传统图像算法+深度学习方法结合会有什么样的火花?

老早之前,有同学在问,有没有传统图像算法与深度学习结合的,其实这类的不是很多,之前学生研究期间有做过一些类似这类工作,结果还是很可以的,结果确实会比单独使用的好,但效率会比之前的一些技术慢一些,也就是就无法达到实时的效果。
这种结合方式,就几种形式:
1)先用传统方法处理,然后作为深度学习框架的输入使用;
2)先用深度学习网络学习源数据的特征表示,然后作为传统图像算法的输入;
3)传统和深度学习方法并行处理,最后设计一个新的损失函数来结合使用。
经过实验,其实后两种方式会比较好,有兴趣的同学可以自己去尝试,一定会有新的发现,加油!
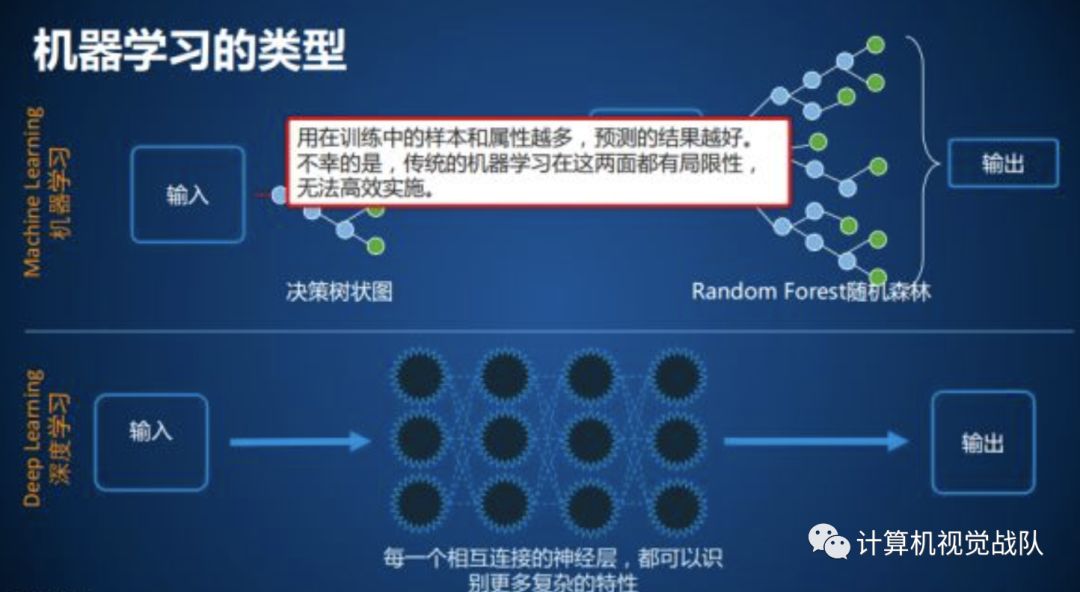
我可以说一下基本原因,因为深度学习最好的输入还是接触最原始的数据,大家做了可视化的同学可以发现,深度学习就好比一个刚刚成长的小孩,如果你刚开始教他的知识比较高深,或者给他传输的知识不是最基本最原始的,他通过你的教学及后期学习,发现与实际不是很符合,这样长大后就会对一些知识出现偏差。所以,输入最好,应该是一定要是源数据,这样通过基本特征不断去深入学习,不仅对该知识有一定的辨别能力,还可以增加泛化能力。
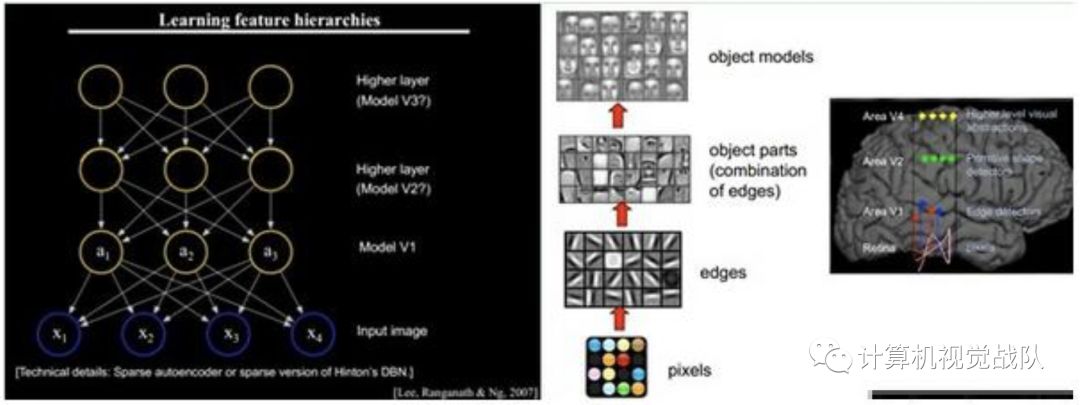
那接下来我就来和大家说说之前比较火的一个技术,就是换脸技术,他就是将传统方法和深度学习结合的案例,如果有了解过的同学,可以再浏览一遍,增加自己的认知和深入思考。主要引用别人的一些现有知识,请大家不要见谅,谢谢~
前一段时间用于人物换脸的deepfake火爆了朋友圈,早些时候Cycle GAN就可以轻松完成换脸任务,其实换脸是计算机视觉常见的领域,比如Cycle GAN ,3DMM,以及下文引用的论文均可以使用算法实现换脸(一定程度上能模仿表情),而不需要使用PS等软件手工换脸(表情僵硬,不符合视频上下文)。
但是deepfake用一个新颖的思考角度进行换脸,其实GAN可以完成该领域的一些技术,但是大家都知道,GAN的训练是极其不稳定,且收敛时间特别长,某些特定的数据集可能还需要有些Trick,才能保证最后的效果。
但deepfake似乎可以在各个数据集里训练测试,无所不能的模型,深入阅读开源代码后(https://github.com/deepfakes/faceswap),发现这东西很多值得一说的地方和优化的空间。
本文主要包括以下几方面:
解读deepfake的模型和预处理与后处理的算法以引用论文。(目前大多文章只是介绍了其中的神经网络,然而这个项目并不是单纯的端到端(end-to-end)的输出,所以本文还会涉及其他CV的算法以及deepfake的介绍)。
引入肤色检测算法,提升换脸的视觉效果。
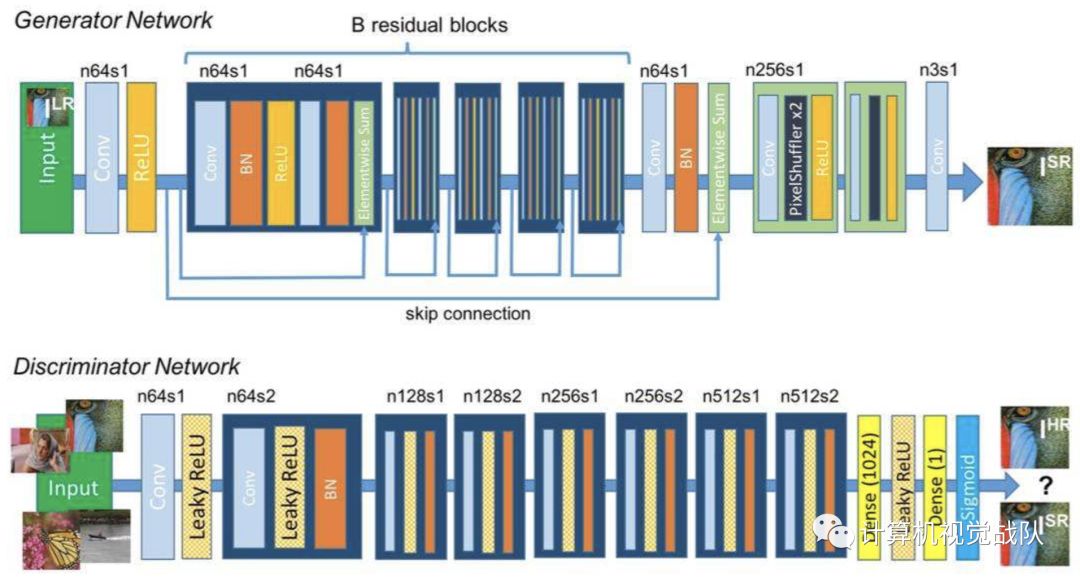
虽然原作没有指出,但从模型和整体方法设计来说,该模型应该是参考了论文https://arxiv.org/abs/1611.09577,其网络结构总体仍是encoder-decoder的形式,但与我们所熟知autoencoder不同的是,它是由一个Encoder和两个Decoder组成,两个Decoder分别对应imageA和imageB的解码。
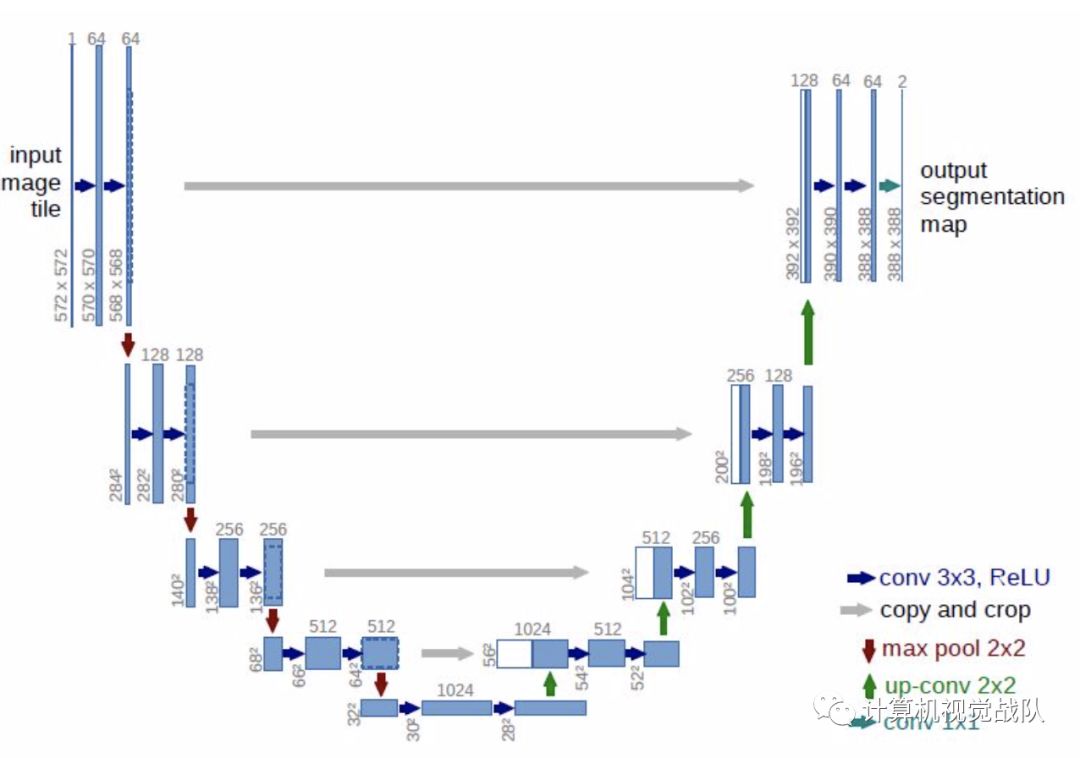
Encoder部分用了简单的堆叠5x5卷积核,采用aplha=0.1的Leak Relu作为激活函数。Decoder部分使用了卷积和Pixel Shuffer来做上采样,结构上采用了4x4,8x8……64x64这样分辨率递增的重建方式(网络整体是类U-net的结构)。下图为U-net网络结构。
如果你想要复现和改进模型的话,需要主要一点的是,虽然期望输入A脸然后输出B脸,输入B脸输出A脸,但训练却不把A、B脸作为pair输进神经网络(输入A脸,期望在另一端获得B脸),仍然是像训练普通autoen coder的一样,给出A脸,你要复原A脸,B脸亦然。
用不同的decoder,这样训练的结果是decoder A能学会用A的信息复原A,decoder B用B的信息复原B,而他们共用的Encoder呢?学会了提取A,B的共有特征,比如眼睛的大小,皮肤的纹理,而解码器根据得到的编码,分别找对应的信息复原,这样就能起到换脸的效果了。

而Encoder获取到共同的特征,比单独学习A的特征,信息要损失得更为严重,故会产生模糊的效果,另一个照片模糊得原因是autoen coder使用得是均方误差这一点已经是不可置否的了,后文提及的使用GAN来优化,可以一定程度上缓解模糊的问题。
预处理
大家都知道在CV里用深度学习解决问题前,需要用进行数据增强,然而涉及人脸的数据增强的算法和平时的有一点不太一样。
在开源代码中,分别使用了random_transform,random_warp 两个函数来做数据增强。但这个两个函数只是做一些比例拉伸之类的参数封装,真正做了转换的是opencv的warpAffine、rmap两个函数。
rmap其直译过来就是重映射,其所做的就是将原图的某一个像素以某种规则映射到新的图中。利用该函数,可以完成图像的平移,反转等功能。
注:
void remap(InputArray src, OutputArray dst, InputArray map1, InputArray map2,int interpolation, intborderMode = BORDER_CONSTANT,const Scalar& borderValue = Scalar())
第一个参数:输入图像,即原图像,需要单通道8位或者浮点类型的图像
第二个参数:输出图像,即目标图像,需和原图形一样的尺寸和类型
第三个参数:它有两种可能表示的对象:
表示点(x,y)的第一个映射;
表示CV_16SC2,CV_32FC1等
第四个参数:它有两种可能表示的对象:
若map1表示点(x,y)时,这个参数不代表任何值;
表示 CV_16UC1,CV_32FC1类型的Y值
第五个参数:插值方式,有四中插值方式:
INTER_NEAREST——最近邻插值
INTER_LINEAR——双线性插值(默认)
INTER_CUBIC——双三样条插值(默认)
INTER_LANCZOS4——lanczos插值(默认)
第六个参数:边界模式,默认BORDER_CONSTANT
第七个参数:边界颜色,默认Scalar()黑色
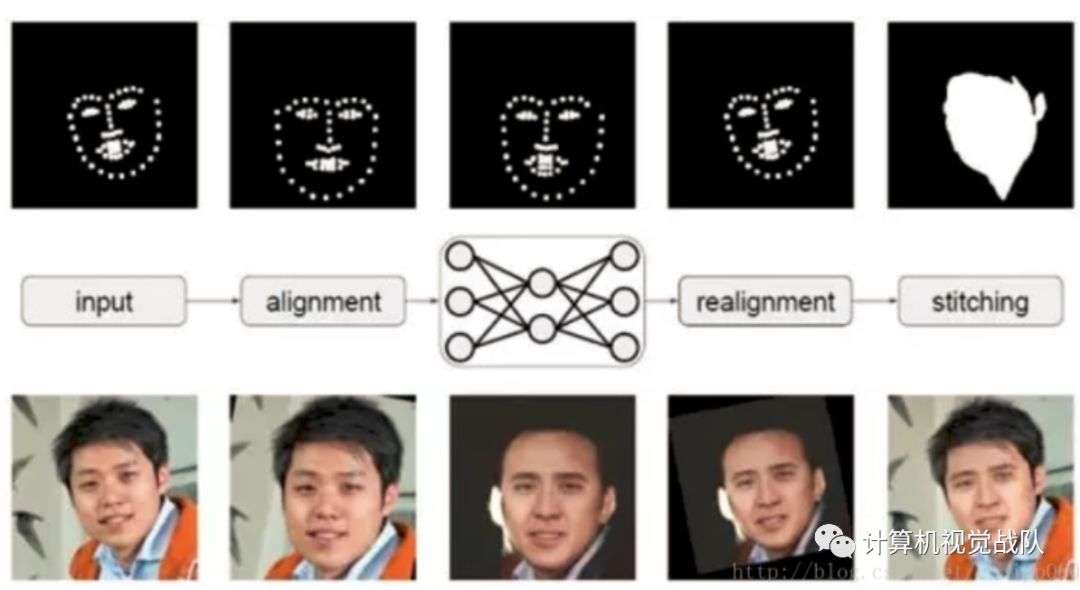
在数据增强中,大家都不希望改动数据会影响label的分布,在常见的有监督任务中,数据的标签由人工打上,如类别,位置等,图像的扭曲,反转不会影响到label的分布,但在deepfake中,做的是生成任务,作为无监督任务中的一种,其反向转播的误差由图像自己的提供,而要使得数据增强后(代码中的warped_image)有对应的样本(代码中的target_image),作者使用了rmap构造除warped_image,而使用umeyama和warpAffine构造出target_image。
Umeyama是一种点云匹配算法,简单点来理解就是将源点云(source cloud)变换到目标点云(target cloud)相同的坐标系下,包含了常见的矩阵变换和SVD的分解过程。调用umeyama后获取变换所需的矩阵,最后将原图和所求得矩阵放进warpAffine即可获的增强后对应的target_image。其中warpAffine的功能就是根据变换矩阵对源矩阵进行变换。下图,上面是经过变型处理的warped_image ,下面是target_image。

后处理
在deepfake(上述链接中)的命令行版本中,有一个-P参数,选中后可以实时演示图片的变化过程。在通过预览这个演变过程中,不难发现进入神经网络的不是整张图片,也不是使用extract出来的整个256x256的部分(头像),而是仅仅只有脸部的小区域(64x64)。因此在预测阶段,首先就是截取人脸,然后送进网络,再根据网络的输出覆盖原图部分。
在脸部替换后,会出现如下问题:
肤色差异,即使是同种人,也会有细微的差异;
差异,每张照片的光照环境不同;
假脸边界明显
前两者的造成原因一是客观差异,二是和数据集的大小相关,作为想给普通的用户用,数据集太大了,用户承受不起,数据集太小,神经网络学习不多。至于最后一点则是前两者造成的,但这一点可以通过降低分辨率缓解。这也是很多网上小视频假脸边界不明显的原因,因为很少会有一张脸占屏幕80%的画面。但如果你直接用在256x256的头像图上则边界效果明显,如下图:

另外的两个问题的解决及缓减方法,我们将下一期继续,感谢大家对我们“计算机视觉战队”的支持!
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。





