近日,欧洲计算机视觉国际会议 ECCV 2022(European Conference on Computer Vision)发布了论文录用结果。本届 ECCV 2022论文有效投稿数5803篇,其中1650篇论文中选,录取率仅为28%。
ECCV是国际顶尖的计算机视觉会议之一,每两年举行一次。今年将在10月23日-27日于以色列特拉维夫(Tel-Aviv)举行,并采取线下和线上混合形式召开。
今年,旷视共有20篇论文入选,其中3篇 oral,内容涵盖目标检测、3D重建、图像复原等多个研究方向。以下是论文亮点解读,enjoy~
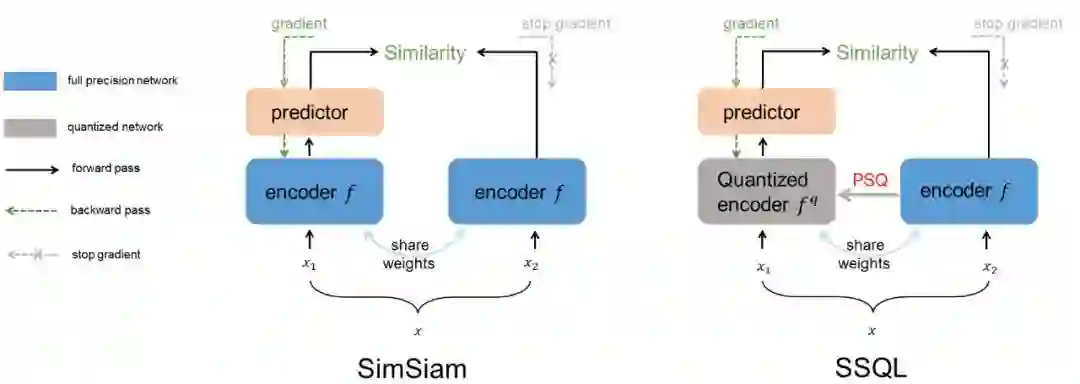
01 Oral:Synergistic Self-Supervised and Quantization Learning
自监督学习与量化协同互助
关键词:self-supervised learning, quantization, pretrained, once-for-all
自监督学习由于可以避免对大量数据标注的需求,已成为当前学界和工业界的关注重点。但将当前的自监督模型经由低比特量化实现部署时,发现模型精度出现严重下降, 限制它们在资源受限场景下的应用。为改善该现象, 论文中提出一种自监督学习和量化协同互助的方法(SSQL)来赋予自监督预训练模型量化友好的性质。SSQL 不仅在量化到不同比特时能显著改善模型精度,同时在多数实验中浮点模型原始精度也得到了进一步提升。SSQL只需要训练一次且不需要引入额外的模型参数就可以实现模型具备量化到不同位宽的能力。
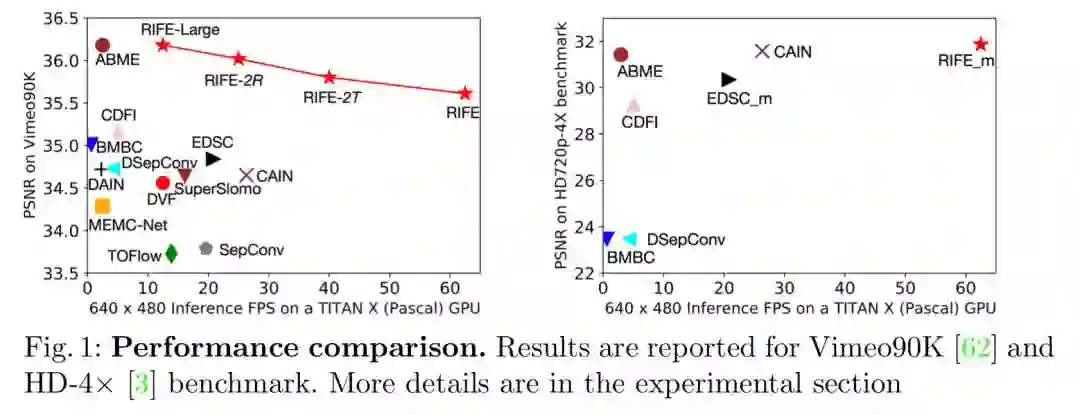
02 Real-Time Intermediate Flow Estimation for Video Frame Interpolation
视频插帧中的实时中间流估计
视频插帧算法被广泛用于视频处理、多媒体播放器和显示设备上。本文提出了一种基于实时中间流估计的视频插帧算法 RIFE,包括一个端到端的高效的中间流估计网络 IFNet ,以及基于特权蒸馏的光流监督框架。RIFE 支持在两帧之间的任意时刻点插帧,在多个数据集上达到了最先进的性能且不依赖于任何的预训练模型。相比目前流行的 SuperSlomo 和 DAIN 技术,RIFE 实现了 4 至 27 倍的加速且取得更好的视觉效果。通过调制 IFNet 的时间编码输入,RIFE 还能支持包括动态场景图像拼接等应用。RIFE 相关代码已开源:
https://github.com/megvii-research/ECCV2022-RIFE,并被 Flowframes,SVFI,SVP 等视频处理软件应用。
RIFE 在处理速度上具有显著优势,如下图,横轴是每秒能处理的视频帧数,纵轴是质量指标。
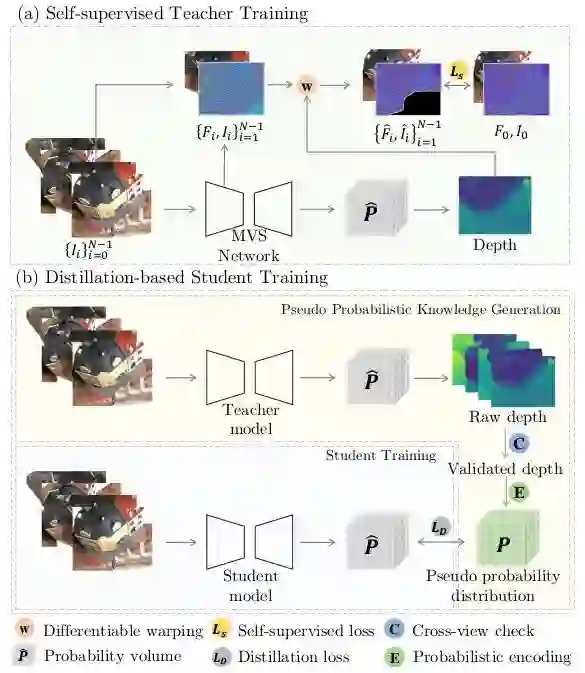
03 KD-MVS: Knowledge Distillation Based Self-supervised Learning for Multi-view Stereo
KD-MVS: 基于知识蒸馏的自监督多视图立体网络训练方法
关键词:MVS,自监督学习,知识蒸馏MVS,自监督学习,知识蒸馏
自监督多视图立体重建方法在重建质量方面取得了显著进展,但面临着收集大规模真实深度标签的挑战。在本文中,我们提出了一种新的基于知识蒸馏的 MVS 自监督训练方法,称为 KD-MVS ,主要包括自监督教师训练和基于蒸馏的学生训练。具体来说,教师模型使用光度和特征度量的一致性以自监督的方式进行训练。然后通过概率知识转移将教师模型中的知识蒸馏到学生模型中。在验证知识的监督下,学生模型能够大大优于教师。在多个数据集上进行的大量实验表明,我们的方法甚至可以优于监督方法。
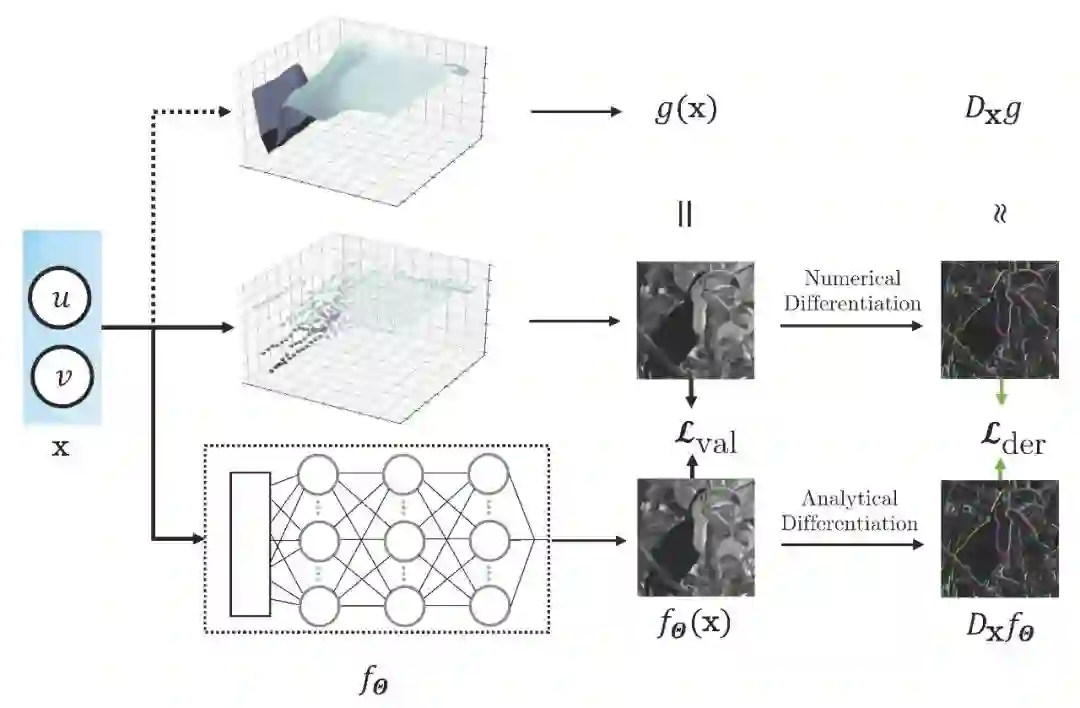
04 Sobolev Training for Implicit Neural Representations with Approximated Image Derivatives
基于近似图像梯度的隐式神经表达的索伯列夫训练
近几年来,用神经网络进行参数化的隐式神经表达 (INRs) 成为一种有效的信号表示方式,相对于传统离散化的信号表示方式,隐式神经表达具有连续、可微分的性质。然而,目前隐式神经表达的训练范式均是基于“输入坐标-信号值”,并没有利用信号导数值,导致隐式神经表达的泛化能力较差。本文提出了一种基于“输入信号-信号值-信号导数值”的训练范式,能够将信号的值和导数值均编码进网络权重中。本文在图像回归和逆向渲染两个任务上应用了该训练范式,结果表明该训练范式能够有效提高隐式神经表达的数据有效性和泛化能力。
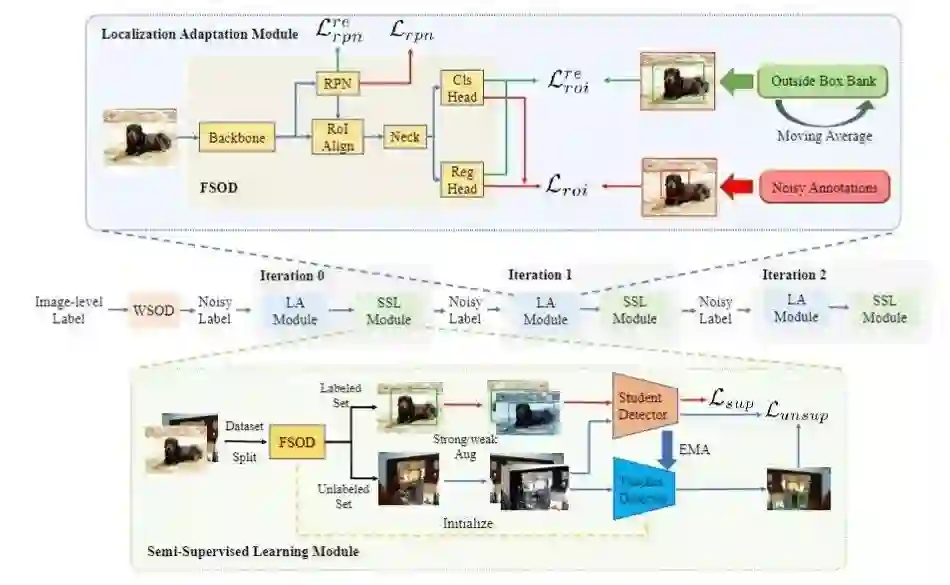
05 W2N: Switching From Weak Supervision to Noisy Supervision for Object Detection
W2N: 一种将弱监督信号转化为噪声监督信号的目标检测方法
弱监督物体检测任务(WSOD)旨在仅利用图像级别的类别标签来训练一个检测器。几年来,一些弱监督检测方法试图从原始的 WSOD 模型中挑选高质量的伪标注来提升模型性能。然而,这些方法仅仅根据图片级的线索,简单的将带有伪标注的训练集数据集划分为有标签集和无标签集,而忽略了每一个检测框的分类信息和定位信息,因此信息没有得到充分利用。在本工作中,我们提出将弱监督信号转化为带噪监督信号的目标检测算法(W2N),该算法包含两个迭代训练的子模块。我们的算法充分考虑了每一个检测框具有的信息,并提出了一个正则化损失来缓解WSOD会集中注意到"discriminative part"的问题。实验结果显示,我们的方法在 PASCAL VOC, COCO 等数据集上都达到了 SOTA 。
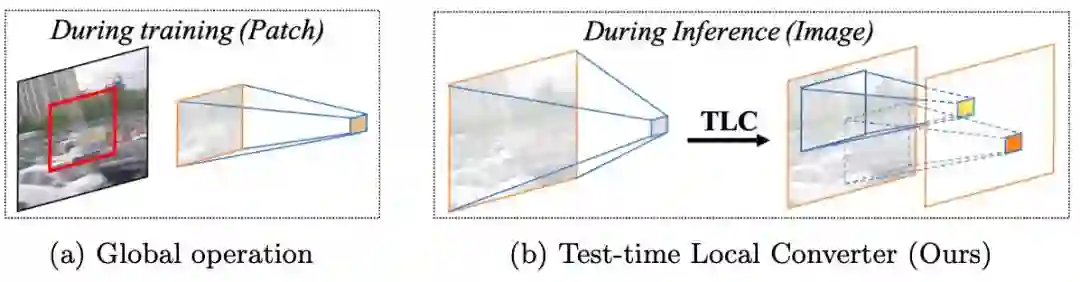
06 Improving Image Restoration by Revisiting Global Information Aggregation
通过重新审视全局信息聚合来改善图像修复效果
关键词:图像复原、全局信息聚合、训练与测试不一致性
本文揭示了图像复原任务中全局操作的训练-测试不一致现象:训练时基于裁切图像的全局信息分布和推理时基于全图的全局信息的分布并不一致。为了缓解不一致性对性能的负面影响,本文提出了测试时局部转换器:在模型推理时将操作的信息聚合范围从全局(整个空间维度)转换为局部窗口。该方法无需任何微调,可以直接应用于已有模型并提升其在多种图像恢复任务上的性能。例如,该方法将 Restormer 在 GoPro 图像去模糊数据集的 PSNR 从 32.92dB 提高到 33.57dB 。代码已开源:
https://github.com/megvii-research/TLC。
07 Simple Baselines for Image Restoration
图像复原的简单基线
本文揭示了使用简单的模型结构也能达到图像复原多个任务的世界领先性能:很多复杂的设计可能不是必须的。与此同时,本文揭示了甚至连传统的激活函数(ReLU, GELU, Sigmoid 等等)都是非必须的——可以直接由点乘操作代替。在计算复杂度只有之前最佳方法 8.4% (去模糊任务)和 47%(去噪任务)的情况下,在 PSNR 指标上分别超越之前最佳方法 0.38 dB / 0.28 dB。代码已开源:
https://github.com/megvii-research/NAFNet。
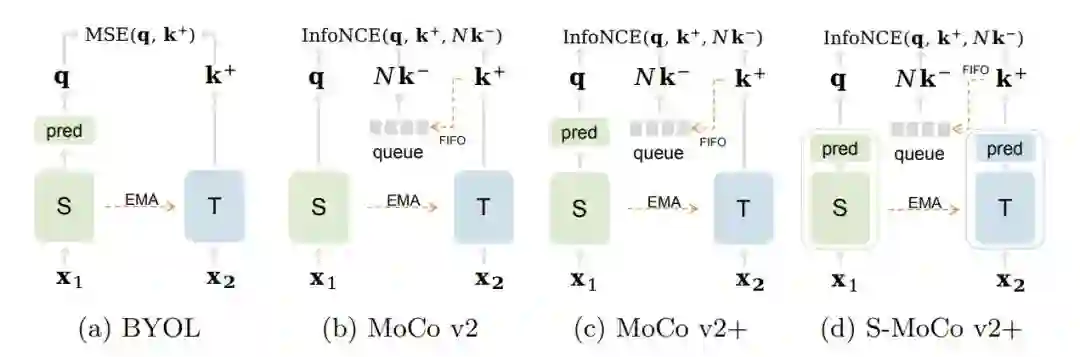
08 Revisiting the Critical Factors of Augmentation-Invariant Representation Learning
重新探索基于增广不变特征学习框架中的关键因素
本文探索了自监督领域基于增广不变特征学习框架中的关键因素。我们建立了 MoCo 和 BYOL 公平对比的 benchmark ,详细研究了预训练模型设计的关键因素对模型在上游和下游任务上的性能影响,主要有以下几个结论:更复杂的模型设计可以提高上游任务的性能,但 linear evaluation 对下游性能没有指示性;在上下游使用不匹配的训练器会影响下游任务的性能。由此,我们提出了简单有效的 NormRescale 来解决这个问题;BYOL 的非对称设计移植到 MoCo 上能够提高上游结果,但会影响下游长尾分类任务的性能。我们希望这项研究能为自监督模型设计带来启发。
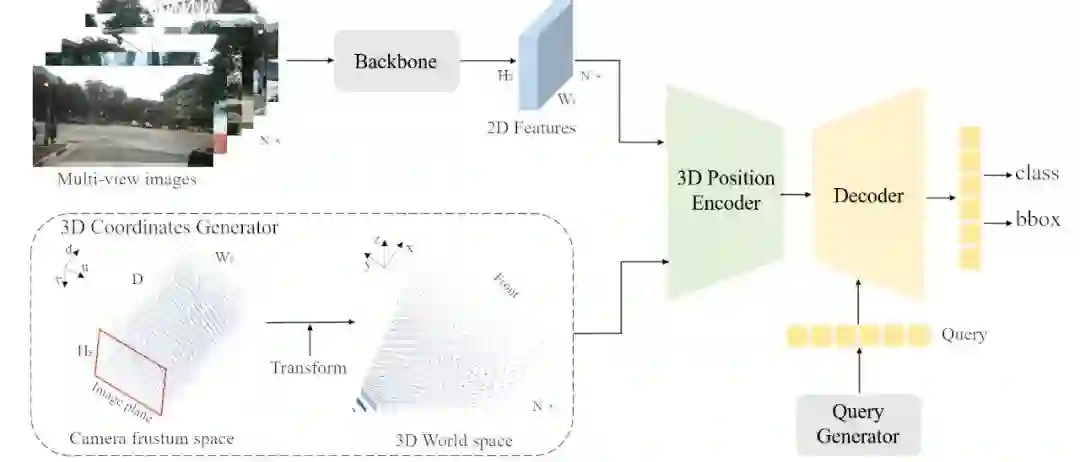
09 PETR: Position Embedding Transformation for Multi-View 3D Object Detection
基于3D位置编码的多视角3D目标检测
关键词:3D位置编码,Transformer,多视角,3D目标检测
在自动驾驶中,如何基于环视相机进行纯视觉 3D 目标检测是一项大的挑战。目前的方法可以分为把多视角 2D 图像特征投影到 3D 空间和从 3D 空间向 2D 特征上采集特征两种思路,这两类方法均不可避免的会涉及到特征的空间转换,不利于实际应用部署。在这篇文章中,我们提出了 3D 位置编码的概念,将相机成像时的视锥空间转换成 3D 位置编码,与 2D 特征直接相加得到 3D 位置相关的特征。得益于上述转换,只需一个 Transformer 解码器便可简单高效地完成 3D 检测任务,端到端地得到 3D 空间下的检测结果。PETR 在 Nuscenes 数据集上取得了 44.1% mAP 和 50.4% NDS 的优异表现,成为领域内第一个在 NDS 指标上达到 50%+ 的纯视觉方法,相关代码已开源在:
https://github.com/megvii-research/PETR。
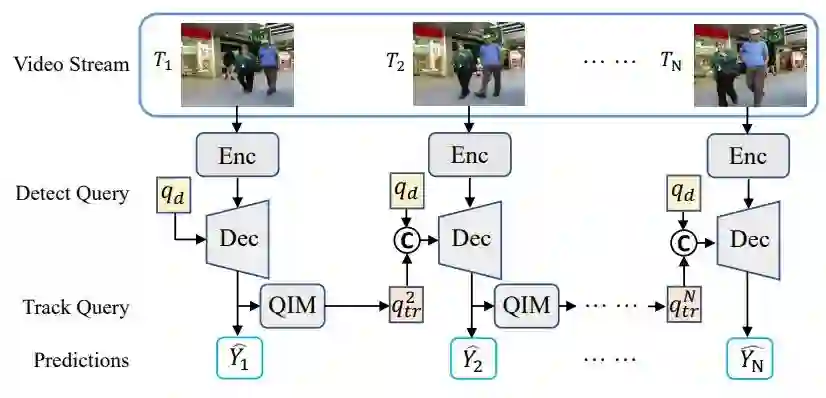
10 MOTR: End-to-End Multiple-Object Tracking with TRansformer
基于Transformer的端到端多目标追踪框架
关键词:多目标追踪、端到端、Transformer
在多目标追踪中,对目标进行时序建模是一个关键性挑战。已有方法往往利用物体运动、外观的先验对目标进行追踪,而利用这些先验所进行的后处理,阻碍了对视频序列中时序的端到端探索。在本文中,我们提出了多目标追踪框架 MOTR ,其扩展于 2D 检测框架 DETR ,并引入追踪向量的概念,实现对所追踪目标的建模。追踪向量随着时间的进行,会被逐帧更新并用于迭代式的预测。我们提出了追踪敏感的标签分配策略对追踪目标、新生目标的训练,同时提出了时序聚合网络、群体平均损失函数,强化对时序的建模。在 DanceTrack 数据集上,MOTR 在 HOTA 指标上显著优于此前的 SOTA 方法 ByteTrack ,优势达到 6.5% 。而在 MOT17 数据集上,MOTR 在连接性能方面超过了同期的 TransTrack、TrackFormer 等基于 Transformer 的方法。MOTR 可以作为一个面向时序建模、基于 Transformer 类研究的强大基线。代码已开源在
https://github.com/megvii-research/MOTR。
11 Oral:Tracking Objects as Pixel-wise Distributions
像素级别的多目标跟踪方案
关键词:多目标追踪、像素级别追踪、Transformer
多对象跟踪 (MOT) 需要通过帧检测和关联对象来实现,这与通过检测到的边界框进行跟踪,或将对象作为点进行跟踪这两种方法有所不同,我们建议将对象跟踪作为像素分布。经过在基于转换器的架构 P3AFormer 上实例化这个想法后,结果表现出具有像素级传播、预测和关联。P3AFormer 传播具有流信息引导的像素级特征,并在帧之间传递消息。此外,P3AFormer 采用元架构来生成多尺度对象特征图。在推理过程中,我们还提出了一种逐像素关联过程,以基于逐像素预测通过帧恢复对象连接。在 MOT17 基准测试中,P3AFormer 的 MOTA 为 81.2%——值得一提的是,这是目前文献中所有变压器网络中第一个达到 80% MOTA。同时,P3AFormer 在 MOT20 和 KITTI 基准上的表现也优于最先进的技术。
12 Explaining Deepfake Detection by Analysing Image Matching
基于图像匹配解释深伪检测模型
我们提出了一种方法来解释深伪检测模型是如何在没有 Artifact 细粒度标签的情况下,仅借助二分类监督信息,就可以取得极高伪造图像检出率的原因。通过对深伪检测模型的深入分析,本文提出并验证了以下三条假设:
-
① 深伪检测模型将伪造图像中同源图像和目标图像特征无关的图像区域判定为 Artifact 区域;
-
② 深伪检测模型在训练中同时借助二分类标签及数据中的图像匹配关系,隐式建模 Artifact 特征;
-
③ 深伪检测模型隐式建模的 Artifact 特征容易受到图像质量影响,导致模型压缩鲁棒性不足。
进而,基于上述理解,我们提出了一个轻量级的基于图像匹配的深伪检测模型,大量实验证明我们的模型在面对强压缩数据时,仍然能够保持很好的性能。
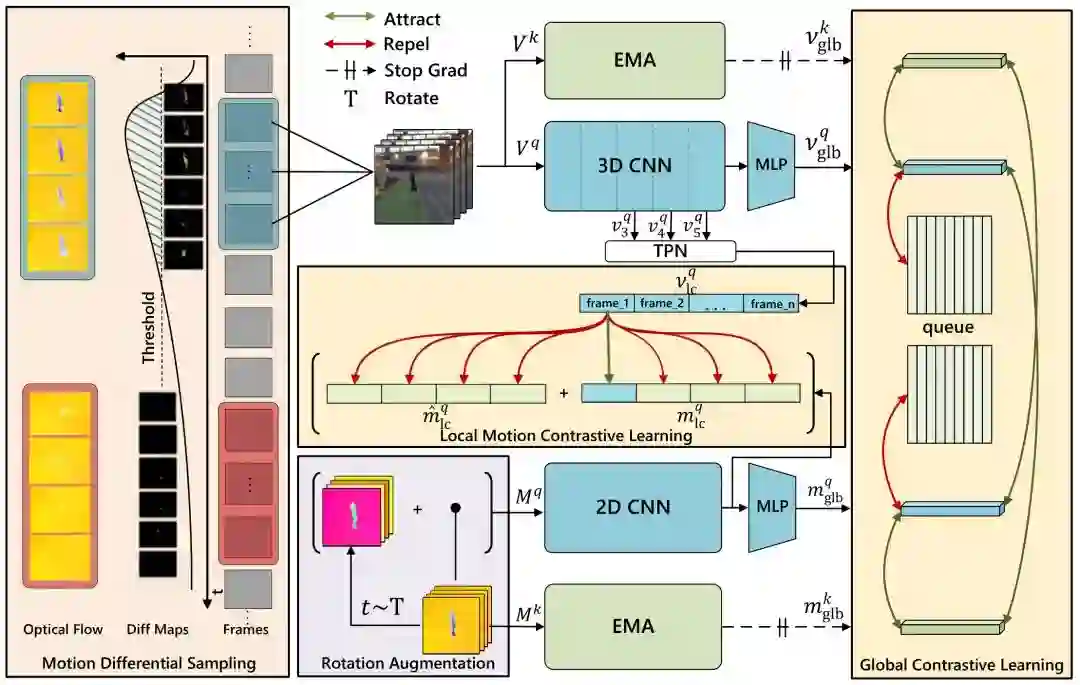
13 Motion Sensitive Contrastive Learning for Self-supervised Video Representation
用于自监督视频表示的运动敏感对比学习
自监督学习在视频表征学习中表现出了很大的潜力,其中短程的局部动态特征学习对于后续下游任务有至关重要的意义,然而现有方法对于提取这类信息没有充分的讨论。我们在本论文中提出了运动敏感对比学习 (MSCL) 来将运动信息从光流结果引入到 RGB 图像中。为此,在视频片段的对比学习之外,我们提出了局部动态对比学习 (LMCL) 来提取两种模态之间的帧级信息。同时,我们引入了光流旋转增强方法来产生额外的负样本,利用动态差分采样来寻找难样本对。我们的实验结果是,3D ResNet-18 在 UCF101 上达到了 91.5% 和在 Something-Something v2 上达到了 50.3% 的分类准确率,在 UCF101 上达到了 65.6% 的视频检索准确率。
14 Efficient One Pass Self-distillation with Zipf's Label Smoothing
基于Zipf分布实现标签平滑的高效一阶段自蒸馏方法
关键词:知识蒸馏,自蒸馏,标签平滑,图像分类,zipf分布
自蒸馏类方法具备在推理阶段不增加额外开销的优势,然而在大模型时代减少训练阶段时间和内存消耗十分重要。本文提出一种高效自蒸馏方法,不依赖样本之间的对比或者额外的参数开销,仅使用模型自身训练过程的输出产生软标签来起到知识传递和正则化作用。本文想法来自于一个观察:训练完成的神经网络输出经过排序和在样本集取平均,遵从 Zip 分布。通过把这个性质应用在网络训练过程中,ImageNet 准确率提升了 0.88% ,INAT21 准确率提升了 3.61% 。
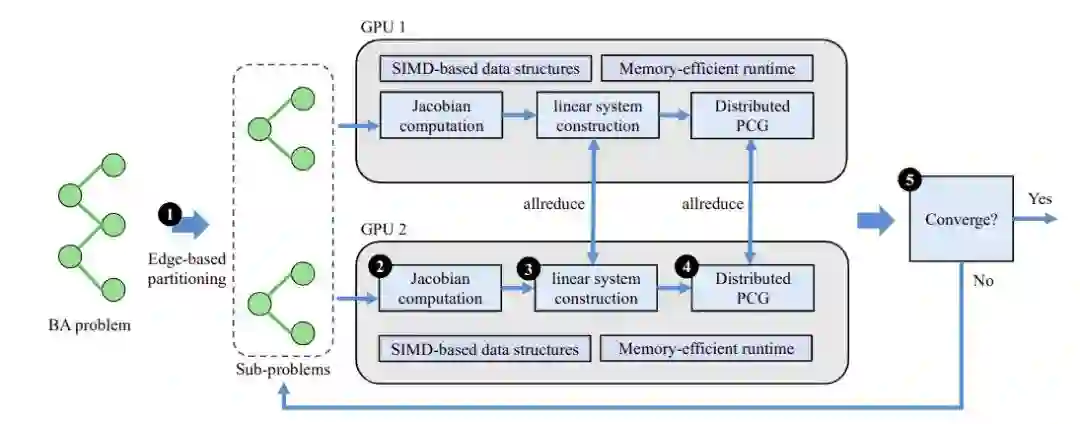
15 MegBA: A GPU-based Distributed Library for Large-Scale Bundle Adjustment
MegBA: 用于求解大规模Bundle Adjustment的GPU实现的分布式库
关键词:Bundle Adjustment, SfM
Bundle Adjustment 是现代 SLAM 以及 SfM 应用中极为重要的算法,它通常会计算三角化得到的坐标估计数据重新投影到相机成像平面并计算与真实拍摄的像素坐标之间的误差,用此误差优化估计坐标和相机位姿。Bundle Adjustment 的优化过程极为耗时,且通常会消耗大量内存,本文使用 GPU 对整个 Bundle Adjustment 过程加速,同时提出了一个新的分布式策略,可以将问题自动拆分到若干 GPU 中以便于将巨大的内存开销分摊到若干 GPU 中,且与已有的分布式策略相比我们的策略不会做任何近似。在 BAL 数据集上,MegBA 相比 CPU 库取得高达 60 倍的加速,相比 GPU 库取得高达 6 倍的加速,同时 MegBA 还能处理十亿条边以上的超大规模数据,而现有的 CPU 和 GPU 框架在此规模上均会崩溃。
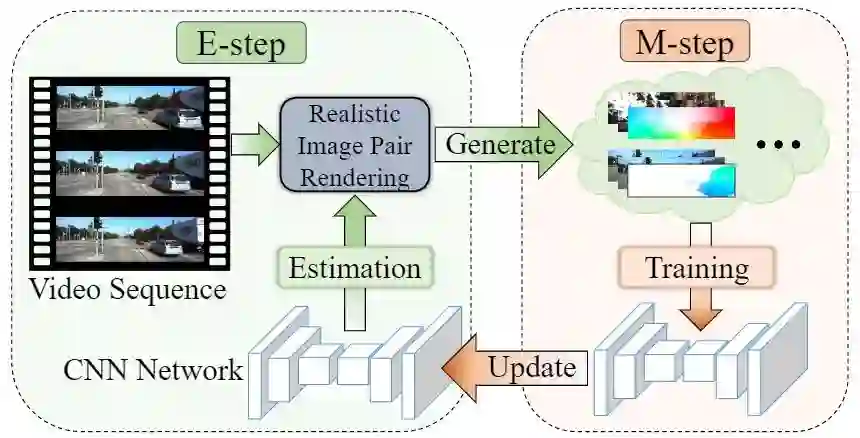
16 Oral:RealFlow: EM-based Realistic Optical Flow Datasets Generation from Videos
真实流: 基于EM算法从视频中生成真实光流数据集
从视频中获取光流标注是非常困难且昂贵的。现有光流估计模型通常使用渲染数据集进行训练,导致其在真实世界应用中的性能较差。本文提出一种基于 EM 算法的框架从任意的真实视频中直接生成光流训练数据集。我们首先从视频序列中的参考帧和目标帧中估计一个光流,然后基于此生成一张新的图片以替换目标帧,从而构成一个训练数据对。我们提出了一个 RIPR 模块来解决图像生成过程中的伪影和空洞填充问题,使得生成的图像更加真实。进一步地,我们提出使用 EM 算法对生成的数据和光流估计网络进行迭代优化。在 E-step 中,我们使用光流估计网络生成训练数据集;在 M-step 中,我们使用生成的数据集对光流网络进行训练。通过多次迭代,生成数据集和光流估计网络能够得到同时优化。实验证明,本文的方法比现有的数据集生成方法效果更好。同时,我们在和强监督、无监督算法的对比中都达到了领先水平
。
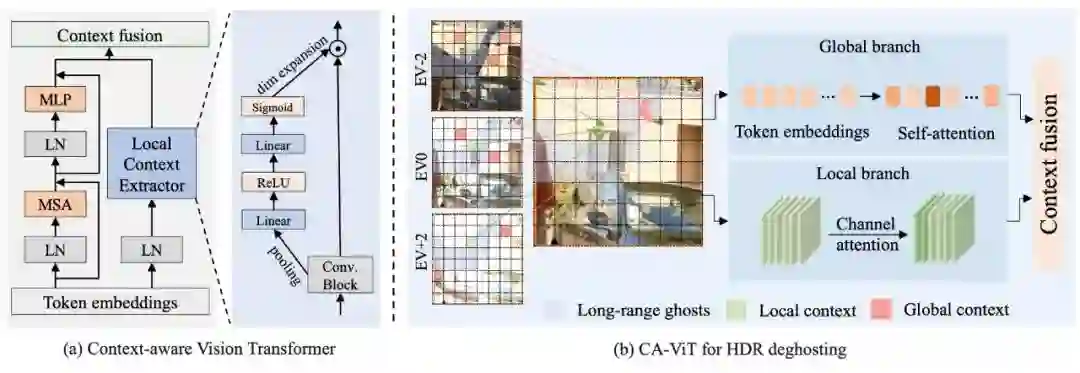
17 Ghost-free High Dynamic Range Imaging with Context-aware Transformer
基于上下文感知Transformer的无鬼影高动态范围成像方法
关键词:High Dynamic Range (HDR) Imaging,HDR Deghosting
受限于卷积操作的感受野,已有基于 CNN 的多曝光 HDR 成像算法容易在具有大前景运动和严重过曝的场景下产生运动鬼影和强度失真。为了同时建模长距离的前景运动鬼影和局部的多帧融合,本文对原始 Transformer 进行改进,提出一种基于上下文感知的双分支 Transformer (CA-ViT),能够同时建模全局和局部图像上下文信息。更进一步地,本文将所提出的 CA-ViT 作为基础组件,提出首个基于 Transformer 的 HDR 去鬼影模型 HDR-Transformer 。在多个公开数据集上的试验结果证明,本文的方法能够更有效地去除鬼影,恢复图像质量更好的 HDR 结果。
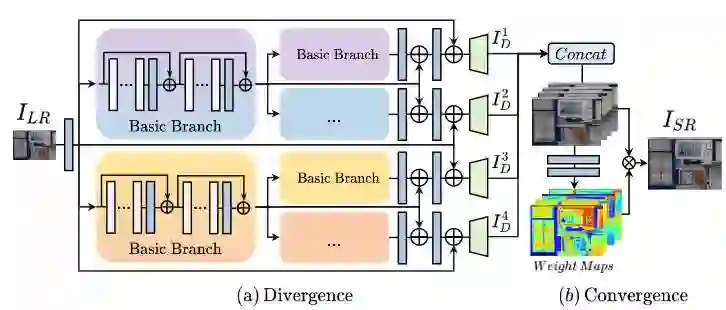
18 D2C-SR: A Divergence to Convergence Approach for Real-World Image Super-Resolution
D2C-SR:一种针对真实世界超分辨率的发散到收敛方法
关键词:Real-world Super-Resolution
作为不适定问题,超分辨率任务的挑战是对于一个给定的低分辨率输入可以有多种预测。一些经典的基于深度学习的方法缺乏对底层高频分布的明确建模,导致结果模糊不清。我们提出先发散再收敛的 D2C 结构,以离散的形式学习底层高频细节的分布。在发散阶段,我们提出了一个基于树状结构的深度网络;在收敛阶段,我们分配空间权重来融合这些发散的预测结果。我们在真实世界的超分辨率数据集进行了评估,包括一个新提出的具有 8 倍缩放系数的数据集。我们的实验表明,D2C-SR 具有更高的评价指标,而参数数量明显减少。
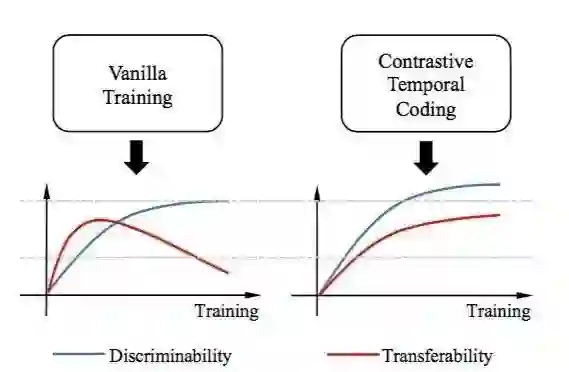
19 Discriminability-Transferability Trade-Off: An Information-Theoretic Perspective
以信息论的视角分析可判别性与可迁移性的权衡
本文主要研究图像分类任务特征的两种重要性质:可判别性与可迁移性。首先,我们对于这两种特征的性质进行了时序上的分析,并且发现了两种性质之间是存在 trade-off 的。具体地说,我们发现可判别性会随着训练不断提升,但是在训练后期,可迁移性会显著降低。我们从信息瓶颈的视角解释了这一 trade-off ,并且发现了输入信息的“过度压缩”问题。基于信息论的解释,我们进而提出了一种学习方法“时序对比学习”,去缓解“过度压缩”问题。
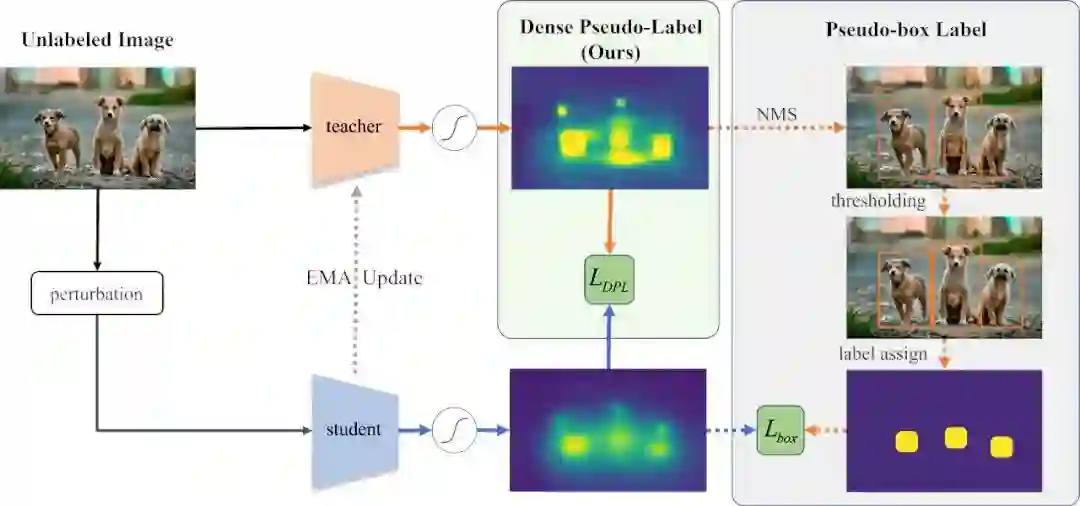
20 Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection
密集学习:用于半监督学习的密集伪标签
本文提出一种适用于一阶段检测器的半监督学习方法。不同于现有的基于目标框的伪标签,本文提出了一种全新的密集标签,在简化了现有半监督模型的基础上,实现了更高效的半监督学习。在 COCO 数据集上,使用 ResNet50 的 FCOS 检测器达到了 46.1% mAP。
公众号后台回复“ECCV2022”获取论文分类资源下载~