DeepMind视频行为分类竞赛,百度IDL获第一,新算法披露
1新智元报道
编辑:闻菲
【新智元导读】ActivityNet竞赛是目前视频动作分析领域影响力最大的赛事。上月,2017年竞赛组织者通过官网宣布了本届比赛的成绩。其中,来自百度深度学习实验室(IDL)的Genome团队获得子命题、由DeepMind主办的“Kinetics行为分类比赛”第一名,香港中文大学获得第二名,德国创业公司TwentyBN获得第三名。本文将具体介绍在ActivityNet Kinetics竞赛排名第一的视频识别任务解决方案。

作为重要的内容载体,视频已经成为信息获取的重要来源之一。与文章不同,视频通常需要预先标注出关键字才能被用户检索到,进而决定是否打开。但大量的视频因缺乏内容标签,一方面无法被检索,另一方面用户也很难快速知道视频内容。如何分析视频内容并进行有效分类,成为业界关注的核心问题之一。
目前视频理解的难点在于,理解视频需要在图像的基础上获得更多场景信息,例如不仅仅需要知道短视频的画面里面有人,还要知道这个人是在做什么动作。此外,在算法层面上视频理解也需要用到多帧的信息,而且视频理解天然是一个多模态的问题,除了图像,还有语音数据,运动信息等。因此,如何合理提取多帧多模态特征中的有效信息是视频理解问题的重点。
常见的视频分类方法主要分为两部分,一是从视频中抽取特征,更好地建模图像、语音以及光流等多模态信息,另一部分则是对多帧的信息进行更好的时序建模。此前,在特征的时序建模上,并没有很好的处理方法。有人使用LSTM模型, 但浅层的LSTM容易导致过拟合,而深层的LSTM会遇到优化问题难以收敛。此外,由于视频包含了图像连续的时间和空间域,怎样构建一个端到端的框架,将这些图像的时空特点表示出来,也是研究的难点。
ActivityNet数据集和竞赛专为促进视频理解而推出。与ImageNet类似,研究人员可以在这个数据集的基础上提出更好的视频分类方案,也可以得到很好的预训练视频模型,能够迁移到其他垂直领域。
ActivityNet竞赛是目前视频动作分析领域影响力最大的赛事,被誉为视频界的ImageNet竞赛。虽然刚刚推出2年,但每年都吸引到MSR、CUHK、CMU、UTS等众多高校和科研机构积极参加。
其中,Kinetics是ActivityNet今年最新推出的一个大规模视频分类任务,本次Kinetics视频行为分类比赛由DeepMind主办,有400个动作类别,24万训练语料,每个视频长10秒左右,一个视频就是一个完整的类别,是迄今为止开放视频内容的最大视频分类数据集。
根据ActivityNet竞赛规则,参赛者需要预测每一个视频的5个可能类别,系统依据预测类别Top1和Top5的平均准确率来排序。值得一提,每支参赛队伍只能提交4次结果,组织方也是在比赛结束前一个多月才将数据集放出来,都是为了防止参赛者拟合数据集。
百度IDL视频分析团队Genome此次获得ActivityNet Kinetics竞赛第一名,获胜的关键主要有三点:如何学到更好的多模态特征表达,基于这些特征建立时序关系,最终将各种不同模态信息融合到一起。
1. 如何通过训练学到更好的特征 获奖方案主要使用了3种类型特征:RGB特征、光流特征和语音特征。团队使用基于双路卷积神经网络的方法学习RGB特征和光流模型,并将RGB模型迁移到语音特征上去,都得到很好的结果。提取更好的特征表示是视频理解的基础。
2. 如何基于这些特征建立更好的时序关系 时序关系建模有基于CNN和基于LSTM/GRU两种思路,Genome团队都做了尝试。在基于LSTM/GRU思路探索序列模型时,他们提出了Fast Forward处理视频时序建模的框架,使用一个深度达到7层的双向LSTM/GRU网络(一共14层)建模深层次的时序关系,堪称视频界的ResNet。通过引入 Fast Forward 连接,不仅能有效防止过拟合,还能加速模型的收敛,提升模型的性能。该模型是本次比赛中单模型性能最佳的时间序列模型。
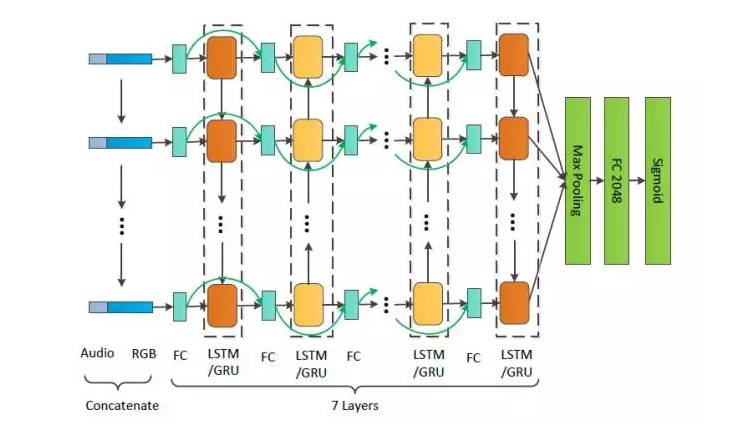
在本次比赛中,单模型性能排名第二的快速传导网络(FFLSTM),也是性能最好的时间序列模型
经过不断实验,团队在建模时序特征时发现单独使用Attention机制非常有效,于是他们就尝试移除LSTM/GRU,引入更多Attention组合参数来捕获更多的时序模式,提出了一个名叫Multi-Group Shifting Attention Network的模型,这也是本次比赛表现最好的单模型。这种架构的设计跟前人的工作也有异曲同工之处。在此前谷歌云联合Kaggle举办的YouTube-8M大规模视频理解竞赛(Genome团队也在其中取得了第三名的成绩),冠军团队使用的是VLADNET算法,这是一种优化过的传统视频分类算法。本次Genome团队在ActivityNet中使用的Multi-Group Shifting Attention Network,可以看作是对VLADNET算法的一次创新,将沿着每一帧的特征去做卷积改为沿着序列去做卷积,由此实现了性能的提升。
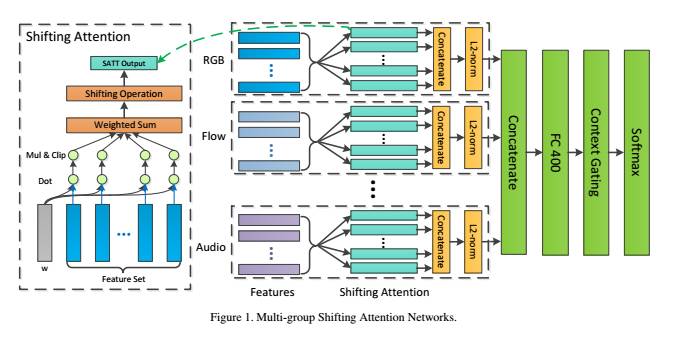
在这次比赛中,单模型成绩最好的Multi-group Shifting Attention Networks架构
3. 如何让多模态更好地融合在一起 传统的多模态数据融合只是将不同特征拼接在一起去学习,而难以学习得到不同模态的特征的有效组合。Genome团队在本次竞赛过程中也针对这个问题提出了相应的优化方案。
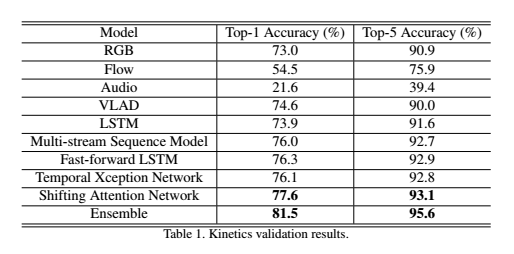
团队提出的4种新视频行为分类方法(也即最后4种单模型)的性能数据。
该项技术已经应用到视频个性化推荐和视频自动化打标签等百度产品中,解决了视频推荐的冷启动和视频关键词缺乏等实际问题。
了解更多请查看论文:
Revisiting the Effectiveness of Off-the-shelf Temporal Modeling Approaches for Large-scale Video Classification
https://arxiv.org/abs/1708.03805





