神经网络架构搜索(NAS)中的milestones
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:风车车
https://zhuanlan.zhihu.com/p/94252445
本文已由作者授权,未经允许,不得二次转载
神经网络架构搜索(NAS)今年也是火的不行,本文简单梳理一下个人觉得比较有代表意义的工作,如果有错误或者遗漏欢迎大家指出hhhh
另外推荐一篇survey(虽然到处都在说这个,但我还是要推荐一下)
Neural Architecture Search: A Survey
大致按照时间线来,内容分为这么几块:大力出奇迹,平民化,落地
1,大力出奇迹
--------------------------------
被人们所熟知的第一篇NAS工作应该是Google的这篇NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING[ICLR'17],充分展现了Google的实力和财力(划掉)。思路也是简单明了,以前每一层的filter数量大小等等都需要人为来定,那就可以做成一个优化问题列几个选项让它自己选个最好的,这样的选择组合起来就成了编码某个网络结构的token。为了让其更加灵活支持变长token,使用RNN来作为这里的controller,然后用policy gradient来最大化controller采样网络的期望reward,也就是validation accuracy
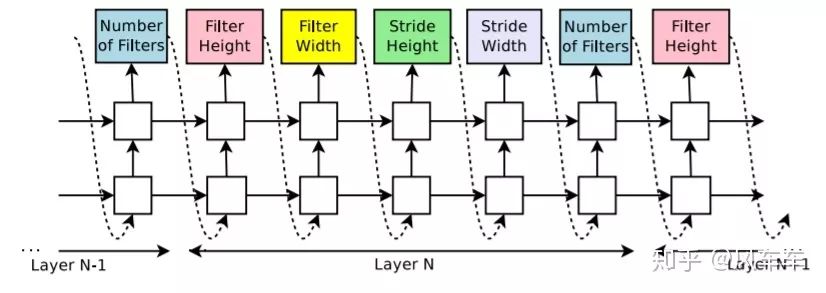
思路很直接,效果也不错,然鹅Google用了800块gpu跑了快一个月(还只是在cifar10)...直接劝退
后来这帮大佬可能觉得跑个cifar10太naive了,应该整个ImageNet,但是像之前这么搞直接在ImageNet上搜肯定是跑不动的,别说800张卡,8000张都搞不定。
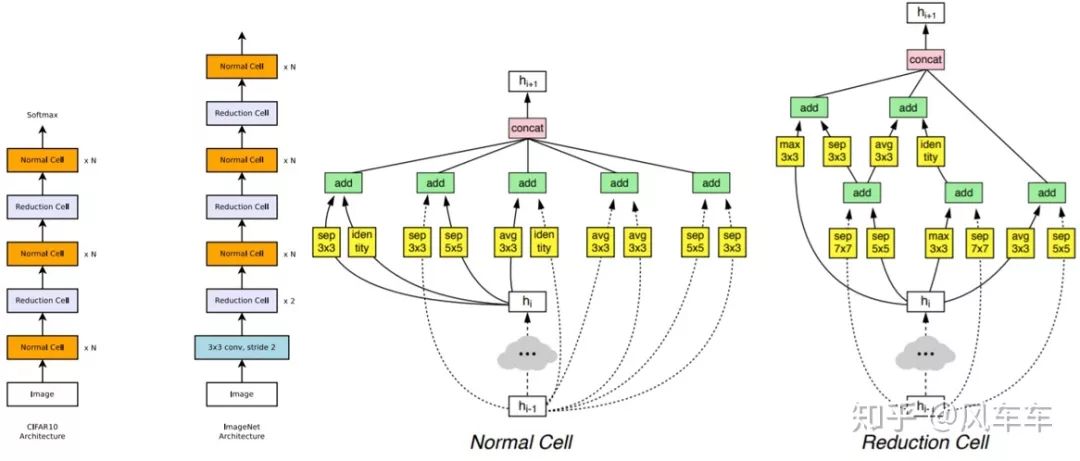
于是Google又出了一篇Learning Transferable Architectures for Scalable Image Recognition[CVPR'18]。那我不搜整个结构,搜个cell然后堆起来就行了,反正VGG/Inception/ResNet也是这么干的,于是沿用了之前的思路,继续用RNN和policy gradient在新的搜索空间中寻找最佳的结构,在cifar上搜cell然后堆起来用到ImageNet上。搜索目标只包括两种cell,一种是normal cell,另一种reduction cell用于downsample,每个cell里面包括一些block,新的搜索空间包括选择这些block使用什么op,用什么作为输入等。之后很多工作都沿用了NASNet Search Space这个套路。
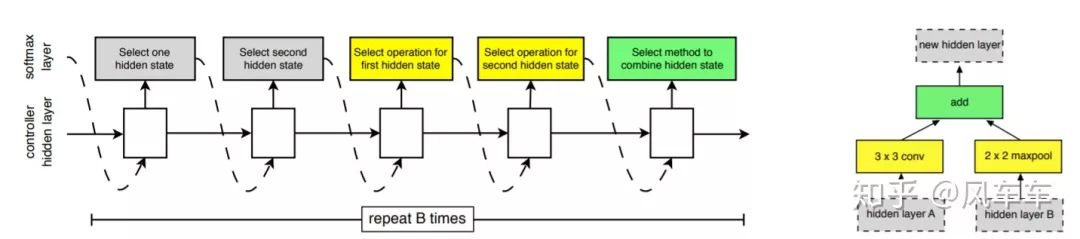
最后整体结构和搜到的cell长这个样子,也就是NASNet
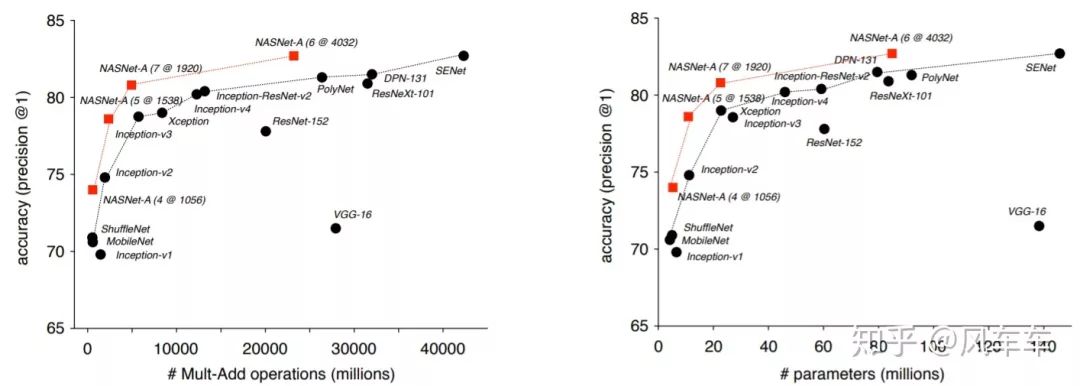
performance也很不错,cifar10最好的一次跑到了2.19%的error rate,在同样参数下ImageNet也都超过了手工设计的网络
这次的速度比上次快多了,500块gpu只跑了4天就跑完了(再次劝退)
之后大佬们可能觉得现在的token都定长了,或许RNN+policy gradient的优化方式可以换成一些其他的算法(也可能是觉得强化学习调参太tm蛋疼了),于是Google又出来一篇Regularized Evolution for Image Classifier Architecture Search[AAAI'19],搜索空间沿用上面的NASNet Search Space,只是将优化算法换成了regularized evolution(具体算法还是看paper吧...写出来感觉内容太多了(其实就是懒)),搜到的结构叫做AmoebaNet。实验表明确实evolution更加好使,收敛快,效果好,调参还没那么蛋疼。
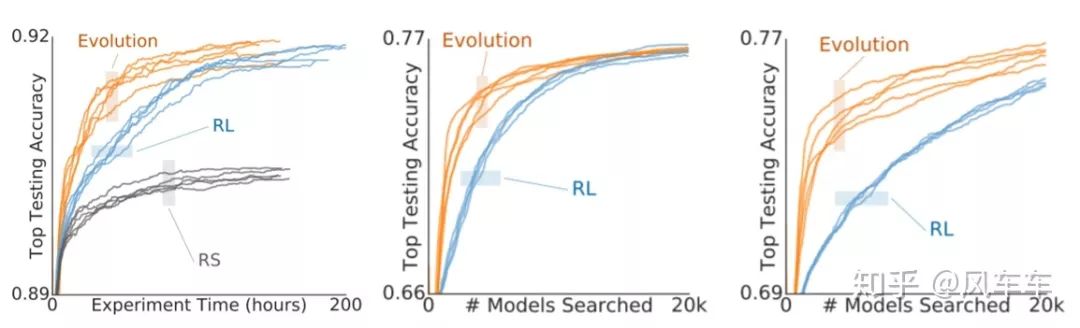
AmoebaNet这种方法用450块gpu跑了7天,依旧劝退。。
后来Google自己也觉得之前的方法太花时间了,于是又搞了个Progressive Neural Architecture Search[ECCV'18],主要目标就是做加速。将搜索空间减小并且用预测函数来预测网络精度,最后时间缩短到大概225个gpu-day,相比AmoebaNet少了十几倍,然而对于普通玩家还是在劝退。。。
2,平民化
--------------------------------
像上面这种大力出奇迹的玩法平民玩家基本玩不起,但是计算量的问题摆在这里,自然就有一些解决方案来加速这个过程。
比较有代表性的就是weight sharing加速validation的Efficient Neural Architecture Search via Parameter Sharing[ICML'18](咦,还是Google的Quoc V. Le他们),大概思路就是将NAS的采样过程变成在一个DAG里面采样子图的过程,采样到的子图里面的操作(卷积等)是参数共享的。与之前的方法主要差别就在于ENAS中子图的参数从DAG继承而来而不是重新初始化,不需要train-from-scratch即可以验证子图的精度,极大的加速了NAS的过程。
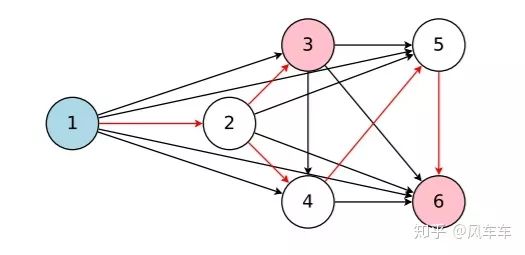
为了评估采样到的子图在数据集上的表现,DAG的参数(weight等)是需要优化的,除此之外为了找到最好的子图,采样器(这里使用的RNN)也是需要优化的。ENAS采用的是交替优化DAG中的参数和采样器中的参数。DAG参数的优化是通过采样一个子图,然后forward-backward计算对应操作的梯度,再将梯度应用到DAG上对应的操作通过梯度下降更新参数。采样器RNN的更新采用了之前policy gradient的优化方式。
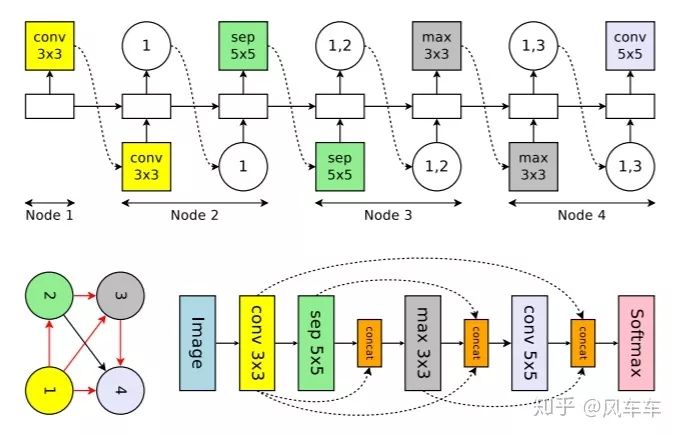
ENAS提出了两种模式(这里只介绍CNN),一种是搜整个网络结构,一种是搜个cell然后按照之前的方式堆起来,在搜索cell的时候只需要一张卡跑半天就能跑完。不过最近ICLR'20的投稿中对于weight sharing有很多不同的声音,有兴趣的可以去openreview看一看。
还有一个很快就能跑完的NAS工作是用可微分的方式进行搜索的DARTS: Differentiable Architecture Search[ICLR'19],在今年被各种魔改(我猜很可能是因为开源了pytorch的代码,然后代码写得很漂亮改起来也比较容易)。DARTS和ENAS很像,也是从DAG中找子图,并且同样采用了weight sharing,主要的区别在于搜索空间和搜索算法上。搜索空间比较类似NASNet search space,搜索算法则是采用了可微分的方式。
DARTS也是搜cell然后按照一定的模式堆起来,在搜索算法上与之前的方法最大的区别在于DARTS选择某个操作的时候并不是像之前按照RNN的输出概率进行采样,而是把所有操作都按照权重(不是直接加权,先将权重softmax归一化)加起来,那这样权重就在计算图里面了,在计算验证集loss之后就可以backward计算权重的梯度,直接通过梯度下降来优化权重。搜索的过程也就是优化权重的过程,最后保留权重最大的操作就是最后搜到的结构。
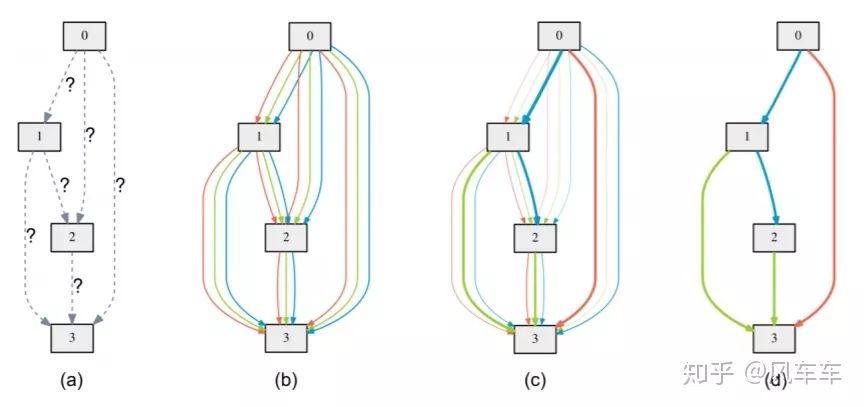
权重的优化和DAG里面weight的优化类似于ENAS,也是交替进行的(在训练集上优化weight,在验证集优化权重),不过DARTS是整个DAG进行forward-backward(这样的缺点在于内存开销会比较大)而不是像ENAS一样先采样子图。

DARTS搜索一次只需要一张1080ti跑一天即可,对于平民玩家完全没压力hhhhh
上面这两项工作让很多只有几张显卡的平民玩家也能玩得起NAS。
3,落地
--------------------------------
上面所介绍的NAS工作很少有人工设计网络的影子,基本都是重新设计了新的搜索空间。从实验结果上来NAS搜到的网络确实能取得很好的效果,但并不一定适合实际部署(比如DARTS能在很小的参数量下达到很高的精度,但是实际forward其实很慢)。既然之前已经有了很多优秀的人工设计的网络结构,NAS可以通过引入这些先验知识来加速或者取得更好的实际部署性能。
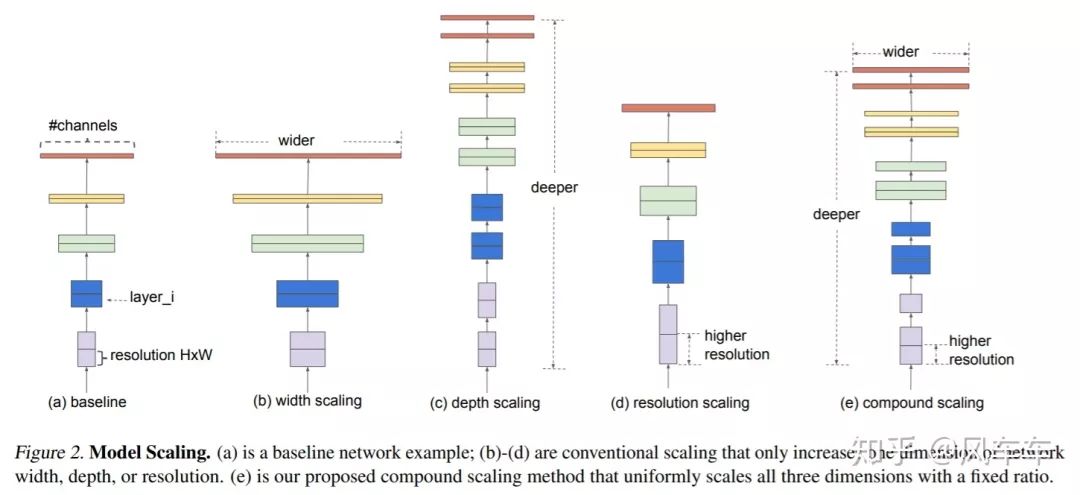
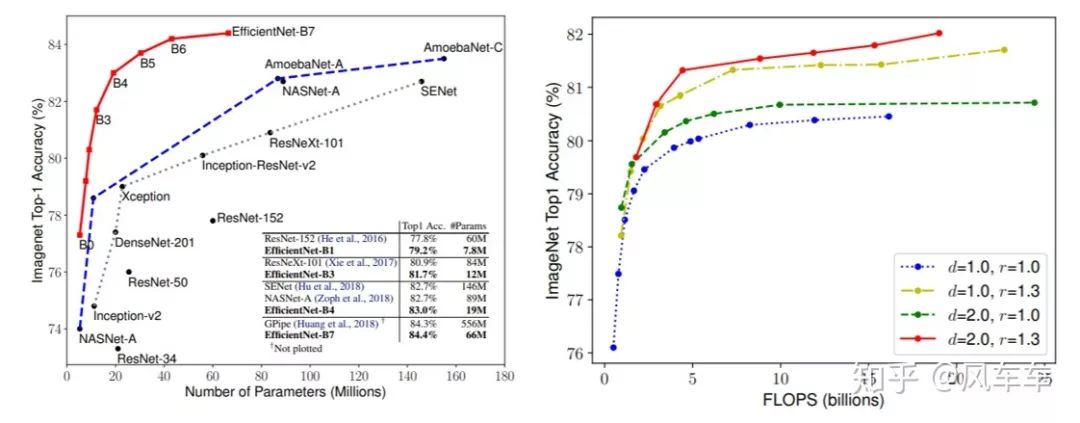
先举个最直观的例子,EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks[ICML'19]简单粗暴,既然MobileNet在同样精度下速度快,那我把它拿来搞大一点,同样的速度下精度会不会高一点?答案是肯定的
问题在于怎么放大这个网络,单独加深/加宽/加大分辨率效果一般般,EfficientNet搜索了宽度/深度/分辨率之间的相对缩放因子,将他们按照一定的比例放大,事实证明这种方式(我觉得这应该也算是NAS)虽然简单但是有效。
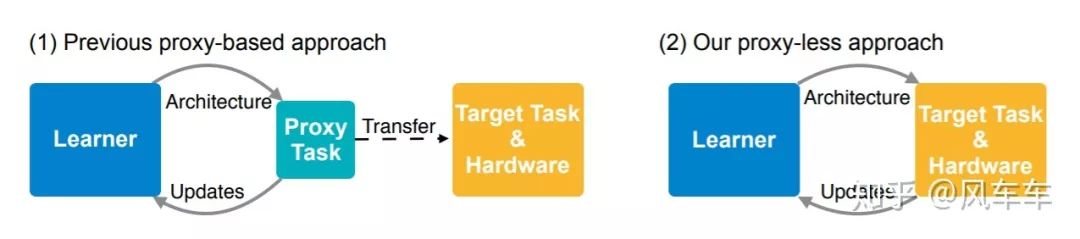
还有一个魔改MobileNetV2的工作出自MIT Song Han组,ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware[ICLR'19],这篇工作的point不在于魔改MobileNetV2(kernel size,expansion ratio等),而是在于proxyless的理念。想要某个数据集在某硬件上的结果就直接在对应的数据集和硬件上进行搜索,而不是像之前的工作先在cifar10搜然后transfer到ImageNet等大数据集上,并且在目标函数上加入硬件latency的损失项作为多目标NAS,直接面向部署的硬件。
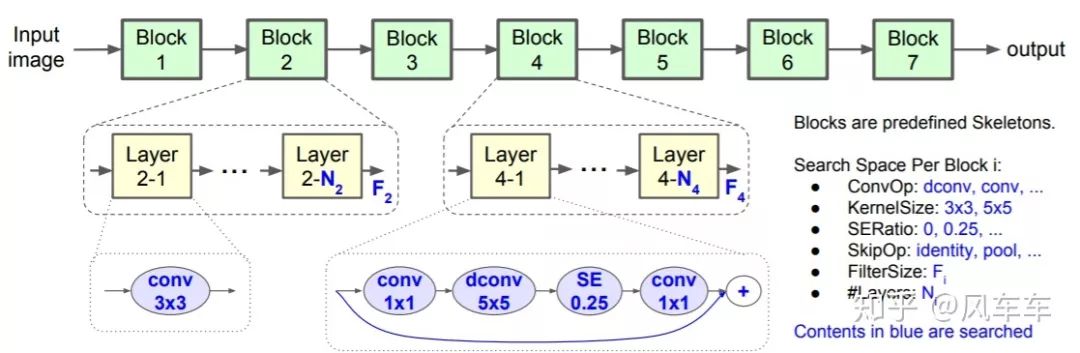
另一个系列的工作也是出自Google,MnasNet: Platform-Aware Neural Architecture Search for Mobile[CVPR'19]用来魔改MobileNetV2里面的layer数/卷积操作/加attention等等,然后用之前同样的RNN+policy gradient的方式来优化
除此之外,NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications[ECCV'18]针对特定硬件对已有的网络做压缩,相当于对网络在硬件上做一个结构上的fine-tune。
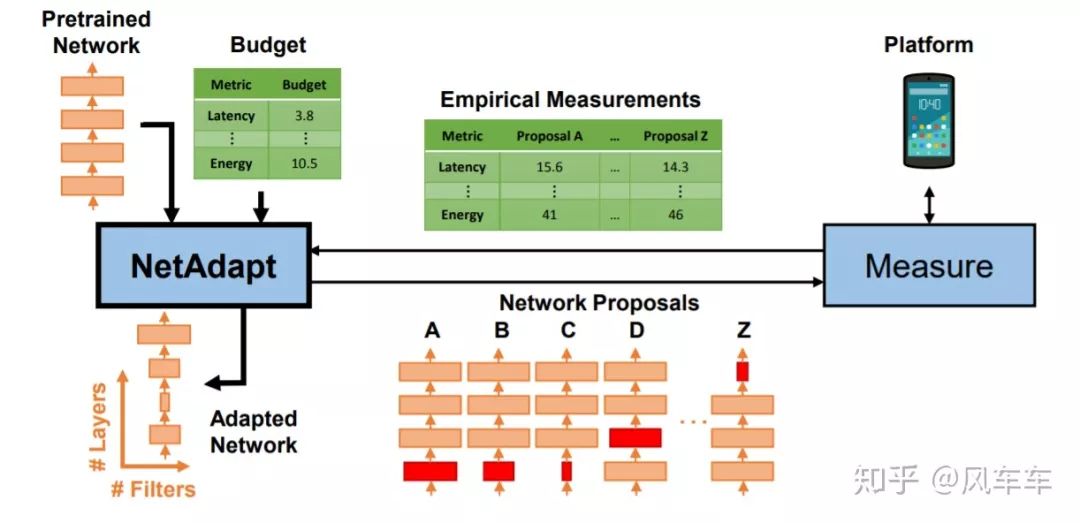
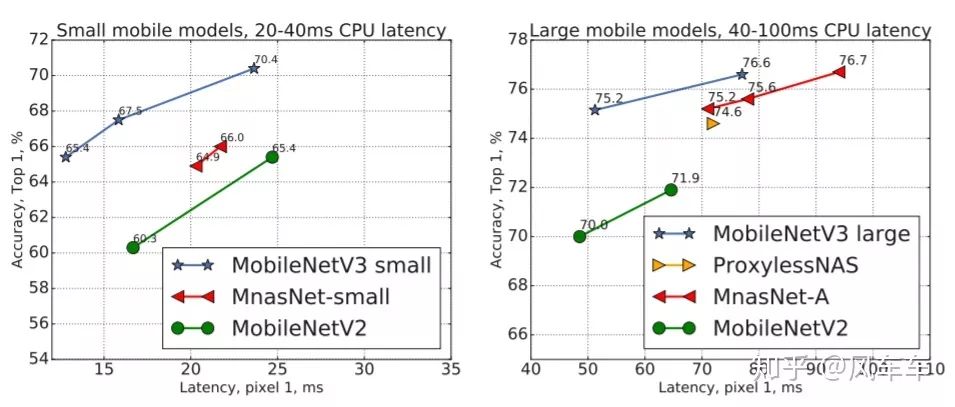
Google后来结合了上面这两项工作,推出了Searching for MobileNetV3[ICCV'19],把MnasNet魔改的MobileNetV2再用NetAdapt做微调,然后加了一些工程技巧,得到了最后的MobileNetV3。
最后再介绍一个同样是Song Han组最近的工作,Once for All: Train One Network and Specialize it for Efficient Deployment[Arxiv],直接train一个大网络,需要哪种网络直接去里面取就可以,将训练过程和搜索的过程解耦开来,相当于只需要train一次。
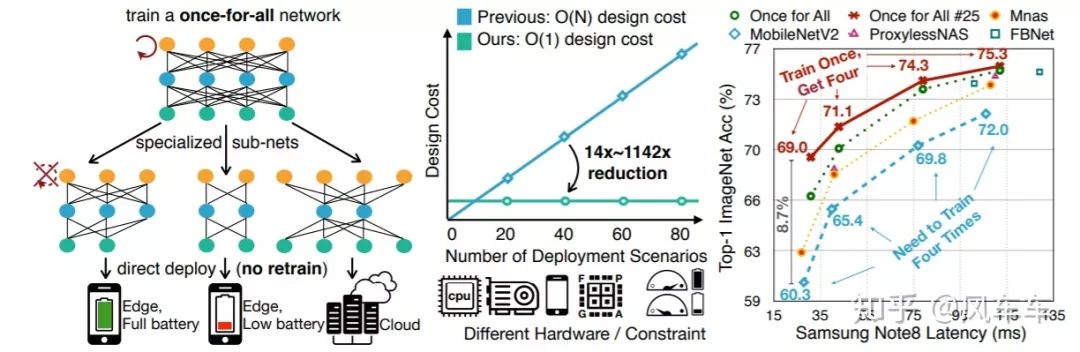
比较神奇的地方在于训完了之后不需要fine-tune就能取得很好的结果,应该是跟下面这种progressive shrinking的训练方式相关。如果再fine-tune精度会更高,openreview上的版本甚至比MobileNetV3高出4个点。
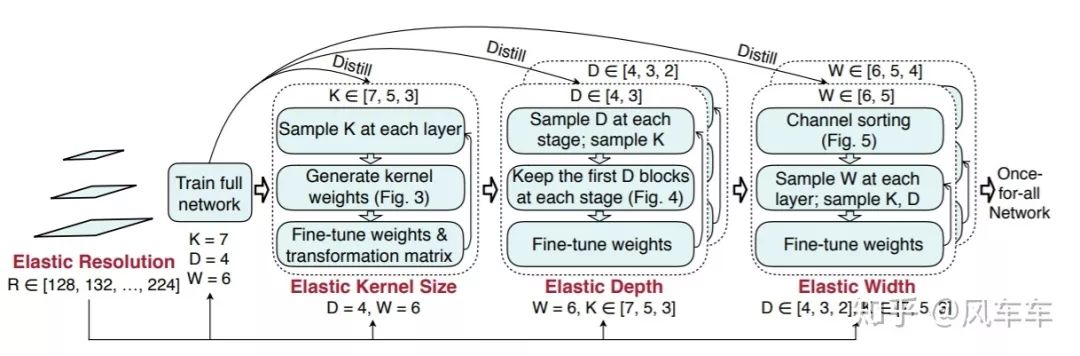
感觉是一个很好的思路,大部分NAS的主要时间到都花在验证/比较网络精度上,那么把这个时间都花在训练一个大网络上,然后再选所需要的小网络或许是一种更高效/性能更好的方式。Once for All使用的一些技巧也比较多,推荐大家看一下原paper
最后再说一个Rethinking the Value of Network Pruning[ICLR'19]里面的结论,对于结构化的剪枝,Training---Pruning---Fine-tuning的pipeline得到的精度并不如将目标网络train-from-scratch的精度高,也就是说剪枝的目标网络的结构设计其实最为重要,这也就是NAS正在做的事情。不过在train-from-scratch代价比较大的时候,pruning和fine-tuning的策略也很重要,争取在计算量尽量少的情况下维持原有精度。
终于写完啦,以后再看到有意思的paper也会继续更新~
重磅!CVer-NAS交流群已成立
扫码可添加CVer助手,可申请加入CVer-NAS交流群,同时可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。一定要备注:研究方向+地点+学校/公司+昵称(如NAS+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


