【EMNLP2018最佳论文出炉】Google语义角色标注&Facebook无监督机器翻译分别斩获
声明:本文转载自公众号 专知
【导读】EMNLP是自然语言处理领域顶级国际会议,每年吸引世界各国近千名学者交流自然语言处理发展前沿。2018年度EMNLP大会将于10月31日-11月4日在比利时布鲁塞尔举办。今天EMNLP 2018公布了两篇最佳长论文和一篇最佳资源论文。

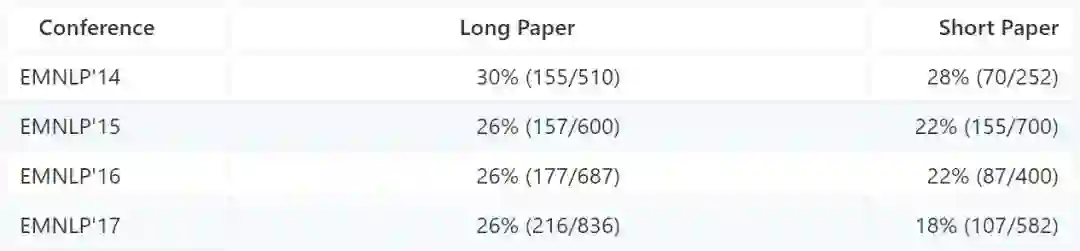
EMNLP是自然语言处理领域顶级国际会议,每年吸引世界各国近千名学者交流自然语言处理发展前沿,前几年长文的录用率只有26%左右:
今天EMNLP在官方Twitter上公布了两篇Best Paper:

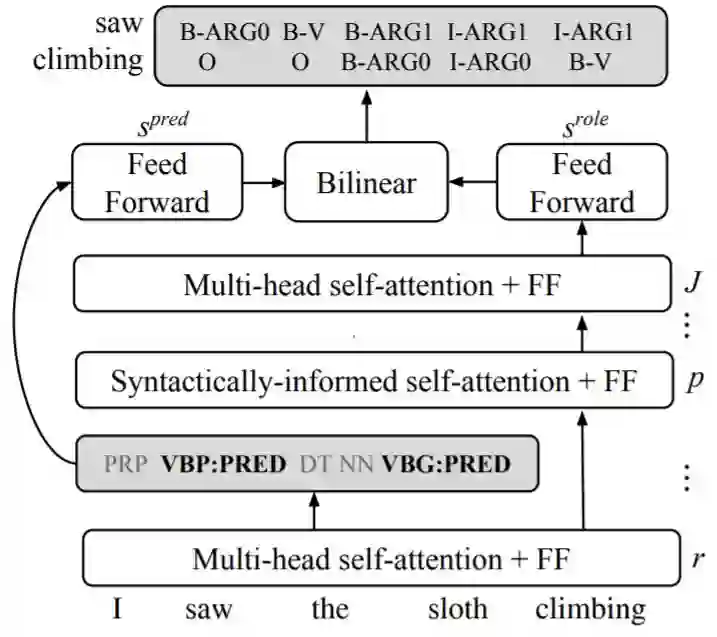
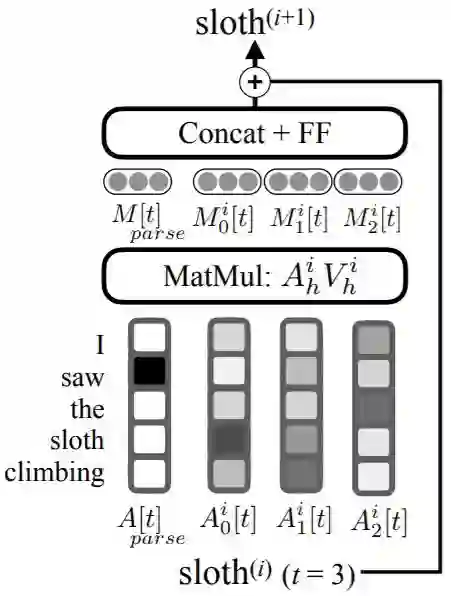
Best long paper 1/2: 谷歌-语言信息融入自注意力的语义角色标注

论文地址:
http://www.zhuanzhi.ai/paper/87964e6ae3d40f170d2934d9cca009af
摘要:当前最先进的语义角色标记(SRL)使用深度神经网络而没有明确的语言特征。但是,之前的工作表明,语法树可以显着改善SRL解码,这表明通过显式语法建模可以提高准确性。在这项工作中,我们提出了基于语言学的self-attention(LISA):一种神经网络模型,它将multi-head self-attention与多任务学习相结合,包括依赖解析,词性标注,谓词检测和语义角色标记。与先前需要大量预处理来准备语言特征的模型不同,LISA可以仅使用原始的token,对序列进行一次编码,来同时执行多个预测任务。语法信息被用来训练一个attention head来关注每个token语法上的父节点。如果已经有高质量的语法分析,则可以在测试时进行有益的注入,而无需重新训练我们的SRL模型。在CoNLL-2005 SRL数据集上,LISA在谓词预测、word embedding任务上比当前最好的算法在F1值上高出了2.5(新闻专线数据)和3.5以上(其他领域数据),减少了约10%的错误。在ConLL-2012英文角色标记任务上,我们的方法也获得了2.5 F1值得提升。LISA同时也比当前最好的基于上下文的词表示学习方法(ELMo)高出了1.0的F1(新闻专线数据)和多于2.0的F1(其他领域数据)。
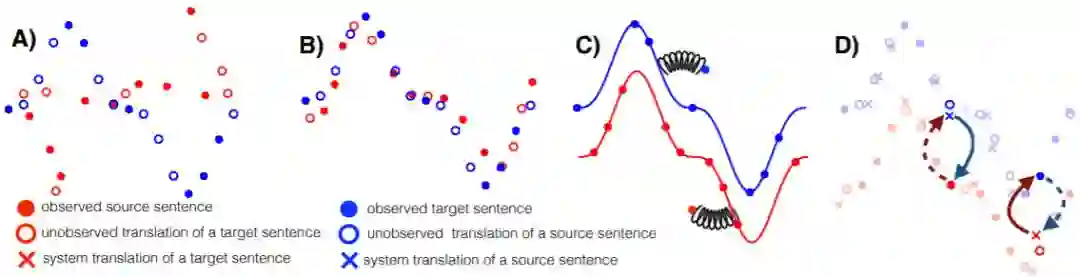
Best long paper 2/2: Facebook 基于短语无监督神经机器翻译

论文地址:
http://www.zhuanzhi.ai/paper/484ce1c1064cd372ba6e9eec459d2e0f
博客介绍:
https://code.fb.com/ai-research/unsupervised-machine-translation-a-novel-approach-to-provide-fast-accurate-translations-for-more-languages/
代码:
https://github.com/facebookresearch/UnsupervisedMT
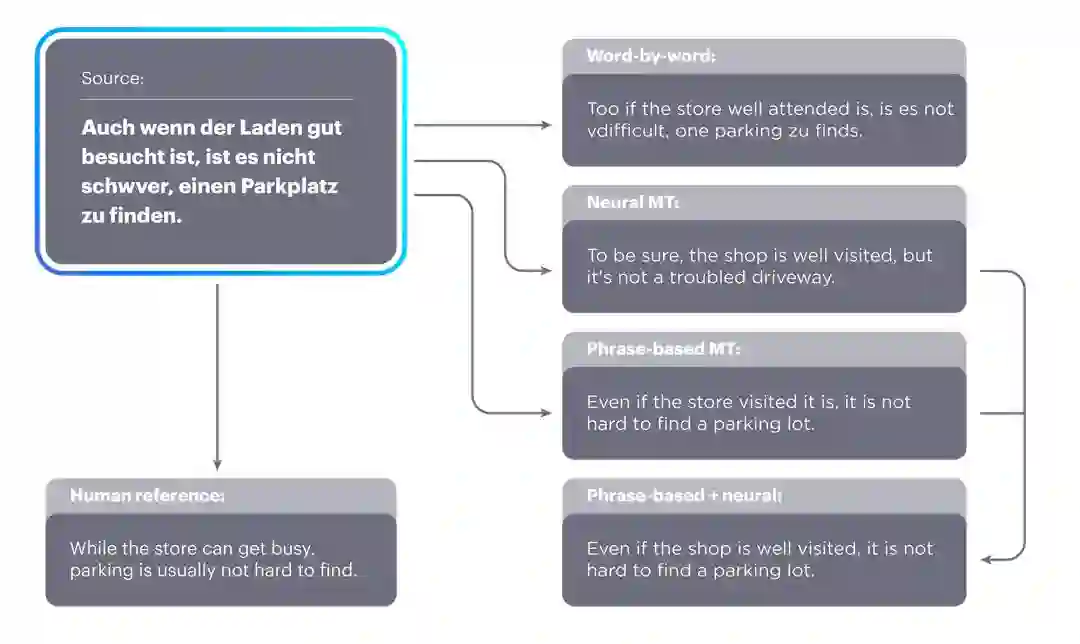
摘要:机器翻译系统在某些语言上实现了接近人类的能力,但它的性能依赖于大量的平行双语语料,这降低了机器翻译的适用性。本研究探讨了如何在只有大规模单语种语料库的情况下进行机器翻译。 我们提出了两个模型(变式),一个基于神经网络和一个基于短语的模型。两个模型都使用了精心设计的参数初始化、语言模型的降噪和基于迭代反向翻译的并行预料生成。这些模型优于引用文献中的方法,而且更简单、具有更少的超参数。在广泛使用的WMT'14 English - French 和 WMT'16German - English基准测试中,我们的模型分别获得了28.1和25.2 BLEU点(在不使用平行预料的情况下),比当前最好的方法高出了11个BLEU点。在资源较少的语言如English-Urdu何English-Romanian中,我们的方法甚至比利用短缺的bitexts的半监督和监督方法要好。我们的NMT和PBSMT代码现在已经公开了。
Best Resource Paper: 任务对话建模数据集
MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan and Milica Gasic
参考资料:
https://github.com/lixin4ever/Conference-Acceptance-Rate
本期责任编辑:赵森栋
本期编辑:蔡碧波
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




