利用深度学习技术,实现MRI图像右心室分割(代码+数据集)
人的心脏是一个惊人的机器,能不间断地运作长达一个世纪。测量心脏功能的重要方法之一是计算其射血分数:心脏在舒张期充满血液后,在收缩期射出血液的百分比。获得这一指标的第一步,便依赖于心脏图像的心室分割(描绘区域)。

作者在纽约进行InsightAI计划(http://insightdata.ai/)期间,决定响应AI Open Network主持的研究呼吁,参与解决右心室精确分割挑战(https://ai-on.org/projects/cardiac-mri-segmentation.html)。设法通过超过少于当前一个数量级的参数,来达到目前最佳的结果。下面简要说明一下过程。
▍问题描述
研究呼吁:
开发能够从心脏核磁共振成图像(MRI)数据库中,自动分割右心室的系统。到目前为止,右心室分割主要由经典的图像处理方法处理,现代深度学习技术将有可能提供更可靠,全自动化的解决方案。
2016年,由Kaggle发起的左心室分割挑战的三名获奖者,都采用了深度学习的解决方案。相比较而言,右心室(RV)分割更具挑战性,原因如下:
在腔内存在与心肌相似的信号强度;右心室是复杂的新月形,从基部到顶点一直变化;分割顶点图像的切片十分困难;患者的心室内形态和信号强度差异相当大,特别是有病理改变的病例,等等。
不使用医学术语,识别右心室困难的原因是:左心室是一个厚壁的圆柱型区域,而右心室是一个不规则形状的物体,较薄的心室壁有时会与周围的组织混在一起。下图是MRI快照中手工绘制的右心室内壁和外壁(心内膜和心外膜)轮廓:
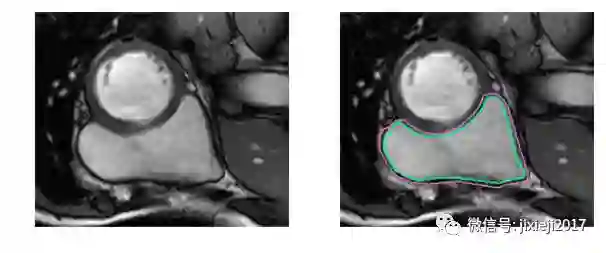
上图的分割较简单。下面是一个比较困难的分割:
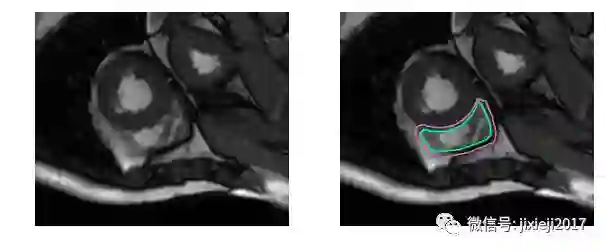
分割这些MRI对于未经专门训练的人来说是非常困难的:
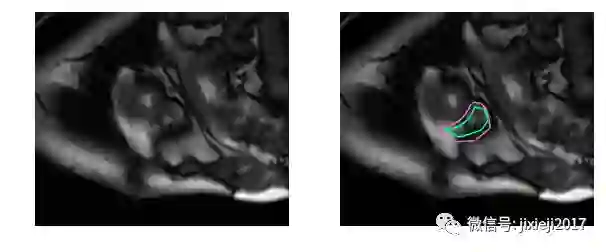
事实上,相比较左心室,人类医生需要两倍的时间来确定右心室的体积,且结果比左心室具有2-3倍的变异性[1]。这项工作的目的是,建立一个高精度的自动化右心室分割的深度学习模型。模型的输出是分割掩码,逐个像素的掩码指示出每个像素是否是右心室的一部分或背景。
▍数据库
利用深度学习方法解决这个问题,面临的最大挑战是数据集太小。数据集仅包含如上图所示的243张医师已分割的、来自有16例患者的MRI图像。另外还有3697个未标记图像,它们对于无监督或半监督学习可能有用的,但这个项目是一个监督学习的问题,我不考虑使用这些图像。图像大小为216×256像素。
对于较小的数据集,人们对于模型泛华到没见过的图像的效果是不抱希望的! 不幸的是,医疗环境中的典型情况就是如此,昂贵的标记数据和的难以获取的数据。通用的流程是应用仿射变换增强数据:随机旋转,平移,缩放和剪切。此外,我还应用了弹性形变,局部拉伸和压缩了图像[2]。
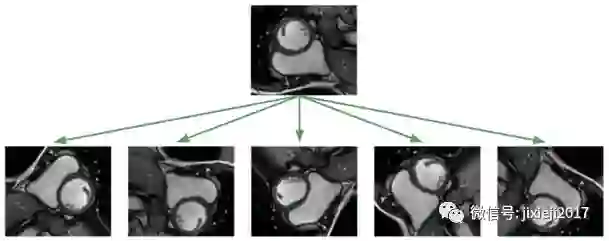
应用这种图像增强算法的目的是为了防止神经网络只记住训练的样例,并强迫其学习RV是一个实心的、月牙形的、方向任意的物体。在我实现的训练框架中,我会随时对数据集应用图像变换算法,这样,神经网络就会在每次训练时看到新的随机变换。
同样常见的是,由于大部分像素都属于背景,所以存在类别的不平衡。将像素强度归一化到0和1之间,我们看到在整个数据集中,只有5.1%的像素是右心室腔的一部分。
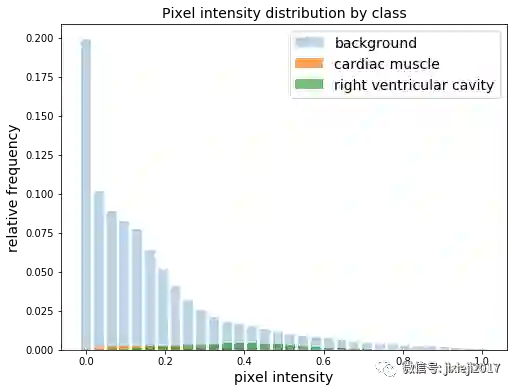
在构建损失函数时,我尝试了重新加权方案以平衡类别的分布,但最终发现未加权的平均表现最好。
在训练期间,20%的图像被作为验证集。右心室分割挑战的组织者有一个单独的测试集,由其他32个患者的514个MRI图像组成,用以最终评估提交的预测模型。
现在让我们来看模型架构。
▍U-net:基线模型
由于我们只有4周的时间来完成我们在Insight的项目,所以我想尽可能快地获得一个基准模型并实施。我选择由Ronneberger,Fischer和Brox提出的u-net模型,因为它在生物医学分割任务中已经取得了相当的成功。
U-net模型很有潜力,其作者能够只用30张图像,通过激进的图像增强和像素加权来训练他们的网络。
u-net架构由一个收缩路径组成,其将图像折叠成一组高级特征,随后是使用特征信息构建像素分割掩码的扩展路径。U-net独特的方面是其“复制和连接(copy and concatenate)”连接方式,它将信息从早期特征图传递到构建分割掩码的网络的后续部分。作者提出,这些连接允许网络同时并入高级特征和像素方面的细节。
我们使用的架构如下所示:
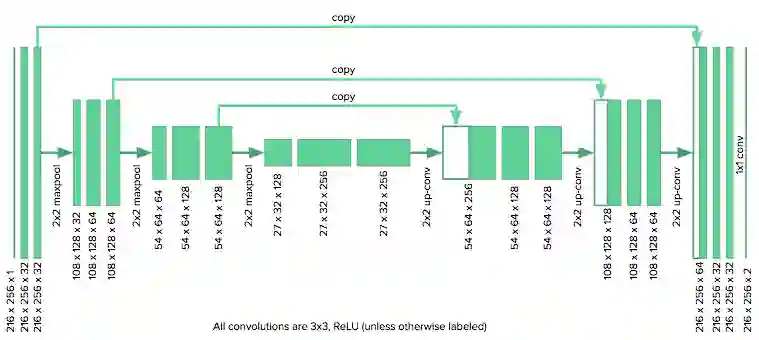
由于我们的图像大小是u-net作者所使用图像大小的一半,所以我们将原始模型中的下采样层数从4个减少到3个。同时,我们采用零填充卷积(而非无填充),以保持图像的大小相同。该模型在Keras实施。
U-net不需要很长的时间来应用和检测,所以我们有时间探索新的架构。我会介绍我开发的另外两种架构,然后展示所有三种架构的结果。
▍扩展u-nets(Dilated u-nets):全局感受野
器官分割需要了解器官如何相对于彼此排列的全局视野。事实证明,即使在u-net的最深的神经元也只有跨越68×68像素的感受野。网络的任何部分都不能“看到”整个图像并将全局上下整合在生成分割蒙版中。原因是网络不了解人类只有一个右心室。例如,下图中它将箭头标记的斑块错误分类为右心室:
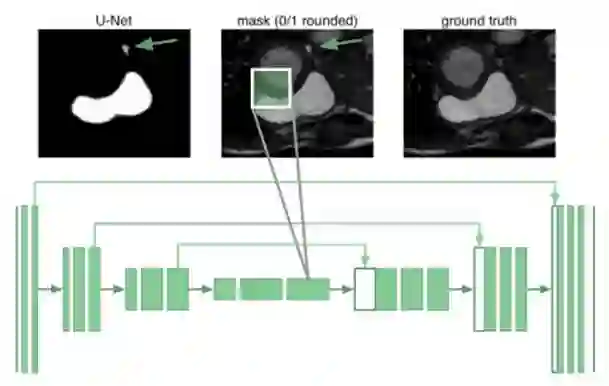
我们采用扩展卷积来增加网络的感受野,而不是增加两个会使参数剧增的下采样层网络。
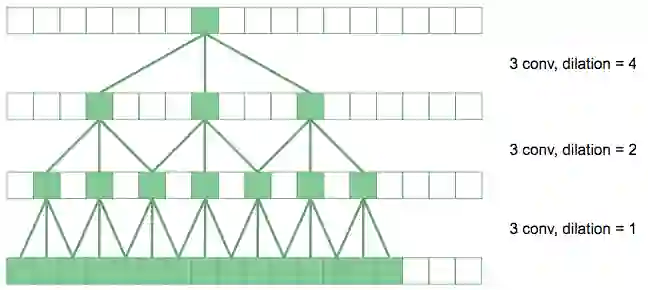
扩展卷积通过扩展因子空出卷积中累加的像素。在上图中,底层的卷积是常规的3×3卷积。上一层,扩展因子为2,我们将卷积扩大了2倍,所以在原始图像中的有效感受野是7×7。顶层卷积扩大4,产生15×15个感受野。相较于堆叠传统卷积的线性膨胀,扩展卷积产生具有深度的指数级膨胀的感受野。
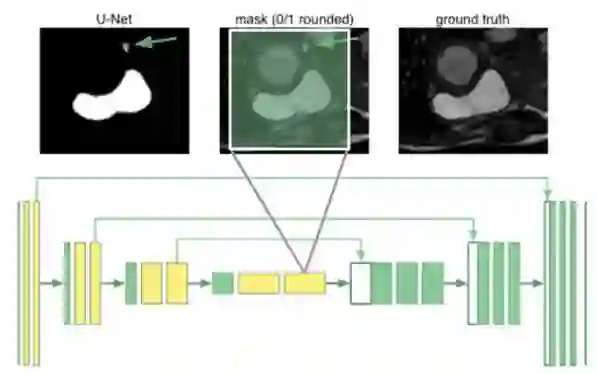
在我们的u-net原理图中,我们用黄色标识出扩展卷积特征图,代替了传统的卷积层。最内层的神经元现在具有覆盖整个输入图像的感受野。我们称这个架构为“扩展u-net(dilated u-net)”。
▍扩展densenets:一次性完成多尺度信息收集
对于分割任务,我们需要来自多个尺度的全局内容和信息来产生像素掩码。如果我们只使用扩展卷积来产生全局内容,而不采用下采样将图像“粉碎”到一个教小的高度和宽度,能行吗?现在卷积层都具有相同的大小,我们可以在所有层之间使用“复制和连接”的连接方式:
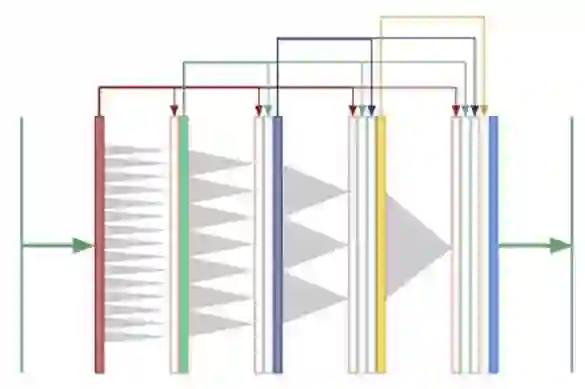
这是一个“扩展densenets”,它结合了两个想法:扩展的卷积和densenets,由Huang等人开发。
在densenets中,第一卷积层的输出作为输入传送到所有后续层中,类似的第二,第三层也向后传送,等等。作者表示densenets有几个优点:
减轻梯度消失的问题,加强特征传播,鼓励特征重用,大幅减少参数数量。
在论文中,densenets已超过了CIFAR和ImageNet分类的最佳表现。
然而,densenets有一个严重的缺陷:由于特征的数量会随着网络的深入而呈倍数增长,因此会极度消耗内存。作者使用“过渡层”来减少通过网络中途的特征图的数量,以便分别训练其40,100和250层densenets。因为只需要8层就能“查看”整个256×256图像,扩展卷积消除了对这种深层网络和过渡层的需求。
在扩展densenets的最终卷积层中,神经元可以访问全局内容以及网络中每一个之前产生的特征。在我们的工作中,我们使用8层扩展densenets,并将生长率从12增加到32。令人吃惊的是:扩展densenets非常节省参数。我们的最终模型仅仅使用了190K个参数,我们将在讨论结果时说到这一点。
现在,让我们来看看如何训练这些模型,然后看看它们在分割右心室的表现。
▍训练:损失函数和超参数?
还需要有一种方法来对数据集上的模型性能进行量化。RV分割挑战赛的组织者选择使用了戴斯系数。模型会输出一个掩码*X*来描述RV,而戴斯系数将*X*与由医师创建的掩码*Y*通过以下方式进行比较:


计算值是交叉区域与两区域之和的比率的两倍。对于不相交的区域,值为0;如果两区域完全一致,则值为1。
度量是掩码(2倍)交集与区域之和的比。不相交的区域为0,完全一致的区域为1。(戴斯系数系数也被称为信息检索领域中的F1得分,因为我们希望最大限度地提高精确度和回收率。)在本节的其余部分,提供了训练方法的各种技术细节–您也可以略过该部分,随时跳到结果部分。
我们使用标准的像素方向交叉熵损失,同时也使用“软”戴斯系数损失进行实验。由nk表示模型的输出,其中n表示遍历所有像素,k表示遍历类(在我们的例子中,背景与右心室)。真实值进行单热编码并用ynk表示。
对于像素方向的交叉熵,我们使用了权重wk来重新加权严重不平衡的类别:
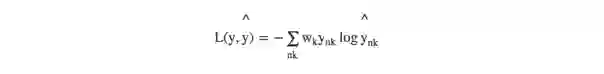
相较于简单平均对应的wbackground = wRV= 0.5,我们用wbackground = 0.1 和wRV = 0. 9进行实验,以调整模型更加倾向右心室的像素。
我们还使用一个“软”戴斯系数损失函数再次总结类别与权重wk,使其重新平衡:
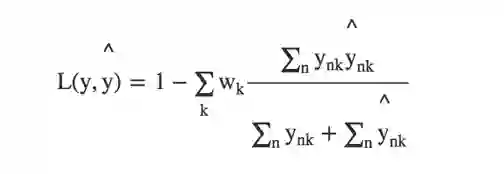
我们用1减去戴斯系数,使损失趋于零。在每个像素nk的输出概率不为[nk]∈{0,1} 的时候,该戴斯系数是“软的”。当舍入后的值不可微分时,该函数不能用作损失函数。我们使用通常的“硬”戴斯系数来报告分类表现。
在我们的训练中,我们改变了以下超参数:
批量归一化(Batch normalization)
Dropout
学习率(Learning rate)
增长率(Growth rate -- 扩展 densenets)
对于下面显示的最终结果,我们使用了adam优化器的默认初始学习率10-3,并训练500个周期。数据集中的每个图像通过减去其平均值,并除以其标准偏差进行单独归一化。
因为表现得比加权和戴斯损失函数更好,我们使用未加权像素交叉熵作为损失函数。没有使用Dropout,因为它实际上降低了验证表现。预激活批量归一化仅用于扩展densenets,因为批量归一化降低了u-net和扩展u-net的性能。
扩展 densenets的增长率为24,达到模型性能与大小的良好平衡。除了扩展densenets层,我们使用的批量大小为32。由于内存限制,我们的16GB GPU只能以批量大小为3处理扩展densenets。
▍结果
吴恩达在这个十分有益的谈话中,解释了如何通过评估人类表现,来提供评估模型表现的路线图。研究人员估计,人类对右心室分割任务的骰子评分为0.90(0.10)(我们在括号中写出标准偏差) [8]。早先发布的模型是Tran [9]的完全卷积网络(FCN),其在测试集上的精度为0.84(0.21)。
u-net基线模型在训练集上得到0.91(0.06)的戴斯得分,这意味着该模型和人类表现没有明显差距。然而,其验证集的精度仅为0.82(0.23),有着较大的方差。正如吴恩达所说,这些都是可以通过获得更多的数据(这个项目中不可能),正则化(dropout和批量归一化并没有帮助)或尝试新的模型架构来解决。
这导致了对极端案例的审查,对感受野更好的了解,最终形成了扩展u-net架构。它突破了原始的u-net表现,在训练集上的精度达到0.92(0.08),在验证集上的精度达到0.85(0.19)。
最后,受到物理学中扩展卷积和tensor networks 的相似性启发的,扩展densenets应运而生。 该架构在训练集上的精度达到0.91(0.10),并仅以0.19M个参数在验证集上使精度达到0.87(0.15)。
最终测试需要提交模型到右心室分割挑战,利用组织举办者提供的测试集评估模型产生的分割轮廓。扩展u-net打破了最先进的技术,尽管减少了〜20×的参数,扩展densenets的表现也紧随其后!
结果总结在下表中。表中的值是骰子系数,括号中的是模型的不确定性。最先进的技术是足够大胆的。对心内膜的分割:
Method |
Train |
Val |
Test |
Params |
Human |
– |
– |
0.90 (0.10) |
– |
FCN (Tran 2017) |
– |
– |
0.84 (0.21) |
~11M |
U-net |
0.91 (0.06) |
0.82 (0.23) |
0.79 (0.28) |
1.9M |
Dilated u-net |
0.92 (0.08) |
0.85 (0.19) |
0.84 (0.21) |
3.7M |
Dilated densenet |
0.91 (0.10) |
0.87 (0.15) |
0.83 (0.22) |
0.19M |
对心外膜的分割:
Method |
Train |
Val |
Test |
Params |
Human |
– |
– |
0.90 (0.10) |
– |
FCN (Tran 2017) |
– |
– |
0.86 (0.20) |
~11M |
U-net |
0.93 (0.07) |
0.86 (0.17) |
0.77 (0.30) |
1.9M |
Dilated u-net |
0.94 (0.05) |
0.90 (0.14) |
0.88 (0.18) |
3.7M |
Dilated densenet |
0.94 (0.04) |
0.89 (0.15) |
0.85 (0.20) |
0.19M |
典型的学习曲线如下所示。在所有情况下,验证损失高原并没有表现出过度拟合的上升特性。在每个周期,都可以看到扩展densenets的学习速度相对于u-net和扩展u-net的惊人表现。
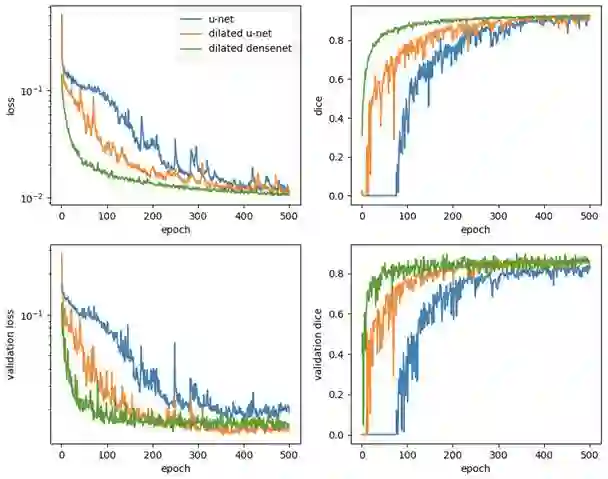
回到心脏分割,在我们的结果以及出版的文献中,戴斯评分显示出很大的标准偏差。 箱形图显示,对于某些图像,网络难以在任何程度上分割右心室:
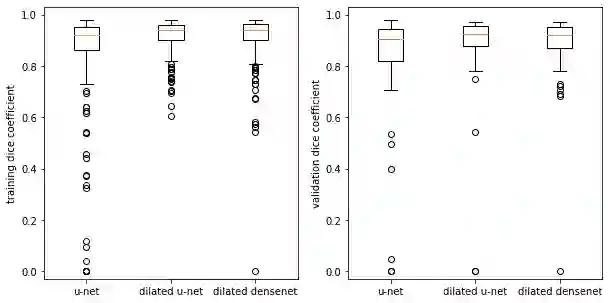
检查异常值时,我们发现它们主要来自右心室难以识别的心脏顶端切片(靠近底部尖端)。 这是验证集上扩展densenets的所示异常值:

右心室在原始图像中几乎看不到,真实值的面积也相当小。将其与比较成功的分割比较:

或者简单的情况比较:
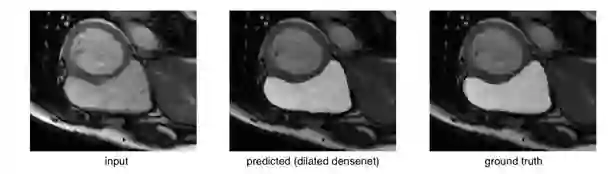
考虑到这些极端案例,很明显,这些模型面临的一个巨大挑战在于消除灾难性的失败,因为它们会导致心脏体积的变化。通过消除这些异常值来减少标准偏差将提高平均骰子得分。
▍总结和展望
深度学习模型的表现有时候似乎是神奇的,但它们的结果却是一个个精心的工程。即使在具有小数据集的情况下,精心挑选的数据增强方案也可以使深度学习模型得到广泛的应用。
通过对数据经过模型的过程的推理,可以得到与问题领域良好匹配的架构。按照这些想法,我们能够创建最先进的模型,来分割心脏MRI中的右心室。我将非常高兴看到扩展densenets在其他图像分割任务的应用,并探索其架构布局。
我将以对未来的一些想法作为本篇的结束:
重新权重数据集,以强调难以分割的顶点切片。
探索准3D模型,可以将完整的心脏切片同时投入模型。
探索多步(本地化,注册,细分)管道。
在生产系统中优化投射分数(最终品质因数)。
高效利用内存的扩展densenets:密集连接网络对内存的大量需求恶名昭彰。原始的TensorFlow更是特别令人震惊,将我们限制在8层网络,16GB GPU上的批量大小仅能为3。切换到最近提出的内存高效实现[10]方法,将允许更深层次的体系架构。
▍关于这个项目
Insight AI研究员计划是一个高强度的7周计划,让已经拥有深厚技术的研究人员填补技能空白,进入AI领域。填补空白的一个重要组成部分,便是完成一个深度学习项目,以获得AI的实践经验。
作为深度学习的新手,我像一位新的研究生一样:选择一个可以在4周内解决,有着明确的动机和应用范围很广的问题。我故意选择了一个小数据集的项目,以便我能够快速迭代并获得经验。这个项目达到了上述目标,并提供了创造扩展densenets的智力乐园。
项目代码:https://github.com/chuckyee/cardiac-segmentation
数据集:http://www.litislab.fr/?sub_project=how-to-download-the-data
★推荐阅读★
长期招聘志愿者
加入「AI从业者社群」请备注个人信息
添加小鸡微信 liulailiuwang




