深度学习的几何观点(1) - 流形分布定律
作者:顾险峰
(最近,哈佛大学丘成桐先生领导的团队,大连理工大学罗钟铉教授、雷娜教授领导的团队应用几何方法研究深度学习。老顾受邀在一些大学和科研机构做了题为“深度学习的几何观点”的报告,汇报了这方面的进展情况。这里是报告的简要记录,具体内容见【1】。)
深度学习技术正在深刻地改变着人类的历史进程,它在图像识别、语音识别、自然语言处理、文本翻译等几乎所有信息科学领域,都带来了翻天覆地的革命。我们这个时代所面临的最为根本的问题之一就是为深度学习的有效性给出一个合理的答案。
纵观人类历史的历次技术革命,火的使用,青铜器的制作工艺,农业的大规模普及,机械的应用,内燃机的发明,电力电气工业的成熟,电子计算机技术的推广,信息工业的蓬勃发展等等,无一不是建筑在深刻的自然科学原理之上的。虽然当时人类可能主观上并没有真正意识到,但是在客观上都是顺应了自然,可能是物理、化学、或者生物方面的基本定律。那么深度学习的巨大成功究竟归功于哪一条自然定律?
我们认为,和历史上的历次技术革命不同,深度学习的成功是基于两条:数据本身的内在规律,深度学习技术能够揭示并利用这些规律。数据科学(或者信息科学)中的基本定律(或者更为保守的,基本假设)可以归结为:
1. 流形分布定律:自然界中同一类别的高维数据,往往集中在某个低维流形附近。
2. 聚类分布定律:这一类别中不同的子类对应着流形上的不同概率分布,这些分布之间的距离大到足够将这些子类区分。
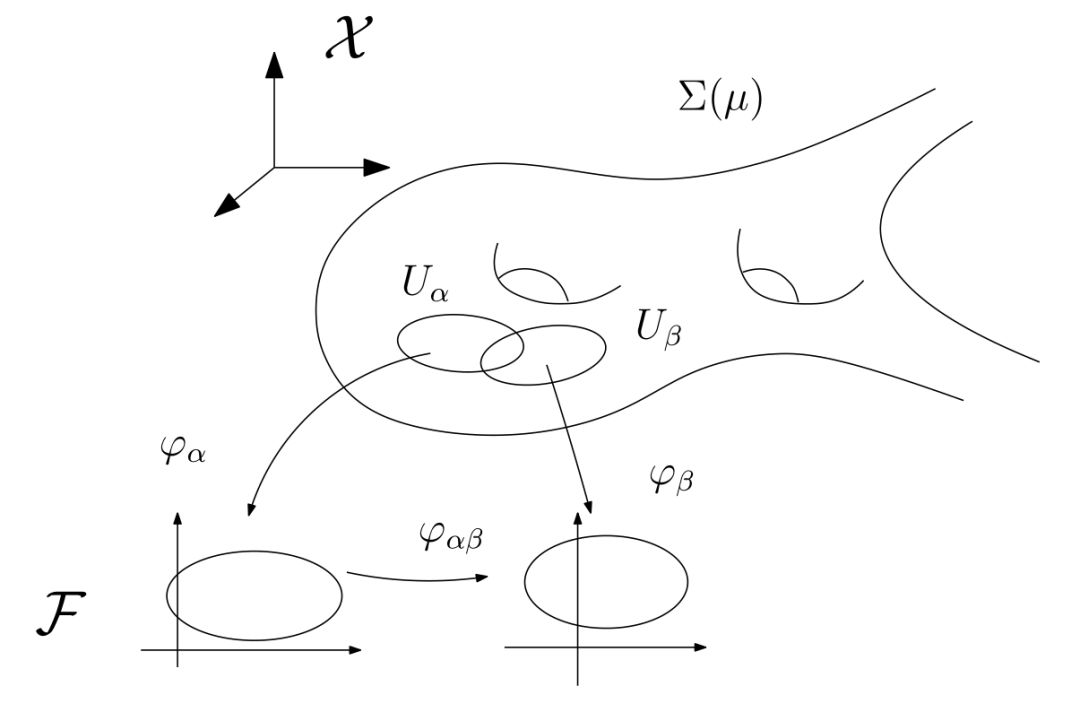
图1. 流形的定义。
深度学习的主要目的和功能之一就是从数据中学习隐藏的流形结构和流形上的概率分布。
关于聚类分布定律,目前有相对完善的理论基础-最优传输理论,和较为实用的算法,例如基于凸几何的蒙日-安培方程解法【2】,这些方法可以测量概率分布之间的距离,实现概率分布之间的变换【3】。关于流形分布定律,目前理论发展不太完备,很多时候学习效果严重依赖于调参。但是很多实际应用问题,都可以用流形的框架来建模,从而用几何的语言来描述、梳理,用几何理论工具来加以解决,进而有望从含混模糊的经验性试错,进化到思路清晰的定量研究。
流形是拓扑和微分几何中最为基本的概念,本质上就是很多欧氏空间粘贴在一起构成的空间。如图1所示,一个流形(manifold)是一个拓扑空间
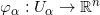
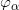
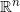
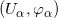
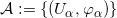
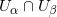
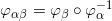
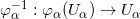
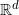
例一:我们试举一例,嵌在三维欧氏空间中的单位球面是最为简单的二维流形,其局部参数表示为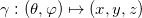
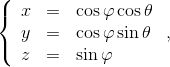
这里球面是流形,三维欧氏空间是背景空间,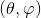
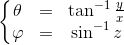
在深度学习中,有关流形的这些基本概念都有相应的术语,我们稍作翻译:流形上的一个点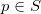


图2. 流形和参数化映射。
例二:如图2所示,米勒佛曲面是三维空间中的二维流形,参数化映射将曲面映射到平面圆盘。这一映射的逆映射给出了曲面的参数化表示。这里,所有的映射都是用分片线性映射来逼近的。注意,这里参数化映射并不唯一,这会带来隐空间概率密度的变化,后面我们会对此进行详细讨论。

图3. 所有人脸图像符合流形分布定律。
例三:我们考察所有
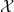
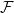
那么在现实中,我们如何学习人脸图像构成的流形呢?这里所谓的“学习”意味着什么?答案是用人脸图片的样本集来训练深度神经网络,我们可以得到人脸图像流形的参数化映射(编码)和局部参数表示(解码)。
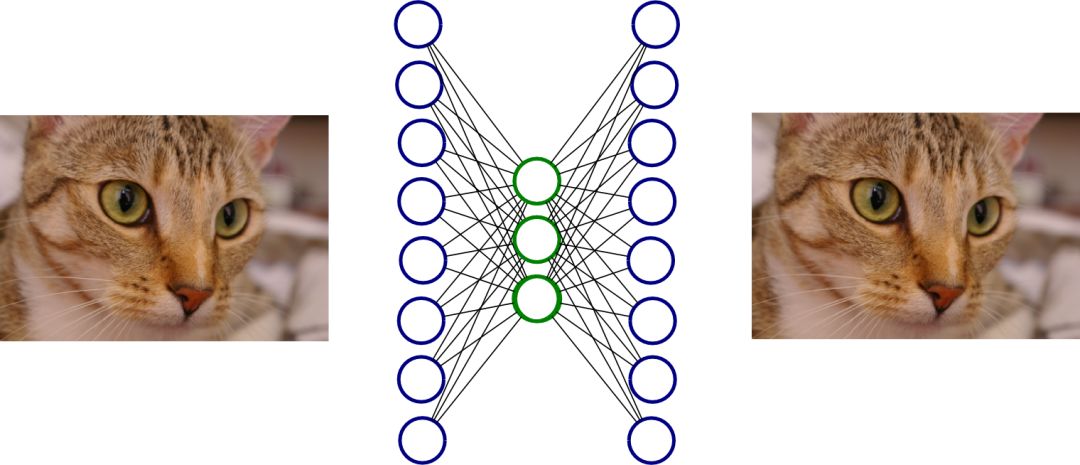
图4. 自动编码解码器。
自动编码器(autoencoder)是非常基本的深度学习模型,用来学习流形结构。如图3所示,自动编码器是一个前馈网络,输入和输出维数相等,输入输出都是背景空间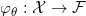
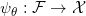
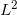
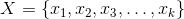
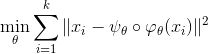
由此,我们得到了编码映射和解码映射,解码映射就是流形的一个参数表示。我们用重建的流形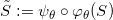
一旦我们掌握了流形在手,我们可以完成很多传统方法无法想象的应用,也可以革新很多传统方法所涉猎的经典应用。下面我们通过几个实例来彰显流形思维框架的威力。

图5. 生成模型。
生成模型是深度学习的一个典型应用,如图5所示,输入一张低维的白噪音,输出一张逼真的人脸图像。这在传统框架下是匪夷所思的:我们妙手空空,平白无故地变出一张人脸!但在流形框架下非常简单。
我们已经训练好了网络,得到了流形的参数表示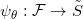
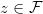
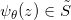
当然,生成图像的质量由很多因素所决定,最为重要的有两个:重建流形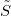
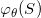
图像去噪是图像处理的经典问题。基于信息论,我们将带有噪音的图像进行傅里叶变换,在频域滤波,去除高频分量,然后再进行傅里叶逆变换,得到去噪图像。因为噪声往往分布在高频部分,因此这一方法比较奏效。这种经典方法比较普适,和图像内容无关。
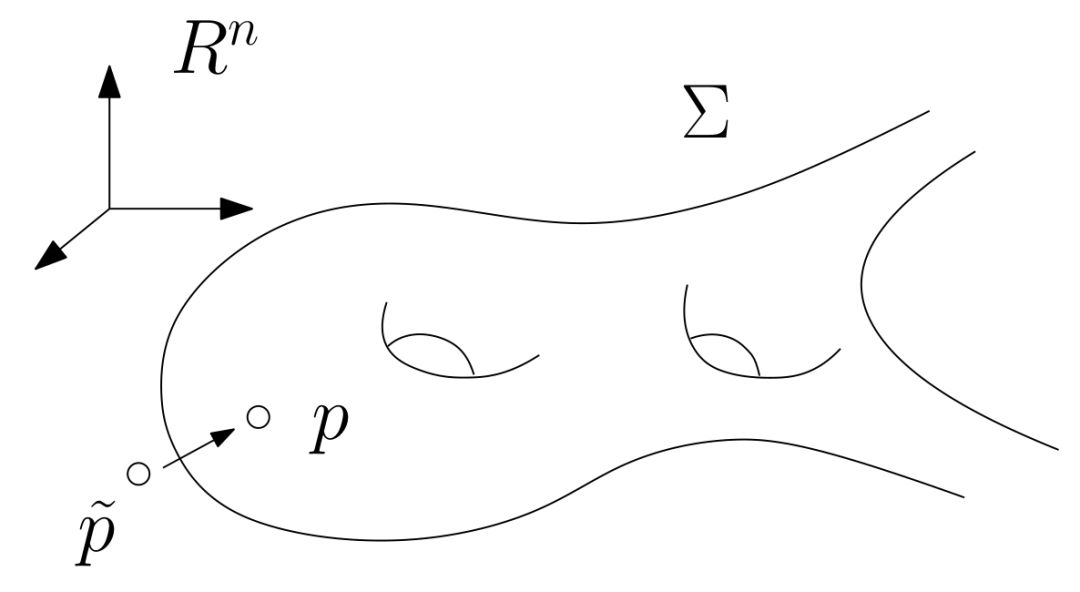
图6. 图像去噪的流形解释。
那么用流形框架如何解释图像去噪呢?如图6所示,假设所有清晰人脸图像构成了一个流形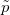
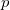

图7. Autoencoder图像去噪结果。
图7显示了基于几何投影思路的图像去噪效果。给定一张带有噪音的人脸图像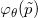
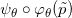
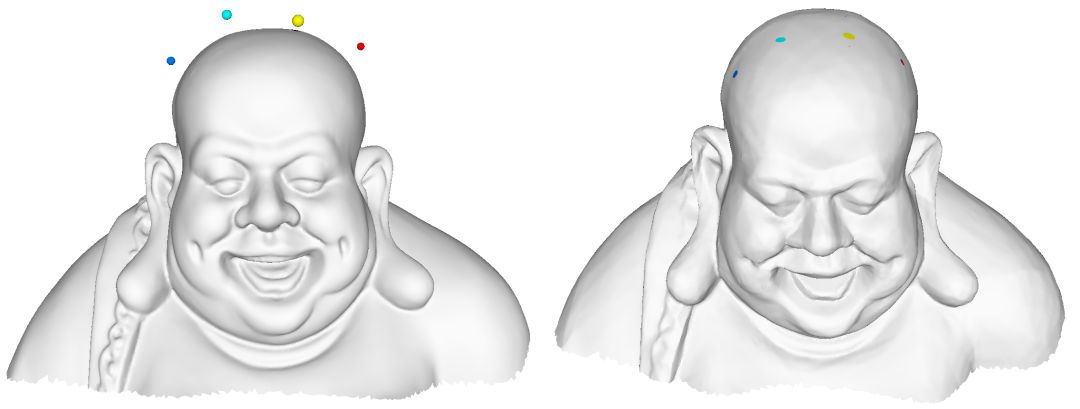
图8. 左帧,输入流形和噪声点;右帧,噪声点被投影到重建的流形上。投影由Autoencoder实现。
这种方法不问噪声的形成机制,适用于各种噪声。但是这种方法严重依赖于图片内容。这里我们进行人脸图像去噪,因此需要清晰人脸图像流形。如果,我们将带噪声的人脸图像向清晰猫脸图像流形投影,所得结果不再具有任何实际意义。
这显示了用深度学习方法去噪的某种局限性,首先我们必须拥有相应的流形,其次不同类型的图像,需要不同的流形。猫脸流形无法应用于人脸图像,反之亦然。这种局限诠释了深度学习仍属于弱人工智能范畴。

图9. 基于深度学习的年龄变换(黄迪教授)。
如图9所示,给定一张人脸图像,生成这张脸二十年后的图像,或者倒推这张脸二十年前的图像,这种变换我们称之为人脸图像年龄变换。对于传统方法而言,人脸图像年龄变换是难以完成的任务。用深度学习的流形框架,我们可以给出清晰的解决方案。
首先我们学习所有二十岁的人脸图像流形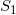
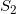
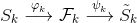
同时我们学习两个流形之间的映射:
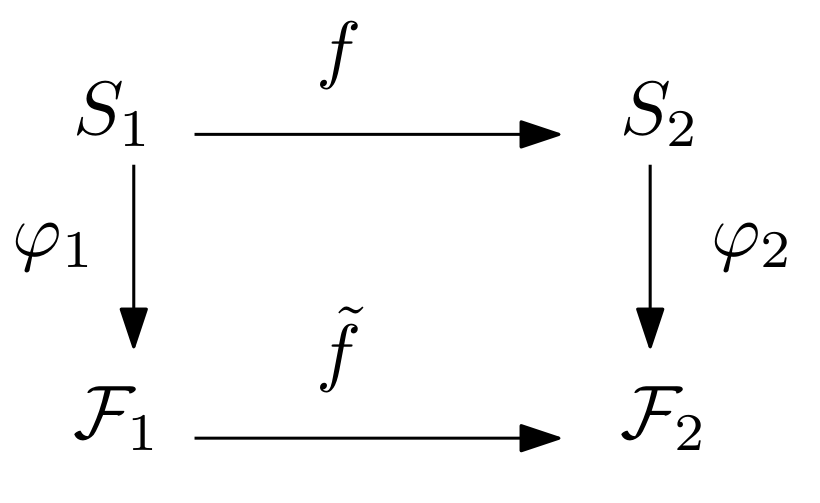
这里隐空间之间的映射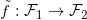
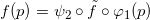
手写体数字识别

图10. 手写体数字流形。
如图10所示,我们考察所有手写体数字二值图像构成的流形,左帧是真实数据,右帧是生成数据。0到9这十个数字在此流形上定义了十个不同的概率分布。我们用编码映射将流形映射到隐空间,编码映射将这十个分布“推前”到隐空间上。为了可视化,我们将隐空间定义为二维平面,如此得到十个概率分布。
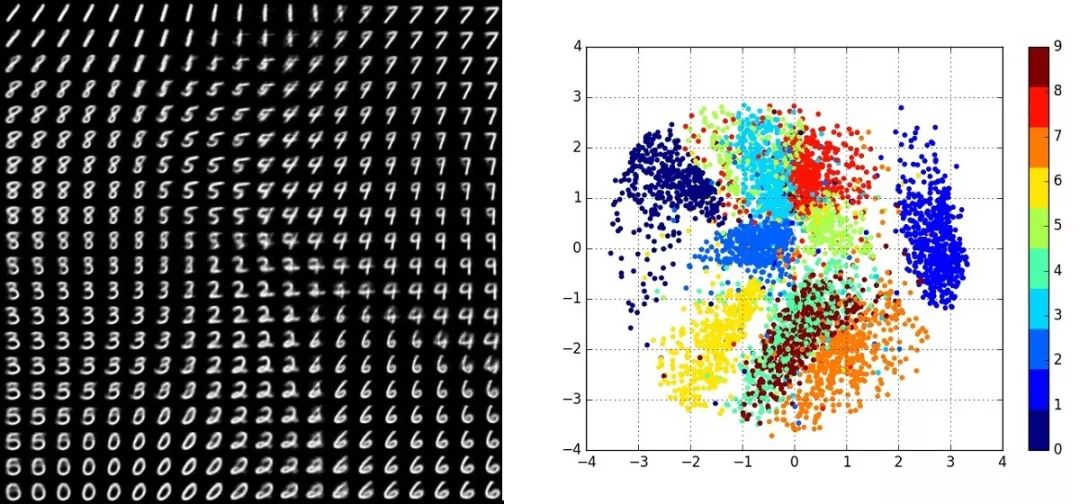
图11. 手写体数字在隐空间的概率分布。
图11显示了不同数字在隐空间的概率分布,这种流形+概率分布可以对知识进行更加详尽的表述,从而用于识别分类等问题。
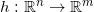
那么,深度神经网络学习流形的能力究竟如何?我们考察一个低维流形的简单例子,见微知著,从中可以观察到一些富有启发的现象。

图 12. 弥勒佛曲面,输入流形。

图13. 隐空间表示和胞腔分解。

图14. 重建流形。
我们假设背景空间是三维欧氏空间,流形是米勒佛曲面,如图12所示。我们在弥勒佛表面上稠密采样,然后训练一个自动编码器,得到编码映射和解码映射。编码映射将曲面映射到隐空间即二维欧氏空间,如图13所示;解码映射将隐空间表示映射回背景空间,得到重建流形,如图14所示。我们采用ReLU作为激活函数,编码解码映射为分片线性映射。编码映射将背景空间分解为很多胞腔,在每个胞腔内编码映射为线性映射,图13右帧画出了背景空间的胞腔分解。我们从图中可以看到重建流形比较精确地逼近了原始的输入流形,几乎保留了所有的几何细节。为了达到这一理想效果,艰苦的调参不可避免。而这正是深度学习的困难所在:缺乏理论指导的实验性调节超参数。
仔细观察这个编码、解码过程,我们看到重建曲面在很大程度上较好地逼近了输入曲面,保持了细微的几何特征,参数化映射建立了整体同胚。由此,引发了下面的问题:
如何从几何上刻画一个深度神经网络的学习能力?是否可以定义一个指标来明确表示神经网络学习能力的上限?
如何从几何上刻画一个流形被学习的难度?是否可以定义一个指标来明确表示这一难度?
对于任意一个深度神经网络,如何构造一个它无法学习的流形?
在下一讲中,我们对这些问题进行深入讨论。
我们认为,深度学习的成功应该归功于数据自身具有内在的规律:高维数据分布在低维流形附近,流形上具有特定概率分布,同时归功于深度学习网络强大的逼近非线性映射的能力。深度学习技术可以从一类数据中提取流形结构,将整体先验知识用流形来表达,具体而言就是编码解码映射,隐含在神经元的权重之中。
深度学习的强大能力来源于某类知识的整体表达,而传统算法只能利用同一类别的局部有限知识。同时深度学习囿于底层流形的选择,很多算法移植性依赖于底层流形的替换。
深度学习的流形框架有助于模块化编程。我们可以想象,在未来深度的商品化硬件或软件模块将是各个类别的流形,和流形之间的映射,以及流形上概率密度之间的变换。底层的流形模块已经被AI公司训练完善,大规模产品化,用户只需要搭建这些模块就可以实现各种功能。
References
Na Lei, Zhongxuan Luo, Shing-Tung Yau and David Xianfeng Gu. "Geometric Understanding of Deep Learning". arXiv:1805.10451 .
https://arxiv.org/abs/1805.10451
Xianfeng Gu, Feng Luo, Jian Sun, and Shing-Tung Yau. "Variational principles for minkowski type problems, discrete optimal transport", and discrete monge-ampere equations. Asian Journal of Mathematics (AJM), 20(2):383-398, 2016.
Na Lei,Kehua Su,Li Cui,Shing-Tung Yau,David Xianfeng Gu, "A Geometric View of Optimal Transportation and Generative Model", arXiv:1710.05488. https://arxiv.org/abs/1710.05488
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习



