博客 | 手把手带你实现 室内用户移动预测(附python代码)

本文原载于微信公众号:磐创AI(ID:xunixs),欢迎关注磐创AI微信公众号及AI研习社博客专栏。
作者:小韩
介绍
大多数的时间序列数据主要用于交易生成预测。无论是预测产品的需求量还是销售量,航空公司的乘客数量还是特定股票的收盘价,我们都可以利用时间序列技术来预测需求。
随着生成的数据量呈指数级增长,尝试新思想和算法的机会也随之增加。使用复杂的时间序列数据集仍然是一个待开发的领域。
这篇文章的目的就是介绍时间序列分类的新概念。我们将首先了解该概念的含义和在行业中的应用。我们不会只停留在理论部分,还会通过处理时间序列数据集并执行分类解决实际问题。一边做一边学有助于以实际的操作来理解概念。
目录:
时间序列分类简介
1. ECG / EEG信号分类
2. 图像分类
3. 运动传感器数据分类
描述问题场景
查看数据集
预处理
建立分类模型
时间序列分类简介
时间序列分类实际上已经存在了一段时间。但到目前为止,它主要用于实验室研究,而不是行业应用。目前有很多正在进行的研究,新创建的数据集,许多新的算法。当我第一次接触到到时间序列分类概念时,最初的想法是:我们怎样对时间序列进行分类以及时间序列分类数据是什么样的?我相信你一定也想知道。
可以想象,时间序列分类数据与常规分类问题不同,因为它的属性是有序序列。让我们来看看一些时间序列分类用例,了解它们之间的差异。
1. ECG / EEG信号分类
心电图(ECG, electrocardiogram),用于记录心脏的电活动,并广泛用于诊断各种心脏问题。使用外部电极捕获这些ECG信号。
例如,考虑以下信号样本,它代表一个心跳的电活动。左侧图像表示正常心跳,而相邻的图像表示心肌梗塞。
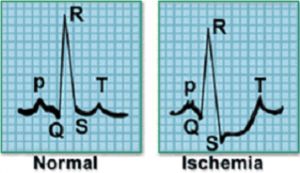
从电极捕获的数据将是时间序列的形式,并且信号可以分类为不同的类别。我们还可以对记录大脑电活动的脑电信号进行分类。
2. 图像分类
图像也可以是时间顺序相关的。考虑以下的情况:
根据天气条件,土壤肥力,水的可用性和其他外部因素,作物在特定的田地中生长。在该区域上持续每天拍摄图片,持续5年,并标记在该区域上种植作物的名称。该数据集中的图像是在固定的时间间隔拍摄的,并且具有特定的顺序,这可能是对图像进行分类的重要因素。
3. 运动传感器数据分类
传感器生成高频数据,可以识别其范围内物体的移动。通过设置多个无线传感器并观察传感器中信号强度的变化,我们可以识别物体的运动方向。
你还知道哪些时间序列分类的应用吗?欢迎大家在文末留言。
描述问题场景
我们将专注于 “室内用户运动预测” 的问题。在该问题中,多个运动传感器被放置在不同的房间中,目标是从这些运动传感器捕获的频率数据中识别个体是否在房间之间移动。
两个房间一共有四个运动传感器(A1,A2,A3,A4)。请看下面的图像,其中说明了传感器在每个房间中的位置。一共设置了 3 对类似的房间(group1,group2,group3)。
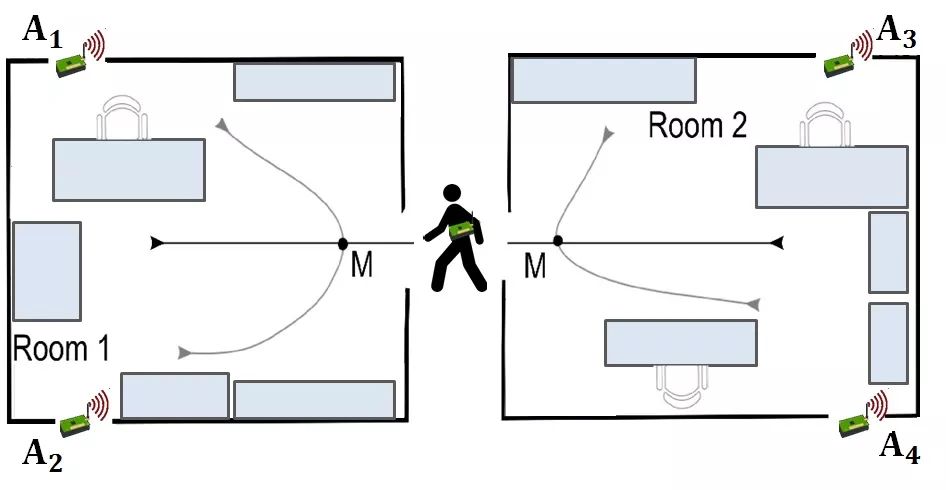
一个人可以沿着上图所示的六个预定义路径中的任意一个移动。路径2, 3, 4或 6 是在房间内移动,路径 1 或 5 在房间之间移动。
传感器的读数可以识别人在某个时间点的位置。当人在房间内或在房间内移动时,传感器中的读数会发生变化。改变化可用于标识人员的路径。
现在问题已经表述清楚了,是时候开始编码了!在下一节中,我们会查看该问题的数据集,有助于使该问题更加清晰。数据集:室内用户移动预测。
查看数据集
数据集一共包含316个文件:
314 个 MovementAAL csv 文件,包含环境中的运动传感器的读数。
一个 Target csv 文件,包含每个 MovementAAL 文件的目标变量。
一个 Group Data csv 文件,用于标识 MovementAAL 文件属于哪一个组。
Path csv 文件包含目标采取的路径。
首先看一下数据集。
1import pandas as pd
2import numpy as np
3%matplotlib inline
4import matplotlib.pyplot as plt
5from os import listdir
1from keras.preprocessing import sequence
2import tensorflow as tf
3from keras.models import Sequential
4from keras.layers import Dense
5from keras.layers import LSTM
6
7from keras.optimizers import Adam
8from keras.models import load_model
9from keras.callbacks import ModelCheckpoint
在加载所有文件之前先快速浏览一下要处理的数据。读取移动数据的前两个文件:
1df1 = pd.read_csv('/MovementAAL/dataset/MovementAAL_RSS_1.csv')
2df2 = pd.read_csv('/MovementAAL/dataset/MovementAAL_RSS_2.csv')
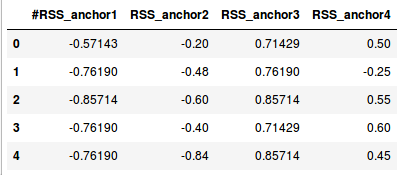
1df1.head()
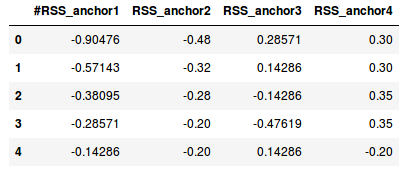
1df2.head()
1df1.shape, df2.shape
1((27, 4), (26, 4))
这些文件包含了四个传感器的标准化数据 —— A1,A2,A3,A4。csv 文件的长度(行数)不同,是因为对应的持续时间不同。为方便起见,我们假设每秒都会收集到传感器数据。第一次变化持续时间为27秒(27行),而另一次变化为26秒(26行)。
在建立模型之前,我们必须处理这种不同的长度。以下的代码用于读取和存储传感器的值:
1path = 'MovementAAL/dataset/MovementAAL_RSS_'
2sequences = list()
3for i in range(1,315):
4 file_path = path + str(i) + '.csv'
5 print(file_path)
6 df = pd.read_csv(file_path, header=0)
7 values = df.values
8 sequences.append(values)
1targets = pd.read_csv('MovementAAL/dataset/MovementAAL_target.csv')
2targets = targets.values[:,1]
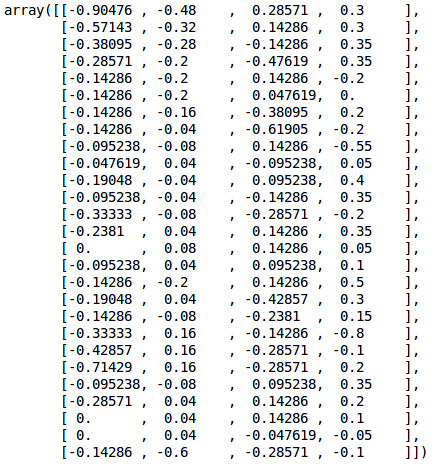
现在有一个名为 'sequences' 的列表,包含了运动传感器的数据和目标——csv文件的标签。sequences[0] 中的数据就是第一个csv文件中获取传感器的值:
1sequences[0]
如上所述,数据集是在三对不同的房间中收集的,所以有三组数据。正好可以将数据集划分为训练集,测试集和验证集。现在加载 DatasetGroup csv 文件:
1groups = pd.read_csv('MovementAAL/groups/MovementAAL_DatasetGroup.csv', header=0)
2groups = groups.values[:,1]
前两组的数据用于训练 ,第三组用于测试。
预处理
由于时间序列数据的长度不同,我们不能直接在数据集上建立模型。那么怎样确定合适的长度呢?我们可以通过多种方发处理。这里有一些简单的想法(欢迎在评论区提出批评和建议):
用零填充较短的序列使所有序列的长度相等。这种方式下,我们向模型提供了不正确的数据
找到序列的最大长度,使用它最后一行中的数据填充
确定数据集中序列的最小长度,将其他所有的序列截断为该长度。这将损失大量的数据
取所有长度的平均值,截断较长的序列,填充较短的序列
获取最小,最大和平均序列长度:
1len_sequences = []
2for one_seq in sequences:
3 len_sequences.append(len(one_seq))
4pd.Series(len_sequences).describe()
1count 314.000000
2mean 42.028662
3std 16.185303
4min 19.000000
525% 26.000000
650% 41.000000
775% 56.000000
8max 129.000000
9dtype: float64
大多数文件的长度在 40 到 60 之间。只有 3 个文件的长度超过 100。因此,采用最小或最大的长度没有太大意义。第 90 个四分位数是 60,可以将它作为所有序列的长度。代码:
1### 用最长序列的最后一行的数据填充较短的序列
2to_pad = 129
3new_seq = []
4for one_seq in sequences:
5 len_one_seq = len(one_seq)
6 last_val = one_seq[-1]
7 n = to_pad - len_one_seq
8
9 to_concat = np.repeat(one_seq[-1], n).reshape(4, n).transpose()
10 new_one_seq = np.concatenate([one_seq, to_concat])
11 new_seq.append(new_one_seq)
12final_seq = np.stack(new_seq)
13
14# 截断较长的序列
15from keras.preprocessing import sequence
16seq_len = 60
17final_seq=sequence.pad_sequences(final_seq, maxlen=seq_len, padding='post', dtype='float', truncating='post')
然后根据分组将数据集分开,准备训练集,验证集和测试集:
1train = [final_seq[i] for i in range(len(groups)) if (groups[i]==2)]
2validation = [final_seq[i] for i in range(len(groups)) if groups[i]==1]
3test = [final_seq[i] for i in range(len(groups)) if groups[i]==3]
4
5train_target = [targets[i] for i in range(len(groups)) if (groups[i]==2)]
6validation_target = [targets[i] for i in range(len(groups)) if groups[i]==1]
7test_target = [targets[i] for i in range(len(groups)) if groups[i]==3]
1train = np.array(train)
2validation = np.array(validation)
3test = np.array(test)
4
5train_target = np.array(train_target)
6train_target = (train_target+1)/2
7
8validation_target = np.array(validation_target)
9validation_target = (validation_target+1)/2
10
11test_target = np.array(test_target)
12test_target = (test_target+1)/2
建立分类模型
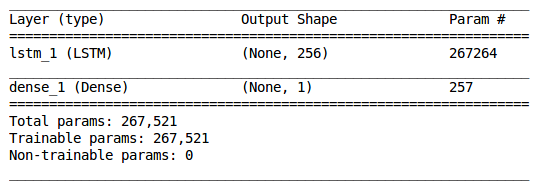
我们已经准备了用于 LSTM(长短期记忆)模型的数据,处理了不同长度的序列并创建了训练集,验证集和测试集。接下来就要建立一个单层 LSTM 网络。
1model = Sequential()
2model.add(LSTM(256, input_shape=(seq_len, 4)))
3model.add(Dense(1, activation='sigmoid'))
1model.summary()
训练模型并验证准确率:
1adam = Adam(lr=0.001)
2chk = ModelCheckpoint('best_model.pkl', monitor='val_acc', save_best_only=True, mode='max', verbose=1)
3model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
4model.fit(train, train_target, epochs=200, batch_size=128, callbacks=[chk], validation_data=(validation,validation_target))
1# 加载模型,用测试集验证准确性
2model = load_model('best_model.pkl')
3
4from sklearn.metrics import accuracy_score
5test_preds = model.predict_classes(test)
6accuracy_score(test_target, test_preds)
最后准确度得分为0.78846153846153844。这是一个相当良好的开端,但我们还可以通过使用超参数,改变学习速率或迭代次数改善 LSTM 模型的性能。
点击 阅读原文,查看更多内容




