CVPR 2022 | 新标注形式!国科大提出CPL:只标一个粗点的多类别多尺度目标定位任务

极市导读
标注为什么要那么多条条框框?研究人员随便标!最新被CVPR 2022收录的一篇论文中,提供了一种粗点优化的新思路,将多类别多尺度定位问题从精确的点标注泛化到任意的粗点标注,第一次从算法角度减轻语义差异。>>加入极市CV技术交流群,走在计算机视觉的最前沿
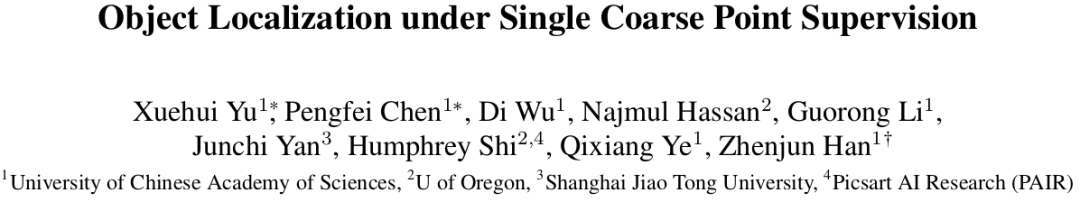

图1:CPR的可视化,根据标注点(绿)采样点,通过实例级别MIL选出语义点(红),并平均权重以得到语义中心点(黄)作为最终改善点。
基于点的目标定位(Point-based object localization,POL)任务,在低成本数据标注下追求高性能的物体感知,越来越受到关注。然而,点标注模式不可避免地会因为标注点的不一致而引入语义方差。现有的POL方法严重依赖于难以定义的精准关键点标注。
本文提出了一种使用粗点标注的 POL 方法,将监督信息从准确的关键点放松到自由标注的点。并为此提出了一种粗点细化(CPR)方法,这是第一个用算法缓解语义方差的方法。
具体来说,CPR构造点包,通过多实例学习(MIL)选出与语义相关点,并产生语义中心点。通过这种方式,CPR 定义了一个弱监督的自修正流程,实现在粗点监督下训练高性能目标定位器。COCO、DOTA和研究人员提出的SeaPerson数据集上的实验结果验证了CPR方法的有效性。
Object Localization under Single Coarse Point Supervision
论文:https://arxiv.org/abs/2203.09338
代码:https://github.com/ucas-vg/PointTinyBenchmark
TinyPerson V2(SeaPerson)数据集:vision.ucas.ac.cn/sources(TinyPerson的扩展版本,约70万个小目标样本)
1、简介
很多实际应用场景里,研究人员只需获取精确的物体位置,而不关注物体的大小(例如,机械臂瞄准一个点来拾取目标)。过细的标注(例如边界框、Mask)是多余的、不可取的,所以出现了点监督目标定位 (POL)任务。正是点的标注简单又省时,越来越受到关注。这类任务用点级别的标注进行训练,并预测原图像中一个2D坐标来表示物体位置。
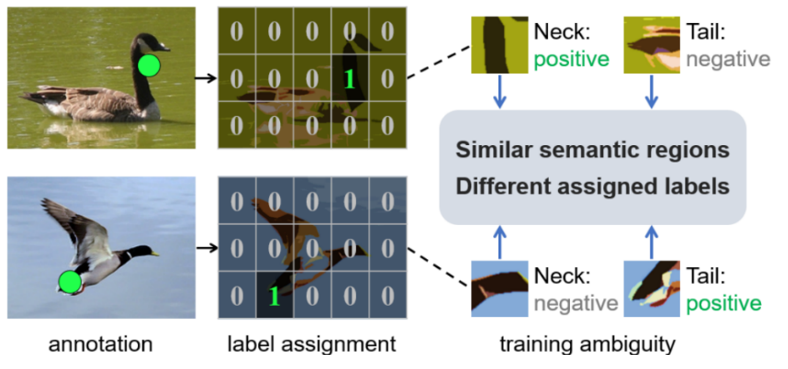
图2:点标注带来的语义歧义问题
通过深入分析POL任务,研究人员发现将物体表示为一个像素点时,必然存在多个候选的像素点,这就是POL语义歧义(语义方差)的问题:对于某个物体,具有不同语义信息的区域都可能被标记为正;对整个数据集,相似语义的区域就可能被标记地不同。以图2为例,都属于鸟类的两个物体,一个标记在颈部,另一个标记在尾部。在网络的训练过程中,一幅图像将颈部区域视为正例,而另一幅图像(标注尾部的图像)视为负例。这种现象就是语义歧义,这导致训练出来的模型性能差。

图3:基于关键点标注的难点。
目前的POL工作大多通过制定严格的标注规则,限制标注人员只在预先规定的区域内标注来解决语义方差问题,这存在以下挑战(图3):(1)关键点难以定义,特别是那些定义广泛、没有特定形状的类别;(2)由于物体的不同姿态和不同的拍摄视角,图像中可能不存在关键点;(3)当物体的尺度范围变化很大时,难以给出合适的关键点。这极大增加了标注难度和人力负担。也正是这些难题限制了POL任务在多类别、多尺度数据集(如 COCO、DOTA)上的探索。
本文提出基于粗点的多类别、多尺度定位(coarse point-based localization,CPL)范式,可训练出更具普遍性的POL定位器(图4)。首先,制作数据集用粗点标注策略,物体内的所有像素点都可标注。然后,用语义方差优化(Coarse Point Refinement,CPR)算法,将初始粗点优化到训练集的语义中心。最后,用语义中心点代替标注点作为监督训练定位器。语义中心点具有更小的语义方差和更高的预测误差容忍度。
研究人员深入研究POL任务,设计出基于粗点的定位(CPL)新范式,将POL任务扩展到多类和多尺度;提出粗点优化(CPR)方法,从算法的角度而不是严格的标注规则来减轻语义差异;MSCOCO、DOTA实验结果表明,CPR对CPL有效,并获得了与中心点(近似关键点)POL相当的性能,且性能超过baseline 10多个点;本文还开源了 SeaPerson新数据集。具有超过 600,000 个实例,可用于弱小人检测。
2、方法
单粗点标注的语义方差优化方法(Coarse Point Refinement,CPR)可看作一种预处理过程。将训练集上的数据标注转换为更具传导性的新标注,以供后续任务使用。CPR的主要目的是寻找一个语义方差更小、预测误差容忍度更高的语义点,并用该语义点代替初始标注点。如图5所示,CPR共有三个关键步骤:1、点采样:在每个初始标注点的邻域内进行点的采样。2、CPRNet训练:训练一个分类网络(CPRNet)对采样点是否与初始标注点属于同一类别进行分类。3、粗点的修正:根据训练好的CPRNet和约束条件,选择与初始标注点语义信息相似的点作为其语义点集,然后对点集里的点进行加权求和,得到标注点对应的语义中心点。
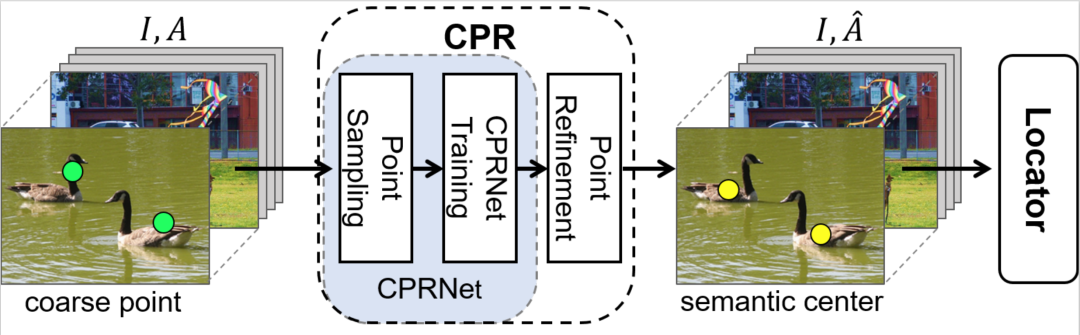
图 4 粗点标注的修正优化方法框架图。
2.1 采样点


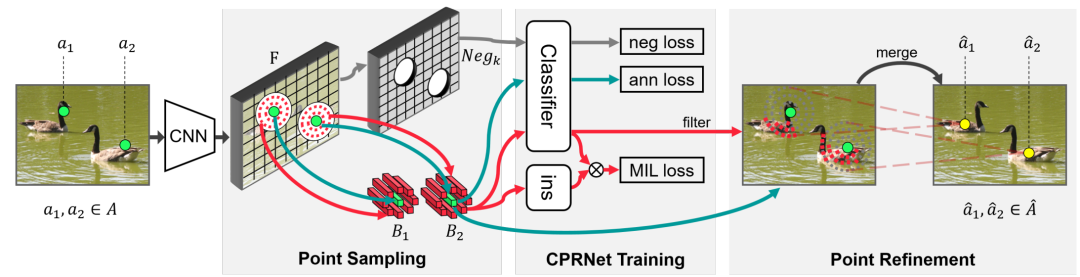
图5 粗点标注的修正方法图。(绿点为标注点,红点为相似语义点,黄点为语义中心点)
2.2 CPRNet的训练


2.3 粗点的修正
通过训练好的CPRNet,选择与初始标注点具有相同类别(相似语义)的点,记为正例点的集合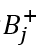
为了获取更好的正例集合
3、实验
3.1 方法对比
多类别P2PNet。研究人员使用P2PNet去训练点标注,并且预测出每个目标,作为一个较高的基准要求。有几种显然可以提高结果的方法:1,P2PNet的骨干网络在本文中是Resnet50而不是VGG16。2,使用focal loss而不是Cross-Entropy loss作为损失函数。3,Smooth-l1函数而不是L2 损失函数作为回归。4,在匹配标签时,使用top-k正例匹配,而不是一对一匹配。使用预测点使用NMS以获得最终点得分。P2PNet的结果在表1的第二行,相较于第一行结果提升了很多。
CPR。相比于自优化,CPR(表一第五行)策略使得P2PNet表现更好,表明CPR能更高效的处理语义歧义问题。为了量化语义差别,相对语义差别(RSV),定义为:

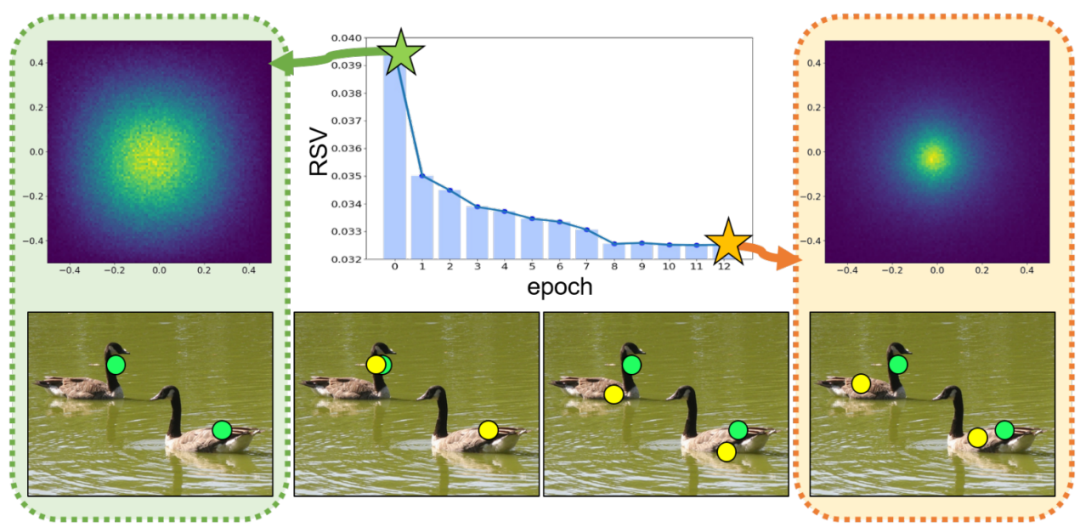
图6 左上和右上图为相对位置分布(自优化与CPR)中间的表格为CPR训练期间RSV值的变化。下面四个图给出了训练过程中,优化后的点的位置变化。
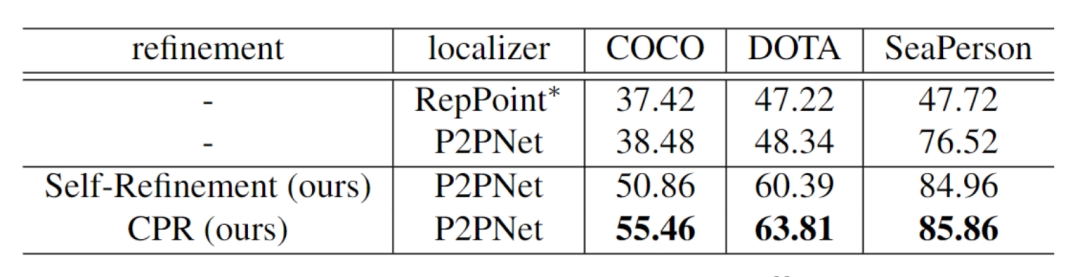
3.2 消融实验
为了更好的分析CPR的有效性和鲁棒性,研究人员进行了大量的实验。
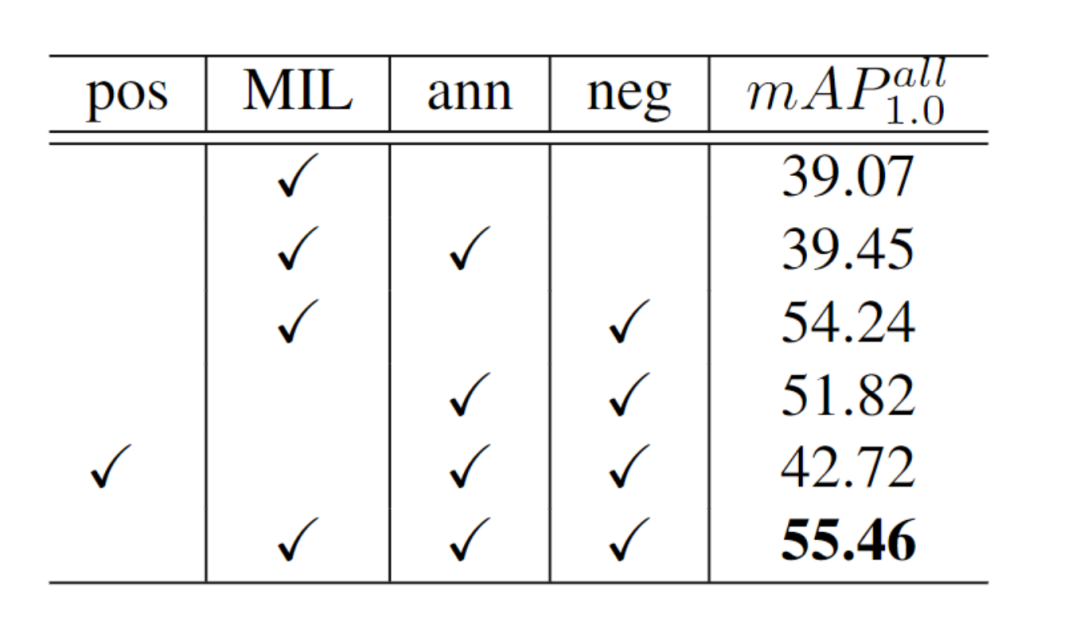
CPRNet的训练损失。消融实验的结果展示在表2。CPRNet的最优设置在第6行,达到55.46mAP。1.MIL loss。如果不使用该损失,结果掉了3.64个百分点。如果使用pos loss代替,结果掉了12.74个百分点(第五行)。表明MIL 可以自动地为候选点分类所归属的物体。2.Annotation loss。缺少该损失,结果跌了1.22个百分点。该损失使得训练朝着一个给定良好的监督训练而不跑偏。3.Negative loss。使用该损失(第2行)结果提升了16.01个百分点。表明MIL损失不足以压制负例损失,额外的背景类有利于压制负例。
公众号后台回复“数据集”获取100+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



