CVPR2019 | 12篇目标检测最新论文(FSAF/GS3D/Libra R-CNN/Stereo R-CNN和GIoU等)
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

前言
CVer 上次推送一则含21篇目标检测论文的文章:一文看尽21篇目标检测最新论文(腾讯/Google/商汤/旷视/清华/浙大/CMU/华科/中科院等)
上述论文并不包含CVPR 2019的目标检测论文,因为为了方便大家阅读/区分,我已经将CVPR2019 目标检测部分论文 单独整理出来(文章将持续更新)。
本文分享的目标检测论文将同步推送到 github上,欢迎大家 star/fork(点击阅读原文,也可直接访问):
https://github.com/amusi/awesome-object-detection
注意事项:
时间按arXiv上由远及近排序
包含 2D 目标检测、3D 目标检测、视频目标检测
CVPR2019 目标检测论文
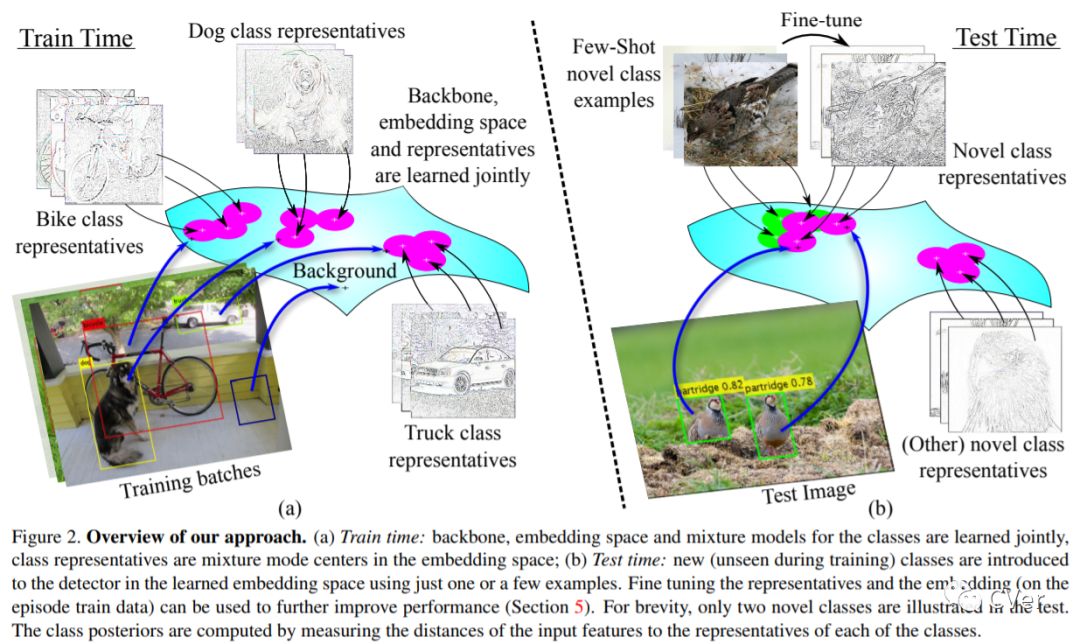
【1】RRepMet: Representative-based metric learning for classification and one-shot object detection
Distance metric learning (DML) has been successfully applied to object classification, both in the standard regime of rich training data and in the few-shot scenario, where each category is represented by only a few examples. In this work, we propose a new method for DML that simultaneously learns the backbone network parameters, the embedding space, and the multi-modal distribution of each of the training categories in that space, in a single end-to-end training process. Our approach outperforms state-of-the-art methods for DML-based object classification on a variety of standard fine-grained datasets. Furthermore, we demonstrate the effectiveness of our approach on the problem of few-shot object detection, by incorporating the proposed DML architecture as a classification head into a standard object detection model. We achieve the best results on the ImageNet-LOC dataset compared to strong baselines, when only a few training examples are available. We also offer the community a new episodic benchmark based on the ImageNet dataset for the few-shot object detection task.
Date:20181118
Author:IBM等
arXiv:https://arxiv.org/abs/1806.04728v3
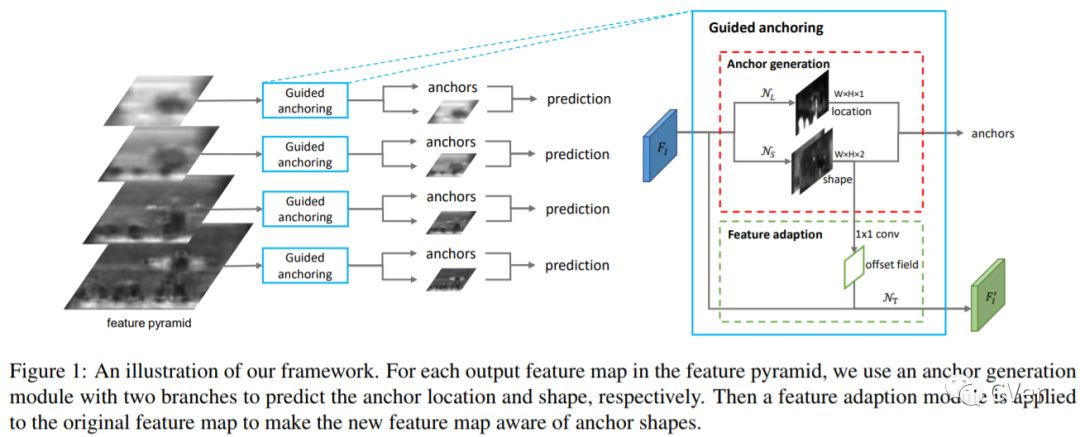
【2】Region Proposal by Guided Anchoring
Region anchors are the cornerstone of modern object detection techniques. State-of-the-art detectors mostly rely on a dense anchoring scheme, where anchors are sampled uniformly over the spatial domain with a predefined set of scales and aspect ratios. In this paper, we revisit this foundational stage. Our study shows that it can be done much more effectively and efficiently. Specifically, we present an alternative scheme, named Guided Anchoring, which leverages semantic features to guide the anchoring. The proposed method jointly predicts the locations where the center of objects of interest are likely to exist as well as the scales and aspect ratios at different locations. On top of predicted anchor shapes, we mitigate the feature inconsistency with a feature adaption module. We also study the use of high-quality proposals to improve detection performance. The anchoring scheme can be seamlessly integrated to proposal methods and detectors. With Guided Anchoring, we achieve 9.1% higher recall on MS COCO with 90% fewer anchors than the RPN baseline. We also adopt Guided Anchoring in Fast R-CNN, Faster R-CNN and RetinaNet, respectively improving the detection mAP by 2.2%, 2.7% and 1.2%.
Date:20190110
Author:香港中文大学&商汤科技&亚马逊&南洋理工大学
arXiv:https://arxiv.org/abs/1901.03278
解读:港中大-商汤联合实验室等提出:Guided Anchoring: 物体检测器也能自己学 Anchor
【3】Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
Intersection over Union (IoU) is the most popular evaluation metric used in the object detection benchmarks. However, there is a gap between optimizing the commonly used distance losses for regressing the parameters of a bounding box and maximizing this metric value. The optimal objective for a metric is the metric itself. In the case of axis-aligned 2D bounding boxes, it can be shown that IoU can be directly used as a regression loss. However, IoU has a plateau making it infeasible to optimize in the case of non-overlapping bounding boxes. In this paper, we address the weaknesses of IoU by introducing a generalized version as both a new loss and a new metric. By incorporating this generalized IoU (GIoU) as a loss into the state-of-the art object detection frameworks, we show a consistent improvement on their performance using both the standard, IoU based, and new, GIoU based, performance measures on popular object detection benchmarks such as PASCAL VOC and MS COCO..
Date:20190225
Author:斯坦福大学等
arXiv:https://arxiv.org/abs/1902.09630
解读:CVPR2019 | 目标检测新文:Generalized Intersection over Union


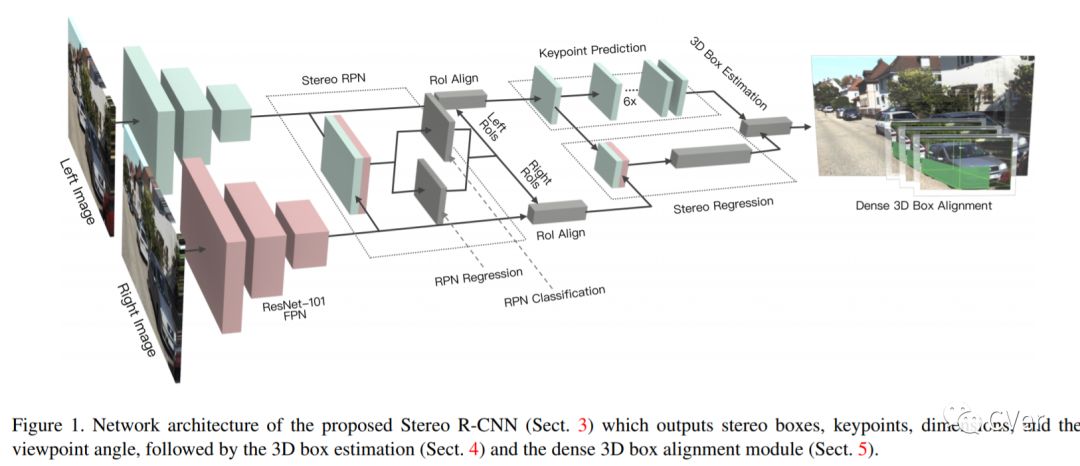
【4】Stereo R-CNN based 3D Object Detection for Autonomous Driving
We propose a 3D object detection method for autonomous driving by fully exploiting the sparse and dense, semantic and geometry information in stereo imagery. Our method, called Stereo R-CNN, extends Faster R-CNN for stereo inputs to simultaneously detect and associate object in left and right images. We add extra branches after stereo Region Proposal Network (RPN) to predict sparse keypoints, viewpoints, and object dimensions, which are combined with 2D left-right boxes to calculate a coarse 3D object bounding box. We then recover the accurate 3D bounding box by a region-based photometric alignment using left and right RoIs. Our method does not require depth input and 3D position supervision, however, outperforms all existing fully supervised image-based methods. Experiments on the challenging KITTI dataset show that our method outperforms the state-of-the-art stereo-based method by around 30% AP on both 3D detection and 3D localization tasks. Code will be made publicly available.
Date:20190226
Author:香港科技大学&大疆(DJI)
arXiv:https://arxiv.org/abs/1902.09738
解读:https://zhuanlan.zhihu.com/p/58077936
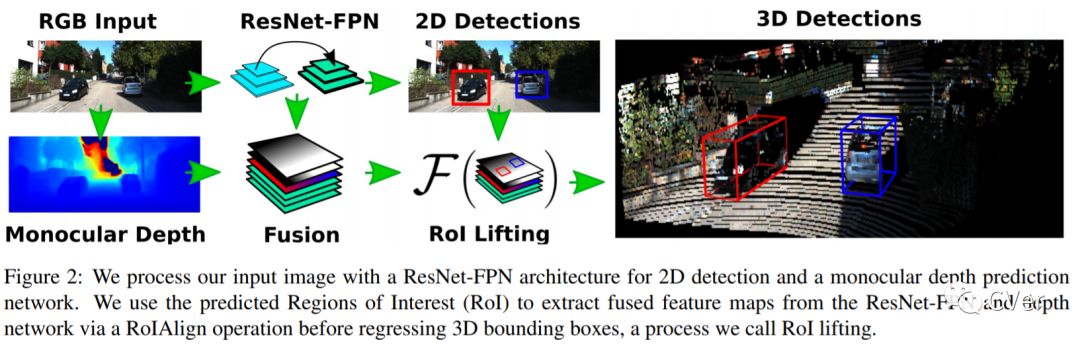
【5】ROI-10D: Monocular Lifting of 2D Detection to 6D Pose and Metric Shape
We present a deep learning method for end-to-end monocular 3D object detection and metric shape retrieval. We propose a novel loss formulation by lifting 2D detection, orientation, and scale estimation into 3D space. Instead of optimizing these quantities separately, the 3D instantiation allows to properly measure the metric misalignment of boxes. We experimentally show that our 10D lifting of sparse 2D Regions of Interests (RoIs) achieves great results both for 6D pose and recovery of the textured metric geometry of instances. This further enables 3D synthetic data augmentation via inpainting recovered meshes directly onto the 2D scenes. We evaluate on KITTI3D against other strong monocular methods and demonstrate that our approach doubles the AP on the 3D pose metrics on the official test set, defining the new state of the art.
Date:20190226
Author:慕尼黑工业大学&丰田研究所
arXiv:https://arxiv.org/abs/1812.02781v2
【6】Feature Selective Anchor-Free Module for Single-Shot Object Detection
We motivate and present feature selective anchor-free (FSAF) module, a simple and effective building block for single-shot object detectors. It can be plugged into single-shot detectors with feature pyramid structure. The FSAF module addresses two limitations brought up by the conventional anchor-based detection: 1) heuristic-guided feature selection; 2) overlap-based anchor sampling. The general concept of the FSAF module is online feature selection applied to the training of multi-level anchor-free branches. Specifically, an anchor-free branch is attached to each level of the feature pyramid, allowing box encoding and decoding in the anchor-free manner at an arbitrary level. During training, we dynamically assign each instance to the most suitable feature level. At the time of inference, the FSAF module can work jointly with anchor-based branches by outputting predictions in parallel. We instantiate this concept with simple implementations of anchor-free branches and online feature selection strategy. Experimental results on the COCO detection track show that our FSAF module performs better than anchor-based counterparts while being faster. When working jointly with anchor-based branches, the FSAF module robustly improves the baseline RetinaNet by a large margin under various settings, while introducing nearly free inference overhead. And the resulting best model can achieve a state-of-the-art 44.6% mAP, outperforming all existing single-shot detectors on COCO.
Date:20190302
Author:卡耐基梅隆大学(CMU)
arXiv:https://arxiv.org/abs/1903.00621
解读:CVPR2019 | CMU提出Single-Shot目标检测最强算法:FSAF
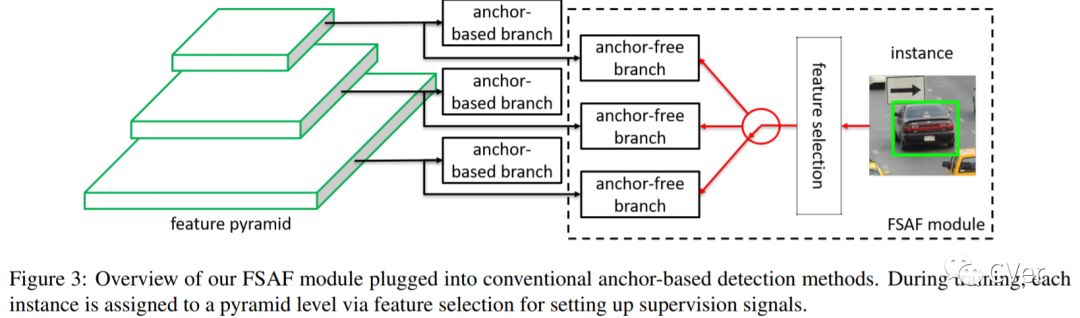
【7】Strong-Weak Distribution Alignment for Adaptive Object Detection
We propose an approach for unsupervised adaptation of object detectors from label-rich to label-poor domains which can significantly reduce annotation costs associated with detection. Recently, approaches that align distributions of source and target images using an adversarial loss have been proven effective for adapting object classifiers. However, for object detection, fully matching the entire distributions of source and target images to each other at the global image level may fail, as domains could have distinct scene layouts and different combinations of objects. On the other hand, strong matching of local features such as texture and color makes sense, as it does not change category level semantics. This motivates us to propose a novel approach for detector adaptation based on strong local alignment and weak global alignment. Our key contribution is the weak alignment model, which focuses the adversarial alignment loss on images that are globally similar and puts less emphasis on aligning images that are globally dissimilar. Additionally, we design the strong domain alignment model to only look at local receptive fields of the feature map. We empirically verify the effectiveness of our approach on several detection datasets comprising both large and small domain shifts.
Date:20190313
Author:波士顿大学院&东京大学等
arXiv:https://arxiv.org/abs/1812.04798
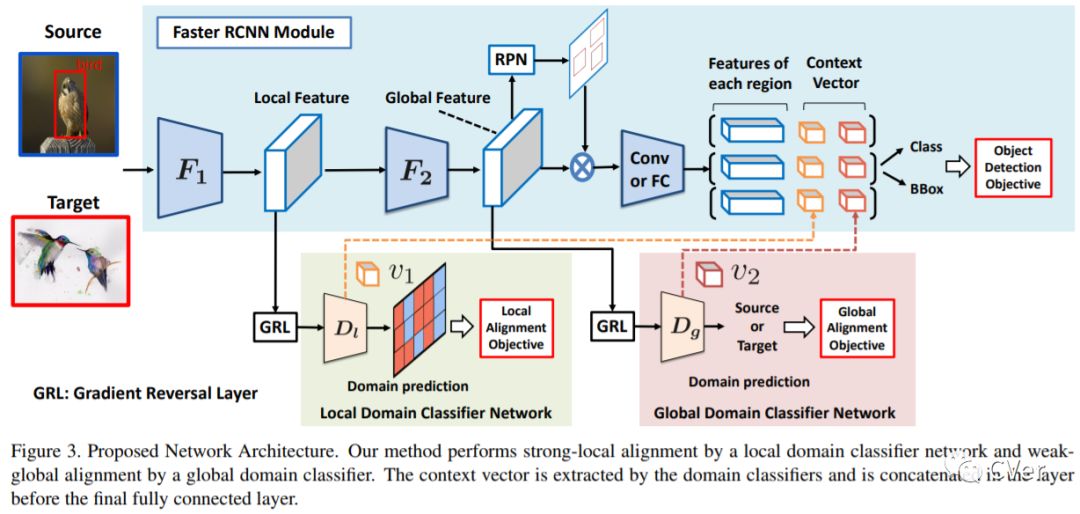
【8】Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
3D object detection is an essential task in autonomous driving. Recent techniques excel with highly accurate detection rates, provided the 3D input data is obtained from precise but expensive LiDAR technology. Approaches based on cheaper monocular or stereo imagery data have, until now, resulted in drastically lower accuracies --- a gap that is commonly attributed to poor image-based depth estimation. However, in this paper we argue that data representation (rather than its quality) accounts for the majority of the difference. Taking the inner workings of convolutional neural networks into consideration, we propose to convert image-based depth maps to pseudo-LiDAR representations --- essentially mimicking LiDAR signal. With this representation we can apply different existing LiDAR-based detection algorithms. On the popular KITTI benchmark, our approach achieves impressive improvements over the existing state-of-the-art in image-based performance --- raising the detection accuracy of objects within 30m range from the previous state-of-the-art of 22% to an unprecedented 74%. At the time of submission our algorithm holds the highest entry on the KITTI 3D object detection leaderboard for stereo image based approaches.
Date:20190318
Author:康奈尔大学
arXiv:https://arxiv.org/abs/1812.07179v3
【9】Few-shot Adaptive Faster R-CNN
To mitigate the detection performance drop caused by domain shift, we aim to develop a novel few-shot adaptation approach that requires only a few target domain images with limited bounding box annotations. To this end, we first observe several significant challenges. First, the target domain data is highly insufficient, making most existing domain adaptation methods ineffective. Second, object detection involves simultaneous localization and classification, further complicating the model adaptation process. Third, the model suffers from over-adaptation (similar to overfitting when training with a few data example) and instability risk that may lead to degraded detection performance in the target domain. To address these challenges, we first introduce a pairing mechanism over source and target features to alleviate the issue of insufficient target domain samples. We then propose a bi-level module to adapt the source trained detector to the target domain: 1) the split pooling based image level adaptation module uniformly extracts and aligns paired local patch features over locations, with different scale and aspect ratio; 2) the instance level adaptation module semantically aligns paired object features while avoids inter-class confusion. Meanwhile, a source model feature regularization (SMFR) is applied to stabilize the adaptation process of the two modules. Combining these contributions gives a novel few-shot adaptive Faster-RCNN framework, termed FAFRCNN, which effectively adapts to target domain with a few labeled samples. Experiments with multiple datasets show that our model achieves new state-of-the-art performance under both the interested few-shot domain adaptation(FDA) and unsupervised domain adaptation(UDA) setting.
Date:20190322
Author:新加坡国立大学&华为诺亚方舟实验室
arXiv:https://arxiv.org/abs/1903.09372

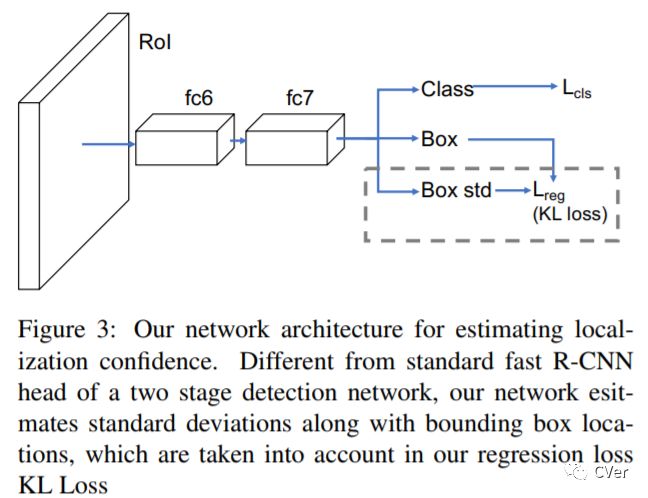
【10】Bounding Box Regression with Uncertainty for Accurate Object Detection
Large-scale object detection datasets (e.g., MS-COCO) try to define the ground truth bounding boxes as clear as possible. However, we observe that ambiguities are still introduced when labeling the bounding boxes. In this paper, we propose a novel bounding box regression loss for learning bounding box transformation and localization variance together. Our loss greatly improves the localization accuracies of various architectures with nearly no additional computation. The learned localization variance allows us to merge neighboring bounding boxes during non-maximum suppression (NMS), which further improves the localization performance. On MS-COCO, we boost the Average Precision (AP) of VGG-16 Faster R-CNN from 23.6% to 29.1%. More importantly, for ResNet-50-FPN Mask R-CNN, our method improves the AP and AP90 by 1.8% and 6.2% respectively, which significantly outperforms previous state-of-the-art bounding box refinement methods. Our code and models are available at: github.com/yihui-he/KL-Loss
Date:20190325
Author:卡耐基梅隆大学(CMU)&旷视科技(Face++)
arXiv:https://arxiv.org/abs/1809.08545v2
github:https://github.com/yihui-he/KL-Loss
注:原Softer NMS的升级版:《Softer-NMS: Rethinking Bounding Box Regression for Accurate Object Detection》

【11】GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
We present an efficient 3D object detection framework based on a single RGB image in the scenario of autonomous driving. Our efforts are put on extracting the underlying 3D information in a 2D image and determining the accurate 3D bounding box of the object without point cloud or stereo data. Leveraging the off-the-shelf 2D object detector, we propose an artful approach to efficiently obtain a coarse cuboid for each predicted 2D box. The coarse cuboid has enough accuracy to guide us to determine the 3D box of the object by refinement. In contrast to previous state-of-the-art methods that only use the features extracted from the 2D bounding box for box refinement, we explore the 3D structure information of the object by employing the visual features of visible surfaces. The new features from surfaces are utilized to eliminate the problem of representation ambiguity brought by only using a 2D bounding box. Moreover, we investigate different methods of 3D box refinement and discover that a classification formulation with quality aware loss has much better performance than regression. Evaluated on the KITTI benchmark, our approach outperforms current state-of-the-art methods for single RGB image based 3D object detection.
Date:20190327
Author:中科院&旷视科技
arXiv:https://arxiv.org/abs/1903.10955

【12】Libra R-CNN: Towards Balanced Learning for Object Detection
这篇论文很特殊,arXiv上还没有出来,但 Amusi 之前就知道这篇论文,所以这里po一下,预计今年6月开源(会合并到 mmdetection 中)
Nice work
Date:None
Author:港中文&商汤科技等(Amusi猜测)
arXiv:None
github:https://github.com/OceanPang/Libra_R-CNN
CVer目标检测交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群。一定要备注:目标检测+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!

