从零开始用Python实现k近邻算法(附代码、数据集)

作者:Tavish Srivastava
翻译:王雨桐
校对:丁楠雅
本文约2000字,建议阅读8分钟。
本文将带领读者理解KNN算法在分类问题中的使用,并结合案例运用Python进行实战操作。
注意:本文于2014年10月10日首发,并于2018年3月27日更新
引言
进入数据分析领域的四年来,我构建的模型的80%多都是分类模型,而回归模型仅占15-20%。这个数字会有浮动,但是整个行业的普遍经验值。分类模型占主流的原因是大多数分析问题都涉及到做出决定。例如一个客户是否会流失,我们是否应该针对一个客户进行数字营销,以及客户是否有很大的潜力等等。这些分析有很强的洞察力,并且直接关系到实现路径。在本文中,我们将讨论另一种被广泛使用的分类技术,称为k近邻(KNN)。本文的重点主要集中在算法的工作原理以及输入参数如何影响输出/预测。
目录
什么情况下使用KNN算法?
KNN算法如何工作?
如何选择因子K?
分解--KNN的伪代码
从零开始的Python实现
和Scikit-learn比较
什么情况使用KNN算法?
KNN算法既可以用于分类也可以用于回归预测。然而,业内主要用于分类问题。在评估一个算法时,我们通常从以下三个角度出发:
模型解释性
运算时间
预测能力
让我们通过几个例子来评估KNN:

KNN算法在这几项上的表现都比较均衡。由于便于解释和计算时间较短,这种算法使用很普遍。
KNN算法的原理是什么?
让我们通过一个简单的案例来理解这个算法。下图是红圆圈和绿方块的分布图:
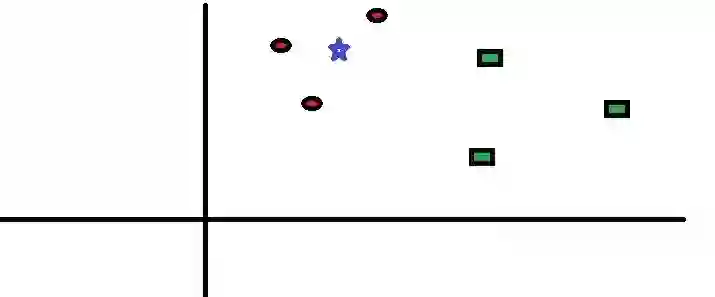
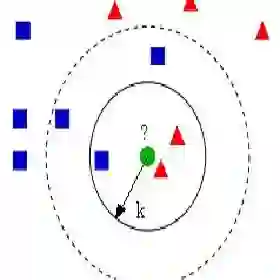
现在我们要预测蓝星星属于哪个类别。蓝星星可能属于红圆圈,或属于绿方块,也可能不属于任何类别。KNN中的“K”是我们要找到的最近邻的数量。假设K = 3。因此,我们现在以蓝星星为圆心来作一个圆,使其恰巧只能包含平面内的3个数据点。参阅下图:
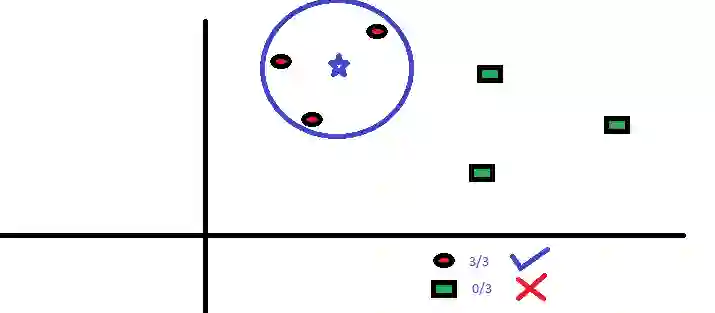
离蓝星星最近的三个点都是红圆圈。因此,我们可以以较高的置信水平判定蓝星星应属于红圆圈这个类别。在KNN算法中,参数K的选择是非常关键的。接下来,我们将探索哪些因素可以得到K的最佳值。
如何选择因子K?
首先要了解K在算法中到底有什么影响。在前文的案例中,假定总共只有6个训练数据,给定K值,我们可以划分两个类的边界。现在让我们看看不同K值下两个类别的边界的差异。
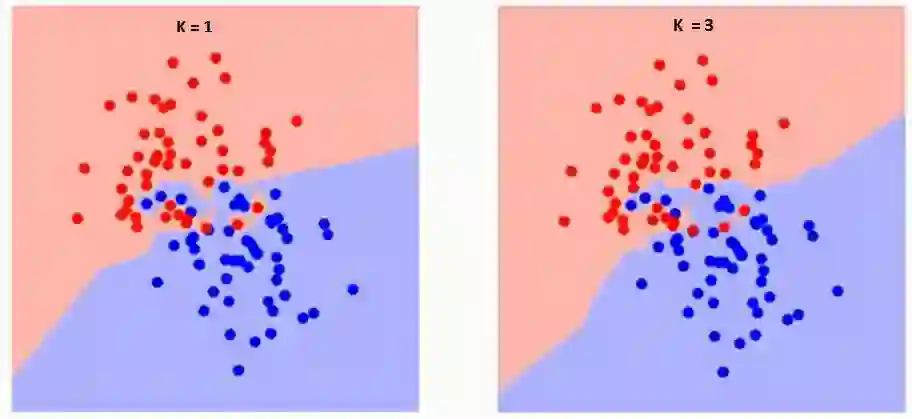
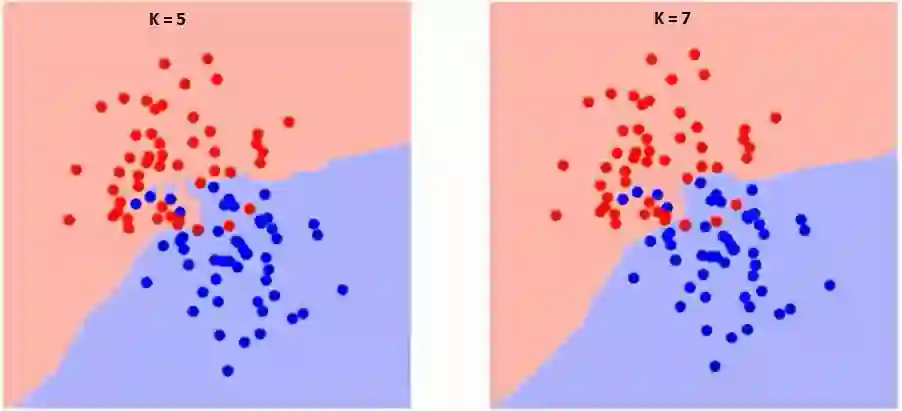
仔细观察,我们会发现随着K值的增加,边界变得更平滑。当K值趋于无穷大时,分类区域最终会全部变成蓝色或红色,这取决于占主导地位的是蓝点还是红点。我们需要基于不同K值获取训练错误率和验证错误率这两个参数。以下为训练错误率随K值变化的曲线:
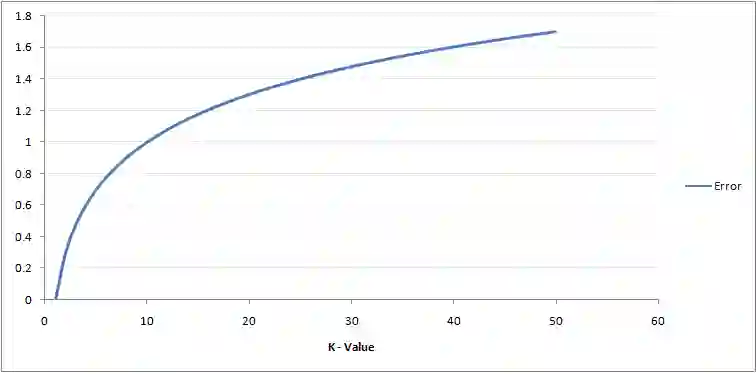
如图所示,对于训练样本而言,K=1时的错误率总是为零。这是因为对任何训练数据点来说,最接近它的点就是其本身。因此,K=1时的预测总是准确的。如果验证错误曲线也是这样的形状,我们只要设定K为1就可以了。以下是随K值变化的验证错误曲线:
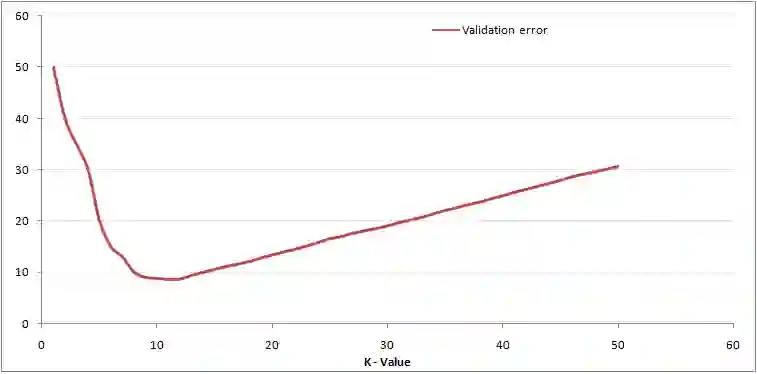
显然,在K=1的时候,我们过度拟合了边界。因此,错误率最初是下降的,达到最小值后又随着K的增加而增加。为了得到K的最优值,我们将初始数据集分割为训练集和验证集,然后通过绘制验证错误曲线得到K的最优值,应用于所有预测。
分解--KNN的伪代码
我们可以通过以下步骤实现KNN模型:
加载数据。
预设K值。
对训练集中数据点进行迭代,进行预测。
STEPS:
计算测试数据与每一个训练数据的距离。我们选用最常用的欧式距离作为度量。其他度量标准还有切比雪夫距离、余弦相似度等
根据计算得到的距离值,按升序排序
从已排序的数组中获取靠前的k个点
获取这些点中的出现最频繁的类别
得到预测类别
从零开始的Python实现
我们将使用流行的Iris数据集来构建KNN模型。你可以从这里下载(数据集链接:https://gist.githubusercontent.com/gurchetan1000/ec90a0a8004927e57c24b20a6f8c8d35/raw/fcd83b35021a4c1d7f1f1d5dc83c07c8ffc0d3e2/iris.csv)
# Importing libraries
import pandas as pd
import numpy as np
import math
import operator
#### Start of STEP 1
# Importing data
data = pd.read_csv("iris.csv")
#### End of STEP 1
data.head()
# Defining a function which calculates euclidean distance between two data points
def euclideanDistance(data1, data2, length):
distance = 0
for x in range(length):
distance += np.square(data1[x] - data2[x])
return np.sqrt(distance)
# Defining our KNN model
def knn(trainingSet, testInstance, k):
distances = {}
sort = {}
length = testInstance.shape[1]
#### Start of STEP 3
# Calculating euclidean distance between each row of training data and test data
for x in range(len(trainingSet)):
#### Start of STEP 3.1
dist = euclideanDistance(testInstance, trainingSet.iloc[x], length)
distances[x] = dist[0]
#### End of STEP 3.1
#### Start of STEP 3.2
# Sorting them on the basis of distance
sorted_d = sorted(distances.items(), key=operator.itemgetter(1))
#### End of STEP 3.2
neighbors = []
#### Start of STEP 3.3
# Extracting top k neighbors
for x in range(k):
neighbors.append(sorted_d[x][0])
#### End of STEP 3.3
classVotes = {}
#### Start of STEP 3.4
# Calculating the most freq class in the neighbors
for x in range(len(neighbors)):
response = trainingSet.iloc[neighbors[x]][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
#### End of STEP 3.4
#### Start of STEP 3.5
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return(sortedVotes[0][0], neighbors)
#### End of STEP 3.5
# Creating a dummy testset
testSet = [[7.2, 3.6, 5.1, 2.5]]
test = pd.DataFrame(testSet)
#### Start of STEP 2
# Setting number of neighbors = 1
k = 1
#### End of STEP 2
# Running KNN model
result,neigh = knn(data, test, k)
# Predicted class
print(result)
-> Iris-virginica
# Nearest neighbor
print(neigh)
-> [141]
现在我们改变k的值并观察预测结果的变化:
# Setting number of neighbors = 3
k = 3
# Running KNN model
result,neigh = knn(data, test, k)
# Predicted class
print(result) -> Iris-virginica
# 3 nearest neighbors
print(neigh)
-> [141, 139, 120]
# Setting number of neighbors = 5
k = 5
# Running KNN model
result,neigh = knn(data, test, k)
# Predicted class
print(result) -> Iris-virginica
# 5 nearest neighbors
print(neigh)
-> [141, 139, 120, 145, 144]
和scikit-learn比较
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(data.iloc[:,0:4], data['Name'])
# Predicted class
print(neigh.predict(test))
-> ['Iris-virginica']
# 3 nearest neighbors
print(neigh.kneighbors(test)[1])
-> [[141 139 120]]
可以看到,两个模型都预测了同样的类别(“irisi –virginica”)和同样的最近邻([141 139 120])。因此我们可以得出结论:模型是按照预期运行的。
尾注
KNN算法是最简单的分类算法之一。即使如此简单,它也能得到很理想的结果。KNN算法也可用于回归问题,这时它使用最近点的均值而不是最近邻的类别。R中KNN可以通过单行代码实现,但我还没有探索如何在SAS中使用KNN算法。
您觉得这篇文章有用吗?您最近使用过其他机器学习工具吗?您是否打算在一些业务问题中使用KNN?如果是的话,请与我们分享你打算如何去做。
原文标题:Introduction to k-Nearest Neighbors: Simplified (with implementation in Python)
原文链接:https://www.analyticsvidhya.com/blog/2018/03/introduction-k-neighbours-algorithm-clustering/
译者简介

王雨桐,统计学在读,数据科学硕士预备,跑步不停,弹琴不止。梦想把数据可视化当作艺术,目前日常是摸着下巴看机器学习。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织