ICCV2019 | 北大、华为联合提出无需数据集的Student Networks

转载自:学术头条(ID:SciTouTiao)

前言
背景
神经网络压缩算法目前根据有无原始数据的参与分为两种。
Data-Driven类
Hinton等提出了一种知识蒸馏方法(knowledge distillation,KD),该方法提炼出经过预训练的teacher网络的信息,以学习portable (student )网络【Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distillingthe knowledge in a neural network. arXiv preprintarXiv:1503.02531, 2015】。Denton等利用低秩分解(SVD)来处理全连接层的权重矩阵【Emily L Denton, Wojciech Zaremba, Joan Bruna, Yann Le- Cun, and Rob Fergus. Exploiting linear structure within convolutional networks for efficient evaluation. In NIPS, 2014】。Han等采用修剪、量化和霍夫曼编码来获得紧凑的深度CNN,使之具有较低的计算复杂度【Song Han, Huizi Mao, and William J Dally. Deep compression:Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015】。Li等进一步提出了一种特征模拟框架,以训练有效的卷积网络进行目标检测【Quanquan Li, Shengying Jin, and Junjie Yan. Mimicking very efficient network for object detection. In CVPR, pages 7341-7349. IEEE, 2017】。
上述方法在大多数据集上取得了良好的效果,但如果没有原始训练数据集,则很难应用。
Data- Free类
Lopes等利用原始训练数据集记录的 “元数据”(meta-data)(例如,每层激活的平均值和标准偏差),但大多数训练过的CNN很难提供此数据【Raphael Gontijo Lopes, Stefano Fenu, and Thad Starner.Data-free knowledge distillation for deep neural networks.arXiv preprint arXiv:1710.07535, 2017】。Srinivas和Babu提出在完全连接的层中直接合并相似的神经元来压缩网络,但这很难应用于未详细说明结构和参数信息的卷积层和网络【Suraj Srinivas and R Venkatesh Babu. Data-free parameter pruning for deep neural networks. arXiv preprint arXiv:1507.06149, 2015】。
实际上,由于如涉及隐私、传输限制等因素,原始训练数据集和详细的网络结构、参数等很难获取,这就意味着上述两类方法难于应用。
整体架构
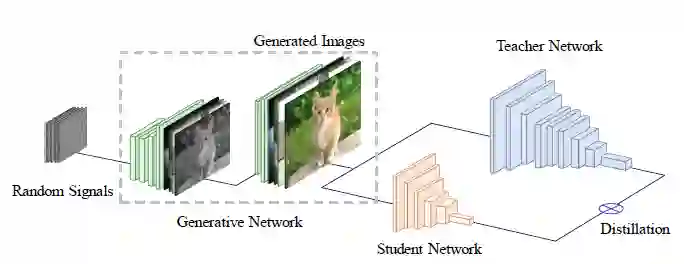
GAN有一个生成器和一个判决器,给定的teacher网络同时作为GAN的判决器,不对其进行任何更新。Random Signals(随机信号)输入到GAN的生成器,变换为模拟的原始数据,由判决器进行识别。生成器生成一组数据后,再通过KD方法对student网络的参数进行更新。
Data-free Student Network learning
Teacher-Student关系
由于很难获取原始训练数据集,有时也无法获得参数和详细结构信息。作者从teacher-student学习范例来着手。作者认为KD并未利用给定网络的参数和体系结构的信息,尽管可能仅提供有限的接口(如输入和输出接口),但仍然可以从teacher网络继承一些有用的信息。令N_T和N_S表示teacher网络和所需的portable/student网络,可用以下基于知识提炼的损失函数来优化student网络:
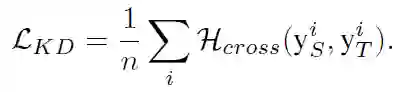
其中H_cross为交叉熵损失,y_T^i=N_T (x^i)和y_s^i=N_s (x^i)分别是N_T和N_S的输出。利用知识转移技术,可在没有给定网络特定架构的情况下优化portable网络。
用GAN生成训练样本
-
one-hot损失函数
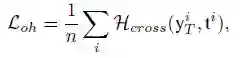
-
特征图激活损失
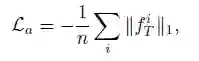
-
图像的信息熵损失函数
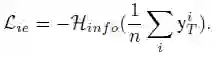
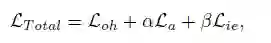
优化
作者设计的学习过程可以分为两个训练阶段。首先,将teacher网络作为固定判决器。使用上述的L_Total损失函数,优化生成器G。其次,我们利用KD方法将知识直接从teacher网络转移到student网络。使用KD的损失L_KD来优化具有较少参数的student网络。
实验
MNIST实验
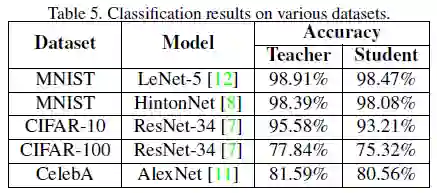
作者分别使用基于卷积的结构和由全连接组成的网络。前者,采用LeNet-5为teacher网络,使用LeNet-5-Hafl(修改后的版本为每层通道数的一半)作为student模型。后者,teacher网络由两个有1200个单元的隐藏层组成(Hinton-784-1200-1200-10),student网络由两个有800个单元的隐藏层组成(Hinton-784-800-800-10)。表1为MNIST实验结果。
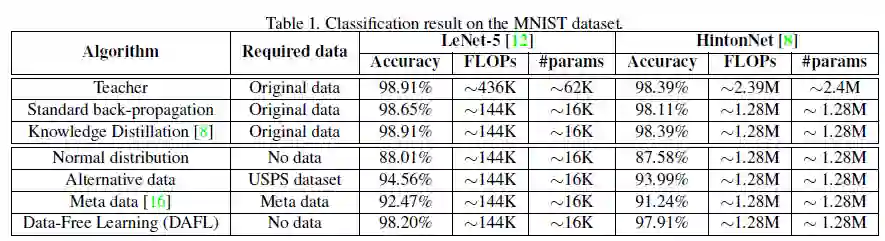
作者首先采用随机生成的正态分布数据来作为训练集时,student网络准确度仅有88.01%,再用USPS数据集训练student网络准确度也仅达到94.56%,说明原始训练集的效果是其他数据集难以替代。作者提出的DAFL方法达到了98.20%的准确度。
在全连接结构上,与前者结果类似,DAFL方法达到了97.91%的准确度。
消融实验
作者用随机生成的样本,student网络的准确度只有88.01%。仅用one-hot损失或特征图激活损失,所产生的样本不均衡,会导致较差。将L_oh或L_a与L_ie结合时,student网络分别为97.25%和95.53%。一起使用时,可达到最佳性能。

可视化结果实验

MNIST数据集上的平均图像

生成的数据集上的平均图像
说明生成器确实以某种方式在学习原始数据分布。
第一卷积层中过滤器的可视化结果如下所示,表明student网络从teacher网络获取了某些有价值的知识。

CIFAR数据集实验
作者进一步使用ResNet-34作为teacher网络,ResNet-18作为student网络。
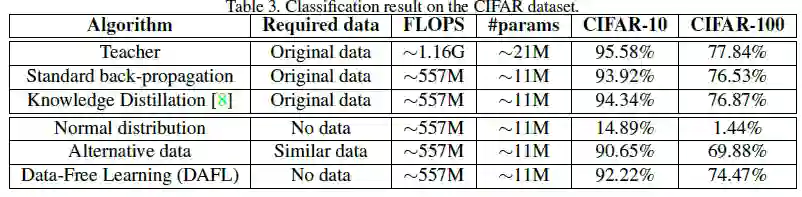
在CIFAR-10上,KD的student网络为94.34%的准确度,DAFL方法可达到92.22%准确度,进一步说明DAFL方法可更好地模拟原始数据。
CIFAR数据集CelebA
作者将AlexNet网络设置为teacher网络,student网络设置为AlexNet-Hafl(修改后的版本为每层通道数的一半)。
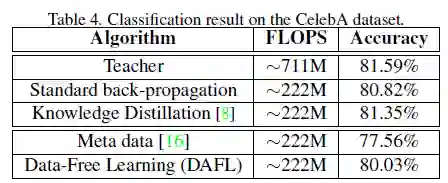
DAFL的student网络的准确度为80.03%,与teacher网络的准确度几乎相当。
扩展实验
作者使用生成的图像训练与teacher网络具有相同架构的student网络。重新训练的student网络的准确度与teacher网络的准确度非常接近。
总结
神经网络压缩算法通常需要原始训练数据。但在实际中,由于某些隐私和传输限制,要获取给定网络的训练数据和详细网络结构信息并非易事。在本文中,作者提出了一个新颖的框架来训练生成器,以模拟原始训练数据集。然后通过KD方法有效地学习、得到portable网络。在MNIST、CIFAR等数据集上的实验表明,作者所提出的DAFL方法可获得性能较好的portable网络,显示了一定的实用价值。
——END——




