可以丢掉SGD和Adam了,新的深度学习优化器Ranger:RAdam + LookAhead强强结合
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者: Less Wright
编译:ronghuaiyang
【导 读】给大家介绍一个新的深度学习优化器,Ranger,同时具备RAdam和LookAhead的优点,一行代码提升你的模型能力。
Ranger 优化器结合了两个非常新的发展(RAdam + Lookahead)到一个单一的优化器中。为了证明它的有效性,我们的团队最近使用 Ranger 优化器在 FastAI 全球排行榜上获得了 12 个排行榜记录。
Lookahead 是 Ranger 优化器的其中一半,是由著名的深度学习研究员 Geoffrey Hinton 在 2019 年 7 月的一篇新论文“LookAhead optimizer: k steps forward, 1 step back“中介绍的。LookAhead 的灵感来自于最近在理解神经网络损失曲面方面的进展,并提出了一种全新的稳定深度学习训练和收敛速度的方法。基于 RAdam(Rectified Adam)在深度学习的方差管理方面取得的突破,我发现将 RAdam + LookAhead 组合在一起(Ranger)可以产生一个梦之队,可以得到甚至比单独的 RAdam 更好的优化器。
Ranger 优化器是一个易于使用和高效的单一代码库(加载/保存和一个循环处理的所有参数的更新),集成到了 FastAI 中,Ranger 的源代码你可以直接拿来用:
https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
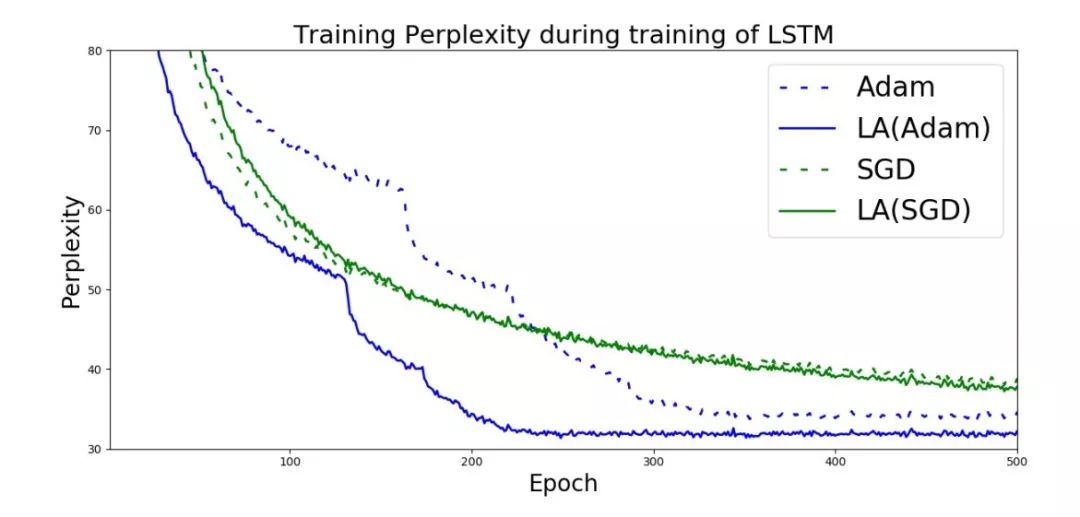
Adam,SGD和Look Ahead + Adam/SGD在LSTM上的对比
为什么 RAdam 和 LookAhead 是互补的
可以说,RAdam 为优化器在开始训练时提供了最好的基础。RAdam 利用一个动态整流器来根据变化调整 Adam 的自适应动量,针对当前数据集,有效地提供了一个自动 warm-up,,以确保可以得到一个扎实的训练开头。
LookAhead 的灵感来自于最近对深度神经网络损失曲面的理解,并为在整个训练过程中进行健壮和稳定的探索提供了突破。
引用 LookAhead 团队的话说,LookAhead“减少了对大量超参数调优的需求”,同时“以最小的计算开销在不同深度学习任务之间实现更快的收敛”。
因此,两者都在深度学习优化的不同方面提供了突破,并且两者的结合具有高度的协同性,可能为你的深度学习结果提供了两种改进的最佳效果。因此,对更稳定和更健壮的优化方法的追求将继续下去,通过结合两个最新的突破(RAdam + LookAhead),Ranger 的集成有望为深度学习提供另一个进步。
Hinton 等人— “我们通过实验证明,即使在 ImageNet、CIFAR-10/100、神经机器翻译和 Penn Treebank 上使用缺省超参数设置, LookAhead 也可以显著提高 SGD 和 Adam 的性能。”
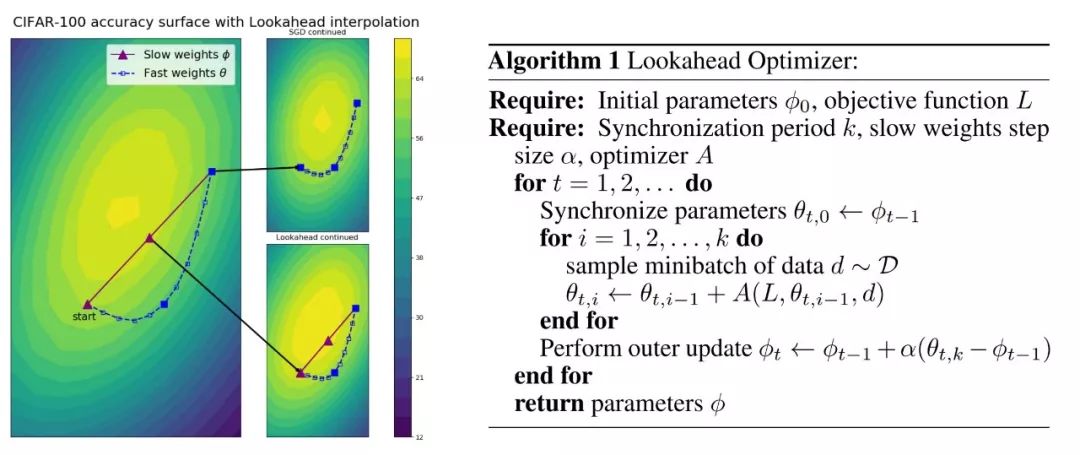
由于LookAhead具有双向探索的设置,因此对比SGD,Lookahead可以优化到距离minima更近的位置。
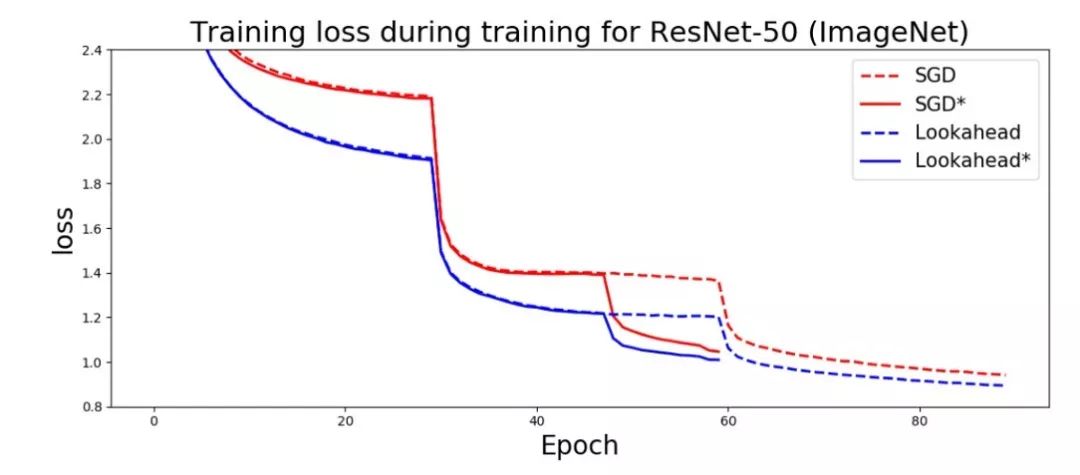
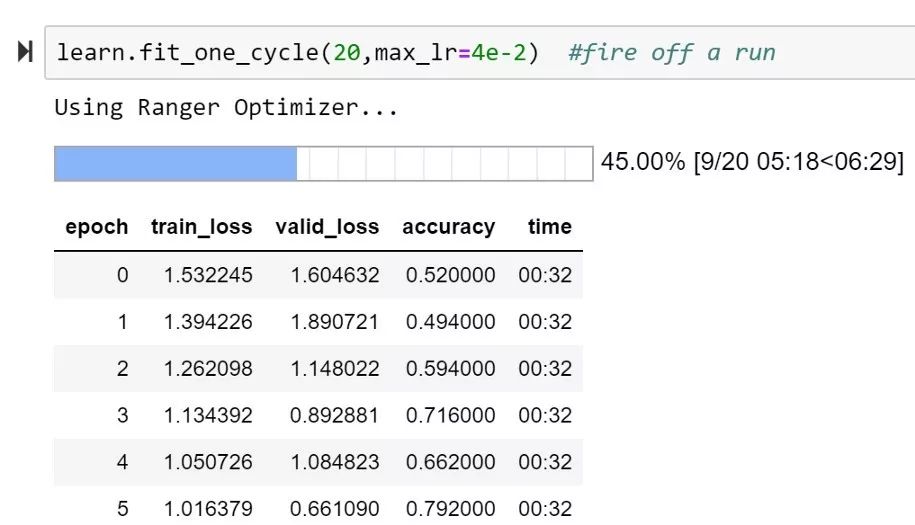
因此,本文在前面的 RAdam 介绍的基础上,解释了什么是 LookAhead,以及如何将 RAdam 和 LookAhead 合并到一个单一的优化器 Ranger 中,从而获得新的高精度。在我测试的前 20 个 epoch 中,我获得了一个新的高准确率,比目前的 FastAI 排行榜高出 1%。
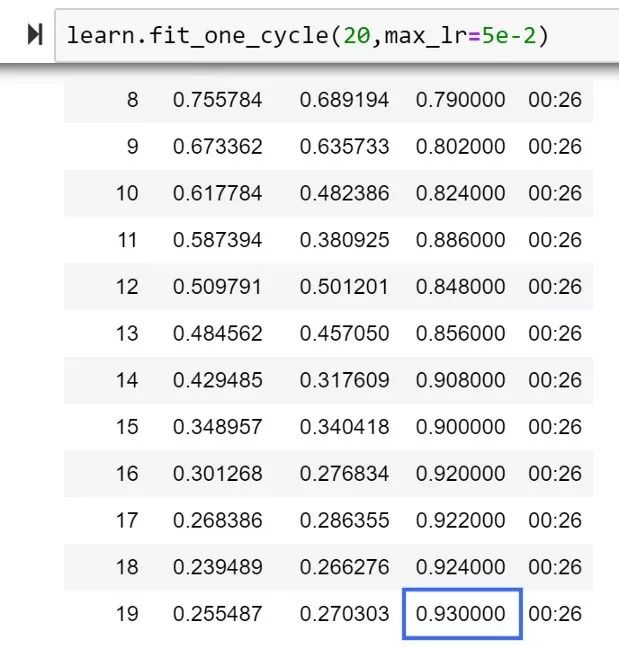
Ranger的第一次测试达到了93%

FastAI排行榜,20个epochs, 92%
更重要的是,任何人都可以使用 Ranger,看看它有没有提高你的深度学习结果的稳定性和准确性!
因此,让我们深入研究驱动 Ranger 的两个组件 — RAdam 和 LookAhead:
1、什么是 RAdam (Rectified Adam):
有个简短的总结,开发 RAdam 的研究人员调查了为什么自适应动量优化器(Adam,RMSProp 等等),所有这些都需要 warmup,否则他们在训练开始前就会陷入糟糕的/可疑的局部最佳状态。
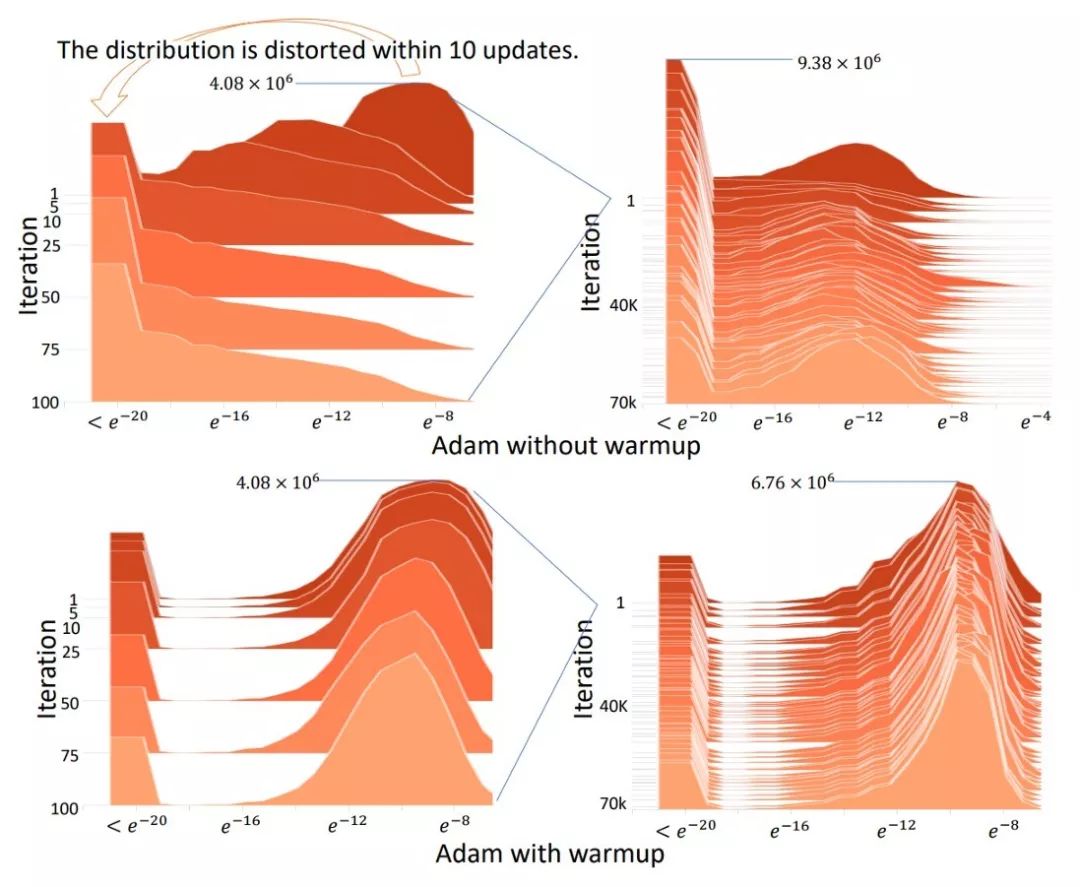
原因是在开始训练时,当优化器没有看到足够的数据来做出准确的自适应动量决策时,数据的方差就会出现非常大的情况。因此,Warmup 可以减少训练开始时的方差……但即使是决定 Warmup 的程度,也需要根据数据集改变手动调整。
因此,Rectified Adam 是通过使用一个整流函数来确定一个“启发式的 Warmup”,这个整流函数是基于实际遇到的方差来确定的。整流器动态的关闭和开启自适应动量,这样它就不会全速跳跃,直到数据的方差稳定下来。
通过这样做,就避免了手动热身的需要,并自动稳定了训练。
一旦方差稳定下来,RAdam 基本上就变成了 Adam,甚至是 SGD。因此,RAdam 的贡献是在训练的开始。
读者注意到,在结果部分,虽然 RAdam 超过了 Adam,但从长远来看,SGD 最终可以赶上并超过 RAdam 和 Adam 的最终精度。
这就是我们现在要使用 LookAhead 的地方,整合一种新的探索机制,即使在 1000 个 epochs 之后也能超越 SGD。
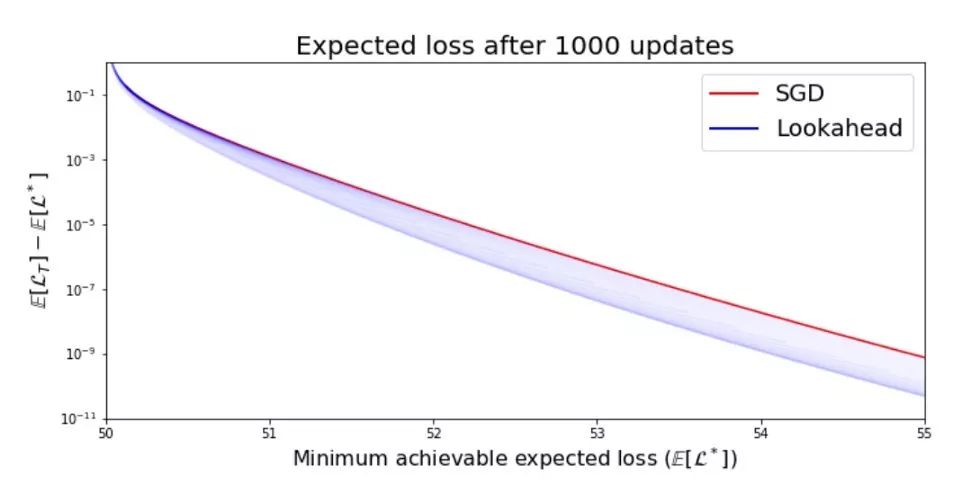
Lookahead使用alpha= 0.5和变化学习率 vs SGD,1000个epoch
2、 Lookahead — 用于探索损失超平面的小伙伴 =更快、更稳定的探索和收敛。
正如 Lookahead 的研究人员所指出的,目前,大多数成功的优化器都是在 SGD 的基础上进行优化的
1 、自适应动量(Adam, AdaGrad)
2 、一种加速形式(Nesterov 动量或 Polyak Heavy Ball)
来完善探索和训练过程,最终趋同。
然而,Lookahead 是一种新的发展,它维持两组权重,然后在它们之间进行插值 — 实际上,它允许一组更快的权重“向前看”或探索,而较慢的权重留在后面,以提供更长期的稳定性。
结果减少了训练过程中的方差,大大降低了对次优超参数的敏感性,并减少了对大量超参数调优的需要。这是在完成各种深度学习任务时实现更快的收敛。换句话说,这是一个令人印象深刻的突破。
通过简单的类比,可以将 LookAhead 理解为以下内容。想象你在一个山顶,周围有各种各样的落差。其中一条通往成功的底部,而其他的只是倒霉的裂缝。
你自己独自探索是困难的,因为你必须选一条路下去,并假设它是一个死胡同,然后再找路出来。
但是,如果你有一个朋友,他呆在或接近顶部,如果你选的路是好的,就帮助你备份,这样你可能会更好的找到最优的路径,因为探索全地形会更快,困倒霉的裂缝的可能性会更小。
这就是 LookAhead 的基本功能。它保留一个额外的权值副本,然后让内部化的“更快”优化器(对于 Ranger,即 RAdam)进行 5 或 6 个 batch 的搜索。batch 间隔由 k 参数指定。
当 k 个 batch 的探索完成时,LookAhead 将它保存的权值与 RAdam 的最新权值之间的差值乘以一个 alpha 参数(默认情况下为 0.5),r 然后更新 RAdam 的权值。

Range代码显示Lookahead更新RAdam的参数
结果实际上是内部优化器(在本例中是 RAdam)的快速移动平均和通过 LookAhead 获得的较慢的指数移动平均的综合效应。速度快的人探索,而速度慢的人则充当拉回或稳定机制 — 通常在速度快的人探索时留在后面,但在某些情况下,当速度快的人继续探索时,速度慢的人会把速度快的人推下一个更有希望的斜坡。
由于具有 LookAhead 的安全性,优化器可以更充分地探索前景,而不必担心陷入困境。
这种方法与目前使用的两种主要方法完全不同——自适应动量或“heavy ball”/Nesterov 类型动量。
因此,LookAhead 在探索和寻找“下降的方式”方面更胜一筹,因为它增强了训练的稳定性,甚至超过了 SGD。
3、Ranger — 一个集成的代码库,提供了把 RAdam 和 LookAhead 结合在一起的优化器
Lookahead 可以和任何优化器一起使用,作为“fast”权值,论文中使用的是 vanilla Adam,因为 RAdam 当时还不可用。

LookAhead的PyTorch集成
然而,为了便于代码集成,简化用法,我合并了成一个单一的优化器,名为 Ranger。
个人看到的ImageNette最高的20个epoch的分数 — 实际上是Ranger的第一次运行。(92%是目前的排行榜)。还要注意稳定的训练进度。
4、现在就来用 Ranger 吧!
在 github 上有几个 LookAhead 的实现,我从 LonePatient 的一个开始,因为我喜欢它简洁的代码,然后在此基础上构建。RAdam,当然来自官方的 RAdam github 代码库。
使用步骤:
1 、 把 ranger.py 拷贝到你的文件夹中
2 、 import ranger:
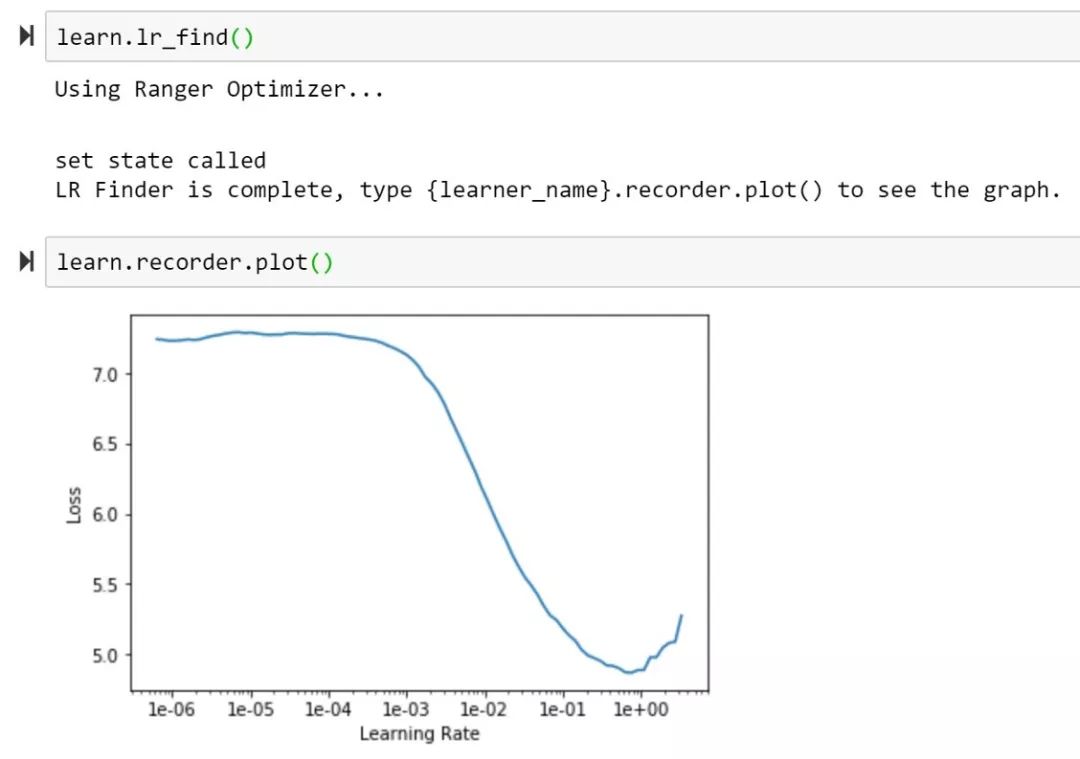
3 、使用 FastAI 构建一个训练准备使用 Ranger。

4 、开始测试!
LookAhead 参数:
k parameter :— 这个参数控制了在与 LookAhead 权值合并之前要运行多少个 batch,常见的默认值是 5 或者 6,论文中使用到了 20。
alpha = 这个参数控制了与 LookAhead 参数差异更新的百分比。Hinton 等人做了一个强有力的证明 0.5 可能是理想值,但值得做个简短的实验验证一下。这篇论文提到的一个未来的想法可能是把 k 和或 alpha 放在一个基于训练进展程度的时间表上。
总结
两个独立的研究团队在实现快速、稳定的深度学习优化算法的目标上取得了新的突破。我发现,通过结合这两个,RAdam + LookAhead,产生了一个增强的优化器(Ranger),并在 ImageNette 验证了运行 20 个 epoch 分数的新高。
需要进一步的测试来优化 LookAhead 的 k 参数和 RAdam 学习率 ,但 LookAhead 和 RAdam 都减少了在达到 state of the art 之前的手动超参数调优,应该可以帮助你得到最好的训练结果。
英文原文:
https://medium.com/@lessw/new-deep-learning-optimizer-ranger-synergistic-combination-of-radam-lookahead-for-the-best-of-2dc83f79a48d
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、姿态估计、超分辨率、嵌入式视觉、OCR 等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~


