《小美好》短评文本情感分析+生成词云

向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
因为最近看了一下《致我们单纯的小美好》,虽然情节是有点“二”吧,但是看了觉得真的很怀念初高中的日子,一时玩心大发,于是就想搞点有意思的东西。。。首先去爬了豆瓣上面的短评,然后就是用SnowNLP做了一个比较粗糙的情感分析,结果可能不是很准确,因为这个python库本来是用来分析购物评论一类的,最后还做了一个简单的词云,因为觉得比较好玩吧。最开始先放上效果图,向各位大佬比心~


一、爬虫
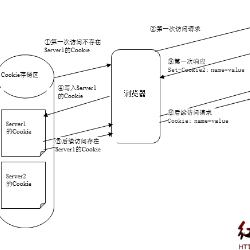
因为豆瓣有反爬虫机制,这里加上了cookie来爬取数据,把登录后的cookie放入txt文件中,经过处理变成我们需要的格式使用。通过分析目标url发现前页和后页两个链接中的start参数的值相差20,其它完全相同,废了点时间找到了最后一页。。。480页,所以直接用了一个for循环来解决翻页的问题,最后是将数据都放到了comment.txt文件中,便于后面分析使用。
import requests, codecs
from lxml import html
import time
import random
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0)
Gecko/20100101 Firefox/54.0'}
f_cookies = open('cookie.txt', 'r')
cookies = {}
for line in f_cookies.read().split(';'):
name, value = line.strip().split('=', 1)
cookies[name] = value
# print cookies
for num in range(0, 500, 20):
url = 'https://movie.douban.com/subject/27008416/comments?start=' + str(num)
+ '&limit=20&sort=new_score&status=P&percent_type='
with codecs.open('comment.txt', 'a', encoding='utf-8') as f:
try:
r = requests.get(url, headers = header, cookies = cookies)
result = html.fromstring(r.text)
comment = result.xpath("//div[@class='comment']/p/text()")
for i in comment:
f.write(i.strip() + '\r\n')
except Exception, e:
print ehttps://bbs.ichunqiu.com/forum.php?mod=post&action=newthread&
fid=59&extra=
time.sleep(1 + float(random.randint(1, 100)) / 20)
二、SnowNLP情感分析
SnowNLP是python中用来处理文本内容的,可以用来分词、标注、文本情感分析等,情感分析是简单的将文本分为两类,积极和消极,返回值为情绪的概率,越接近1为积极,接近0为消极。
import numpy as np
from snownlp import SnowNLP
import matplotlib.pyplot as plt
f = open('comment.txt', 'r')
list = f.readlines()
sentimentslist = []
for i in list:
s = SnowNLP(i.decode('utf-8'))
# print s.sentiments
sentimentslist.append(s.sentiments)
plt.hist(sentimentslist, bins = np.arange(0, 1, 0.01), facecolor = 'g')
plt.xlabel('Sentiments Probability')
plt.ylabel('Quantity')
plt.title('Analysis of Sentiments')
plt.show()
三、生成词云
词云的话这里用到了jieba(结巴)分词,wordcloud,Counter(计数用的),还有scipy,scipy.misc来处理图像。
import matplotlib.pyplot as plt
from scipy.misc import imread
from wordcloud import WordCloud
import jieba, codecs
from collections import Counter
text = codecs.open('comment.txt', 'r', encoding = 'utf-8').read()
text_jieba = list(jieba.cut(text))
c = Counter(text_jieba) # 计数
word = c.most_common(100) # 取前100
bg_pic = imread('heart.png')
wc = WordCloud(
font_path = 'C:\Windows\Fonts\simfang.ttf', # 指定中文字体
background_color = 'white', # 设置背景颜色
max_words = 200, # 设置最大显示的字数
mask = bg_pic, # 设置背景图片
max_font_size = 150, # 设置字体最大值
random_state = 20 # 设置多少种随机状态,即多少种配色
)
wc.generate_from_frequencies(dict(word)) # 生成词云
plt.figure()
plt.imshow(wc)
plt.axis('off')
plt.show
wc.to_file('heart.jpg')
via https://bbs.ichunqiu.com/thread-30145-1-2.html
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注