详解AlphaGo到AlphaGo Zero!

作者 | 刘思乡,达观数据数据挖掘工程师,负责达观数据推荐系统的开发和部署,对推荐系统在相关行业中的应用有浓厚兴趣。
编辑 | Jane
摘要
1、围棋是一个 MDPs 问题
2、policy iteration 如何求解 MDPs 问题?
3、WHAT and WHY is Monte Carlo method?
4、AlphaGo Zero 的强化学习算法
1.前言
AlphaGo 是 Google DeepMind 团队开发的一个基于深度神经网络的围棋人工智能程序,一共经历了以下几次迭代:
(1)2015 年 10 月,以 5-0 击败欧洲冠军樊麾,其使用了两个神经网络;
(2)2016 年 3 月,以 4-1 击败世界冠军李世石,较于上一版本,其使用了更复杂的网络结构,在生成训练数据时,使用了更加强大的模拟器;
(3)2017 年 1 月,AlphaGo Master 在网络上与人类棋手的对阵中保持了 60 不败的战绩,与之前版本不同的是,只使用了一个神经网络;
(4)2017 年 10 月,DeepMind 公开了最新版本的 AlphaGo Zero,此版本在与 2016 年 3 月版的 AlphaGo 的对阵中取得了 100-0 的战绩,并且,在训练中未使用任何手工设计的特征或者围棋领域的专业知识,仅仅以历史的棋面作为输入,其训练数据全部来自于 self-play。
2.马尔可夫决策过程
一个马尔可夫决策过程(Markov Decision Processes,MDPs)通常包括以下几个要素:
(1)状态集合 S,包含 MDPs 可能处在的各个状态;
(2)动作集合 A,包含 MDPs 在各个状态上可采取的动作;
(3)转换概率 Psa,表示在状态上采取动作后,下一个状态的概率分布;
(4)回报函数 R,R(s) 表示状态的回报。
在定义了以上几个要素之后,我们可以来描述一个典型的 MDPs:从某个起始状态 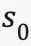
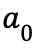
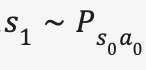
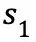
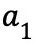
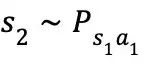
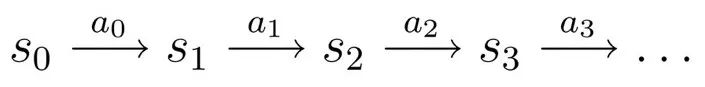
如果 MDPs 的状态集合和动作集合是有限大的,则称之为有限 MDPs。
通常,我们还会定义另外一个参数——折扣因子(discount factor)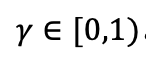

MDPs的核心问题是如何找到一个对所有状态都适用的最优策略,按照此策略来选择动作,使总回报的期望最大化。在总回报中加入折扣因子后,为使总回报的期望最大化,须尽可能的将正向回报提前,负向回报推迟。
回想一下围棋的对弈,起始状态是一个空的棋盘,棋手根据棋面(状态)选择落子点(动作)后,转换到下一个状态(转换概率为:其中一个状态的概率为 1,其他状态的概率为 0),局势的优劣是每个状态的回报。棋手需要根据棋面选择合适落子点,建立优势并最终赢下游戏,因此,围棋可以看作是一个 MDPs 问题。
3.策略迭代
定义一个策略𝜋的状态值函数(state-value function)为:
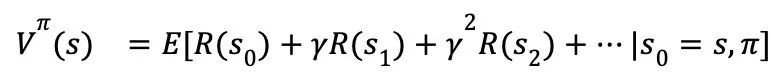
等式右半部即为总回报的期望值。展开等式的右半部分:
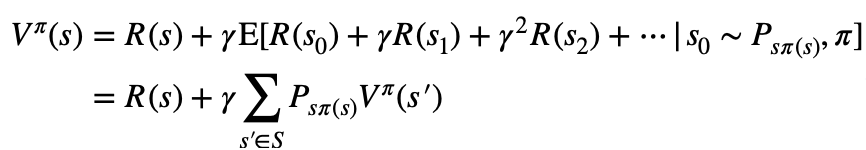
上面的等式称作贝尔曼方程(Bellman equation),从贝尔曼方程可以看出,当前状态的回报的期望包括两部分:1)当前状态的立即回报,2)后续状态的回报的期望和与折扣因子之积。
定义最优状态值函数(optimal state-value function)为:
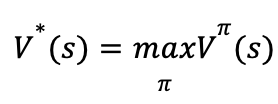
根据贝尔曼方程有:
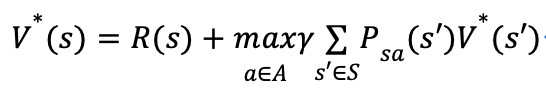
定义策略为:
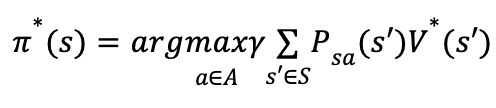
对于任意状态和任意策略,均有:
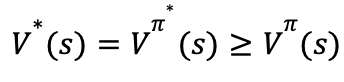
因此,策略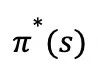
最优策略可通过策略迭代来求解。一次策略迭代包括两个步骤:1)策略估计(Policy Evaluation):基于当前的策略和状态值函数根据贝尔曼方程更新状态值函数;2)策略提升(Policy Improvement):基于当前的策略和1)中更新后的状态值函数来更新策略。
策略迭代求解MDPs问题的算法如图1所示:

图1 策略迭代算法
为证明算法的收敛性,定义动作值函数(action-value function)为:
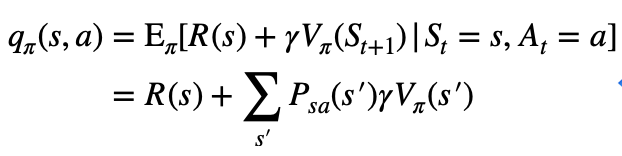
假设有两个策略和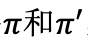
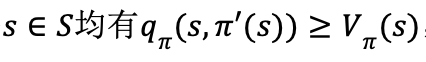

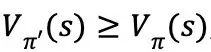
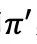
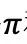
因此,在策略迭代中,每一次策略提升后,将得到一个更优的解。对于有限MDPs,策略的个数是有限的,在经过有限次的迭代之后,策略将收敛于最优解。
4.蒙特卡洛方法
在策略迭代中,为了估计状态值函数,需要计算并存储所有状态的值函数。在围棋中,有超过 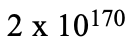
蒙特卡洛方法(Monte Carlo Method)通过模拟采样来估计状态值函数和动作值函数,将采样结果的均值作为估计值,根据大数定律,随着采样次数的增加,估计值将趋近于实际值。蒙特卡洛方法适用于“情节任务(episodic tasks)”,即不管使用哪种策略,最终都能到达终止状态,围棋是一种 “情节任务”。蒙特卡洛方法对各个状态的估计是相互独立的,即在估计状态值函数或动作值函数时不依赖于其他状态的值函数,因此,不需要计算或存储所有状态的值函数。
为估计策略 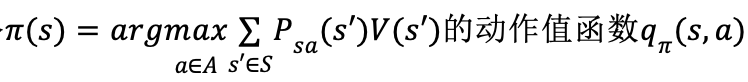
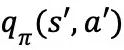
策略 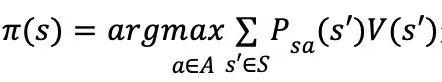
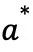
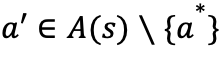
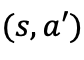
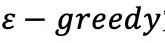
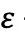
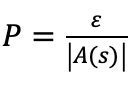
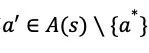
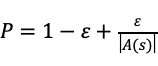
在蒙特卡洛方法中,“深耕”使得我们更多的在最有希望的方向上搜索,而“探索”使得我们能够同时兼顾到其他方向。
5.AlphaGo Zero
5.1 AlphaGo Zero的网络架构
围棋的棋面可以看作是一个 19 × 19 的图像,每一个棋子对应一个像素点,不同颜色的棋子对应不同的像素值。考虑到深度神经网络,尤其是卷积神经网络在图像领域的成功应用,AlphaGo 使用卷积神经网络来估计当前的局面,选择落子的位置。
AlphaGo Zero 所使用的卷积神经网络的输入是 19 × 19 × 17 的张量 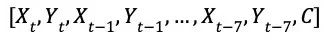
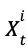
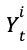
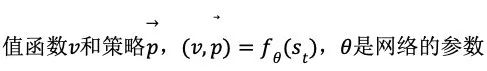
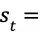
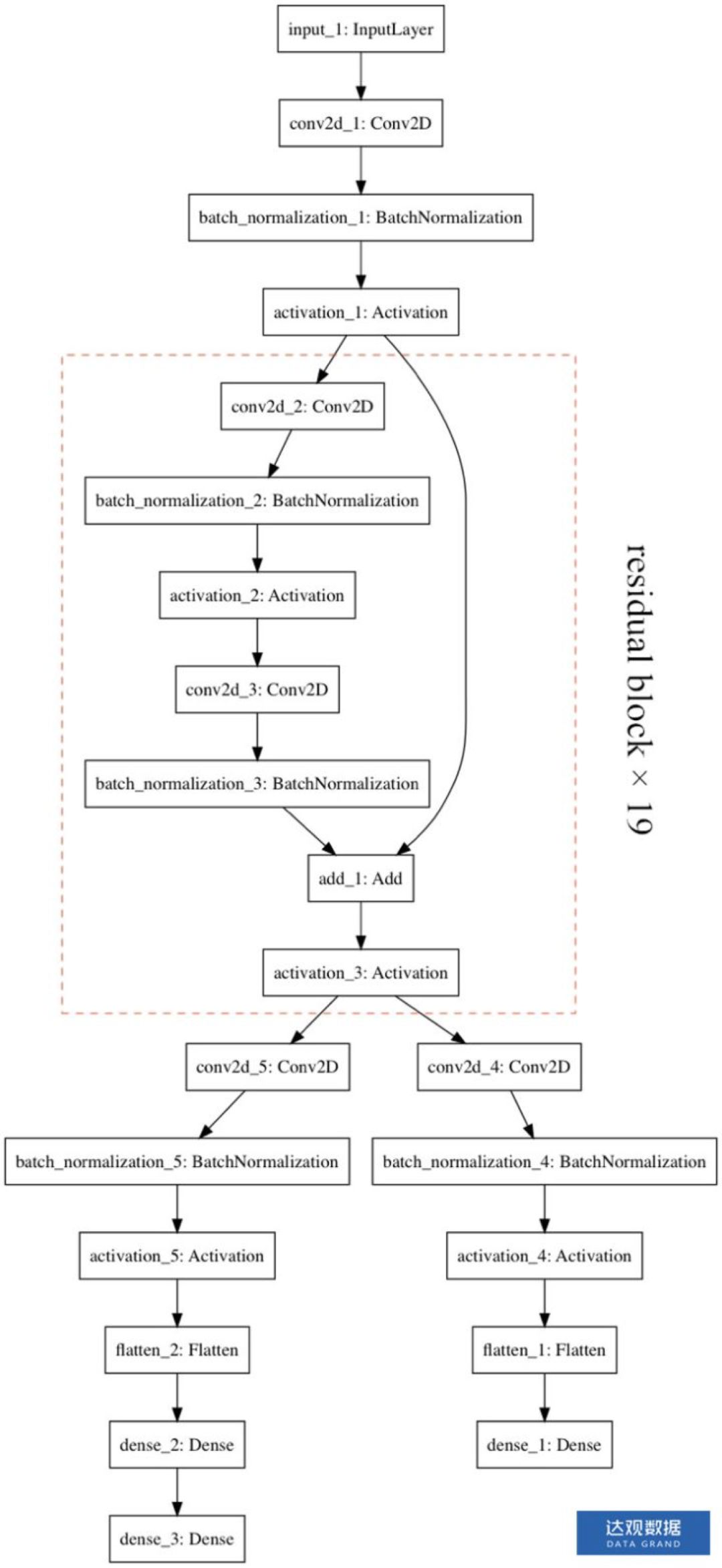
图2 AlphaGo Zero网络架构
5.2 策略迭代与蒙特卡洛树搜索
蒙特卡洛树搜索使用蒙特卡洛方法估计搜索树上的每个节点的统计量。AlphaGo 将策略迭代与蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)结合了起来。对于每个状态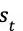
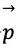
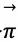
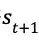
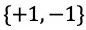
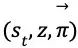
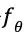
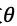
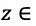
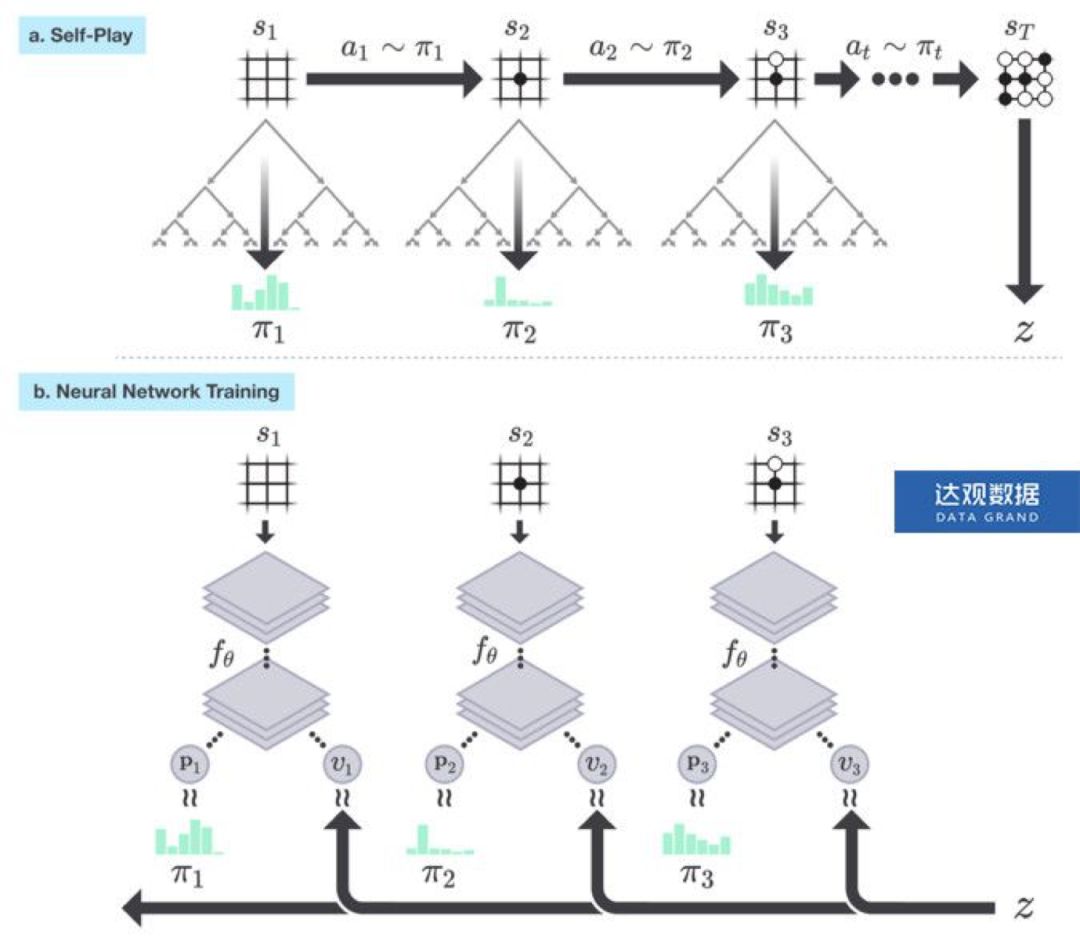
图3 AlphaGo的强化学习算法
5.2.1 策略提升
在 MCTS 的过程中,搜索树上的每个节点 s 的每条边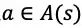
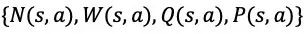
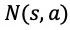
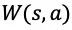
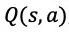
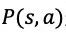
策略提升的一次搜索过程包括以下几个步骤:
(1)对于从根节点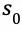
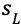
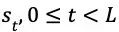

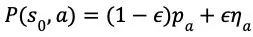
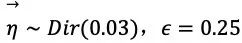
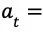
(2)在搜索到达叶节点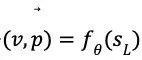
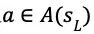
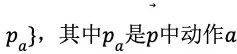
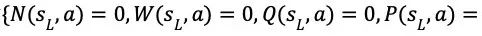
(3)备份,更新搜索路径上节点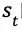
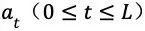
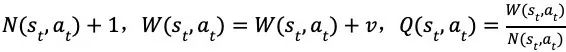
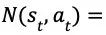
在多次搜索之后,根据根节点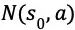
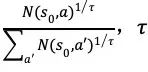
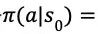
5.2.2 策略估计
在状态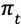
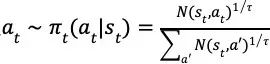
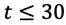
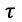
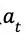
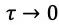
在状态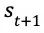
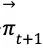
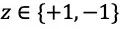
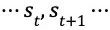
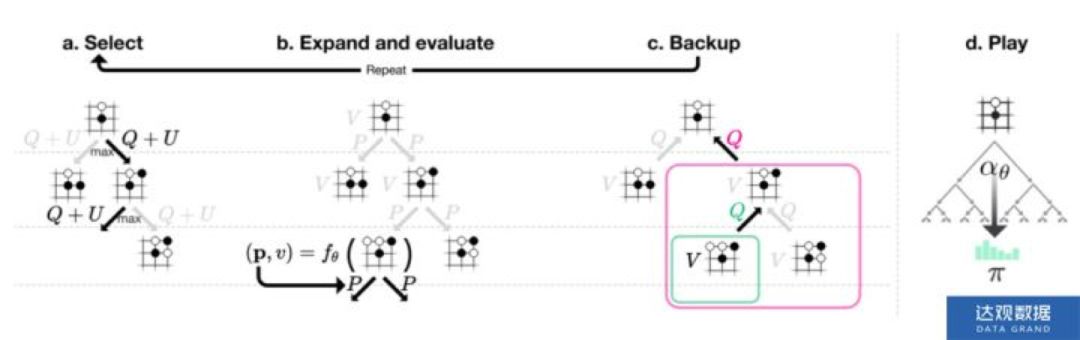
图4 MCTS
这个过程即 self-play。为了提高搜索的效率,在策略提升时,当搜索到叶节点后,使用值网络估计状态值函数作为收益返回,避免继续向下搜索,限制搜索的深度;在策略估计时,使用策略提升输出的策略来指导动作的选择,限制搜索的广度。另外,如果值网络估计的局势的收益(胜率)低于一个阈值之后,便放弃此局游戏。
5.2.3 旋/翻转不变性
将围棋的棋盘旋转或翻转之后,不会影响局势,落子的位置也只需要做相应的变换即可。如果状态 s 被旋转或翻转,值网络的输出 v 不变,策略网络的输出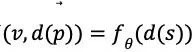
棋盘有 7 种不重复的旋/翻转变换,分别是:上(下)翻转,右(左)翻转,右上(左下)翻转,右下(左上)翻转,90度旋转,180度旋转,270度旋转。90度旋转可以通过右下翻转+上翻转来实现,180度旋转可以通过上翻转+右翻转来实现,270度旋转可以通过右下翻转+右翻转来实现,因此,只需要实现4个基础的翻转变换。在估计叶节点的值函数和各条边的先验概率时,从8种变换中随机地取一个对叶节点进行处理,并对策略网络的输出做相应的反变换。
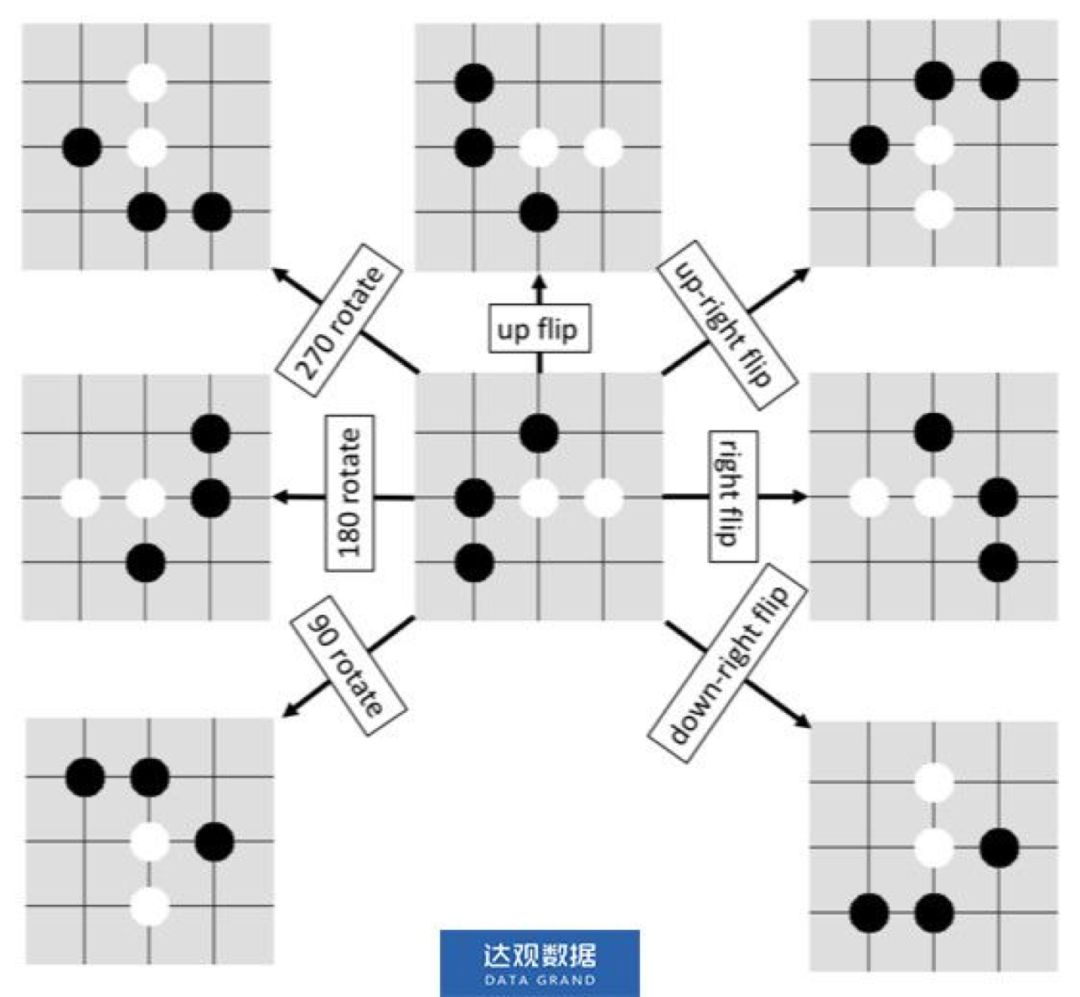
图5 旋转和翻转
5.3 模型优化
在 self-play 的每一局游戏中,会生成一系列的状态-策略-值元组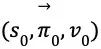
模型优化的损失函数是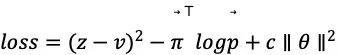
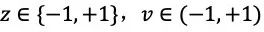
模型参数更新使用带动量和学习率衰减的随机梯度下降方法,动量因子设为0.9,学习率在优化的过程中从 0.01 衰减到 0.0001。每次从最近的 500,000 局游戏中随机地选取一个大小为 2048 的 mini-batch,每 1000 次更新之后,对模型进行评估。
5.4 模型评估
更新后的模型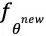
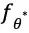
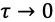
6.总结
人工智能在很多领域已经显示出了超越人类的水准,并且还在不断的攻城略地,达观也将在文本智能处理领域持续地深耕和探索,让计算机代替人工来处理企业内的各类文书资料,帮助企业提升自动化水平。
(*本文为 AI科技大本营投稿文章,转载请联系作者)

推荐阅读




