手把手教你在多种无监督聚类算法实现Python(附代码)

来源: 机器之心
本文约2704字,建议阅读6分钟。
本文简要介绍了多种无监督学习算法的 Python 实现,包括 K 均值聚类、层次聚类、t-SNE 聚类、DBSCAN 聚类。
无监督学习是一类用于在数据中寻找模式的机器学习技术。无监督学习算法使用的输入数据都是没有标注过的,这意味着数据只给出了输入变量(自变量 X)而没有给出相应的输出变量(因变量)。在无监督学习中,算法本身将发掘数据中有趣的结构。

人工智能研究的领军人物 Yan Lecun,解释道:无监督学习能够自己进行学习,而不需要被显式地告知他们所做的一切是否正确。这是实现真正的人工智能的关键!
监督学习 VS 无监督学习
在监督学习中,系统试图从之前给出的示例中学习。(而在无监督学习中,系统试图从给定的示例中直接找到模式。)因此,如果数据集被标注过了,这就是一个监督学习问题;而如果数据没有被标注过,这就是一个无监督学习问题。
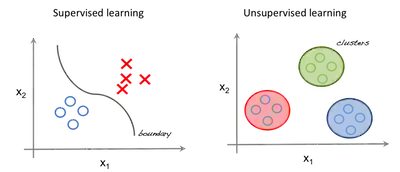
上图是一个监督学习的例子,它使用回归技术找到在各个特征之间的最佳拟合曲线。而在无监督学习中,根据特征对输入数据进行划分,并且根据数据所属的簇进行预测。
重要的术语
特征:进行预测时使用的输入变量。
预测值:给定一个输入示例时的模型输出。
示例:数据集中的一行。一个示例包含一个或多个特征,可能还有一个标签。
标签:特征对应的真实结果(与预测相对应)。
准备无监督学习所需的数据
在本文中,我们使用 Iris 数据集来完成初级的预测工作。这个数据集包含 150 条记录,每条记录由 5 个特征构成——花瓣长度、花瓣宽度、萼片长度、萼片宽度、花的类别。花的类别包含 Iris Setosa、Iris VIrginica 和 Iris Versicolor 三种。本文中向无监督算法提供了鸢尾花的四个特征,预测它属于哪个类别。
本文使用 Python 环境下的 sklearn 库来加载 Iris 数据集,并且使用 matplotlib 进行数据可视化。以下是用于探索数据集的代码片段:
# Importing Modules
from sklearn import datasets
import matplotlib.pyplot as plt
# Loading dataset
iris_df = datasets.load_iris()
# Available methods on dataset
print(dir(iris_df))
# Features
print(iris_df.feature_names)
# Targets
print(iris_df.target)
# Target Names
print(iris_df.target_names)
label = {0: 'red', 1: 'blue', 2: 'green'}
# Dataset Slicingx_axis = iris_df.data[:, 0] # Sepal Length
y_axis = iris_df.data[:, 2] # Sepal Width
# Plotting
plt.scatter(x_axis, y_axis, c=iris_df.target)
plt.show()
['DESCR', 'data', 'feature_names', 'target', 'target_names']
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
['setosa' 'versicolor' 'virginica']
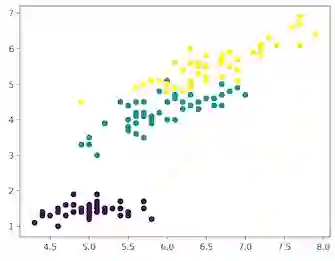
紫色:Setosa,绿色:Versicolor,黄色:Virginica
聚类分析
在聚类分析中,数据被划分为不同的几组。简而言之,这一步旨在将具有相似特征的群组从整体数据中分离出来,并将它们分配到簇(cluster)中。
可视化示例:
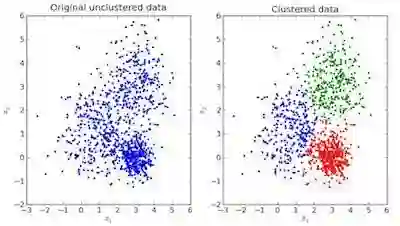
如上所示,左图是没有进行分类的原始数据,右图是进行聚类之后的数据(根据数据本身的特征将其分类)。当给出一个待预测的输入时,它会基于其特征查看自己从属于哪一个簇,并以此为根据进行预测。
K-均值聚类的 Python 实现
K 均值是一种迭代的聚类算法,它的目标是在每次迭代中找到局部最大值。该算法要求在最初选定聚类簇的个数。由于我们知道本问题涉及到 3 种花的类别,所以我们通过将参数「n_clusters」传递给 K 均值模型来编写算法,将数据分组到 3 个类别中。现在,我们随机地将三个数据点(输入)分到三个簇中。基于每个点之间的质心距离,下一个给定的输入数据点将被划分到独立的簇中。接着,我们将重新计算所有簇的质心。
每一个簇的质心是定义结果集的特征值的集合。研究质心的特征权重可用于定性地解释每个簇代表哪种类型的群组。
我们从 sklearn 库中导入 K 均值模型,拟合特征并进行预测。
K 均值算法的 Python 实现:
# Importing Modules
from sklearn import datasets
from sklearn.cluster import KMeans
# Loading dataset
iris_df = datasets.load_iris()
# Declaring Model
model = KMeans(n_clusters=3)
# Fitting Model
model.fit(iris_df.data)# Predicitng a single input
predicted_label = model.predict([[7.2, 3.5, 0.8, 1.6]])
# Prediction on the entire data
all_predictions = model.predict(iris_df.data)
# Printing Predictions
print(predicted_label)
print(all_predictions)
[0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 1 1 1 1 2 1 1 1 1 1 1 2 2 1 1 1 1 2 1 2 1 2 1 1 2 2 1 1 1 1 1 2 1 1 1 1 2 1 1 1 2 1 1 1 2 1 1 2]层次聚类
层次聚类,顾名思义,是一种能够构建有层次的簇的算法。在这个算法的起始阶段,每个数据点都是一个簇。接着,两个最接近的簇合二为一。最终,当所有的点都被合并到一个簇中时,算法停止。
层次聚类的实现可以用 dendrogram 进行展示。接下来,我们一起来看一个粮食数据的层次聚类示例。
数据集链接:https://raw.githubusercontent.com/vihar/unsupervised-learning-with-python/master/seeds-less-rows.csv
层次聚类的 Python 实现:
# Importing Modules
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt
import pandas as pd
# Reading the DataFrame
seeds_df = pd.read_csv(
"https://raw.githubusercontent.com/vihar/unsupervised-learning-with-python/master/seeds-less-rows.csv")
# Remove the grain species from the DataFrame, save for later
varieties = list(seeds_df.pop('grain_variety'))
# Extract the measurements as a NumPy array
samples = seeds_df.values
"""
Perform hierarchical clustering on samples using the
linkage() function with the method='complete' keyword argument.
Assign the result to mergings.
"""mergings = linkage(samples, method='complete')
"""
Plot a dendrogram using the dendrogram() function on mergings,
specifying the keyword arguments labels=varieties, leaf_rotation=90,
and leaf_font_size=6.
"""
dendrogram(mergings,
labels=varieties,
leaf_rotation=90,
leaf_font_size=6,
)
plt.show()
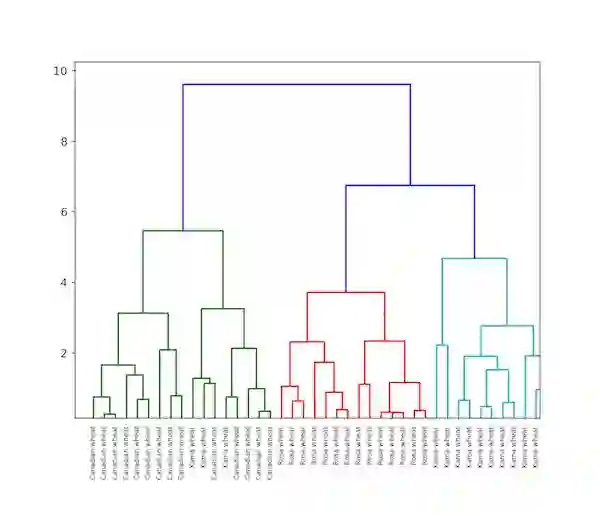
K 均值和层次聚类之间的差别
层次聚类不能很好地处理大数据,而 K 均值聚类可以。原因在于 K 均值算法的时间复杂度是线性的,即 O(n);而层次聚类的时间复杂度是平方级的,即 O(n2)。
在 K 均值聚类中,由于我们最初随机地选择簇,多次运行算法得到的结果可能会有较大差异。而层次聚类的结果是可以复现的。
研究表明,当簇的形状为超球面(例如:二维空间中的圆、三维空间中的球)时,K 均值算法性能良好。
K 均值算法抗噪声数据的能力很差(对噪声数据鲁棒性较差),而层次聚类可直接使用噪声数据进行聚类分析。
t-SNE 聚类
这是一种可视化的无监督学习方法。t-SNE 指的是 t 分布随机邻居嵌入(t-distributed stochastic neighbor embedding)。它将高维空间映射到一个可视化的二维或三维空间中。具体而言,它将通过如下方式用二维或三维的数据点对高维空间的对象进行建模:以高概率用邻近的点对相似的对象进行建模,而用相距较远的点对不相似的对象进行建模。
用于 Iris 数据集的 t-SNE 聚类的 Python 实现:
# Importing Modules
from sklearn import datasets
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
# Loading dataset
iris_df = datasets.load_iris()
# Defining Model
model = TSNE(learning_rate=100)
# Fitting Model
transformed = model.fit_transform(iris_df.data)# Plotting 2d t-Sne
x_axis = transformed[:, 0]
y_axis = transformed[:, 1]
plt.scatter(x_axis, y_axis, c=iris_df.target)
plt.show()

紫色:Setosa,绿色:Versicolor,黄色:Virginica
在这里,具备 4 个特征(4 维)的 Iris 数据集被转化到二维空间,并且在二维图像中进行展示。类似地,t-SNE 模型可用于具备 n 个特征的数据集。
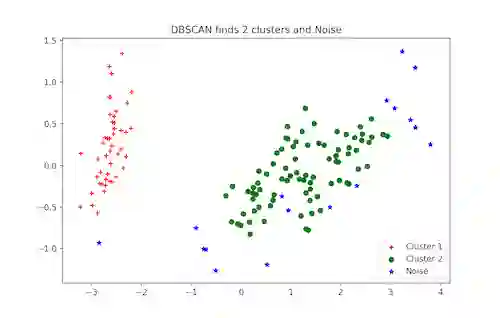
DBSCAN 聚类
DBSCAN(带噪声的基于密度的空间聚类方法)是一种流行的聚类算法,它被用来在预测分析中替代 K 均值算法。它并不要求输入簇的个数才能运行。但是,你需要对其他两个参数进行调优。
scikit-learn 的 DBSCAN 算法实现提供了缺省的“eps”和“min_samples”参数,但是在一般情况下,用户需要对他们进行调优。参数“eps”是两个数据点被认为在同一个近邻中的最大距离。参数“min_samples”是一个近邻中在同一个簇中的数据点的最小个数。
DBSCAN 聚类的 Python 实现:
# Importing Modules
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.decomposition import PCA
# Load Dataset
iris = load_iris()
# Declaring Model
dbscan = DBSCAN()
# Fitting
dbscan.fit(iris.data)
# Transoring Using PCA
pca = PCA(n_components=2).fit(iris.data)
pca_2d = pca.transform(iris.data)
# Plot based on Class
for i in range(0, pca_2d.shape[0]):
if dbscan.labels_[i] == 0:
c1 = plt.scatter(pca_2d[i, 0], pca_2d[i, 1], c='r', marker='+')
elif dbscan.labels_[i] == 1:c2 = plt.scatter(pca_2d[i, 0], pca_2d[i, 1], c='g', marker='o')
elif dbscan.labels_[i] == -1:
c3 = plt.scatter(pca_2d[i, 0], pca_2d[i, 1], c='b', marker='*')
plt.legend([c1, c2, c3], ['Cluster 1', 'Cluster 2', 'Noise'])
plt.title('DBSCAN finds 2 clusters and Noise')
plt.show()
更多无监督学习技术:
主成分分析(PCA)
异常检测
自编码器
深度信念网络
赫布型学习
生成对抗网络(GAN)
自组织映射
原文链接:https://towardsdatascience.com/unsupervised-learning-with-python-173c51dc7f03





