传统算法和深度学习的结合和实践,解读与优化 deepfake

AI 研习社按:本文为知乎主兔子老大为雷锋网 AI 研习社撰写的独家稿件。
前言
前一段时间用于人物换脸的deepfake火爆了朋友圈,早些时候Cycle GAN就可以轻松完成换脸任务,其实换脸是计算机视觉常见的领域,比如Cycle GAN ,3dmm,以及下文引用的论文均可以使用算法实现换脸(一定程度上能模仿表情),而不需要使用PS等软件手工换脸(表情僵硬,不符合视频上下文),只能说deepfake用一个博取眼球的角度切入了换脸算法,所以一开始我并没有太过关注这方面,以为是Cycle GAN干的,后来隐约觉得不对劲,因为GAN系列确实在image to image领域有着非凡的成绩,但GAN的训练是出了名的不稳定,而且收敛时间长,某些特定的数据集时不时需要有些trick,才能保证效果。但deepfake似乎可以无痛的在各个数据集里跑,深入阅读开源代码后(https://github.com/deepfakes/faceswap),发现这东西很多值得一说的地方和优化的空间才有了这一篇文章。
本文主要包括以下几方面:
解读deepfake的model和预处理与后处理的算法以引用论文。(目前大多文章只是介绍了其中的神经网络,然而这个项目并不是单纯的end2end的输出,所以本文还会涉及其他CV的算法以及deepfake的介绍)
引入肤色检测算法,提升换脸的视觉效果。
干货和口水齐飞,各位客官可安心食用
DeepFake Model
虽然原作者没有指出,但从模型和整体方法设计来说,该模型应该是参考了论文https://arxiv.org/abs/1611.09577,其网络结构总体仍是encoder - decoder的形式,但与我们所熟知autoencoder不同的是,他由一个Encoder和两个Decoder组成,两个Decoder分别对应imageA和imageB的解码。
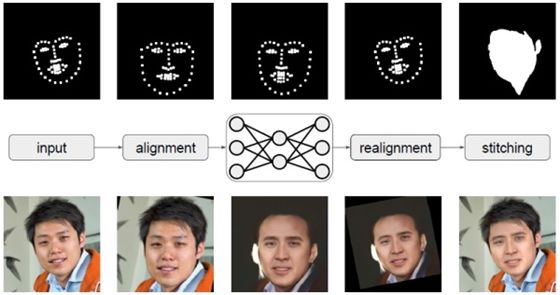
Encoder部分用了简单的堆叠5x5卷积核,采用aplha=0.1的LeakRelu作为激活函数。Decoder部分使用了卷积和PixelShuffer来做上采样,结构上采用了4x4,8x8……64x64这样逐分辨率增加的重建方式(网络整体是类U-net的结构)。

(图为u-net)
如果你想要复现和改进模型的话,需要主要一点的是,虽然我们期望输入A脸然后输出B脸,输入B脸输出A脸,但训练却不把AB脸作为pair输进神经网络(输入A脸,期望在另一端获得B脸),仍然是像训练普通autoencoder的一样,我给出A脸,你要复原A脸,B脸亦然。(用不同的decoder),这样训练的结果是decoderA能学会用A的信息复原A,decoderB用B的信息复原B,而他们共用的Encoder呢?则学会了提取A,B的共有特征,比如眼睛的大小,皮肤的纹理,而解码器根据得到的编码,分别找对应的信息复原,这样就能起到换脸的效果了。
而Encoder获取到共同的特征,比单独学习A的特征,信息要损失得更为严重,故会产生模糊的效果,另一个照片模糊得原因是autoencoder使用得是均方误差(mse)这一点已经是不可置否的了,后文提及的使用GAN来优化,可以一定程度上缓解模糊的问题。
预处理和后处理
在文处,我就强调了这个不是end2end的东西,接下来就着找介绍deepfake里的预处理和后处理。
我们都知道在CV里用深度学习解决问题前,需要用进行数据增强,然而涉及人脸的数据增强的算法和平时的有一点点不一样。
在开源代码中,作者分别使用了random_transform,random_warp 两个函数来做数据增强。但这个两个函数只是做一些有关比例之类的参数的封装,真正做了转换的是opencv的warpAffine、rmap两个函数。下面分别解读这两个函数做了些什么。
首先解读rmap其直译过来就是重映射,其所做的就是将原图的某一个像素以某种规则映射到新的图中。利用该函数,可以完成图像的平移,反转等功能。
在数据增强中,我们不希望改动数据会影响label的分布,在常见的有监督任务中,数据的标签由人工打上,如类别,位置等,图像的扭曲,反转不会影响到label的分布,但在deepfake中,我们做的是生成任务,作为无监督任务中的一种,其反向转播的误差由图像自己的提供,而要使得数据增强后(代码中的warped_image)有对应的样本(代码中的target_image),作者使用了rmap构造除warped_image,而使用umeyama和warpAffine构造出target_image。
Umeyama是一种点云匹配算法,简单点来理解就是将源点云(source cloud)变换到目标点云(target cloud)相同的坐标系下,包含了常见的矩阵变换和SVD的分解过程,(碍于篇幅本文不作详解)。调用umeyama后获取变换所需的矩阵,最后将原图和所求得矩阵放进warpAffine即可获的增强后对应的target_image。其中warpAffine的功能就是根据变换矩阵对源矩阵进行变换。

上图是经过变型处理的warped_image ,下图是target_image。
后处理
说完了数据增强部分后,我们来分解后处理。
在deepfake(上述链接中)的命令行版本中,有一个-P参数,选中后可以实时演示图片的变化过程。在通过预览这个演变过程中,不难发现进入神经网络的不是整张图片,也不是使用extract出来的整个256x256的部分(头像),而是仅仅只有脸部的小区域(64x64)。因此在预测阶段,首先就是截取人脸,然后送进网络,再根据网络的输出覆盖原图部分。
至于将头像部分传进网络,也并非不行,脸部还是会可以进行转换,但背景部分也会变得模糊,且很难修复,因此我们只选择脸部替换。
在脸部替换后,会出现如下问题:
肤色差异,即使是同种人,也会有细微的差异。
光照差异,每张照片的光照环境不同
假脸边界明显
前两者的造成原因一是客观差异,二是和数据集的大小相关,作为想给普通的用户用,数据集太大了,用户承受不起,数据集太小,神经网络学习不多。
至于最后一点则是前两者造成的,但这一点可以通过降低分辨率缓解。这也是很多网上小视频假脸边界不明显的原因,因为很少会有一张脸占屏幕80%的画面。但如果你直接用在256x256的头像图上则边界效果明显,如下图:

(原图,下文所有图片的原图都是这个,由官方提供)

该图使用的是官方提供的预训练权重和数据。接下来在试试低尺寸下的视觉效果:

相对来说,边界效果没那明显了。
至于另外的两个问题,官方给出了下面的几种后处理方法缓减:
smooth_mask
这个方法解释其实起来很简单,你神经网络输出的图像不是很模糊吗?要模糊变清晰很难,但清晰变糊还不简单吗?直接用高斯模糊将边界进行处理,从而让过渡看起来自然。
adjust_avg_color
这个方法背后的理论同样很简单,假设A图要换成B图,那么做法就是A图加上自身和B图的每一个像素的均值的差值,算是作为一种色彩的调和。

(左图未经处理,右图经过上述两种方法处理)
以上两种便是deepfake默认的处理方式。下面介绍另外一种图像编辑常用的算法,这种算法作为deepfake的后备选项,由参数-S控制。
泊松融合
此外,deepfake给出了基于泊松融合算法的来进行后处理,泊松融合的大致思想提供一个一个mask矩阵,背景区域为0,ROI区域(region of insteresing 这里就是指脸部,下文同一简称ROI)的区域为255,算法通过该矩阵得知拿一步分是融合的部分,然后通过计算梯度,用梯度场作为指示,修改ROI的像素值,使得边界与原图更为贴切。

( 图片源于网络)
Deepfake中的泊松融合可以选择两种模式。一种以人脸矩形框为边界,另一种以人的特征点(即人脸边界和眼睛边界)为边界。

(左图未经处理,右图在整个替换区域进行泊松融合)
事实上,这里得补充一点,人脸检测和定位如果不想自己实现,一般有两种实现方法(在本地实现),一种是使用dlib库提供的api,另一种是使用opencv。dlib,face_recongize的模型比opencv的精度要高的,但要自己下载模型(模型比较大),且这个库的编译在windows上比较麻烦,但对于特征点检测,opencv没有现成的特征点检测的接口。如果有同学不想依赖dlib,这里提供一种方法来代替在泊松融合时的特征点定位问题。(人脸检测可以使用opencv即可)
肤色检测
显然,我们选择人脸的特征点的位置信息,目的时为了只替换人脸,这样可以尽量将信息损失(模糊)局限于人脸部分,而其他部分则保留原图的清晰度,而我们刚才说过了,deepfake并不将全图放进神经网络,而是将人脸部分(由人脸检测算法确定),定位后的ROI是以人脸为主的矩形,这时唯一的肤色就只有人脸部分了,不用太过担心其余噪音干扰。
如果再人脸定位这一步出错,那么使用肤色检测还是人脸特征点两种方法,都不会有太大差别。因此,使用肤色检测在这种场景上,在效果上一定程度能代替人脸特征点检测这种方法。
下面解释肤色检测如何使用。总的来说,肤色检测一般常见RGB,HSV和YCrCb空间的检测,所谓的YCrCb空间,Y代表的是亮度,Cr与Cb代表的都是色度,而HSV空间H代表色调,S饱和度,V亮度,RGB则是常见的红绿蓝空间。
下面只介绍RGB空间下的肤色检测,无需依赖其他库,手写即可,亦可以达到不错的效果。
检测规则如下:
R>G and R>B and |R - G| > 15
在(1)满足下,(R > 95) and (G > 40) and (B > 20) and (max(R, G, B) - min(R, G, B) > 15)
在(1)满足,(2)不满足下,(R > 220) and (G > 210) and (B > 170),则可认为该像素是肤色。
(左图未经处理,右图经过肤色模型构造mask矩阵,再进行泊松融合)
可以优化的空间
最后说说deepfake可以优化的空间。
Deepfake出现后也有很多工作对deepfake进行优化,包括使用GAN的,这些优化的针对生成图像的质量,但目前看质量没有太大的提升,同时几乎没有工作是针对模型的训练速度和图像的后处理。
本文最后提出的肤色检测代替原来人脸特征点检测的,算是一种补充。
我也曾经尝试过一些模型压缩的算法,虽然在原始数据下可以恢复精度,但迁移的能力差(因为参数少了)。而deepfake的目的是做成一款app,(已经有了,叫fakeapp,在deepfake的基础上添加了图形界面),那么就不能不考虑软件的体积,fakeapp共1.8G,以及没有GPU的普通用户在自己数据集上迁移的时间。
在Reddit上,作者是指出,在GPU上模型训练要几小时,而CPU要近3天,这已经超出很多人的忍受范围了。
深度学习走入寻常百姓家,尤其是有自定制需求的深度学习,仍然任重道远。

NLP 工程师入门实践班:基于深度学习的自然语言处理
三大模块,五大应用,手把手快速入门 NLP
海外博士讲师,丰富项目经验
算法 + 实践,搭配典型行业应用
随到随学,专业社群,讲师在线答疑
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
刷爆朋友圈的 deepfakes 视频人物换脸是怎样炼成的?
▼▼▼




