Rethink Deepfakes,浅谈深度学习落地

AI 科技评论按:本文为兔子老大为雷锋网 AI 科技评论撰写的独家稿件,未经许可禁止转载。
最近关于生成模型有两件事情得到广泛的讨论,其一是 Nvidia 的基于风格的 Style GAN 生成足以以假乱真的人脸高清图(1024x1024)[1],另一件就是一篇论文 DeepFakes: a New Threat to Face Recognition? Assessment and Detection[2] 表明了 DeepFakes 生成的假脸足以欺骗大都数较为前沿人脸识别和检测系统。借着这两件事,诞生于 2017 年末的,后又被封禁 Reddit 讨论区的 deepfakes 再度进入我们的视野中,那么时隔一年,deepfakes 此刻又取得了什么进展?
除了 Deepfakes 外,另外一个热点话题就是关于深度学习在工程上的落地问题。
本文希望通过 deepfakes 从初版到现在版本的演变,来思考一下深度学习的落地和发论文之间,存在着什么差异。
什么是 Deepfakes,原理是什么?
在 Rethink Deepfakes 前,先回答一个可能初次接触 Deepfakes 都可能会有的问题,为什么要这样设计,而不是使用 Cycle GAN?
看一幅图(图一):

此图为 Cycle GAN 在同样数据集(Trump,Cage)上的实现效果,其中第一列和第三列为输入,第二列和第四列为相对应的输出。
对于 successful example,生成图像清晰,转换是全局的转换(Deepfakes 是局部的转换,这一点后文会说),而对于 failed example 则问题比较多:
首先显著的一点是表情不能一一对应,其二是出现混杂无意义的像素。
对于第二点,其实 Deepfakes 也会有,Deepfakes 作为一个工程项目有一定的手段来应对这一点,但第一点是一个 fatal error,如果表情神态都无法保证对应,输出再清晰也毫无意义。
至于为什么会造成这个原因,在介绍 DeepFakes 后会给出我的解释。
我们得知 CycleGAN 在这里的局限,CycleGAN 保证了语义上的转变,却没法保证一些细节问题,接下来介绍 Deepfakes 的初始结构。
首先,DeepFakes 的整体架构是 denoise autoencoder,作者做出了一个假设:对于任意人脸 A,经过仿射变换后得到 WA ,其中 WA 等价于任意一张脸,即任意一张脸都是 A 扭曲而来的,所以如果网络能学会从 WA 去噪修复至 A,那么网络就能将任意一张脸转换成 A。
而在网络结构的设计上,作者也应该花了一番心思。其在编码器中采用全链接层破坏了之前卷积层提取的特征内的空间关系,让每一个像素之间都充分运算,而在解码器中采用 PixelShuffler 结构亦是如此考虑,在 [3] 中,有知乎用户提出,如果省略这些结构,该模型会退化成 AutoEncoder,得不到想要的结果。
整体网络共用一个编码器,分用两个解码器的目的是让编码器学习到更丰富的脸部特征,把不同的人脸都编码在同一个隐空间上,再通过不同的解码器用不同的方式“重构”回来。
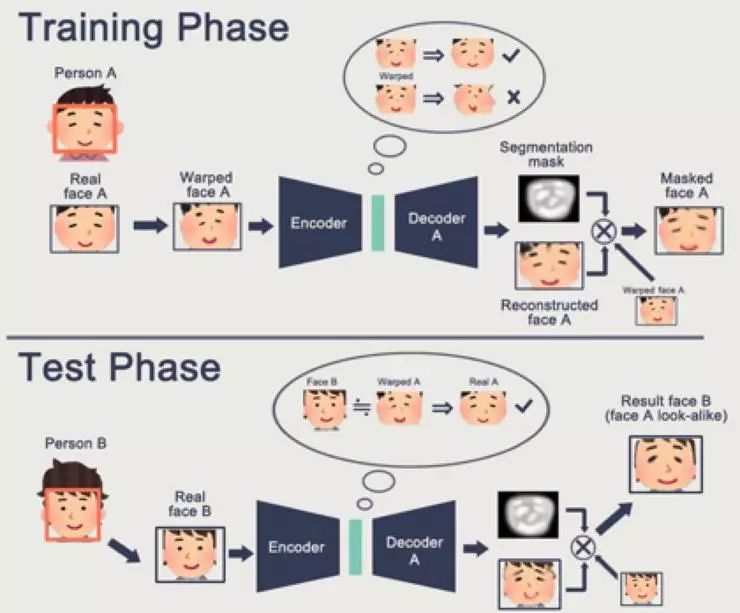
图片来自[4]
不过有趣的是,乍一眼看过去,无论是假设和设计都独出心裁,但在 2017 年末设计的模型竟然没有用到一些在 CV 领域内常见的设置,比如残差结构,甚至是连 norm layer 都没有使用,也没有把图像缩放到[-1,1],而是[0,1],有相关文献提出,残差和 norm 都能起到平滑 loss 曲面的作用,后续的改进更改了这三点,有助于模型的收敛。
原版 DeepFakes 的输出效果如图所示:

第一列和第四列为原图,第二和第五列为重构结果,第三和第六列为换脸结果,可以观察到,deepfake 原版转换中人脸的表情细节得到了保留,但比 GAN 生成的结果要模糊。
成因分析
1. 对于 CycleGAN 的结果,我们可以分析其 loss,CycleGAN 是如何衡量 A 转换到 B 的?没错,对抗损失。无论是 KL 散度,JS 散度……都是衡量两个分布之间的距离。由基本的概率论知识我们可知,当 X,Y 同分布的时候,我们指 X,Y 在概率上具有相同性质,如 EX=EY,但不能得到 X=Y,这就说明了 GAN 具有很强大的”创造力“。同时,当数据量不够时,GAN 的训练是有问题的(因为数据不能很好的代表分布,容易发生崩塌到生成某个特例上)。在数据集中,cage 具有较少侧脸数据,而 trump 则相反,故 trump 侧脸转换时基本都是失败。如图一第三行,第一二列。
同样的问题,在 cyclegan 应用于马和斑马的转换的过程中,也可以观察到。

而这些问题,在使用 MSE 和 MAE 这种逐像素误差作为优化目标时,可以得到缓解。
2. DeepFakes 也并非完美,其一是因为使用 MAE 作为 loss 具有均值性,会导致图片模糊。其二,WA=任意一张脸,这个假设是有局限的。
第一点,将男脸 A 换成女脸 B,比女脸 A 换成女脸 B 先天要困难。
第二点,这个假设局限了只能在五官周围一部分进行转换,且人脸对齐与否,仿射变换的参数都会对结果造成影响。改进版的 DeepFakes 每一个模型插件都对应不同的仿射变换参数,且花费了大量的功夫对人脸进行预处理。而 cyclegan 对预处理的要求没有这么高。正是因为只能在局部进行变换,且原模型的生成图片大小固定在 64x64,因此生成后几乎必然还要做一次 resize,原本模糊的人脸会进一步模糊。
第三点,这一点则完全是对数据的理解能力了。在美图横行的时代,若只考虑五官数据,部分女星的人脸数据五官部分区分度极低,造成效果令人不满。
改进
在分析问题后,首要也是最为容易解决的问题就是清晰度问题。
对于生成图片的清晰度问题是因为 MAE 的均值性,这一点我们可以通过引入 GAN 来进行解决,目前在 [4] 作者引入两个 Discriminator,分别对应于 AB 图片,如同 cycleGAN,甚至引入了 cycle consistant loss,而在官方的项目中,作者像在 pix2pix 中,一样引入了 conditionGAN,除了判别真假,还能判别是否配对。
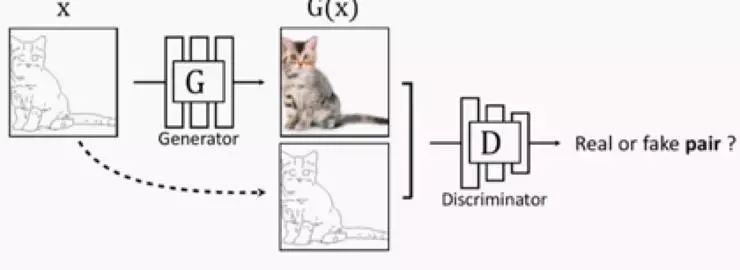
而在我的实验中,因为已经判定 deepfakes 是一种 denoise autoencoder 的思路,所以只需引入一个 Discriminator,用于补充生成图片的细节,而不考虑 A 与 B 的差异。如同其他 SR 和 denoise 的任务一样。 这样得出的结果在视觉上是相仿的,一来可以省点参数,二来如果 A 和 B 任一个的数据量不大时,其实这样会使训练更稳定。 其中特别指出的,gan 虽然会使得图像变清晰,但并不能保证细节和原图一致,这就涉及两种应用场景。更注重视觉效果还是更注重细节恢复,显然 Deepfakes 是前者,所以引入对抗,是可以接受的。

可以看见 GAN 得到的结果要比没有 GAN 的结果更为清晰,但同时亦有另外一个问题,当 A 没有胡子时,B 的训练样本具有胡子时,GAN 会抓取到 B 具有胡子的特征,在 A 转换 B 时,会自动加上胡子。如果 AB 任一方具有眼镜,而另一方没有,那么转换效果亦然。
为什么要提这一点,因为虽然从常识理解,GAN 这种"添油加醋"是不正确的,但事实上,我们不妨从人类自身出发,以人类感知来说,我们是如何判别 A 是 A?
很简单,相比五官,这个人是否有胡子,眼镜,发型也同样重要,其实五官单拿出来,对人来说辨识率其实不高。如果是全身照,身体的体态也同样重要,那么如果一个常年以有胡子的形象示人的人,你看到他没胡子的形象,反而感觉违和了。所以 GAN 从数据中抓取主要特征,导致多了胡子,其实不是什么主要问题,更重要的是解决视频转换中,胡子这种特征会在某一帧中突然丢失,产生的违和感要更重一些。
为了解决这点问题,在 [4] 中以及 DeepFakes 的官方更新中,都采用了 Mask 机制。Mask 网络和生成网络共享编码器和解码器除最后一层外的其他所有层,最后一层生成一个数值范围 0~1 的 Mask,假设生成的图片记为 G,原图为 S,那么最后采用的图片为
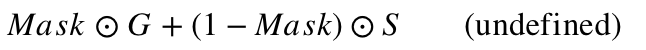
通过这个方法,让模型自己学习图像需要转换的部分。

图片来自于 [4] 的项目主页
关于 GAN 的架构再谈多几点,曾经我也有过疑惑,目前这么多图像转换或图像编辑中,为什么更多的是用 StandardGAN 的 loss,而其他无论理论和结果都很漂亮的 GAN(如 WGAN-GP,SAGAN)却很少用到。而经过一番讨论后得到的结果便是,这些 GAN 带来的差别,不如在论文中贴一张好看的图。结果令人无语,但很现实。
这一现实可能有以下几点原因:
1.任务类型不同,目前发现惊人成果的 GAN,多是在随机分布生成图片,而图片转换多是在 encoder-decoder 的结构下改进,后者比前者多了一个 encoder 对图像进行编码,额外的先验信息可能降低了对生成器的结构的依赖。
2.GAN 评价本身存在局限。
在知乎中有知友在 [5] 和 [6] 中指出了 IS 和 FID 两种评价的不足,GAN 作者本人亦提出新的评价 GAN 的方法,但并没有引起多大反响。
在我看来,不同的 GAN 肯定是有差别的,但至少在图片视觉效果上没有到非应用另一种 GAN 不可。
在 [4] 中作者引入了 self-attention 机制,即 SAGAN,且 self-attention 的层数比 SAGAN 要多,而在官方的改进版中,并没有引入这一点,我按照 SAGAN 的结构,加入 self-attention,得出如下的生成结果:

可见,相比引入 self-attention 和 SpectralNorm 带来额外的计算量,SAGAN 并没有给 Deepfakes 带来足够的优势。
在探讨完 loss function 对清晰度的影响外,来谈谈影响清晰度的另外一个因素,尺寸问题。
尺寸的问题很简单,现在生成模型连 1024 的图像都能生成,高清人脸不是问题。但在这里想大家思考一个问题,DeepFakes 真的需要生成一张高清人脸吗?或者是什么时候需要?
在前面简述 Deepfakes 的原理时,我们提到,最好不要除去全连接层,那么此时增加图像尺寸,必然会导致全连接层的参数暴增,导致延迟用户在自己数据集上迁移的时间。
我们需要准确认识到尺寸在 DeepFakes 对应用场景上的影响,市面上换脸的场景大概可以分为两种,第一种是如之前“军装照”,这属于单张照片的换脸,另一种是合成视频影像。
前者,人脸多占图像的绝大多数部分,这时产生高质量的人脸是重要的。后者中,人多是以半身照出现,人脸的分辨率对感知影响不大,而此时产生高分辨率图像后,还需 resize 会低分辨率,同样会造成细节的损失。
数据质量对 DeepFake 的影响
在数据挖掘和机器学习领域,有一句话特别被强调,即 Garbage In,Garbage Out.数据质量决定了模型的上限,这一个特点,在 DeepFake 中体现得淋漓尽致。
前文提及 DeepFake 的关键假设在于认为 Wrap face = any face,从而采用了 denoiseGAN 的结构,那么不难想到,除了使用仿射变换制造噪音脸部外,是否有其他方法?答案是有的。在 [4] 中,作者使用了 probrandomcolor_match,交换两张不同人脸颜色的均值和方差来制作噪音,以及 motion blurs,运动模糊来损坏原脸,同时这两种处理方法亦可视作是一种数据强化的手段。
除此之外,为了让模型更好的训练,使用了 eye-aware(做了眼部对齐),edge loss 以及上文提及的 Mask 机制,更改了官方原有的 Dlib,改为 MTCNN 来做人脸的定位和关键点定位,以及人脸对齐等操作,获得更好、更灵活的数据。因为 Dlib 在侧脸和有遮挡的情况下表现比 MTCNN 要差。
对于数据的干扰不仅仅包括数据的预处理,也包括其后处理。
在获取模型输出后,需要映射回去,这时需要用到图像融合的手段,如高斯模糊,泊松融合这些传统图像处理的方法也得以施展拳脚。
我们不难得知,不论是 [4] 还是官方的项目,在第一版的 DeepFakes 后进行的改进中,在模型的 layer 上只是采取了场景的 NormLayer 和 ResBlock 等常见的手段,而并不是重新发明一个更厉害的网络结构或者用上一些高大上的 layer 和理论,而是把心思放在数据的干预上和对问题建模的重新思考。
论文和工程区别
在回顾完 DeepFakes 的发展历程,不难得出一些和我们平常写论文时思路的区别。首先明显特点就是在论文中,我们更注重论文的可发性。比如论文的工作是否潮流,理论是否漂亮。比如深度学习火了后,各种领域都用上了深度学习,有些是突破,有些就是为了吸引眼球了。而在 GAN 火了后,又纷纷涌入 GAN。而在工程上,很大程度要抛弃这种新潮模型==效果好的态度,在知乎问题 [7] 上有对这个问题的更广泛的讨论。在上文中亦体现了 SAGAN 相比使用 LSGAN 来说,在 DeepFakes 上没有带来足够的优势。
其次一点是要理解论文的一些套路。很多东西,比如一些对实验结果的统计陷阱,或者对结果的展示的挑选,都会对读者造成迷惑。比如连 BigGAN 这种级别的网络的都会产生无意义的输出,其余 GAN 的就不太可能全部像论文展示的那么稳定。而且线上应用有时对错误要敏感得多,不像论文一样把失败的样本掩盖掉就行。当然,事物发展需要过程,要是太严格,那很多论文可能都要毙掉。
对模型影响最大的反而是数据,GIGO 原则其实大家都知道,但是因为大家写论文都是在公开数据集上做测试,而公开数据集一般比较干净,久而久之倒是可能忘记和习惯无视了。而一旦经历过线上项目或者个人项目,需要自己去收集数据或清洗数据时,就能感知到当中的滋味。有 70% 的时间都是和数据本身打交道,并不是危言耸听。
在论文 [8] 中,比较了几种常见的 data augmentation 对模型性能影响。可见,在公开数据集上使用不同的数据处理方案亦会对模型性能产生影响,但只做数据预处理的文章很难发表,除非诸如 mixup 这种取得惊艳效果的新手段。
还有对业务场景的理解,这点也经常听到,但新人会很疑惑,什么样才叫对业务场景的理解?回顾上文,关于视频单帧和大头照人脸尺寸的思考,怎么提出更合适的假设,关于遮挡物是否影响人对”脸“和其身份的感知,这些就是对应用场景的思考。只有理解了业务场景,才能做出合适的模型架构,数据的预处理和后处理。比如一些场景上需要先做关键点对齐,亦是这个原因。总的来说,Deep Learning 的潜力很大,但前提是用在合适的地方。
另一点,相比论文开源出来的训练脚本,如果有更为成熟的工业库,其实更值得学习。因为在工程项目上,当数据规模达到一定程度,在分布式的环境上,有些模型的实现是有多种变体的。比如在 [9] 中提到的跨卡同步的 BN。有兴趣的同学可以读一些偏工程驱动的论文,如 YouTuBe 的推荐系统的那篇,比如阿里的鲁班,和美团的一个相似的智能海报技术。虽然是”生成“海报,但实际上 GAN 只是其中一个部件,而且很巧妙的把这个看着很像 image generate 这样目前还是黑盒的问题换成了要比较好控制和干预的 Seq2Seq 问题。
后话
关于上文对论文和工程的区别,可能大家在很多场合都常见,有些是显然的结论,但如果你找身边的人抓着某一个点去问,往往言之无物。本文接着 DeepFakes 的发展路程,加上个人见解,分析了当我们预着这么一个问题时,可以从那些方面分析和改进。
至于为什么选 DeepFakes,虽然不是什么大型项目,但 DeepFakes 一开始就往着 app 上走,而不是 script 上发展,相对应的,DeepFakes 的设计和考虑的细节,总归是偏向工程一些,还是有参考价值的。
参考
[1] https://arxiv.org/pdf/1812.04948.pdf
[2] https://arxiv.org/pdf/1812.08685.pdf
[3]https://zhuanlan.zhihu.com/p/34042498
[4]https://github.com/shaoanlu/faceswap-GAN
[5]https://zhuanlan.zhihu.com/p/54146307
[6]https://zhuanlan.zhihu.com/p/54213305
[7]https://www.zhihu.com/question/304599202/answer/546354846
[8]https://zhuanlan.zhihu.com/p/51870052
[9]https://zhuanlan.zhihu.com/p/40496177

点击阅读原文,查看 使用深度学习玩Pong游戏



