数据分析师挣多少钱?我们“黑”了某招聘网站的数据,竟发现……
作者/ 魏凯
Udacity “数据分析师”纳米学位项目学员
从去年7月份开始学习Udacity的“数据分析师”纳米学位课程,到现在也算学了不少内容,接下来打算慢慢开始找工作了。既然想要从事数据分析师这个岗位,那自然首先需要对这个岗位有所了解。最直接、最真实的方式就是从企业那里获得需求讯息,这样才最能够指导自己的学习方向和简历准备。本次项目即是要利用爬虫爬取拉勾网上数据分析这一岗位的信息,然后进行一些探索和分析,以数据分析来了解‘数据分析’。
本项目所使用的数据集全部来自拉勾网,是通过集搜客这一网络爬虫工具来爬取的。集搜客是一款简洁易用且功能强大的网络爬虫产品,通过鼠标点选和简单的命令操作即可实现爬虫的定制和运行,这里也推荐一下。之所以选择拉勾网作为本项目的数据源,主要是因为相对于其他招聘网站,拉钩网上的岗位信息非常完整、整洁,极少存在信息的缺漏。并且几乎所有展现出来的信息都是非常规范化的,极大的减少了前期数据清理和数据整理的工作量。(笔者毕竟是工作之余完成,时间有限,能省则省)本次爬取信息的时候,主要获得了以下信息:
| 内容 | 字段 |
|---|---|
| 岗位名称 | title |
| 月薪 | month_salary |
| 公司名称 | company |
| 所属行业 | industry |
| 公司规模 | scale |
| 融资阶段 | phase |
| 投资人 | investors |
| 所在城市 | city |
| 经验要求 | experience |
| 学历要求 | qualification |
| 全职/兼职 | full_or_parttime |
| 职位描述及任职要求 | description |
主要是希望通过实际的数据来解答针对数据分析岗位的一些疑惑,Udacity数据分析师课程的童鞋一些参考性的意见。具体来说,主要针对以下几个问题:
- 数据分析师岗位需求的地域性分布;
- 整个群体中薪酬分布的情况;
- 不同城市数据分析师的薪酬情况是怎样的;
- 该岗位对于工作经验的要求是怎样的;
- 根据工作经验的不同,薪酬是怎样变化的;
- 从用人单位的角度看,数据分析师应当具备哪些技能?
- 掌握不同技能是否会对薪酬有影响?影响是怎样的?
本项目主要分为两大部分,第一部分是数据爬取,采用的是集搜客网络爬虫工具。第二部分是数据分析,以python编程语言为基础。数据分析部分主要使用pandas作为数据整理和统计分析的工具,matplotlib用于图形的可视化,seaborn库包用于图形美化。在进行技能需求分析的时候,使用了jieba作为分词工具包,并使用wordcloud包制作词云。
加载和清理
* 点击图片缩略图可放大,下同。

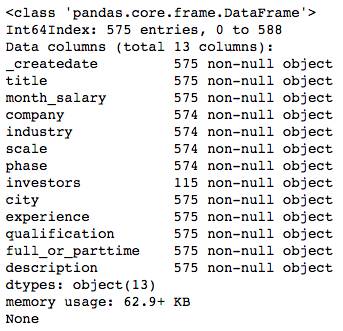
可以看到,经过初步清理后,数据集中有效变量为13个,数据记录575条。除了投资人这一项之外,其他各字段的数据完整度非常好,几乎没有缺失值。这对于后面的分析来说是个大大的好消息。
地域性分布
<matplotlib.text.Text at 0x1102e1f90>
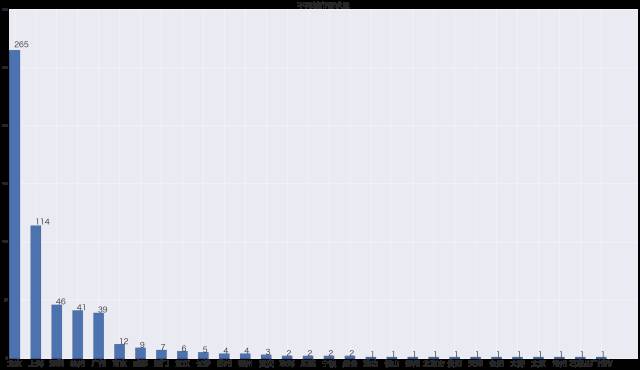
在拉勾网上,全国有29个城市的企业邮数据分析师的人才需求,其中将近一半需求产生在北京市,需求量全国第一。排在前5的分别是:北京、上海、深圳、杭州、广州。数据分析这一职业大量集中在北上广深四大一线城市,以及杭州这个互联网和电子商务企业的聚集地。北京市巨大的需求比重令我稍感意外,不过,考虑到拉勾网是一个偏重互联网相关行业的招聘平台,而我国大量互联网企业在北京聚集,这个结果倒也算合理。以后有时间,可以对全国互联网行业分布特点做个分析。
总而言之,可以得出一个清晰的结论:数据分析这一岗位,有大量的工作机会集中在北上广深以及杭州,期待往这个方向发展的同学还是要到这些城市去多多尝试。当然,从另一个方面说,这些城市也都集中了大量的各行业人才,竞争压力想必也是很大的。
总体薪酬情况

/Users/carrey/anaconda/lib/python2.7/site-packages/ipykernel/__main__.py:16: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
([<matplotlib.axis.XTick at 0x11ccaa290>, <matplotlib.axis.XTick at 0x11d478210>, <matplotlib.axis.XTick at 0x11d5652d0>, <matplotlib.axis.XTick at 0x11d602f10>, <matplotlib.axis.XTick at 0x11d6116d0>, <matplotlib.axis.XTick at 0x11d528290>, <matplotlib.axis.XTick at 0x126eb4c10>, <matplotlib.axis.XTick at 0x11d441e90>, <matplotlib.axis.XTick at 0x11d611bd0>, <matplotlib.axis.XTick at 0x11d618390>, <matplotlib.axis.XTick at 0x11d618b10>, <matplotlib.axis.XTick at 0x11d6242d0>, <matplotlib.axis.XTick at 0x11d624a50>, <matplotlib.axis.XTick at 0x11d62d210>, <matplotlib.axis.XTick at 0x11d62d990>, <matplotlib.axis.XTick at 0x11d637150>, <matplotlib.axis.XTick at 0x11d6378d0>, <matplotlib.axis.XTick at 0x11d642090>, <matplotlib.axis.XTick at 0x11d642810>], <a list of 19 Text xticklabel objects>)
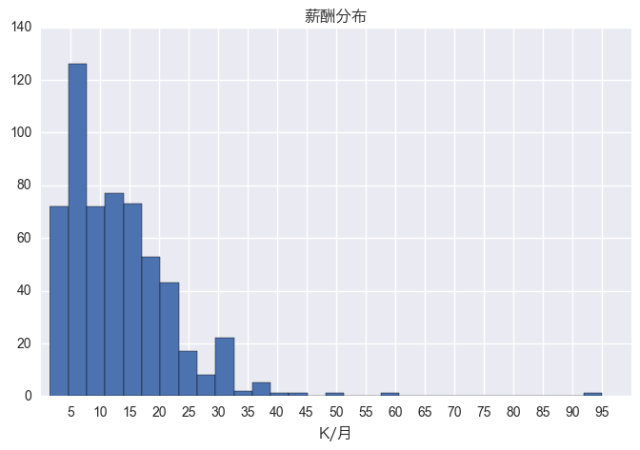
如同大多数其他工作一样,数据分析师的薪酬也是一个右偏分布。大多数人的收入集中在5k-20k每月,只有少数人能够获得更高的薪酬,但有极少数人薪酬极高,让人充满期待。需要说明的是,拉勾网上的薪酬值是一个区间值,并且相互之间互有重叠,为了便于分析,我取区间的中值作为代表值进行的分析。因此,实际的薪酬分布情况可能会比图中的情况更好一些。总是有人能够拿到薪酬的上限。综合来看,数据分析师的薪酬收入整体还是可观的,从这方面说,选择这个职业还是不错的。
不同城市薪酬分布情况

<matplotlib.text.Text at 0x115796650>
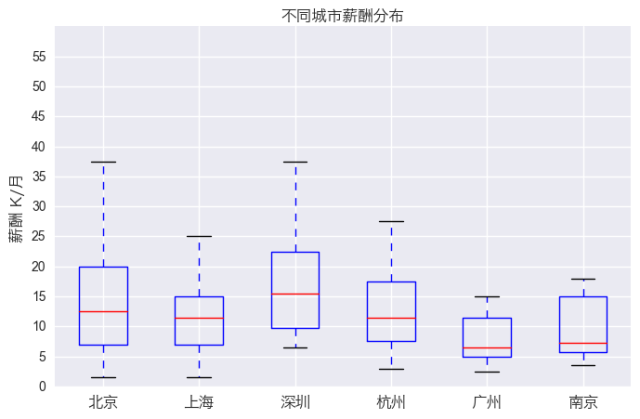
忽略掉那些人才需求量比较小的城市,我重点关注排名前六的城市。从图上看,这六大城市的薪酬分布情况总体来说都比较集中,这和我们前面看到的全国的薪酬总体情况分布是一致的。深圳市薪酬分布中位数大约在15k,居全国首位。其次是北京,约12.5k,之后是上海和杭州。深圳确实是个创造奇迹的城市,在这里也给了我一个小小的惊喜。从待遇上看,数据分析师留在深圳发展是个不错的选择。
工作经验需求

/Users/carrey/anaconda/lib/python2.7/site-packages/ipykernel/__main__.py:7: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy /Users/carrey/anaconda/lib/python2.7/site-packages/pandas/core/indexing.py:132: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy self._setitem_with_indexer(indexer, value) /Users/carrey/anaconda/lib/python2.7/site-packages/ipykernel/__main__.py:13: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy /Users/carrey/anaconda/lib/python2.7/site-packages/ipykernel/__main__.py:25: FutureWarning: sort(columns=....) is deprecated, use sort_values(by=.....)
<matplotlib.text.Text at 0x110577dd0>
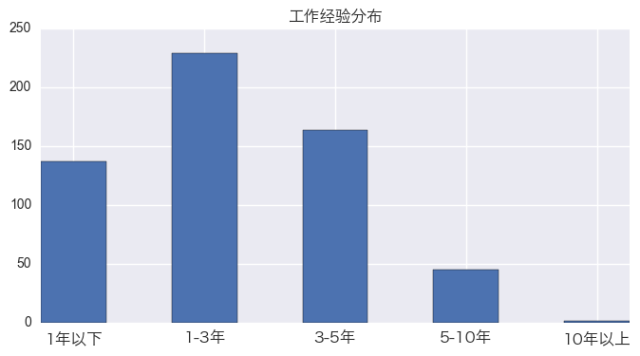
不出所料的,工作经验的需求分布近似于正态分布。工作1-3年经验的熟手需求量最大,其次是3-5年工作经验的资深分析师。工作经验不足1年的新人,市场需求量比较少。另外,工作经验要5-10年的需求量非常稀少,而10年以上的更是凤毛麟角。
从这个分布我们大致可以猜测出:
数据分析是个年轻的职业方向,大量的工作经验需求集中在1-3年;对于数据分析师来说,5年是个瓶颈期,如果在5年之内没有转型或者质的提升,大概以后的竞争压力会比较大。
不同工作经验的薪酬分布

<matplotlib.text.Text at 0x11cc58f50>
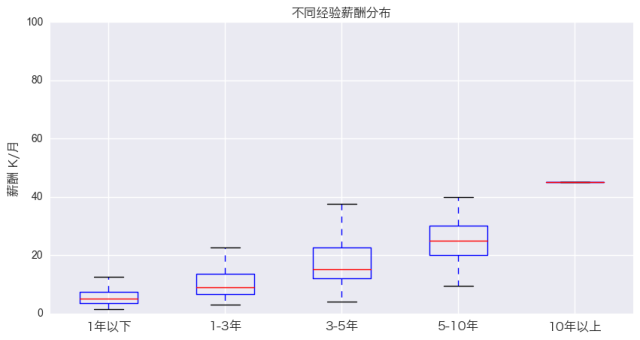
毫无疑问的,随着经验的提升,数据分析师的薪酬也在不断提高。另外,从现有数据来看,数据分析师似乎是个常青的职业方向,在10年内大概不会因为年龄的增长导致收入下降。
职业技能关键词


Building prefix dict from the default dictionary ... Loading model from cache /var/folders/p7/6s6n_sw53dq_w9j52wlzyl800000gn/T/jieba.cache Loading model cost 0.417 seconds. Prefix dict has been built succesfully. /Users/carrey/anaconda/lib/python2.7/site-packages/ipykernel/__main__.py:7: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy

词云显示出的情况,有点超出了我的预料。对于数据分析师这一岗位,企业需求频率最高的技能并不是Python语言和R语言等如今非常时髦的数据分析语言,而是传统的结构化查询语言SQL和表格神器Excel。这一点需要各位小伙伴注意,要想从事数据分析师岗位,SQL和Excel看起来是必备技能。 从词云上看出,数据分析师技能需求频率排在前列的有:SQL,Excel, SAS,SPSS, Python, Hadoop和MySQL等。另外,Java, PPT, BI软件等属于第二梯队。
掌握不同技能对薪酬收入的影响


/Users/carrey/anaconda/lib/python2.7/site-packages/ipykernel/__main__.py:13: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
<matplotlib.text.Text at 0x11f59b890>
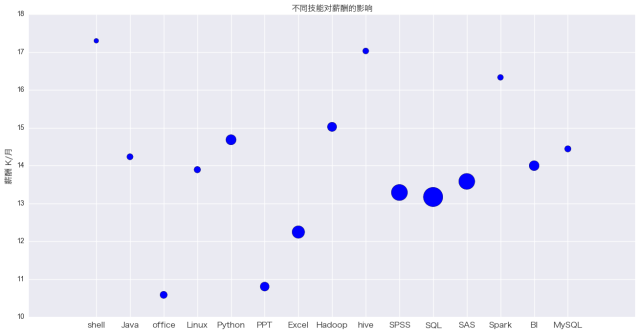
我对需求频率最高的前15个技能进行统计计算,得出每一个技能对应的平均薪酬水平,如上图。点的大小代表该技能需求量的多少。
在前15项技能中,shell,Hive, Spark这三者的平均薪酬水平最高,并且相对其他技能来说有比较大的差异。对数据分析师工作有所了解的人应该都知道,这三个工具中,Hive和Spark都是应用于分布式数据处理,而shell脚本则是Linux系统下工作的必须技能。这三者共同指向了一个方向,那就是海量数据的分布式处理!
所以,想要拿高薪的小伙伴注意了,海量数据处理、分布式处理框架是走向高薪的正确方向。 另外值得注意的是,在数据分析领域,Python语言的平均薪酬水平要高于目前如日中天的Java语言。而SQL语言和传统的SAS,SPSS两大数据分析软件,则能够让你在保证中等收入的条件下,能够适应更多企业的要求,也就意味着更多的工作机会。
通过上面的分析,我们可以得到的结论有这些: 数据分析这一岗位,有大量的工作机会集中在北上广深以及杭州。 大多数据分析师的收入集中在5k-20k每月,只有少数人能够获得更高的薪酬,但有极少数人薪酬极高,让人充满期待。
从待遇上看,数据分析师留在深圳发展是个不错的选择,其次是北京、上海。 数据分析是个年轻的职业方向,大量的工作经验需求集中在1-3年。
对于数据分析师来说,5年似乎是个瓶颈期,如果在5年之内没有转型或者质的提升,大概以后的竞争压力会比较大。 随着经验的提升,数据分析师的薪酬也在不断提高,10年以上工作经验的人,能获得相当丰厚的薪酬。
数据分析师需求频率排在前列的技能有:SQL,Excel, SAS,SPSS, Python, Hadoop和MySQL等,其中SQL和Excel简直可以说是必备技能。 海量数据、分布式处理框架是走向高薪的正确方向。 SQL语言和传统的SAS,SPSS两大数据分析软件,能够让你在保证中等收入的条件下,能够适应更多企业的要求,也就意味着更多的工作机会。
对于数据分析师技能的分析是比较简陋的,在本次分析过程中,仅针对工具型的技能进行了分析。但其实,数据分析师所需要具备的素质远不止这些,还需要有扎实的数学、统计学基础,良好的数据敏感度,开拓但严谨的思维等。如果要对这些内容进行深入挖掘的话,应该会更加有趣。不过,要进行这项内容的话,需要掌握大量中文分词、关键字提取等方面的知识和技能,难度也会更高。时间所限,在这里不再进一步展开了,希望以后有时间再做一个专项分析吧。 让人忍不住吐槽的是,Python2.X环境对中文编码的支持着实不够好,在处理数据的时候消耗了大量的时间和精力,也犯了不少错,走了很多弯路。以后这一块的内容要找时间专门攻坚一下,也可以考虑换到python3平台去。
特别说明:本次数据源完全来自拉勾网,但拉勾网本身是专注于互联网相关行业的招聘平台,所以本次分析出的结论更加适用于互联网行业的相关企业,对于其他行业的企业,未必合适。
━━━━━
Facebook & mongoDB 联合打造的
数据分析师认证项目
此项目分为入门与进阶,旨在帮助学员从零开始,熟悉符合硅谷标准的数据分析流程,掌握从数据清洗到数据可视化各环节的关键技能,最终成为顶尖数据分析师,获得Facebook、MongoDB 官方认证,通过工作内推加入领先科技企业,帮助团队或自己的事业做出通往成功的正确决策!

项目将于 7月26日 正式开放报名,全国仅限300名额,回复关键词“DAND”, 加入 Facebook & mongoDB 数据分析师认证 项目交流群:
*免费获得来自硅谷的数据领域职业指南;
*限时免费体验课程;
*抢先预订本期席位!