华为诺亚实验室:端侧AI模型的技术进展与未来|量子位·吃瓜社
主讲人 | 王云鹤 华为诺亚实验室
量子位编辑 | 公众号 QbitAI
近两年来,端侧AI在技术和应用方面都取得了快速发展。相较于云侧AI,端侧AI具有低时延、保护数据隐私与安全、减少云端能耗、不依赖网络稳定等显著优势。
但端侧AI也面临巨大的挑战,比如计算需求量大、对实时性要求高,受限于运行环境、内存、存储空间等。面对这些挑战,端侧AI取得了哪些技术进展?未来将如何落地应用?
5月13日,量子位·吃瓜社第9期线上活动中,华为诺亚方舟实验室技术专家王云鹤直播分享了端侧AI模型的最新技术进展。
主要分享内容包括:
端侧AI模型的背景介绍
如何对神经网络模型进行压缩加速
如何对神经网络进行架构搜索
如何保护用户隐私等
文末附有直播回放链接、PPT获取方式;以下为量子位·吃瓜社整理的云鹤老师分享的内容:

大家好,我是王云鹤,2018年博士毕业于北京大学,现在在华为诺亚方舟实验室,我主要研究的方向是关于端侧AI模型的优化和加速等。
今天晚上很荣幸参加量子位·吃瓜社的线上活动,有机会给大家做一些相关工作的分享。我今天讲的内容主要是关于端侧AI模型,包括我所在公司和学术界的一些新的进展。
今天的分享,我将首先介绍端侧AI模型的相关背景;然后分三个框架介绍最新取得的一些技术进展,包括如何进行模型的压缩和加速、如何进行架构的搜索、如何保护用户的隐私数据;然后给大家展示一个案例,是华为在端侧AI的算法与昇腾芯片的结合;最后是一点总结,包括我们用到的算法、未来的计划。
端侧AI模型背景介绍
提到端侧AI,我们主要做的是深度神经网络模型的架构优化,以使它可以在端侧取得更好的表现。先来看一下深度神经网络架构的发展情况。
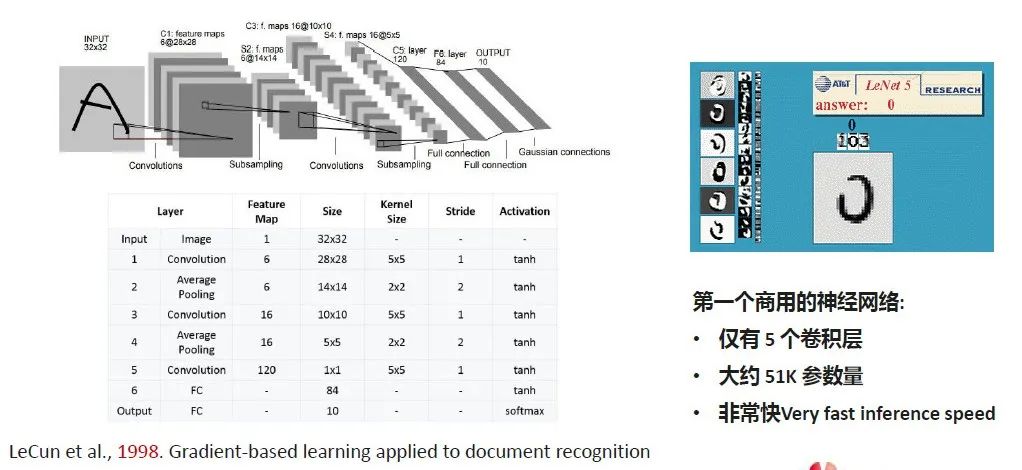
上图是LeCun在1998年提出的LeNet,是一个五六层的神经网络,搭建出一系列手写字体的数字识别。这是第一个可商用的神经网络,仅有5个卷积层,51K参数量,速度也非常快,被用于很多手写字体的识别场景。
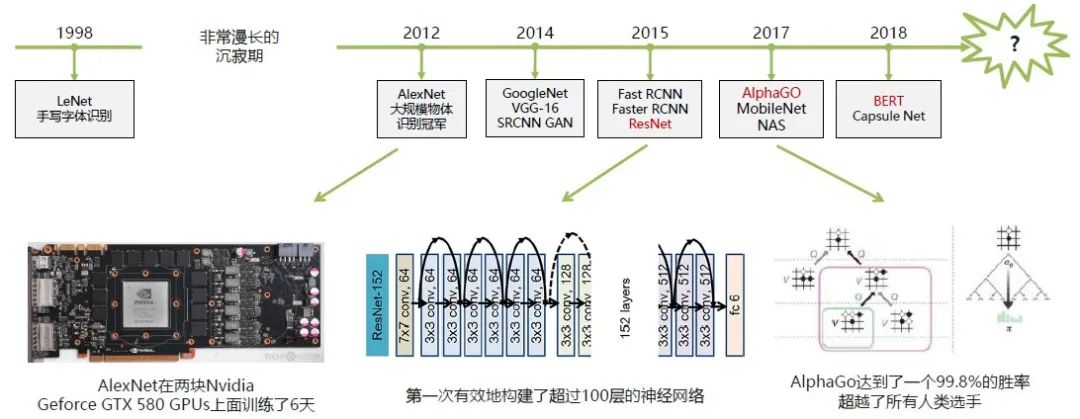
上图是深度神经网络框架的演变。从1998年开始LeNet手写字体识别之后,到现在大家讨论的深度神经网络,中间经过了非常漫长的沉寂期。
2012年, AlexNet在ImageNet大规模物体识别的竞赛上得到冠军。它当时的实验结果远超其他基于传统的手工设计特征的精度,虽然AlexNet在我们现在看来是一个比较小的模型,但当时是在两块NVIDIA GPU上面训了6天才训完。
2014年提出了更多不同的模型,包括GoogleNet,VGG等非常深非常大的神经网络。大家也逐渐把深度神经网络应用到更广泛的领域,如SR-CNN图像超分辨率神经网络,GAN图像生成对抗模型等。
2015年进一步把这些深度神经网络做了更深远的高层语义的推广。如Fast R-CNN目标检测网络,ResNet深度残差神经网络,都是在这个时间段集中的提出的。
2017年取得了突破性的进展。如AlphaGo利用强化学习深度神经网络,超越了人类围棋选手冠军;MobileNet,NAS也是在这个时间提出的。
到2018年,更大规模的BERT预训练模型在NLP任务上表现出非常好的性能,Capsule Net等相继被提出。
现在大家仍在探索,到底什么样的神经网络是比较优的架构,产生更好的性能的同时,还能带来更好的用户体验。
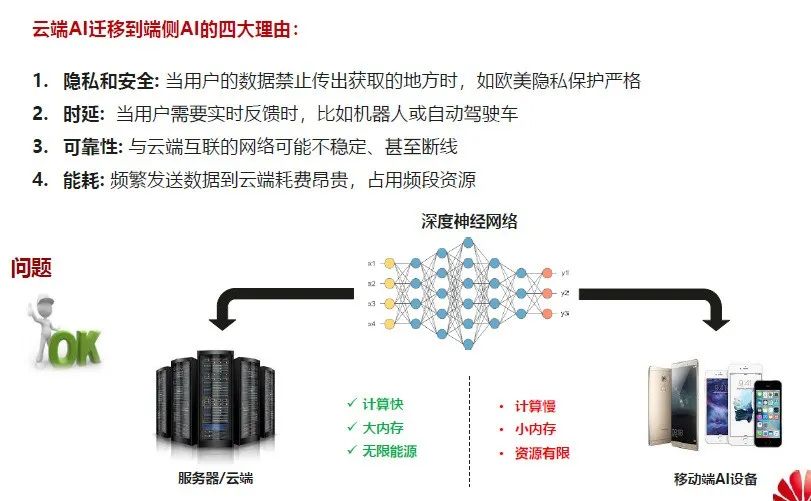
前面提到了多个深度神经网络,虽然不断取得了更好的表现,但是把模型从云端迁移到端侧时,会面临很多问题。
首先是隐私和安全的问题,对于训练好的模型,用户数据不可公开时,我们就无法使用这些AI模型。
第二是备受关注的时延问题,云上的AI模型都具有非常好的性质,但是它的计算量相应的也非常庞大。当把它迁移到计算能力较小的端侧AI设备上面,时延是一个急需优化的问题。
第三点是可靠性,虽然端测设备可以把我们所需要的任务和数据传到云上做推理,但有时候与云端互联的网络可能并不稳定。比如自动驾驶,在一些无人区或者地下车库时,由于网络不可靠,我们就需要在本地推理AI模型。
最后是能耗的问题,近两年受到的关注也非常大。AI模型在推理过程中产生的计算量非常大,如果放到端侧移动设备上面,将产生非常大的能耗。尤其是在AIoT应用下,很多端侧处理器的电池容量比较小,这种大量的深度神经网络的计算就会导致设备的使用周期打折扣。
如何对神经网络模型进行压缩加速
MIT的韩松老师在2015年提出了一些观测:预先训练好的AlexNet、VGGNet模型中,去掉大约90%的参数,它的精度还是无损的。因此韩松老师开始提出一些模型压缩的技术。
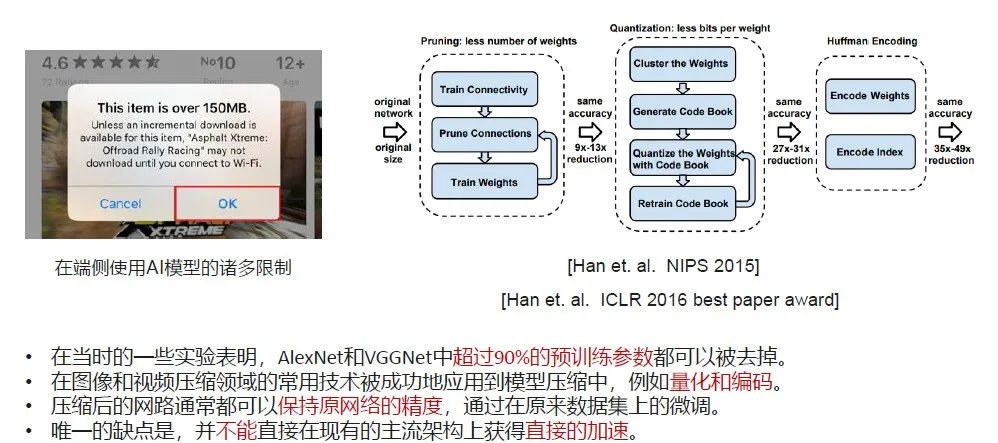
如上图,一个预先训练好的神经网络的模型,先识别出其中一些不重要的权值,然后对它进行FineTune以保证它的精度。接下来通过权重的量化、熵编码,得到一个非常小的压缩文件。当时最好的结果可以达到40倍以上的模型压缩比例。
这种方法唯一的缺点是,虽然可以构建出非常稀疏的神经网络,但它的计算是非结构化的,它的稀疏是需要我们一些特殊的技术去帮助实现的,很难在大规模的GPU运算单元上去做加速。接下来介绍下针对这个问题华为做了哪些工作。
CNNpack:在频域上的模型压缩技术(NIPS 2016)
第一个工作是我们在NIPS 2016上发表的,是在频域上做模型压缩的技术。如下图,第一行是算法对模型的神经元参数做压缩的过程。这个图是对当时的卷积神经网络的可视化。这些卷积核本质上还是要提取自然图像里的一些重要信息,如斑点,条纹等。
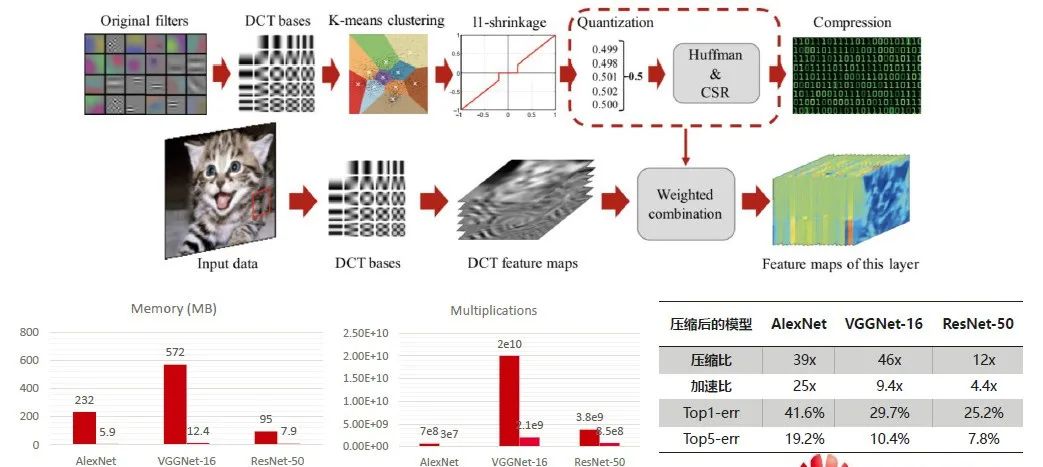
所以我们提出利用DCT做模型压缩。首先把卷积核通过DCT的变换产生频域系数,然后在频域上做K-Means聚类,挖掘卷积核与卷积核之间的冗余信息,最后利用如L1做通过权值最小的剪枝、量化、差分编码,得到压缩模型的文件。
第二行是模型加速。压缩完成之后,我们不希望压缩后的模型在线上推理的时候还要解压缩。所以同时把输入的数据,利用DCT的变化去产生一系列的在频域上的DCT的积,这里面的每一个特征图就可以理解成左侧的输入数据跟具体的相应的DCT的积去做卷积计算,产生中间的特征图。然后跟上面我们在频域做过稀疏的这些卷积核的系数,做一个加权的线性组合,就可以产生压缩后的这一层的特征图。
这里有一个有意思的现象,由于DCT变换是正交变换,所以我们在空域上用原来的卷积核跟原来的图像去做卷积计算生成的特征图,等价于在DCT频域上做卷积计算,这样就可以保证我们在频域上也能实现模型压缩和加速的技术。
上图下方是当时的一些实验结果。从容量上来看,这种模型压缩的技术效果很显著,包括AlexNet,VGGNet,ResNet都具有非常好的压缩比和加速比。但是也有缺陷。虽然呈现出了内存的下降和理论上计算复杂度的下降,但是在实际使用过程中,很难把加速比换成线上推理速度的加速。
基于对抗学习的知识蒸馏方案(AAAI 2018)
除了上述对预训练好的卷积神经网络的卷积核做剪枝的技术,另外一个技术路线是用较大的教师神经网络帮助较小的学生神经网络去学习,希望小的学生神经网络可以达到跟大的教师神经网络同样精度。
通常我们都会把学生神经网络设计的比较小,所以如果它的精度可以跟教师神经网络保持一致的话,学生神经网络的推理速度就可以达到较好的水平。这种模型压缩的思路最早是Hinton提出的,帮助我们更好的学习一些更小的、精度还有所保持的神经网络。
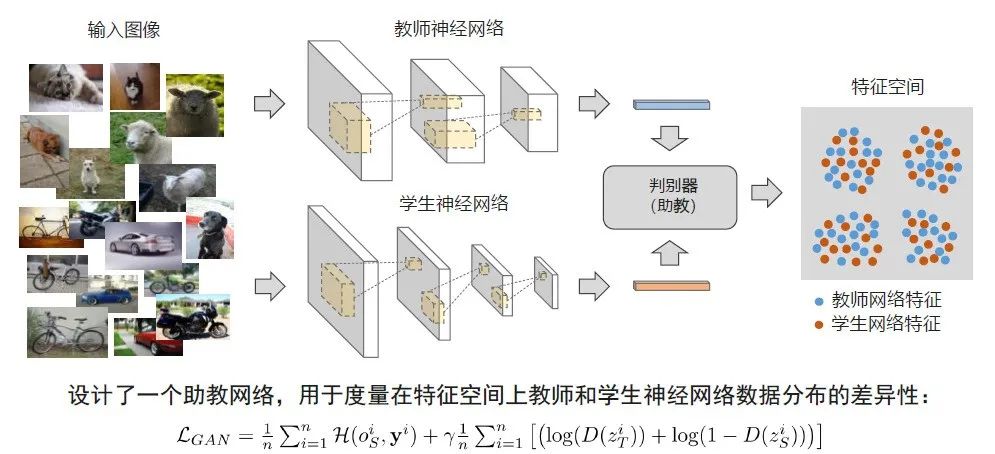
华为提出了一种基于对抗学习的知识蒸馏方法,顾名思义,就是在上述教师和学生神经网络知识蒸馏的过程中,引入了GAN技术。具体来说,在整个PipeLine里面,我们把需要做训练的数据集同时输入给教师和学生这两个神经网络,在得到他们的特征时,加了一个判别器。目的是同时把教师和学生神经网络的特征喂到判别器里面,希望判别器学到最后分不出教师和学生的特征,就会把同一类的特征混到一起,帮助提升学生神经网络的精度。
进行自动剪枝和量化(SIGKDD 2018)
第三个工作是对模型的冗余神经元做筛检。我们提出了一种进化的自动剪枝和量化的策略,发表在SIGKDD 2018上面。前面讲的都是通过人为的先验知识去识别卷积神经网络中有哪些是冗余信息,比如有一个神经元比较小,认为它对输出的特征图影响比较小,我们就把它去掉,这样它的精度一般也不会有损失。这种方法的缺陷是,我们需要逐层去做神经网络剪枝。
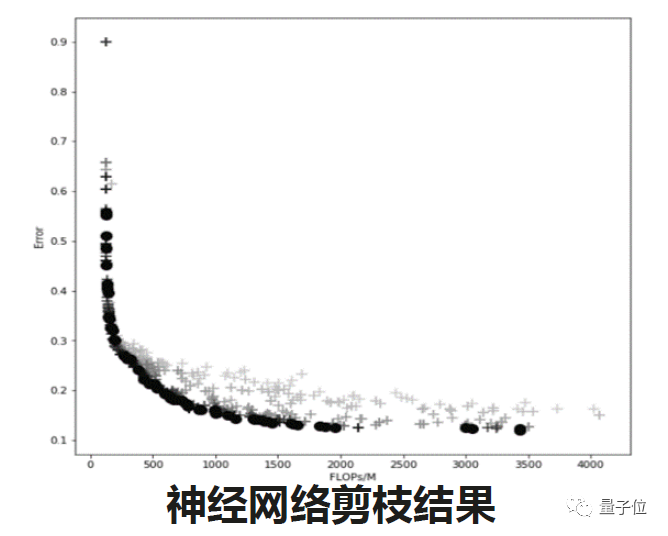
因此,我们提出了一个新的概念,把神经网络的剪枝问题,当做成全局01规划的问题。我们把预先训练好的深度神经网络的每一层每一个卷积核都做01编码,得到一个长的01编码字符串。在进化算法的过程中,就会产生一系列的种群。下图展示了进化算法的实验过程:
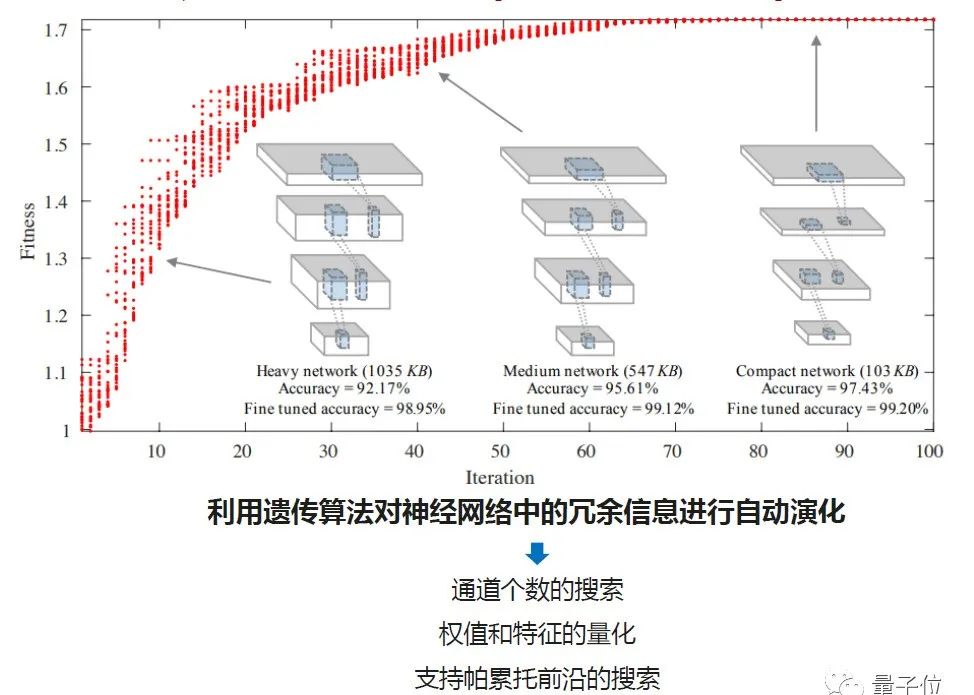
左侧每一个红点都代表了我们在搜索过程中所产生的一个神经网络;横坐标代表算法执行过程中所需要的迭代次数;纵坐标是适应值的函数,在这里面我们用到了个体网络在评价过程中精度的值和剩余的神经网络参数量的衡量指标。我们希望它的精度越高越好,希望网络稀疏度越高越好。指标越高,我们就会得到一个更小、精度更高的网络。
从可视化的结果看迭代过程,在前几个迭代过程中,网络的精度非常低,但是它的冗余度比较高。通过进化算法的逐渐迭代,中间的一些网络会产生更好的表现,但是模型相对还是比较大。在最后的一个优化截止之后,我们得到了一个非常小的网络模型,只有103kb,且最终的精度是99.2。这是一个在MNIST上的非常小的网络,它的BaseLine是1.5G的模型,通过进化算法的优化,差不多可以达到15倍的压缩比。
这种卷积核剪枝跟刚才讲的那种权值剪枝又不一样。由于我们在卷积核剪枝做完之后,有一些神经元直接被剪掉了,就可以直接梳理出比较好的紧致的神经网络架构,我们用这种方式做出来的神经网络可以直接拿到实际过程中,产生很好的加速效果。
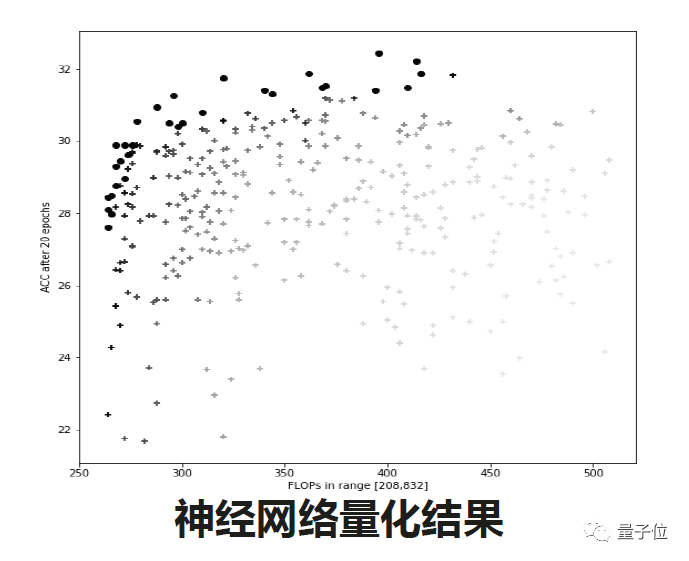
实际应用中做一些项目和产品时会有更多的需求,比如说我们需要对神经网络的权重和激活函数做一些量化操作,然后这里面我们也会引入一些遗传算法做搜索。好处是我们可以把这种帕累托前沿在搜索过程中同时去输出。用户就可以根据自己的倾向,比如说模型体量更小但是精度略低,或者中等体量但是精度更高。
上图是卷积核剪枝的结果,同时可以输出帕累托前沿。这是一种比较简单、好用的技术,在实际项目中我们经常用到。
针对生成模型的协同进化压缩算法(ICCV 2019)
这个工作是自动剪枝和量化的延续。在此之前,大量深度神经网络的模型压缩算法都是在讨论如何在ImageNet、图像识别等任务上做压缩和加速,很少讨论到如何对生成模型做压缩。
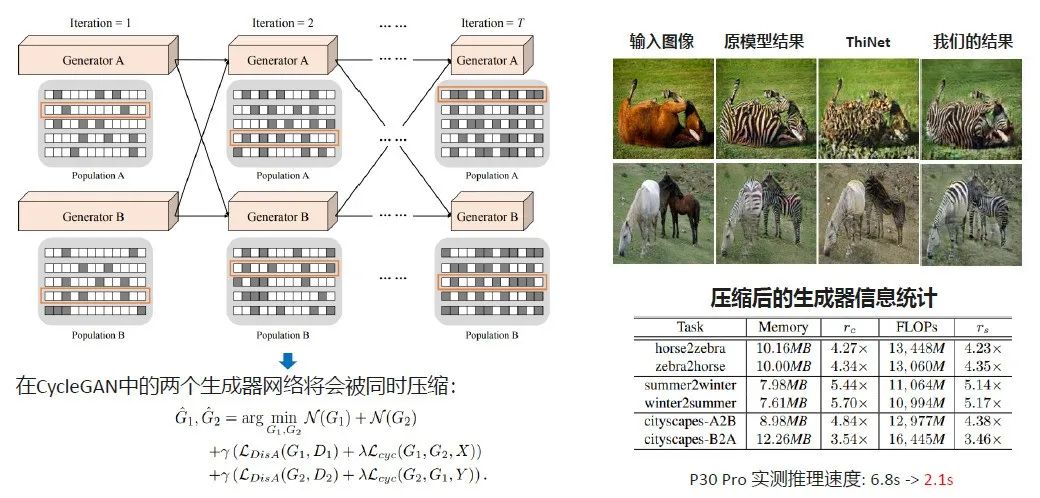
因此我们就提出了协同进化压缩算法,帮助我们把预先训练好的模型做优化,比如CycleGAN。我们把预先训练好的生成器里的卷积核做01编码,0是要保留的,1是要被去掉的。同时由于CycleGAN的原生结构同时要维护两个生成器,所以我们的算法里同时维护了两套种群。两套种群的好处是,我们在整个CycleGAN的结构优化过程中,下一次迭代的生成器A就可以用到上一次迭代里面,找到最优的生成器B的结构,帮助我们做迭代和交互。经过不断迭代直到算法收敛时,就会同时得到A、B两个生成器,同时具有原来的网络性质,并且整个网络的计算量、计算代价都下降了。
在这个工作中,我们提出了用于压缩GAN的一些指标。比如说这里会有一个关于判别器的 loss,就是我们期望压缩后的GAN生成的一些图像,放到原来的判别器里,跟原来的真实图像还是不能区分的,就是说我们还是希望尽可能多的保持图像生成能力。
右上角是一些可视化的结果,第一个是完成的马到斑马的结果,左侧是输入的图像,右侧是原生的CycleGAN输出的斑马图像。如果我们用传统的模型压缩技术,去对这个生成器做剪枝的话,可以看到马到斑马的任务没有办法保持好的效果了,生成的图像质量非常差。
右下角是CycleGAN在六个数据集上的压缩和验证结果。可以看到在实际上我们都可以获得6.8s到2.1s的实测推理速度。这里大家要注意一个问题, CycleGAN的模型并不大,算上压缩比之前的模型大小只有40G,但是FLOPs会非常大,而 FLOPs的计算跟输入图像和每一层的特征图的尺寸是强相关的。这种图像生成模型的特点是输入的图像是多大,输出的图像一般也是那么大,甚至会更大。中间特征图的一些密集的计算就会把FLOPs带的非常高。因此这样的模型加速算法可以把CycleGAN的模型大小、FLOPs计算量都提升4-5倍。
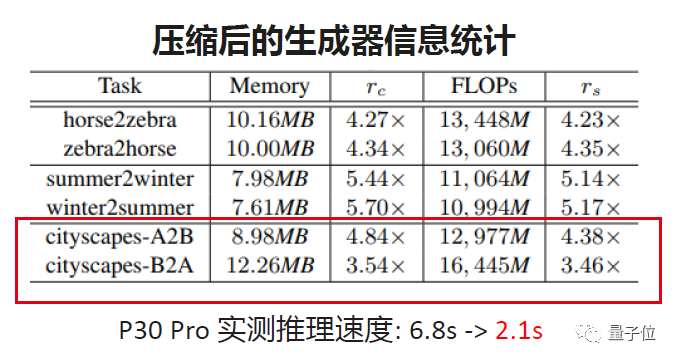
我们还发现一些有意思的规律。由于CycleGAN的设计是两个生成器具有同样的结构、同样的参数量,但是通过这种协同进化压缩会产生不一样的地方。最后一行的数据集是街景图与语义分割图的转化,可以看到在A2B的任务上获得了更大的压缩比,但是在B2A上就达不到如此高的压缩比。原因可能是从真实的街景图到像素图的任务是相对简单的,所以它所需要的参数量和计算量都会相应减少。通过这个发现,希望对未来GAN的设计有一些启发的意义。
高效的单元和结构设计
前面讲的都是关于如何对预先训练好的模型做优化裁剪、线上加速推理。除了怎样去除原来的冗余信息,另外一个技术路线是如何设计高效的单元结构,我们做了很多尝试。
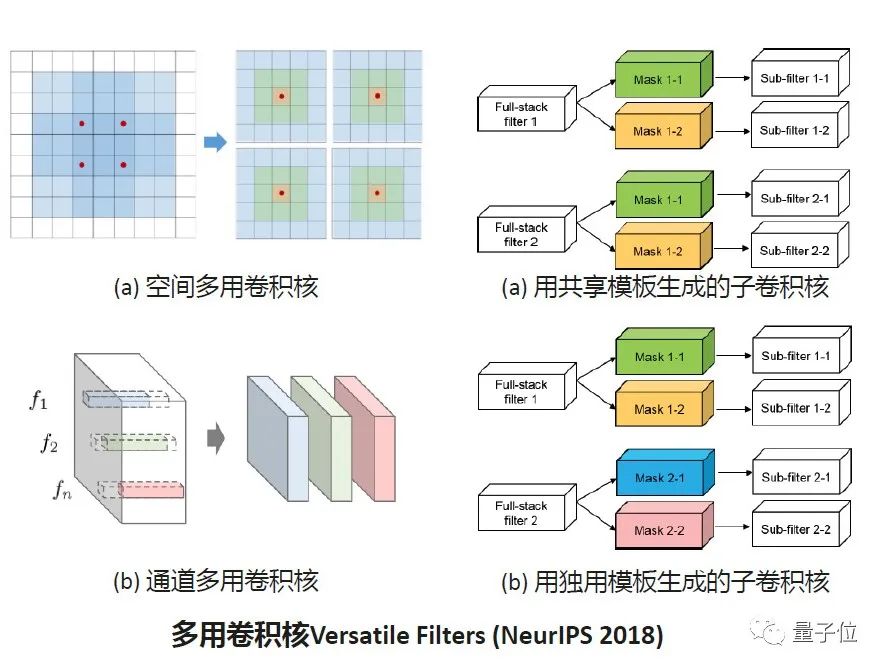
华为在2018年提出了多用卷积核,发表在NeurlPS上。我们发现卷积核的参数量非常多,但是它产生的特征并不多,所以我们的思路是,如何利用预先设定好的卷积核参数产生尽可能多的特征。
在这个工作里,以5×5的卷积核为例,我们会做三次卷积计算,即5×5做一次,3×3做一次,1×1再做一次,那原来的5×5卷积核就可以产生三个特征。原来一个神经网络需要三个特征,也就是说需要三个卷积核,现在只需要一个卷积核。通过这样的参数共享,就可以减少原来神经网络架构设计时所需的参数量和大量的神经计算。
同时我们再把空间上多用的卷积核做扩展,在通道上引入步长的概念,产生更多的特征。通过卷积核的复用,产生更高效的神经网络设计。
右侧是多用卷积核的扩展。我们把全精度的神经网络卷积核,通过边界Mask产生子卷积核,然后复用原来的全精度的参数。但是它是用更简单的一比特的参数量产生的,它的计算也可以通过这样的方式做一个筛检。
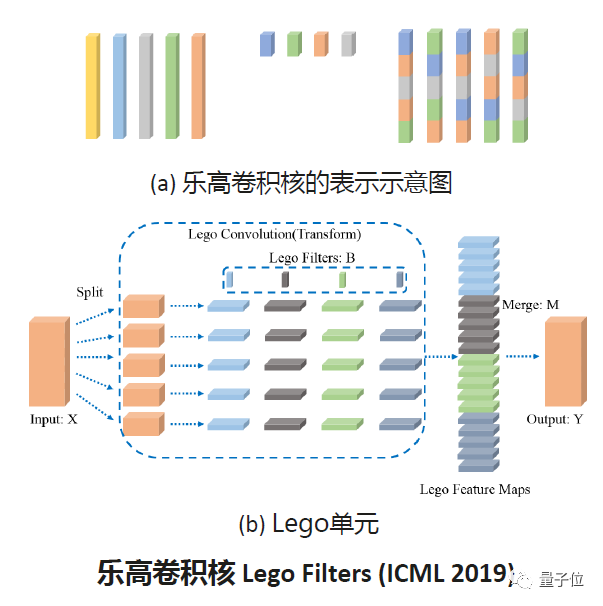
这是华为在ICML2019上提出的乐高卷积核。具体做的事情跟乐高很像,如上图,正常的卷积核就是上方这些不同颜色的长方体,通常都是通道数很长的卷积核。而在乐高卷积核里,我们会生成一些更小的卷积核,其通道数都远远小于原来构建时所需要的通道数。我们在深度神经网络的学习的过程中,不学原来的那些较长的卷积核,而是学习比较小的卷积核和小卷积核在相应位置的排列组合。如图所示,通过学习小卷积核的排序和权值,整个网络的计算量和所需要的参数量就能得到一个非常大的优化。
下方是在实际计算中如何使用乐高卷积核,以帮助我们在线上做一些推理。根据乐高卷积核,我们把输入数据x做一个拆分,逐一做出它的特征图,最后我们再根据上面学到的排列组合以及拼接方式,把它们合到一起产生输出。
这一部分我想分享的是,除了现有的一些神经网络架构,其实还有更多的算子值得我们去探索。谷歌也在不断的提出一些新的操作,比如说DepthWise等。虽然这些工作在现有的一些推理平台上面很难达到实际的压缩和加速,但是我认为这些探索对未来的神经网络架构设计也有重要意义。
GhostNet:业界性能最好的端侧AI架构(CVPR 2020)
沿着刚才讲的路线,我们在不断尝试产生更好的神经网络架构。在今年的CVPR上,华为提出了GhostNet。在没有任何额外的训练技巧,包括学习率、数据扩充等情况下,GhostNet的性能是比较不错的。
我们前期通过对ResNet、VGG以及常见的神经网络架构等大量的观测发现,同一个数据输进去,特征和特征之间的冗余度非常高,经常会出现一些很相似的特征。那么这些很相似的特征能否不通过如此大量的卷积计算去产生,而是通过更简单的变化去产生?
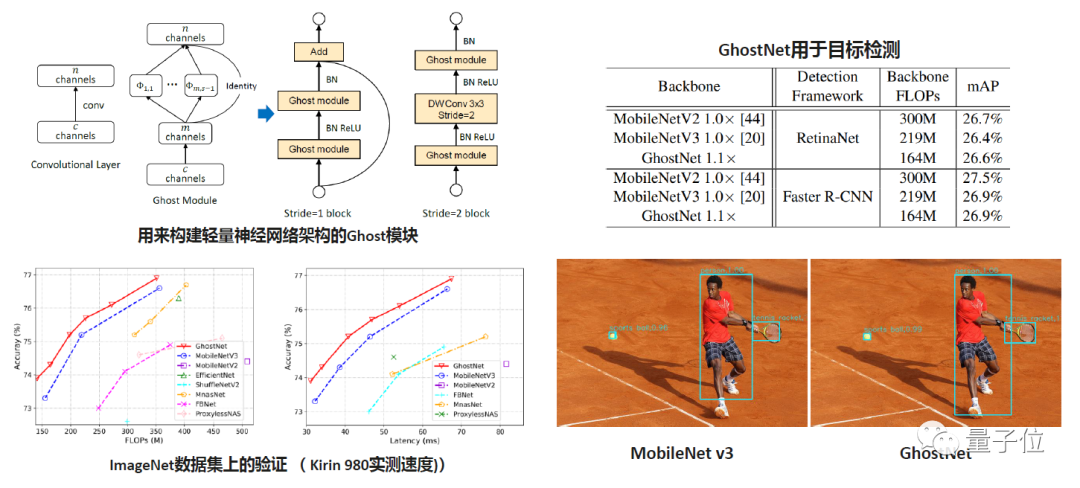
GhostNet的思路是,假如输入的通道是c,正常的神经网络它需要的输出通道数是n,但我们把卷积核的通道数通过一个更小的m表示,在具体的实现里面m=n/2。这里产生的特征图直接喂到输出层之后,剩下的这些特征也是通过这m个通道通过一些简单的变换产生。具体实现时,由于我们主要的目标还是在CPU上产生更好的结果,所以这里用到了DepthWise来代替大量的计算,就构建出了这样的架构。
左下角是一个具体的实验结果,当时GhostNet高于MoblieNetv3。在同样的FLPOS的情况下,精度提高差不多0.5-1个点。实验中我们把这些模型放到端侧设备上,这里我们取了一个Kirin980CPU的测速,可以看到虽然增加了很多DepthWise的操作,但是这个操作在CPU上是非常友好的,在堆积了一些GhostNet模块之后,取得了非常好的加速效果。蓝线也是我们自己复现和测试的MobileNet,可以看到在同样精度下,GhostNet加快10-15%的实测效果。右侧是把GhostNet用于目标检测上,也产生了更好的结果。
AdderNet:用加法替代乘法的深度神经网络(CVPR 2020)
大量的模型压缩算法中,压缩的都是卷积神经网络里所必须的乘法计算。我们的想法是,如果能把乘法替换成加法,它所带来的意义以及能耗下降的指标,是我们现在所想不到的。
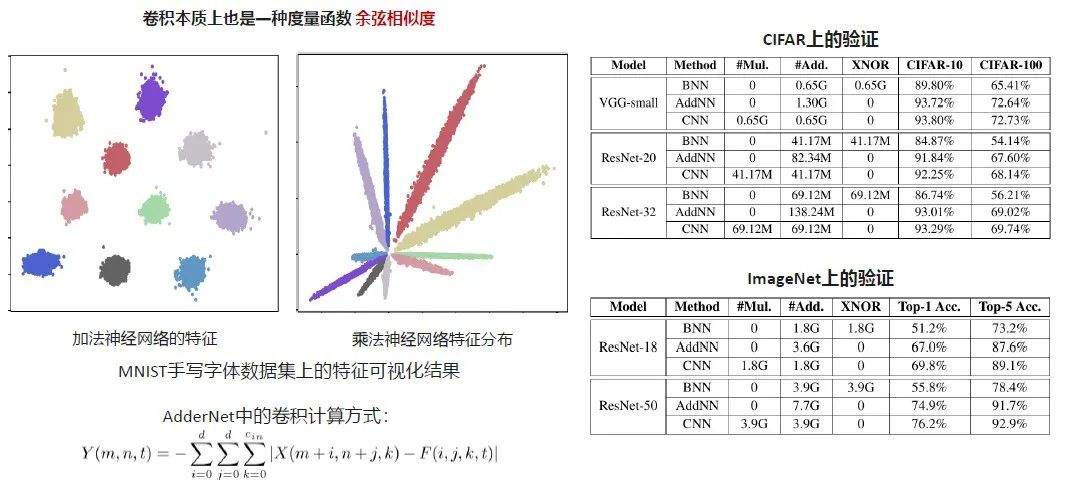
在这个paper里,我们提出卷积的本质也是一种度量的函数,它度量的是特征与卷积核之间的余弦相似度。通过把最后的神经元约束到两个的时候,可以做出很好的特征可视化,左侧的是加法的,右侧的是乘法的。可以看到乘法的特征都是成放射状的,分类器就会根据不同特征的角度做对比,做出每一类的区分。加法的分类器会根据输入数据的类别中心来做区分。
用公式表示这个观测,原来是输入的数据x跟卷积核数据逐位做点乘,然后求和;而在加法神经网络里它就变成另外一种形式,是输入数据x跟卷积核的数据逐位相减,取绝对值,然后再取负数(取负数的目的是为了跟卷积一样,卷积时当x完全等于f的时候,这样的东西是最相似的)。同时我们也配套给这些特征做了BN、ReLU等操作,来保证整个神经网络的训练,另外还运用了学习率调整、梯度clip等训练技巧。
右侧是在图像分类上的验证,性能基本上跟原来的神经网络一致。在ImageNet上面,结果是我们在ResNet50上跟Baseline的乘法神经网络相比,它的精度损失Top5有1.2左右的差距。在我们最新的结果里,我们通过一些额外的训练技巧优化,这种加法神经网络的精度是要比乘法神经网络的精度高一些的。
这里也跟BN做过对比,因为这样的加法计算,其实等价于权重是1比特,激活函数是32比特的计算。这时就会产生另外一个问题,32比特的加法的能耗会比较高。我们最近在做的工作是,把这里面所有的加法的参数、激活函数都换成8比特,得到的精度基本上跟之前保持一致,而且降低了能耗。
我们希望通过加法替代乘法的思路和结果,去改变现有的AI体系框架,实现能耗更低、性能更好的目标。弹幕有同学问开源,我们已经把一些推理的代码、简单的训练技巧公开了,整个的训练技巧我们争取两个月内把开源都做好。
如何对模型架构进行搜索
接下来要分享的是近两年比较热的模型架构搜索。神经网络架构搜索(NAS)概念是谷歌在2016年提出来的,也是用进化算法做种群的概念。把大量的神经网络block和常用单元做了一个堆叠,然后通过进化算法的概念做种群的繁衍和演进。
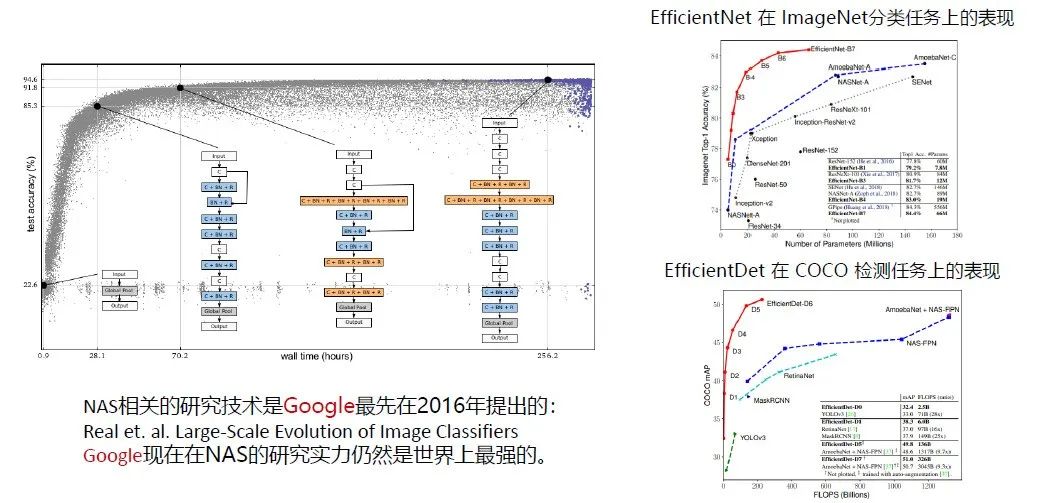
前面是一些非常简单的网络,精度也比较低。通过进化算法,针对精度很高的大的网络做出搜索。由于谷歌的计算资源还有相关的人力投入,现在我们看来谷歌的NAS技术、AutoML技术是比较领先的,以及谷歌EfficientNet、EfficientDet等在不同任务上搜索出来的神经网络框架都比较好。
基于连续进化的神经网络架构搜索算法(CVPR 2020)
先分享一个不一样的概念,在大多数的论文里大家report主要还是以FLOPs、mAP为主,但是这种理论的计算复杂度跟在公司实际应用中模型的实测速度相差甚远。举个简单的例子,如果我们搞了一个DenseNet,把DenseNet所有的卷积核都去掉,但是把Concat,Short-cut等保留,然后测试它的实际的速度还是很慢的。
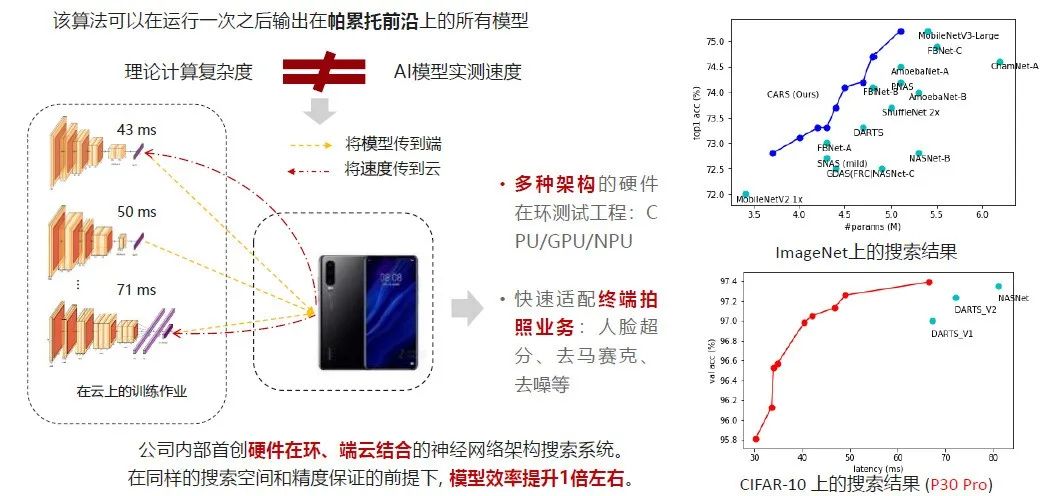
因此我们提出了这个概念,第一步先做一个硬件在环,作为压缩的模型搜索的工具,搜索指标不再是用理论上的计算复杂度,而是实际的模型下发到手机上的推理速度,然后把这个指标返回来,去做模型优化的指标。通过这样的端云协同,就可以把最适合我们当下硬件的模型搜出来。这里面也有一些技术细节,这个算法可以继承我们在上一次搜索中得到的架构的一些参数,每次都更新帕累托前沿上的一些架构和参数,通过这个方式可以在一个GPU上都搜索出来。
跟其他的模型相比,这个结果还是不错的。同样的搜索空间下,我们搜索得到的模型会比相同精度用DARTS算法搜索出来的模型快上一倍(这里不是指训练的速度,而是搜出的模型的推理速度)。通过硬件在环的思路,我们就可以把搜索得到这个模型部署到具体的设备里面,从而达到一个更好的效果。这也反映了,理论上的算法都跟实际的推理速度相差较大。所以在实际的工程项目里,我们都会把AI模型的实测速度当成一个比较重要的指标去做。
轻量的超分辨模型架构搜索(AAAI 2020)
现有的大量NAS算法都是在分类的任务上去跑的,关注底层视觉的模型并不多。
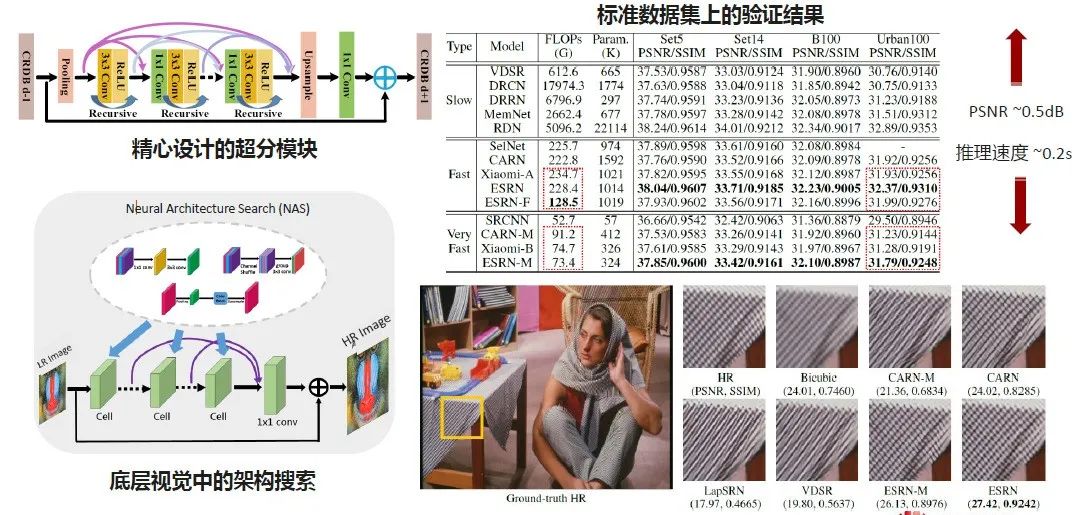
因此提到用AutoML的思路来产生一些更好的模型,这里面对比的CARN算法是当前比较好的超分模型。这里面我们提出了几个比较适用于SR模型的block,然后通过block的组合、连接、设计等做算法的搜索,产生了更好的适用于超分网络的模型。
在标准数据集上的验证结果是,比SOTA超分模型的PSNR高0.5个db左右,推理速度快0.2秒。这200毫秒在用户实际拍照时是能感知到的,推理时间越长,用户的体验就会越差。
底下是一些具体的可视化结果,原图是一张标准的高清图,在同样FLOPs、模型大小等约束下,通过上述算法搜索得到的效果可视化要好于其他的算法。这个论文发表在今年的AAAI上,大家可以去看里面的细节,我们也会在5月底开源。
二值神经网络的等价性问题(ICCVw 2019 Neural Architects)
我们对AutoML还做了更多探索。这个工作是对二值神经网络的等价性做了一个搜索。
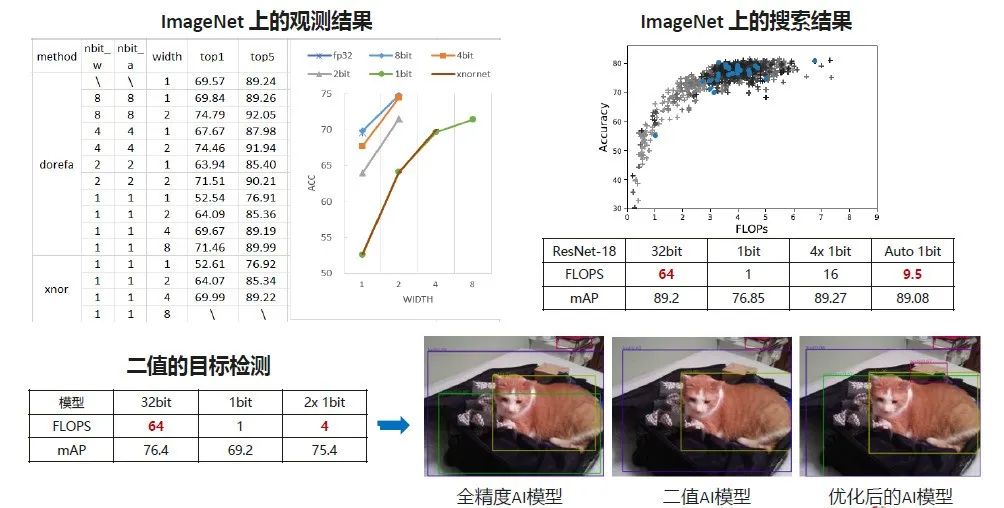
大家都知道,1比特神经网络的精度不是很好,但是具有非常好的能耗、速度、模型大小。我们可以把大量的全精度神经网络的密集计算转化成一种1比特的比较简单的计算。那如何开发具有很高精度的1比特神经网络,是大家一直很关注的问题,在这个方向的论文也比较多。
这个工作前置的观测就是,如果我们把1比特神经网络的宽度做出调整,从1倍调整到2倍、4倍、8倍,发现到4倍的时候,1比特神经网络精度,也就是它在ImageNet上的accuracy可以逼近甚至超越原来的全精度32比特的神经网络。继续扩展,它还会产生更好的结果。
我们在这个方向上做了一个尝试,把1比特神经网络的宽度作为一个编码信息,然后用进化算法做搜索,右上角是搜索得到的结果。我们可以调整1比特神经网络的宽度,去产生精度更高、计算复杂度可控的实验的结果和现象。这个工作的实用性和意义还蛮大的,现在也有一些人关注,也在华为的一些实际项目中用到了。
如何保护用户隐私
接下来要分享的是,我们在做这些模型压缩、加速、搜索的时候,如何去保护用户的隐私。学术界可能不是很关心这个问题,因为很多训好的神经网络都是采用了一些公开的数据集。但在实际应用中,涉及到隐私的端侧App就会非常多,包括人脸解锁、语音助手、指纹识别、一些娱乐APP的应用,基本上都需要用户实时的采集一些自己的隐私数据去完成训练。如果我们想要获取这些隐私数据,用户很可能会感到焦虑。比如之前比较火的一键换脸的软件,面临的隐私问题也受到很大的关注度。
但是如果用户在本地训出的模型,比如人脸识别解锁,体验不好、或者人脸解锁比较慢,想让我们把他的AI模型做一个速度优化的时候,但他不想给我们人脸,只想把他自己的训好的AI应用给我们,这种情况下怎么去做一些模型压缩和加速?我们提出两个解决方案。
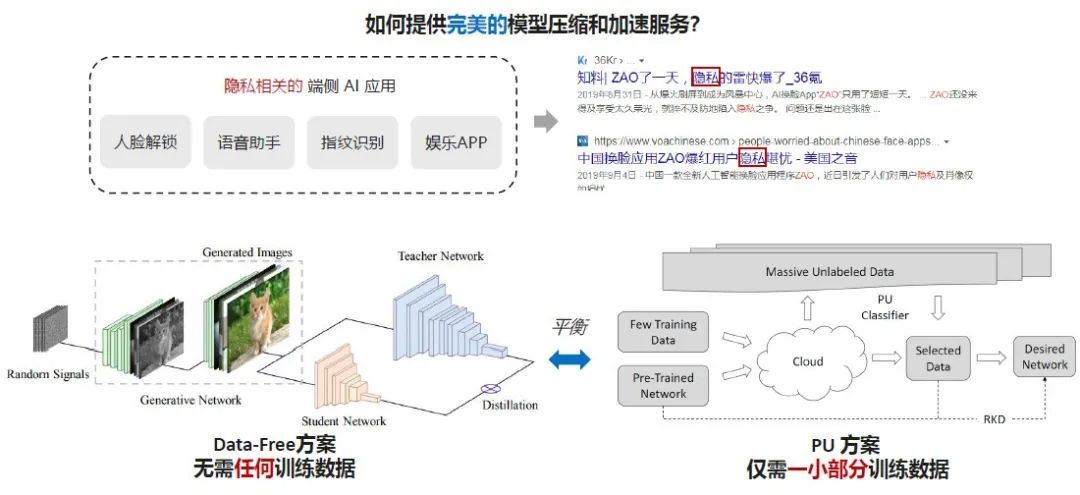
第一个方案是左下角的Data-Free方案,是不需要任何训练数据集的模型压缩技术。我们把用户给到的网络放在这里,网络的结构、权值信息是未知的,我们只知道网络的输入接口和输出特征是什么。在这个方案里,我们有了这样的一个Teacher Network模型,就会有一个想要的Student Network模型,可以根据我们预先需求的速度、大小、能耗等设计好。然后在前面接上一个生成器,把输入的随机信号喂到生成器里面,把生成的图像给到Teacher Network做出信息的提取,并且希望生成的数据在Teacher Network里表示出非常好的性质,这样的话我们就认为它是比较符合原始的Teacher Network所需要的训练数据集的样子。
有了这个生成器和生成的图像,它的label就是Teacher Network所标记出来的,这样的话就可以构建出一个我们想要的数据集。通过这样的方式,再结合Teacher-Student的蒸馏方式,去帮助我们学习小的学生神经网络,就可以产生很好的压缩结果。
第二个方案是上图右下角的PU方案。如果用户只愿意给我们一点点数据,比如说5%的数据,这时我们怎么更好的完成压缩任务呢?这里提出了PU Learning的方式,帮助我们在云上找到我们想要的数据。因为云上通常都有大量的未标注数据,在云上加上一个PU分类器,结合用户给到的一小部分数据,我们就可以获取到对这个任务有用的一些数据。再用原来的Pre-trained Network在这些数据集上做模型的压缩和加速,结合知识蒸馏等,就可以获得一个很好的压缩结果。
无需训练数据的压缩方(ICCV 2019)
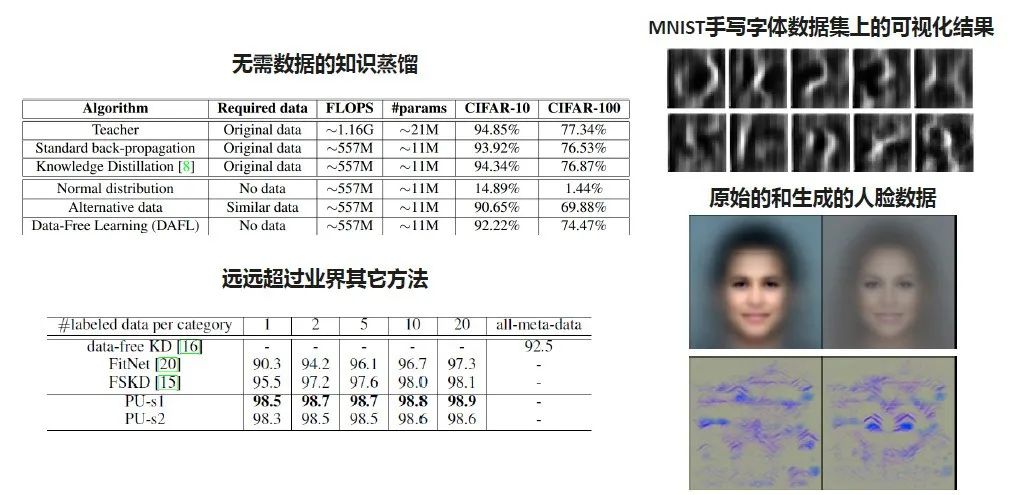
首先我们来看无训练数据压缩方法的可视化结果。右上角是手写字体数据集,我们有一个训好的神经网络,通过Data-Free learning就可以把它每一类的数据做一个模拟。由于这个数据集其实比较简单,所以会产生一些图像的纹理信息。右下角是我们在一些人脸数据集上的结果,由于机器识别时关注的不是整张图,而是人的眉毛、眼睛等特征,所以生成时就产生了一些不一样的纹理。
实验结果说明,用这种方案去学习Student Network在CIFAR-10和CIFAR-100上都达到了比较好的结果。比如原来的Teacher Network在CIFAR-10是94.85,但是如果我们用正态分布的噪声作为原来数据的替代,它的精度是非常差的,因为它可能就会直接被陷入到某一类的识别,Student只能学不好了。
我们这里提到了alternative,把CIFAR-10和CIFAR-100做交换,用CIFAR-100的去代替原来CIFAR-10的数据,然后学出来的精度是90.65。虽然这两个数据集基本上是同源的,并且很像,但由于没有原来的标注信息还是学得不够好。Data-Free的思路可以把Student Network学到92.2的精度,它跟Baseline神经网络精度差两个点左右,差距也是比较大的。这个工作也是希望给做模型压缩、加速的同学提了一个新的思路,如何在做一个端侧AI框架时更好的保护用户隐私。
在云上的PU压缩方案(NeurlPS)
PU是指根据给定的数据,去识别无标签的数据集里哪些是正样本,哪些是负样本,在大量的未标注的数据集里挑出我们想要的、对我们任务有用的数据。
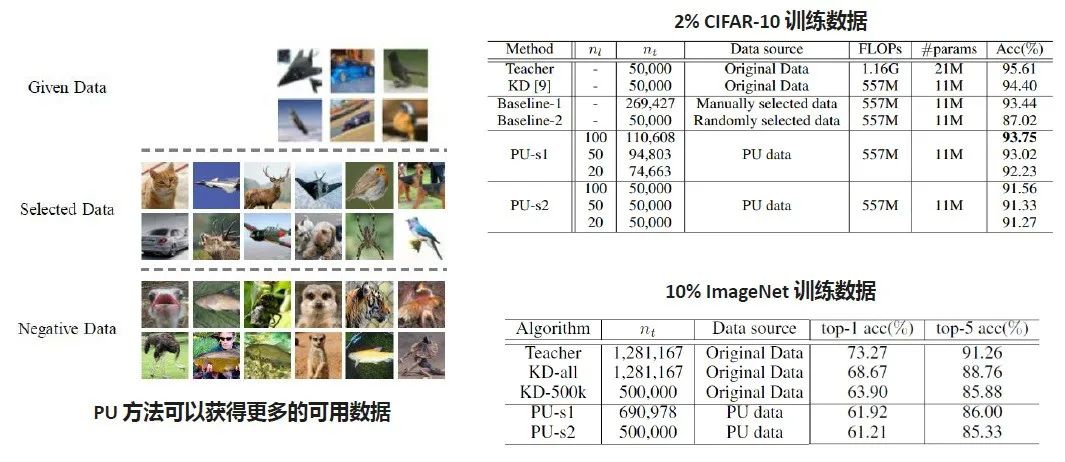
云上PU压缩大概的算法执行过程是:首先通过PU的方法挑选出与用户给定的数据集相关的图像,同时也会排除一些不重要、看起来不相关的数据,由于这里利用了一小部分数据和大量的未标注的数据,得到的结果是非常好的。比如说在CIFAR-10上面,我们只用了原来的2%的数据集,就可以达到93.75的效果。如果我们只有10%的ImageNet训练数据集,然后在更大的数据集上做一些挑选的话,也可以把Student Network的精度训练得很好。这是用一个ResNet50教ResNet18的任务,Teacher是91.26,如果用全量的数据集,Student是88.76;然后用PU的方法,Student可以达到86.0。
这个思路也是很有意义的,我们也在持续不断的投入研究,从完全无训练数据集到有一点训练数据集,两种方向都给出了相应的解决方案,也都获得了比较好的结果。
端侧AI与华为昇腾芯片
上述分享的都是算法层面的论文之类的研究工作,这部分讲一个实际的应用。

这是今年在华为的开发者大会上,做的一个实时的视频风格迁移。比如我们输入一个电影的图像,通过GAN的技术,可以实时产生一些电影。
但这些模型的计算代价其实是比较大的。在华为Atlas200上,它原来的推理速度是630ms,远远超过视频摄像头对实时数据的抓取所需要的速度。
我们通过一系列的模型优化技术,最后把模型的推理速度优化到40ms,15倍以上的差距。如果我一秒想抓20帧图像的话,那40毫秒就足够去完成这样的实时推理的要求了。
在这个项目里面,我们用到了这些技术:
模型蒸馏:去掉原始模型中的光流模块,帮助我们解决稳定性的问题
神经元剪枝:降低视频生成器的计算复杂度
算子优化:在不同的硬件上会有不同的最优算子和最优架构,我们用了AutoML的技术自动地选择最适合Atlas200的AI算子
模型适配:包括多种风格迁移,例如梵高、毕加索等
由于今年疫情的原因,华为的开发者大会也将转为线上。这里是一个风格迁移的现场展示,感兴趣的同学也可以看一看,(链接:https://developer.huaweicloud.com/exhibition/Atlas_neural_style.html)
未来的展望
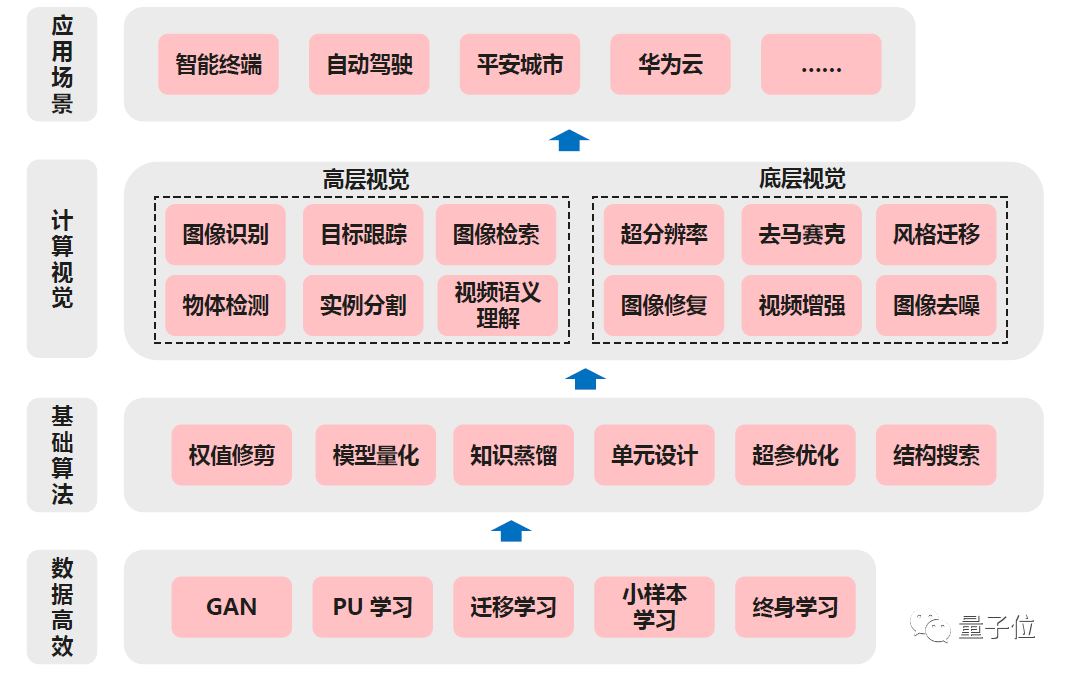
从数据高效的角度来讲,我们会用到GAN、PU learning、迁移学习、小样本学习等,来帮助我们收集更好的数据。
往上一层,端侧AI模型的优化涉及到一些技术算法,也是上面讲到的权值修剪、模型量化、知识蒸馏等。
计算机视觉里需要做端侧AI模型优化的地方非常多,主要是高层视觉和底层视觉两个方向,这里面有大量的研究、工程的空间都是可以做的。
最后,这些东西在华为内部应用场景也比较低,包括自动驾驶、智能终端、平安城市、华为云等。

我今天分享的所有内容,在Github的开源连接(上图二维码)都能获取。我们近期还会开源诺亚实验室的一个AutoML的平台—Pipeline,里面会集成我们更多同事的一些更好的东西,以及很多成功的案例,来帮助大家做AutoML的技术,谢谢大家。
传送门
本期直播回放链接:https://www.bilibili.com/video/BV1xT4y1u7Re
PPT获取链接:https://pan.baidu.com/s/18x2kJWZeYltu2WSMgi9NVg
提取码: x49q
最后,云鹤老师经常会在知乎上分享他们的研究成果,包括最新的Paper、开源链接等,欢迎大家关注云鹤老师的知乎专栏:

— 完 —
5.31号(本周日)晚7点,腾讯云资深架构师何书照老师将直播分享,欢迎识别下图报名:
直播报名 | 腾讯云音视频解决方案技术专场


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !




