【新智元导读】一年一度的MegTech来了!VR裸手写字、「纸片人」跳舞、研发小姐姐在线试妆等各种Demo全亮相。
万万没想到,之前把小伙伴们拉去炼丹的旷厂又来了!
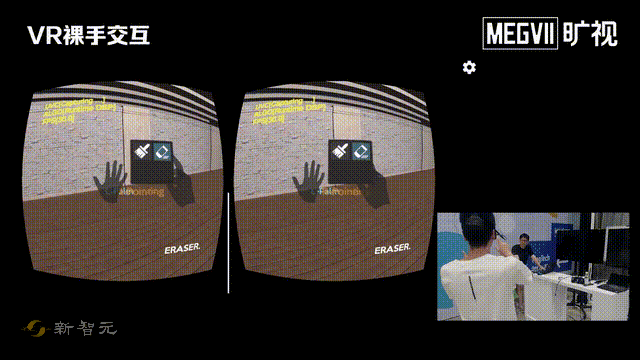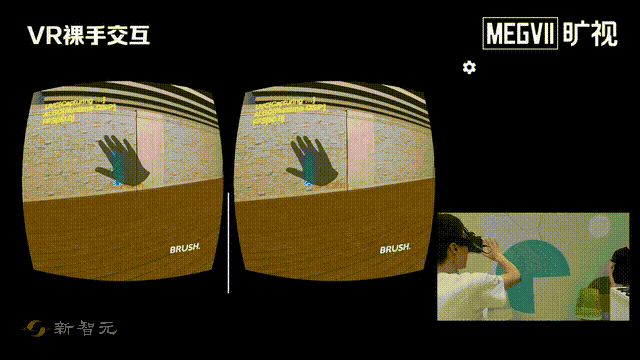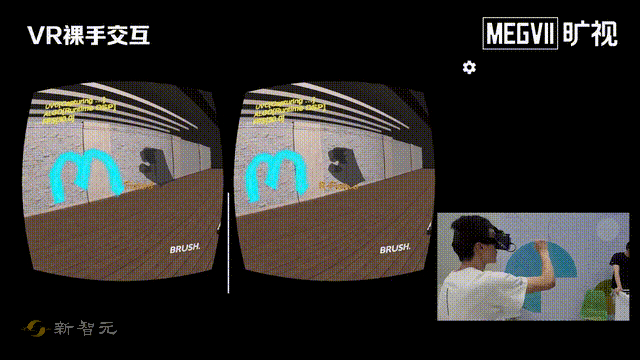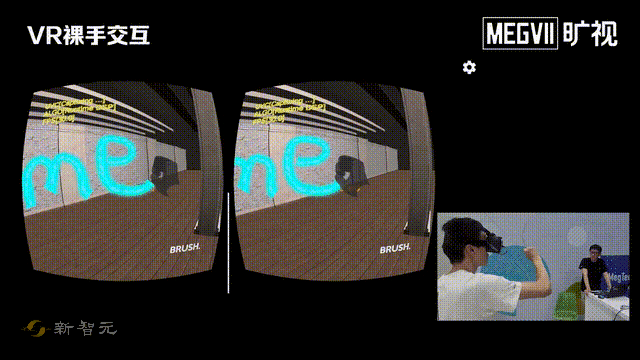
这次一进门,就给我们来了个「左手画个龙,右手画个彩虹」。
![]()
看得出来,这位研发小哥哥的手非常灵活。
刚刚这些好玩儿的技术,就是旷视在一年一度的技术开放日MegTech 2022上秀出的全新肌肉。
作为一家正经的AI公司,刷刷顶会,搞搞前沿技术肯定是少不了的。
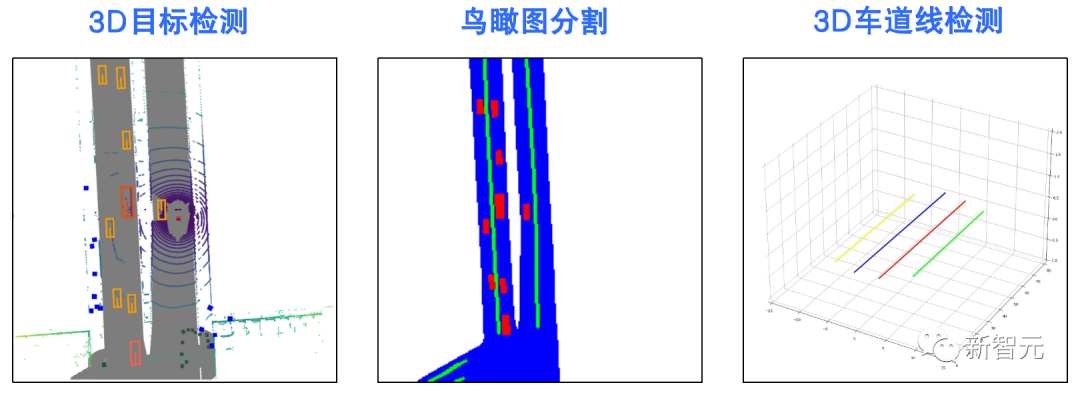
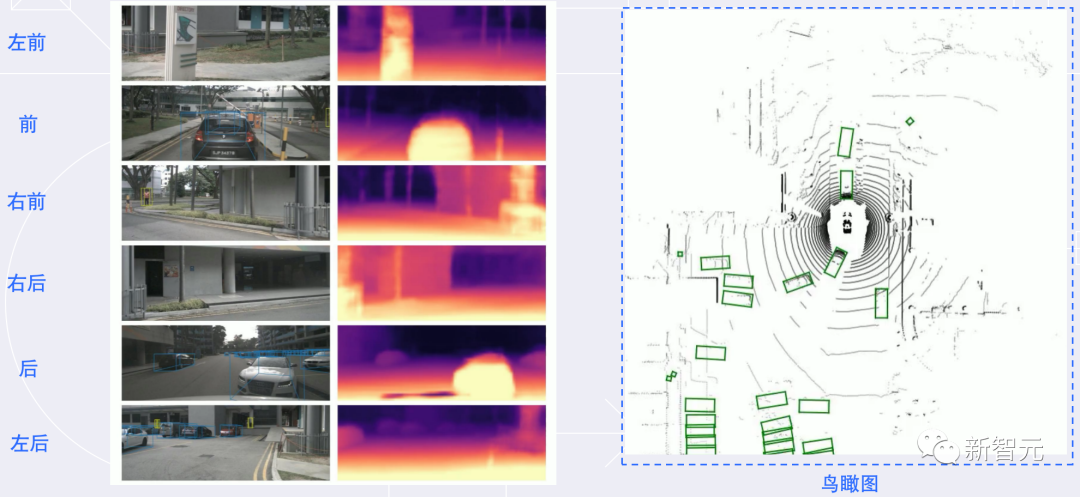
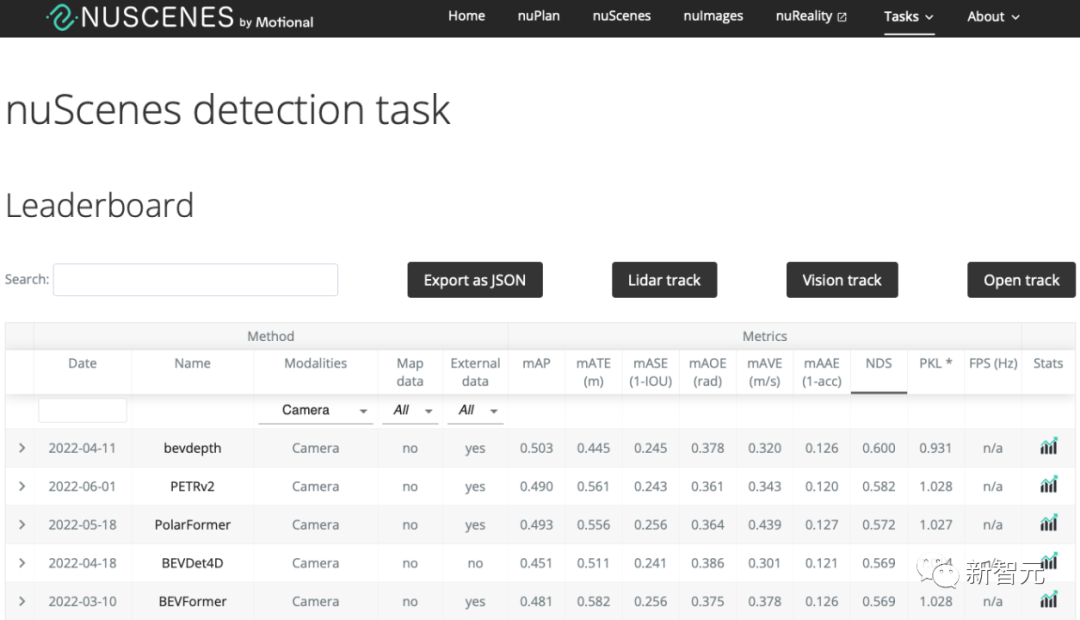
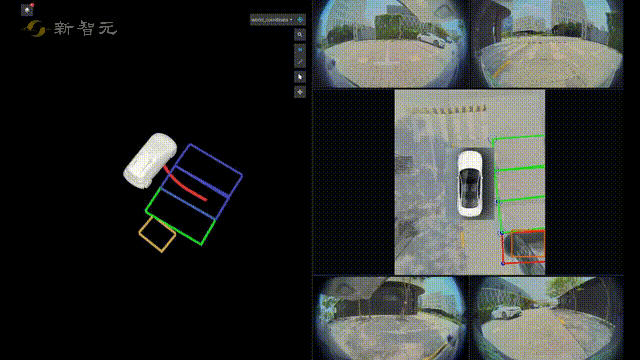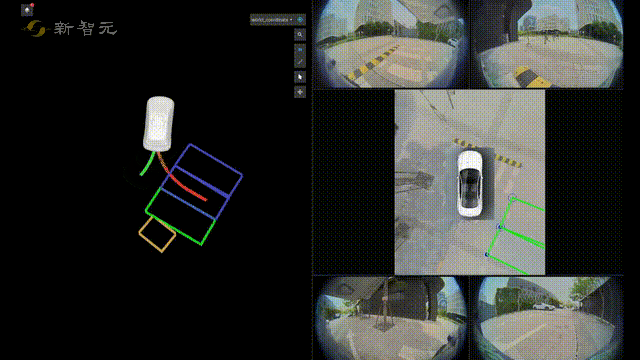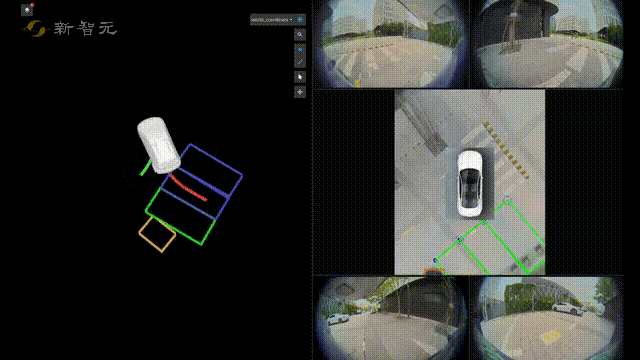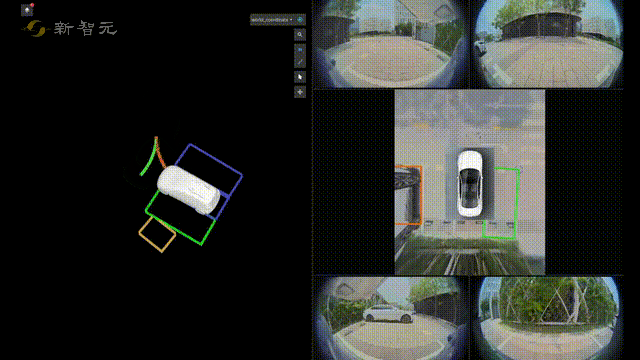
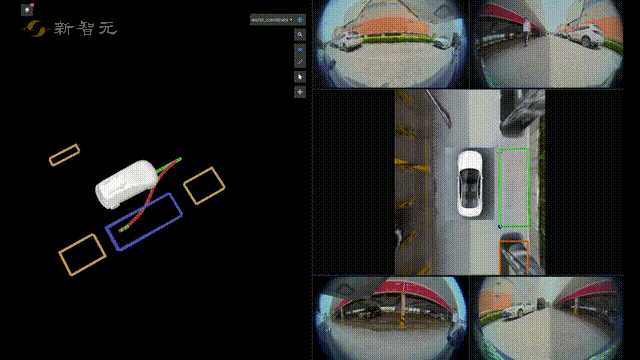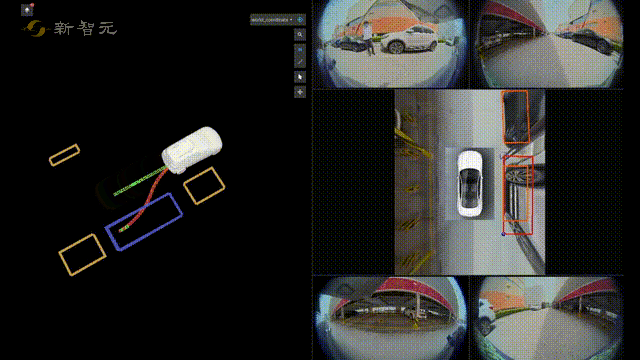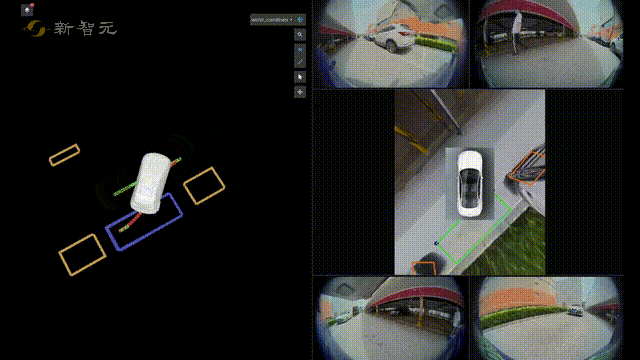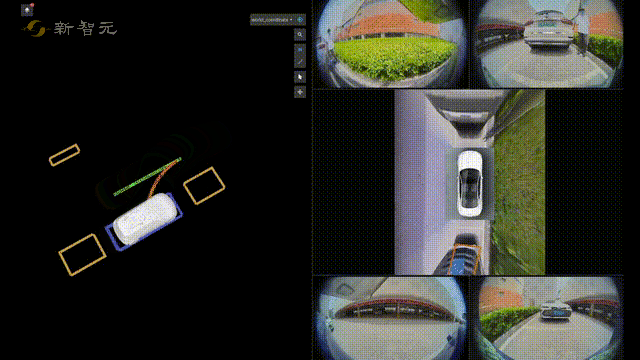
比如在自动驾驶技术预研方面,旷视研究院就提出了一种全新自动驾驶的纯视觉3D感知框架——PETR。
这个PETR框架能同时进行3D目标检测、BEV(Bird's Eye View,鸟瞰图)分割和3D车道线检测等多项感知任务。
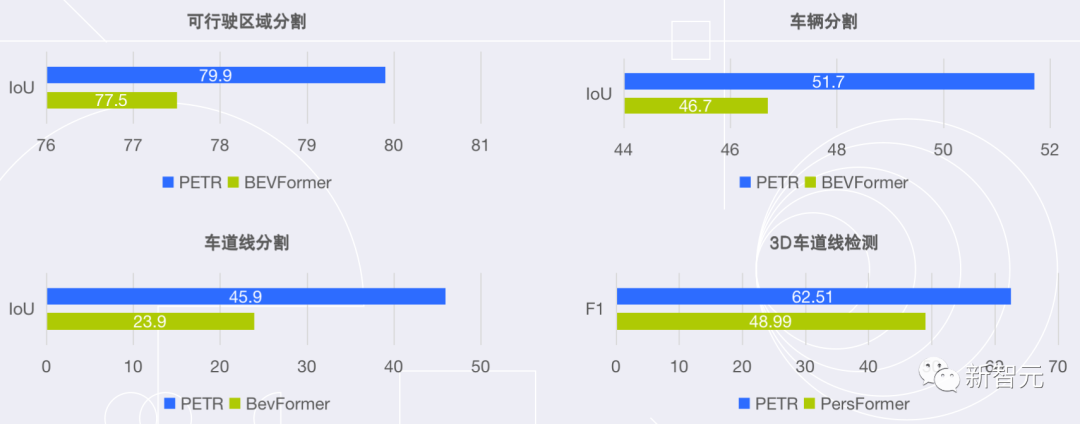
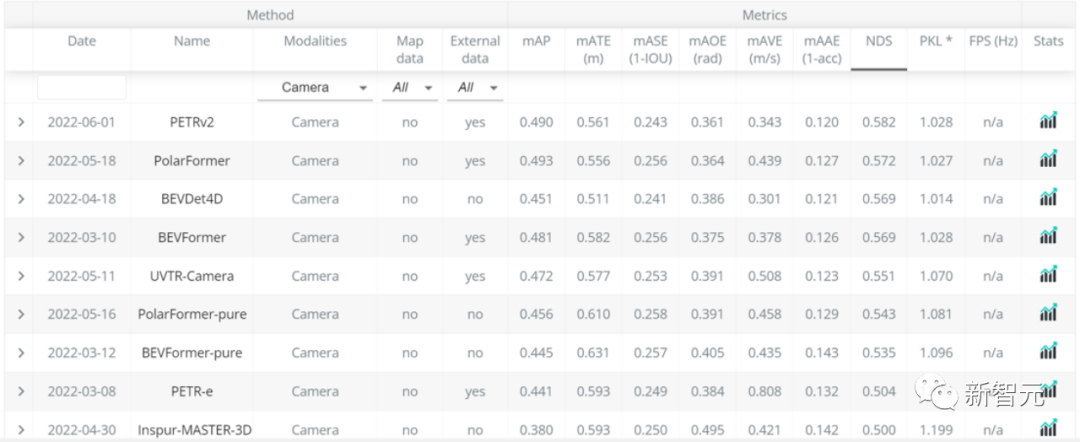
作为PETR系列的最新研究成果,PETRv2在BEV分割和3D车道线检测上,全面优于目前主流模型。
并且在没有使用TTA(Test-Time Augmentation,测试数据增强)的情况下,PETRv2还刷新了纯视觉3D检测榜单nuScenes的记录。
目前,相关论文已经被计算机视觉顶级会议ECCV 2022接收,模型代码也已开源。
为了进一步加强模型在BEV时的性能,旷视研究院又提出了一个新的3D目标检测器BEVDepth。
BEVDepth率先定位了影响视觉3D检测最核心的问题——物体深度估计,继而创新性地使用了未经标注过的点云数据作为监督信号,极大增强网络感知物体深度能力的同时,不影响推理的任何性能。
在nuScenes数据集的3D目标检测比赛上,BEVDepth取得最优结果,平均精度均值mAP达到了0.503。
有了3D目标检测,再加上感知、定位、预测、规划、自主泊车等关键技术,旷视研究院在自动驾驶技术预研方面,也有着不小的进展。
在感知方面,旷视研究院凭借丰富的机器视觉技术积累,在融合感知和视觉感知两方面均达到了业界领先水平,从而可以有效满足不同车型的需求。
同时在定位、预测和规划方面,旷视研究院采用基于深度学习的方案,泛化能力强并且容易维护。
说了这么多,不如拉出来溜溜吧!
除了纯粹的算法,旷视近年来也开始「加大力度」搞硬件,同时也不忘结合原本的优势项目软件。
于是,旷视特有的co-design,也就是「软硬协同设计」诞生了。
而在这次的演示中,也准备了这一趴——「又要马儿跑,又要马儿不吃草」。(不是
言归正传,简单来讲就是在降低功耗的同时,还能保证模型的精度。
尤其是随着AIoT的不断发展,考虑到成本、能耗,以及数据的安全,AI模型也越来越多地从云端拓展到边缘端和设备终端。但由于计算能力和精度等因素限制,嵌入式设备一般只用于模型推理,难以进行模型训练。
于是,旷视的研究员们通过对计算图的设计和混合精度的训练策略,再结合旷视天元MegEngine开源深度学习框架,使ResNet-18、VGG等模型的微调式训练可在一颗用于推理的芯片上实现。
以ResNet-18微调为例,训练时的平均功率仅为2.36W,用一个5V 1A的充电宝就能带得动。微调训练该模型消耗的能量也仅有NVIDIA V100显卡的1/3左右,与A100同量级。
另外,在车载感知方面,模型对于精度和算力需求也非常高。
比如进行大分辨率输入下的行人、车辆3D感知时,单帧单任务下模型推理部分经常需要200-300GOPS以上的计算量。实车跑多个任务时,整套感知系统可消耗多达几十个TOPS的算力,因此在一般的嵌入式系统上难以达成实时推理。
旷视研究院提出模型超级压缩算法,通过软硬协同设计进行算法和硬件联合优化,使得在精度对齐浮点模型的条件下,实现L2级车载感知模型平均速度达到Nvidia NX平台浮点模型的2倍。此时整套系统的AI计算部分功耗保持在3W左右。
最近,跟着直播健身可谓是异常火爆,放眼望去,几乎全是刘畊宏女孩/男孩。
在这方面,旷视也有一个非常有意思的产品——基于纯视觉方案的运动猿小刚。
这名由程序猿开发出的运动猿,可以通过自研模型快速精准的检测超过30个人体骨骼点,准确描述人体运动过程中的各个动作姿态,并完成高精度的测距、测速和计数。
其中的跳绳产品,可在240次/分钟的条件下,实现±1误差的精度。相较普通传感器方案,运动猿小刚可有效判断违规,准确识别有绳或无绳。
小编直接亲自上场测试了一波:半分钟也就跳了100多下吧。
仰卧起坐产品则通过准确的骨骼点模型,支持仰卧起坐过程中的双手未抱头、双腿未屈膝、手肘未触碰膝盖等多种违规情况识别,准确记录运动过程中的真实数据,达到±1的计数要求。
立定跳远产品通过精确的人体骨骼点模型,可以准确判断脚部的各项动作,达到±1cm的精度,并可以识别过线、助跑等各类违规动作。
说到视觉,除了这种「只有计算机才能看得到」的以外,还有不少是可以通过肉眼直观感受到的。
只需在理解场景信息的基础上,将画面中的物体尽可能恢复到它本来的亮度,完成与真实观感接近的色调映射与高光恢复,同时融合多帧特征信息来加强细节,就可以准确还原多彩明亮的世界了。
这个模式集合了人像虚化、视频人像留色、视频双重曝光和视频光斑四种视频特效以及最新研发的电影模式算法。
其中,视频特效通过视频人像分割算法、深度信息以及丰富而有趣的图像处理算法,可以满足不同场景和人物的拍摄需求,丰富拍摄体验。
电影模式算法则利用单摄深度信息、对焦主体检测和多目标跟踪算法、图像虚化算法,实现手机平台模拟单反大光圈的视频效果,并在此基础上叠加手动切焦技术,实时实现顺滑的焦点变换,模拟出电影镜头般的拍摄效果,从而提高视频故事感。
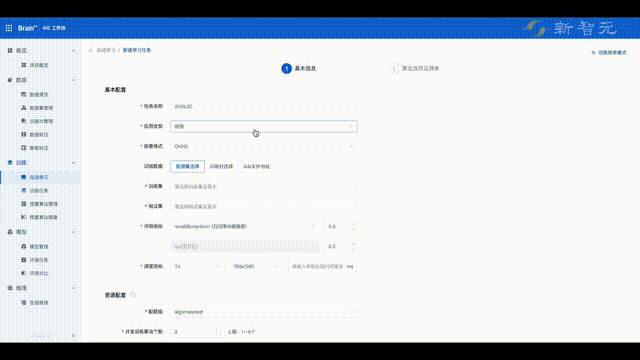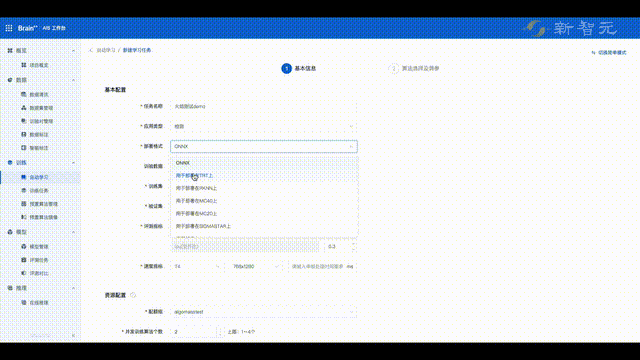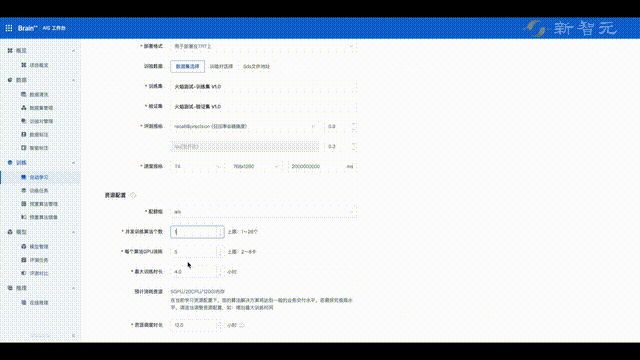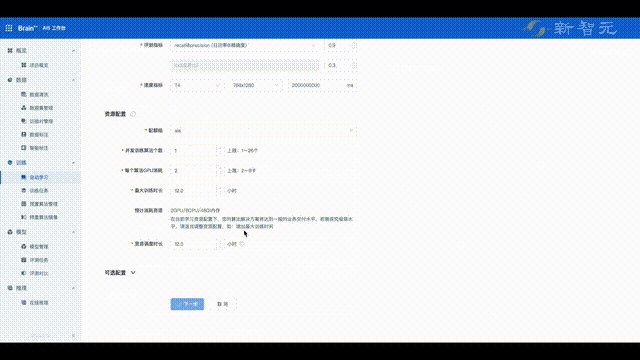
最后,集多年算法生产经验于一身的旷视,又打造出了一套一站式MLOps算法生产平台。
刚刚我们看到的这些已经落地的应用,有些就是通过AIS算法生产平台研发而成。
具体来说,旷视AIS(AI Service)算法生产平台,提供了从数据清洗、智能标注、数据管理、数据质检、算法自动生产、模型多维能力评测、pipeline部署等全流程能力,并支持算法快速生产部署。
就拿模型训练来说,基于旷视研究院自研的算法库以及算法推荐能力,用户只需提供训验数据、选择模型训练目标,AIS算法生产平台就能自动自动训练出表现良好的模型。
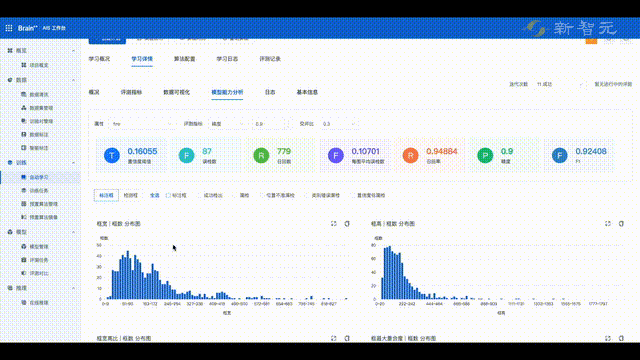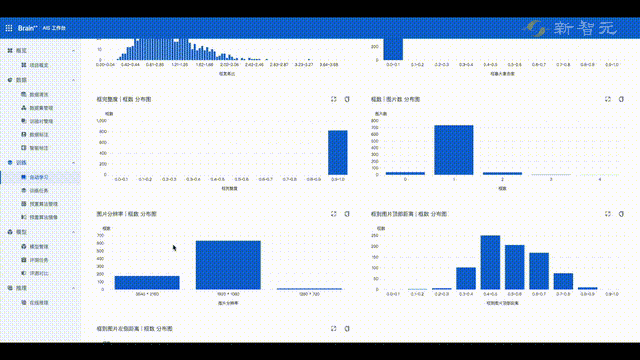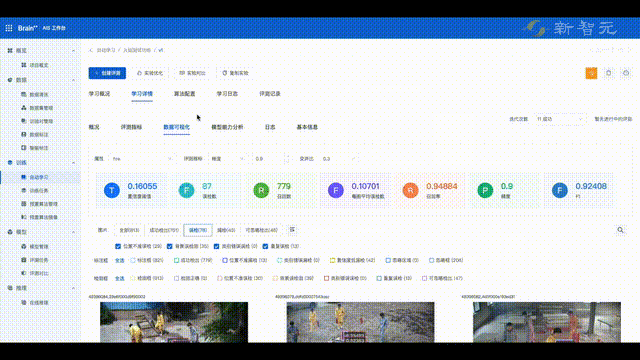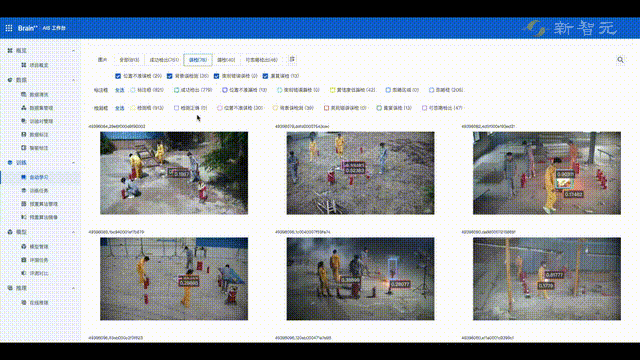
目前,平台已经能够支持100多种业务模型训练,2小时即可完成,而且模型产出精度指标远高于业界平均水平。
在接下来的模型测试中,平台提供了可视化的训练过程,并会统计出模型在不同分布、不同维度下的表现,帮助快速定位模型的问题,进一步优化模型。
最后,利用旷视自研的ADS(Auto Deploy Service)模型部署工具,不仅可以实现模型的自动部署,而且用户还能将模型一键转换至不同计算平台,大幅简化了模型从训练到部署的流程。
如此一来,就可以高效地实现自动化、零代码算法生产,降低行业算法生产的技术门槛以及生产成本,大幅提升生产效率。
今年是旷视成立第十一个年头,也是MegTech举办的第二年。
在旷视技术开放日上,CEO印奇对旷视这十一年来核心主旋律做了总结,那便是AIoT。
他认为,AIoT=AI+IoT+空间。这个朴实无华的等式是当前AIoT产业创新的新范式。
若想让AI能够真正规模化落地到场景中,就需要一个硬件载体,即IoT设备。
所以,AI和IoT两者相辅相成,又是核心相关的词。如果AI是大脑,IoT就是躯壳和真正的骨干。
当前,AR/VR技术不断演进,大大提升了虚拟世界的沉浸感。然而,当人们跳脱出那个「元宇宙」的世界,就会发现现实世界并没有什么不一样。
怎样让「产业互联网」能够在物理世界中定义场景和定义应用才是最重要。
一直以来,AIoT是旷视长期的业务战略方向和商业战略方向。
从2015年开始,旷视就提出AIoT是AI的产业化路径。
目前,旷视在消费物联网、城市物联网和供应链物联网三大场景,都形成了软硬一体化产品和解决方案的能力。
那么,旷视AIoT战略靠什么核心技术能力来支撑呢?
可以总结为「2+1」数学公式,即(基础科研+算法量产)+算法定义硬件。
2022年,视觉AI基础研究呈现出「大」和「统一」的新趋势。
「大」是指AI大模型。通过利用大数据、大算力和大参数量,提高模型的表达能力,让AI模型能够适用多种任务、多种数据和多种应用场景。
然而,模型越大不一定代表其性能越好,同时大模型还需要消耗更多的算力。
因此,研究不仅需要往「大」的方向努力,更重要的是将大模型的优势发挥出来。目前,旷视分别在大模型、大算法、大应用这三方面做了许多研究。
除了「大」,近2年,旷视研究人员还发现许多算法在底层正在走向统一。
通过使用统一的算法、模型来表示和建模各种数据、各种任务,我们将可以得到简单、强大且通用的系统。
基于以上「大」和「统一」这两大观点,旷视在通用大模型方面,提出了一种基于大Kernel的CNN和MLP设计范式。
在自动驾驶感知大模型方面,刚刚提到的BEVDepth,以及关于激光雷达感知神经网络架构LargeKernel3D Network都是旷视取得最新成果。
回顾旷视的算法生产的过程,经历了从点到线到面演进的过程。在MegTech 2021上,旷视曾展示了其算法量产星空图。
通过总结旷视这十年多的经验,旷视认为算法生产的主要困难集中在整个生产环节的复杂性上。具体来说:数据生产的复杂性、算法模型本身的不确定性、硬件平台多样性。
因此,需要将算法生产过程标准化就能够真正有效地解决这样一个复杂的、碎片化的算法生产所面临挑战的手段。
就比如刚刚提到旷视自研的算法生产平台AIS,让标准化成为生产流程中的核心优势。
要知道,算法量产并不是一个单一的产品,而是对旷视整个AI生产模式理念的革新和生产力的进化。
旷视将,通过AI生产的标准化以及AI生产力平台,极大地降低算法生产成本和门槛,让更多的人可以参与到算法生产过程中来,从而促进算法在更多行业里的落地。
要知道,AIoT是由AI和IoT结合在一起的。在IoT的范畴之下,主要提到的核心理念就叫AI传感器。
随着AI、视觉算法等领域的发展,传感器将不再单独直接地提供应用价值,这两者之间需要算法来作为承上启下的「桥梁」。
直白讲,不是需要用到哪去做一个传感器,而是通过算法让这个传感器实现需要的应用。
随着应用的不断改变与升级,传感器对算法提出了越来越多的需求,反之算法也对传感器到底需要提供什么样的信息和输入提出了要求,甚至本质性地改造了传感器的形态以及样式。
过去,我们拍照必须选择一个光源好的地方,而现在,算法和智能手机结合让我们也能实现夜晚拍照的效果。
这里,就不得不提旷视定义了一个「AI画质」影像技术的概念。
在1080P规格上,旷视「AI画质」方案已经用通过多种形态软件得到了应用。对于4K以上级别的,其专业硬件方案已经在一个甚至多个行业内实现了客户维度上的量产。
今年,旷视公布了AI定义传感器的这条路的两个新技术愿景。
在画质的维度上,要走向16K AI极高清的AI画质这一概念。希望通过AI、传感和显示这三者一起联动,实现真正身临其境的影像体验。
另外,从IoT角度来讲,传感器将将走向更加极致的小型化、低功耗,从而能够和每个人的日常生活,和每个人自身实现更加深度的结合。
印奇对旷视「2+1」的AIoT核心技术科研体系总结道:
AI一定是旷视一直坚持的核心能力,而IoT是核心载体,即以「基础算法科研」和「规模算法量产」为两大核心的AI技术体系,和以「计算摄影学」为核心的「算法定义硬件」IoT技术体系(包括AI传感器和AI机器人)。
这个「2+1」的AIoT科研战略是旷视坚定走「软硬结合」道路的有力技术支撑,是支撑旷视未来不断走向新的AIoT商业成功的最重要的基石。
一是拥有从软到硬的全栈能力,其开发的Brain++平台,包括了自研的深度学习框架MegEngine,覆盖从AI模型生产到应用各环节。
二是基础科研有真正的突破,在通用图像大模型、视频理解大模型、计算摄影大模型以及自动驾驶感知大模型取得了不错的成果。
三是技术和产品走的很近,比如AIS算法平台已经产品化SAAS服务,计算摄影千万级传感器等。
面向未来,旷视期待通过AI和IoT结合,让物理世界变得更加美好。
![]()