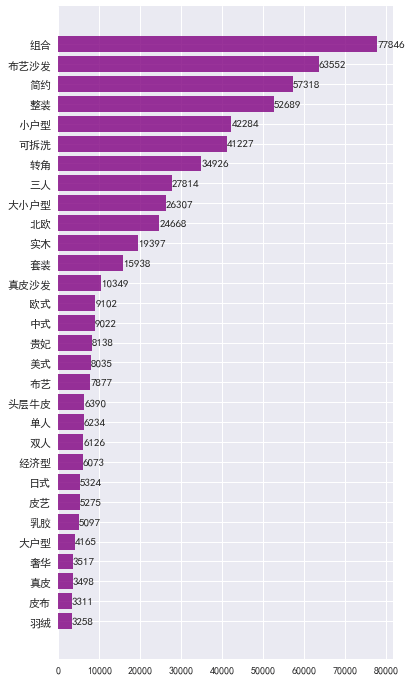
由图表可知:
组合商品销量最高。
从品类看:布艺沙发销量很高,远超过皮艺沙发。
从户型看:小户型沙发销量最高,大小户型次之,大户型销量最少。
从风格看:简约风销量最高,北欧风次之,其他依次是中式、美式、日式等。
可拆洗、转角类沙发销量可观,也是颇受消费者青睐的。
商品的价格分布情况分析
分析发现,有一些值太大,为了使可视化效果更加直观,这里我们结合自身产品情况,选择价格小于 20000 的商品。
代码如下:
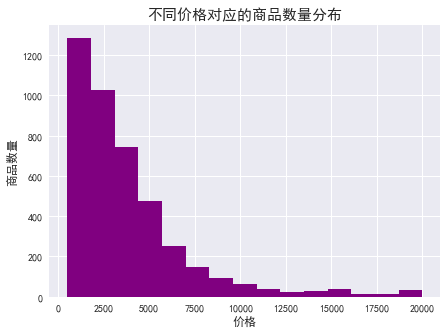
由图表可知:
商品数量随着价格总体呈现下降阶梯形势,价格越高,在售的商品越少。
低价位商品居多,价格在 500-1500 之间的商品最多,1500-3000 之间的次之,价格 1 万以上的商品较少。
价格 1 万元以上的商品,在售商品数量差异不大。
商品的销量分布情况分析
同样,为了使可视化效果更加直观,这里我们选择销量大于 100 的商品。
代码如下:
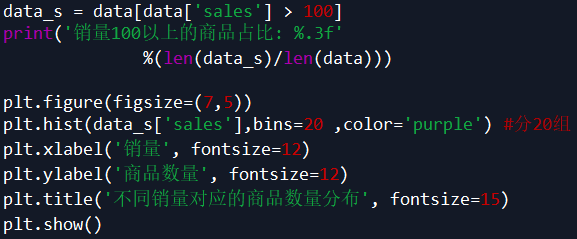
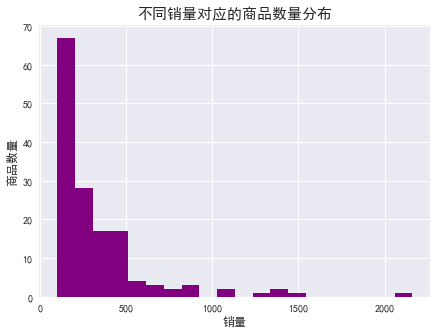
由图表及数据可知:
销量 100 以上的商品仅占 3.4% ,其中销量 100-200 之间的商品最多,200-300 之间的次之。
销量 100-500 之间,商品的数量随着销量呈现下降趋势,且趋势陡峭,低销量商品居多。
销量 500 以上的商品很少。
不同价格区间的商品的平均销量分布
代码如下:
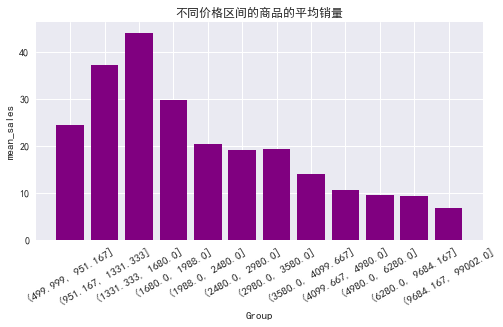
由图表可知:
价格在 1331-1680 之间的商品平均销量最高,951-1331 之间的次之,9684 元以上的最低。
总体呈现先增后减的趋势,但最高峰处于相对低价位阶段。
说明广大消费者对购买沙发的需求更多处于低价位阶段,在 1680 元以上价位越高,平均销量基本是越少。
商品价格对销量的影响分析
同上,为了使可视化效果更加直观,这里我们结合自身产品情况,选择价格小于 20000 的商品。
代码如下:

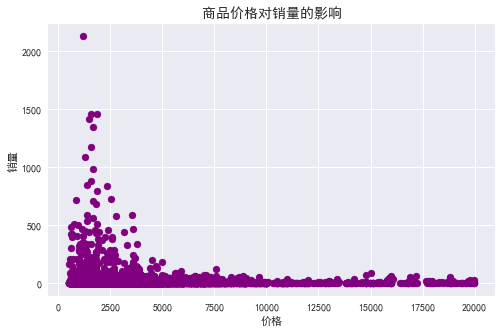
由图表可知:
总体趋势:随着商品价格增多,其销量减少,商品价格对其销量影响很大。
价格 500-2500 之间的少数商品销量冲的很高,价格 2500-5000 之间的商品多数销量偏低,少数相对较高,但价格 5000 以上的商品销量均很低,没有销量突出的商品。
商品价格对销售额的影响分析
代码如下:

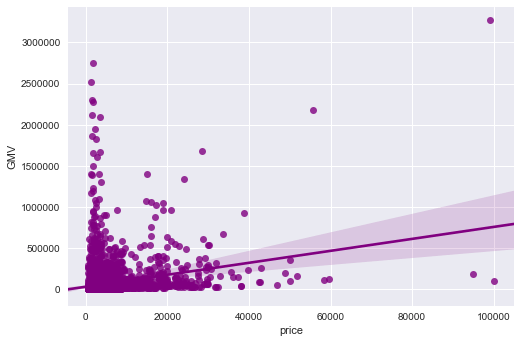
由图表可知:
总体趋势:由线性回归拟合线可以看出,商品销售额随着价格增长呈现上升趋势。
多数商品的价格偏低,销售额也偏低。
价格在 0-20000 的商品只有少数销售额较高,价格 2-6 万的商品只有 3 个销售额较高,价格 6-10 万的商品有 1 个销售额很高,而且是最大值。
不同省份的商品数量分布
代码如下:

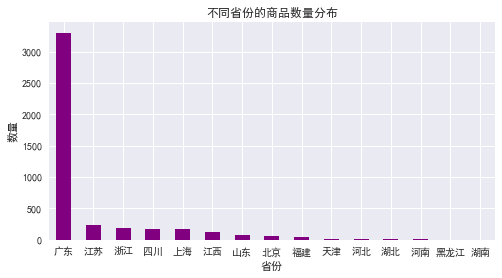
由图表可知:
广东的最多,上海次之,江苏第三,尤其是广东的数量远超过江苏、浙江、上海等地,说明在沙发这个子类目,广东的店铺占主导地位。
江浙沪等地的数量差异不大,基本相当。
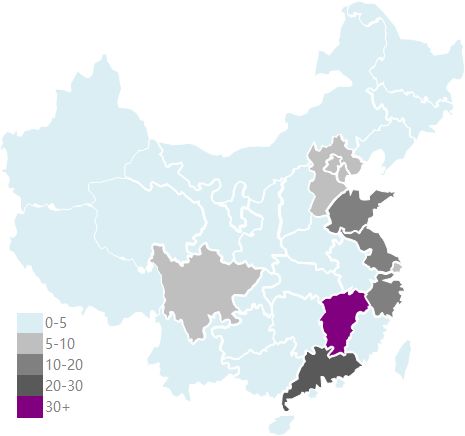
不同省份的商品平均销量分布
代码如下:
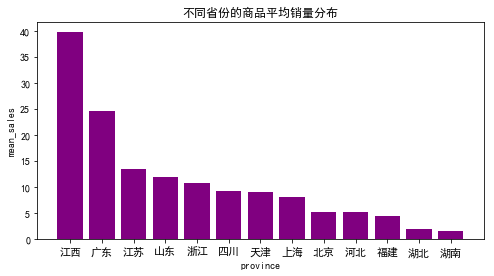
热力型地图
微信后台回复关键词“淘宝”下载源代码和相关文档
作者:孙方辉,从事数据分析工作,热爱数据统计与挖掘分析
编辑:陶家龙、孙淑娟
来源:转载自CDA数据分析师微信公众号

精彩文章推荐:





