【韩家炜老师CS512 Spring 2020课程】数据挖掘:原理与算法,附下载
【导读】韩家炜老师是数据挖掘领域的祖师爷,也是华人计算机界的代表性人物之一。最近他在UIUC美国伊利诺伊大学香槟分校新开设一门课程CS512 Spring 2020关于数据挖掘《Data Mining: Principles and Algorithms》,介绍数据挖掘的原理、算法和应用,包括算法、方法、实现和应用。课程内容包括:网络概论、信息网络挖掘、序列与图数据挖掘、先进的聚类方法、离群点分析方法、数据流挖掘、时空数据挖掘、文本数据挖掘、Web数据挖掘等。值得关注学习。


美国伊利诺伊大学香槟分校计算机系教授、ACM和IEEE会士、美国信息网络学术研究中心主任 韩家炜
韩家炜是美国伊利诺伊大学香槟分校计算机系教授、IEEE和ACM会士、美国信息网络学术研究中心主任。曾担任KDD、SDM和ICDM等国际知名会议的程序委员会主席,创办了ACM TKDD期刊并担任主编。在数据挖掘、数据库和信息网络领域发表论文600余篇。曾获得2004 ACM SIGKDD创新奖、2005 IEEE计算机分会技术成就奖、2009 IEEE计算机分会Wallace McDowell奖等。
主页:https://hanj.cs.illinois.edu/
课程地址:
https://wiki.illinois.edu//wiki/display/cs512
课程介绍:
这是一门关于数据挖掘的研究生课程。介绍了数据挖掘的原理、算法和应用,包括算法、方法、实现和应用。课程内容包括:网络概论、信息网络挖掘、序列与图数据挖掘、先进的聚类方法、离群点分析方法、数据流挖掘、时空数据挖掘、文本数据挖掘、Web数据挖掘等。本课程主要面向对数据挖掘感兴趣的计算机科学研究生。同时,本课程也可能吸引其他学科的学生,他们需要理解、实现和/或使用数据挖掘方法来分析大量数据。
教课书
Jiawei Han, Micheline Kamber, and Jian Pei. "Data Mining: Concepts and Techniques, 3rd ed., Morgan Kaufmann, 2011.
Note: Two chapters of the course will use this 3rd edition of the book (Chapters 11 & 12 of 3rd ed. of the book). The remaining chapters will use network mining materials plus the 2nd edition of the book (2006) starting at Chapter 8 (mainly replying on slides or related papers).
See the book's home page for errata, course slides, and other reference materials.
Yizhou Sun and Jiawei Han, Mining Heterogeneous Information Networks: Principles and Methodologies, Morgan & Claypool, 2012 (which will be used mainly in the first second half of the course).
参考书
D. Easley and J. Kleinberg, Networks, Crowds, and Markets: Reasoning About a Highly Connected World, Cambridge Univ. Press, 2010.
M. Newman, Networks: An Introduction, Oxford Univ. Press, 2010.
C. M. Bishop, Pattern Recognition and Machine Learning, Springer 2007.
S. Chakrabarti, "Mining the Web: Statistical Analysis of Hypertext and Semi-Structured Data", Morgan Kaufmann, 2002
R. O. Duda, P. E. Hart, and D. G. Stork, Pattern Classification, 2ed., Wiley-Inter-science, 2001.
T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Springer-Verlag, 2nd ed. 2009.
C. D. Manning, P. Raghavan, and H. Schutze, Introduction to Information Retrieval, Cambridge Univ. Press, 2008.
T. M. Mitchell, Machine Learning, McGraw Hill, 1997.
P.-N.Tan, M. Steinbach, and V. Kumar, Introduction to Data Mining, Addison-Wesley, 2006. ISBN: 0-321-32136-7
关键演讲
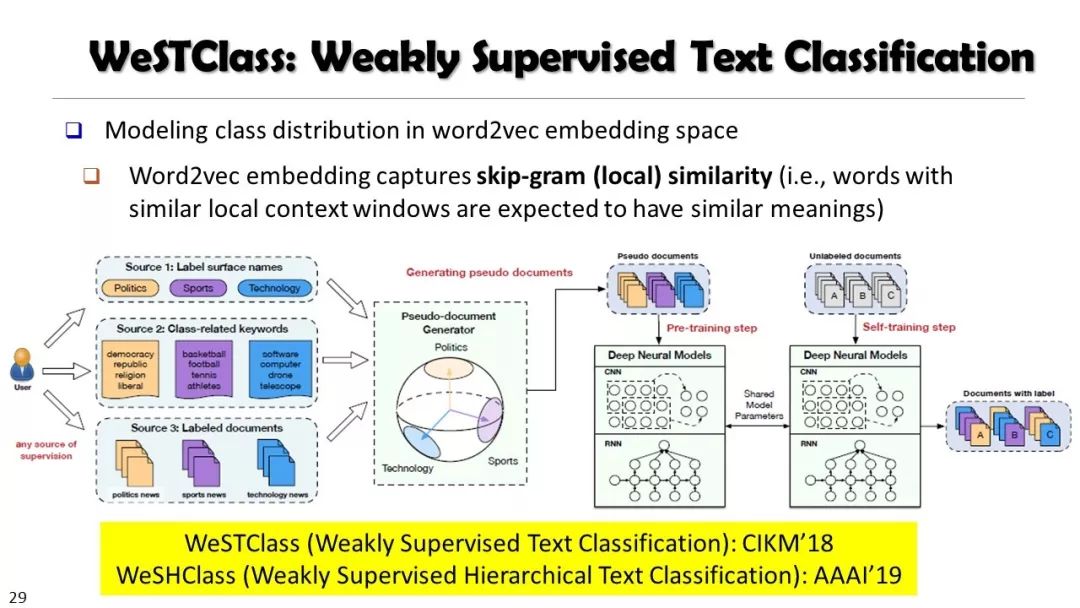
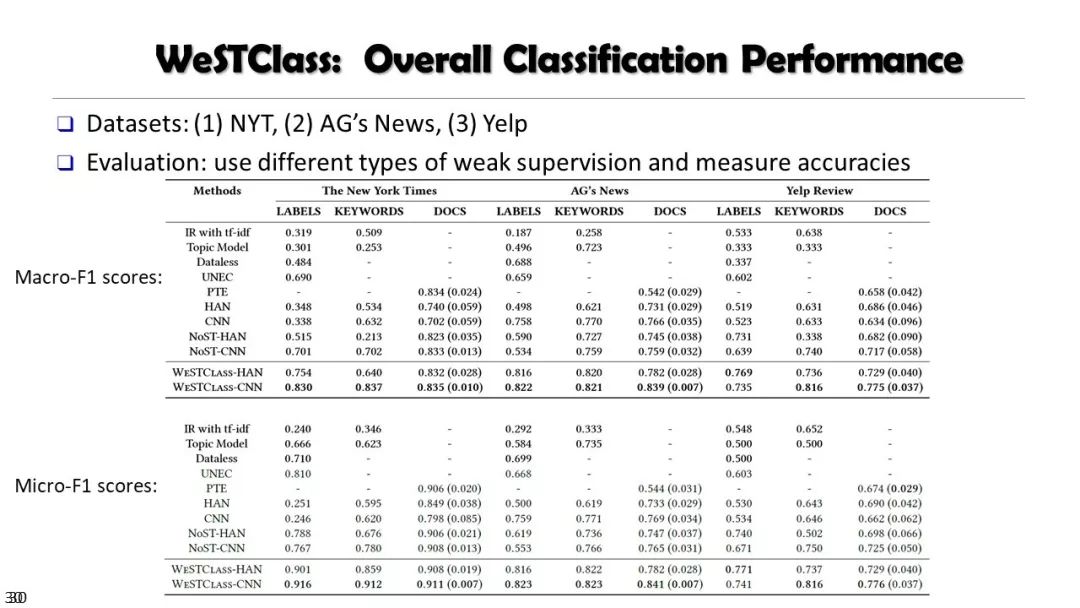
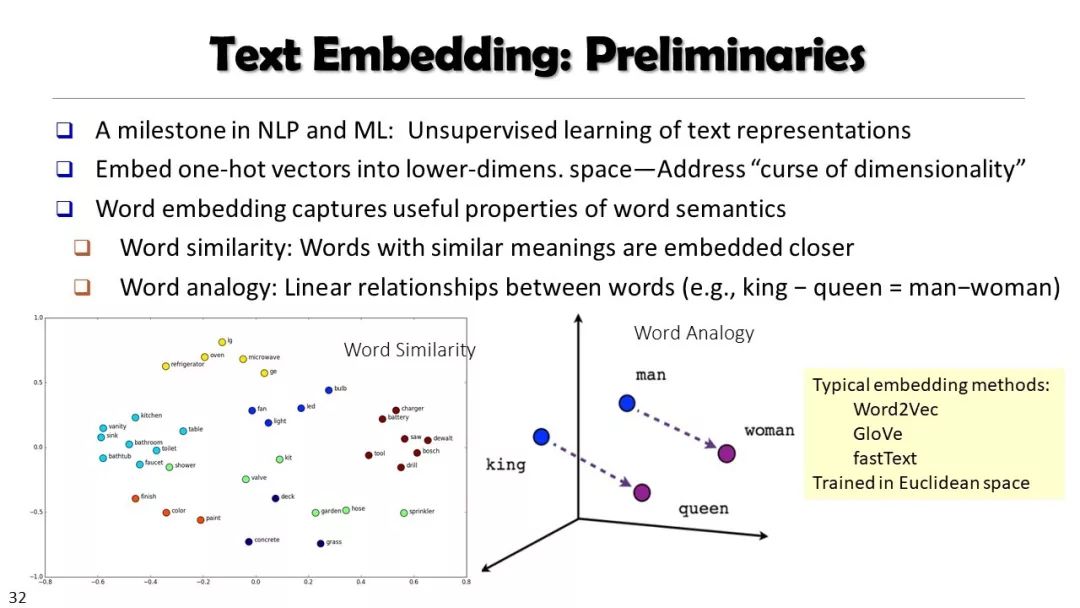
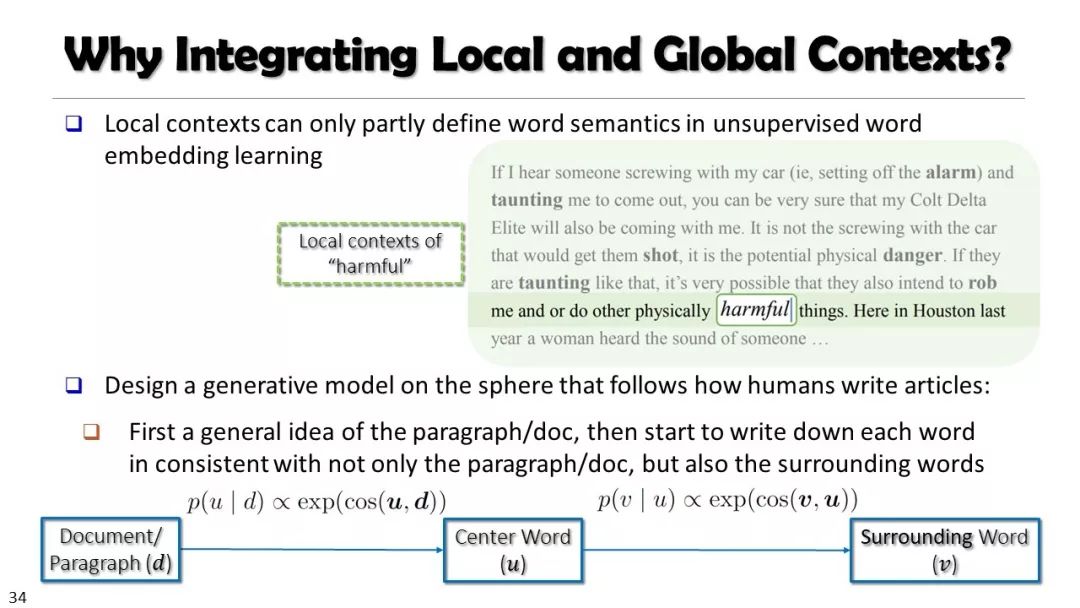
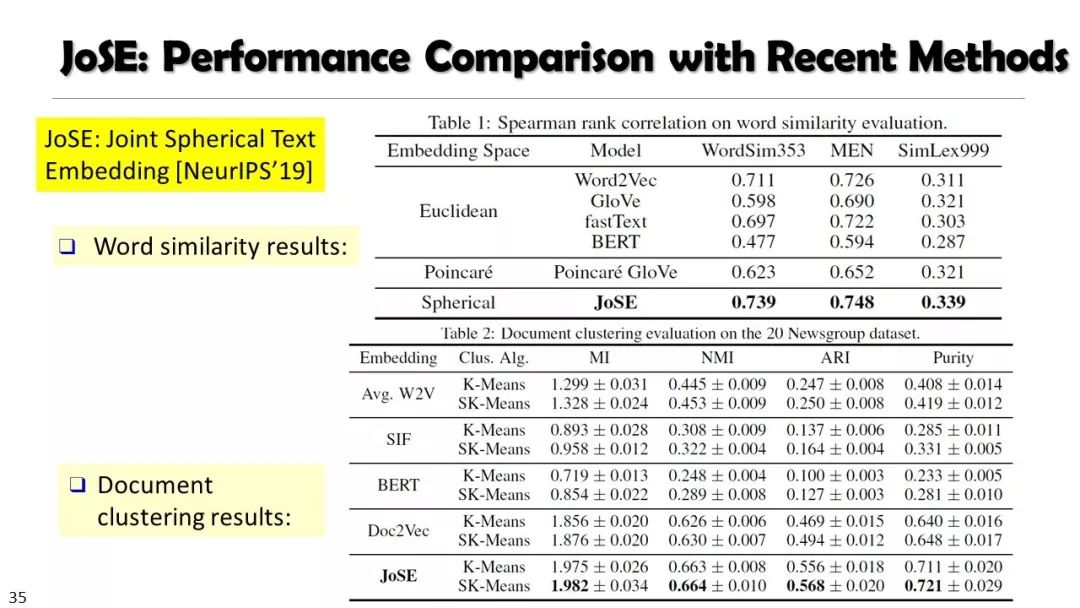
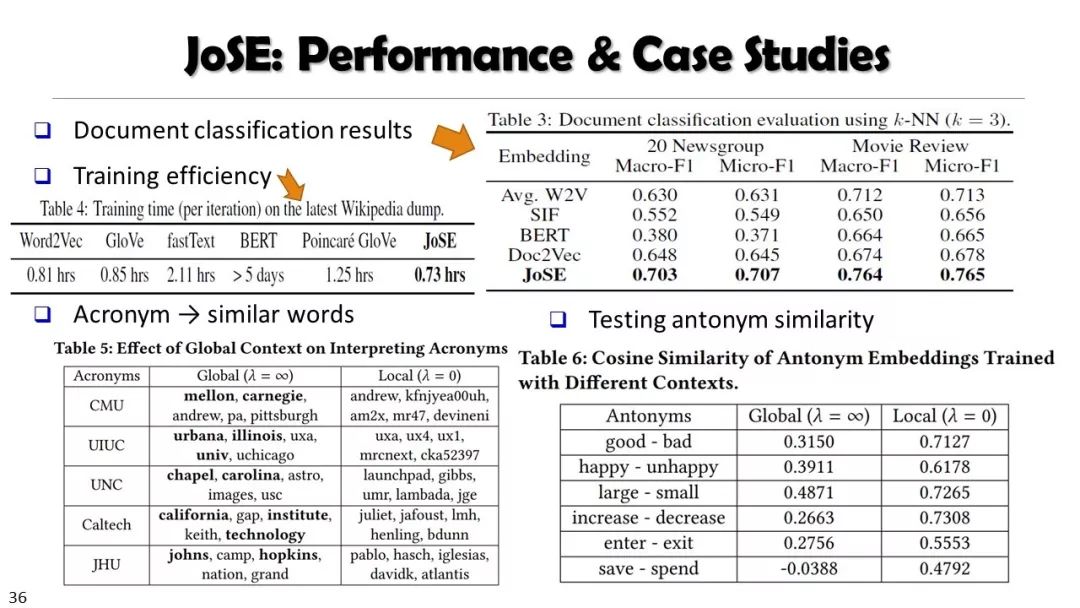
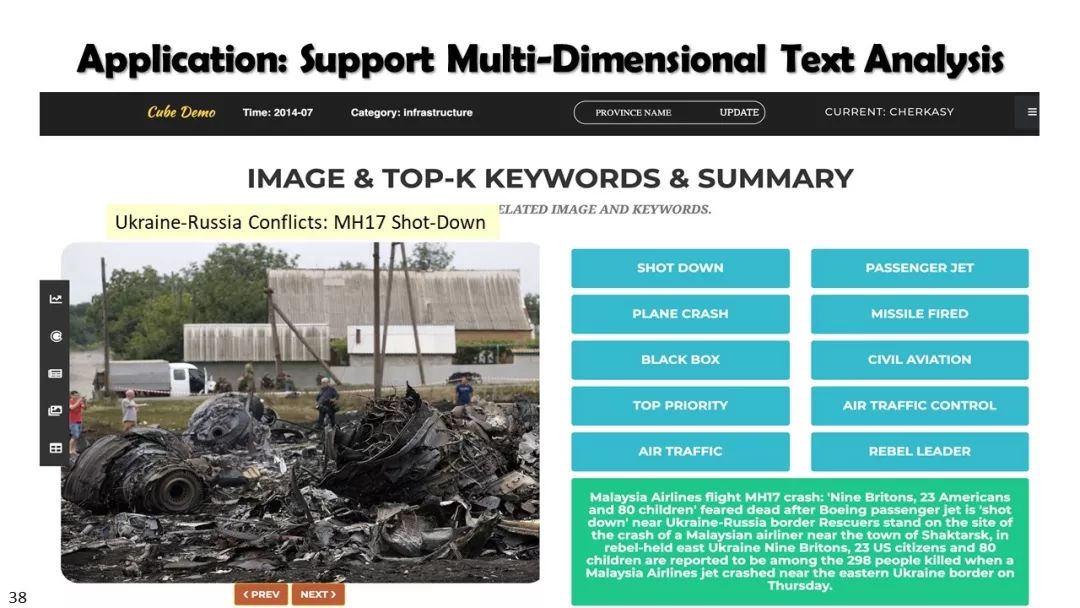
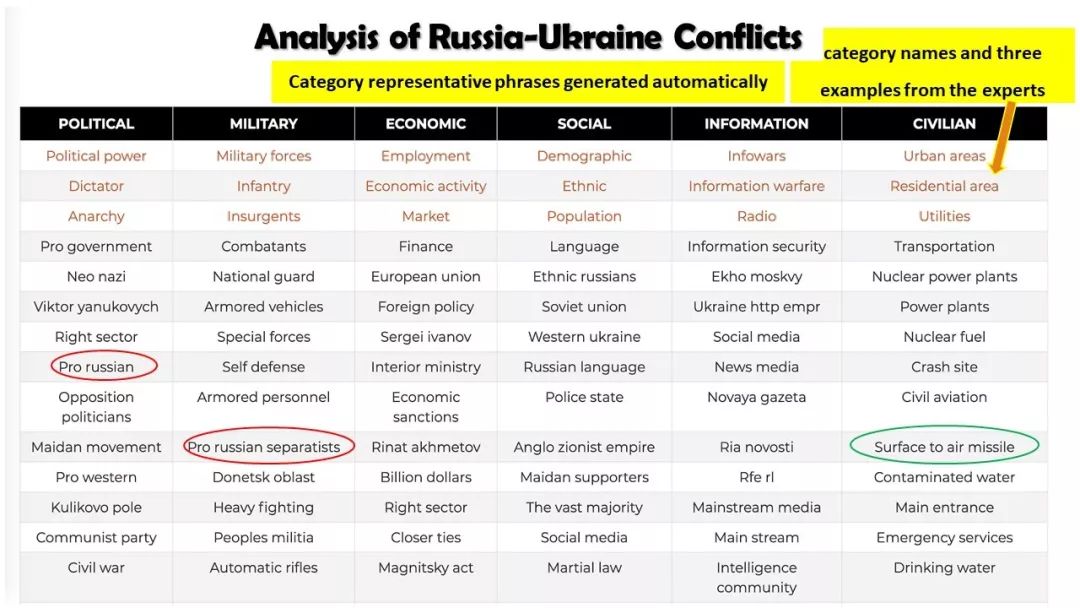
从非结构化文本到知识立方TextCube:自动化构建和多维探索

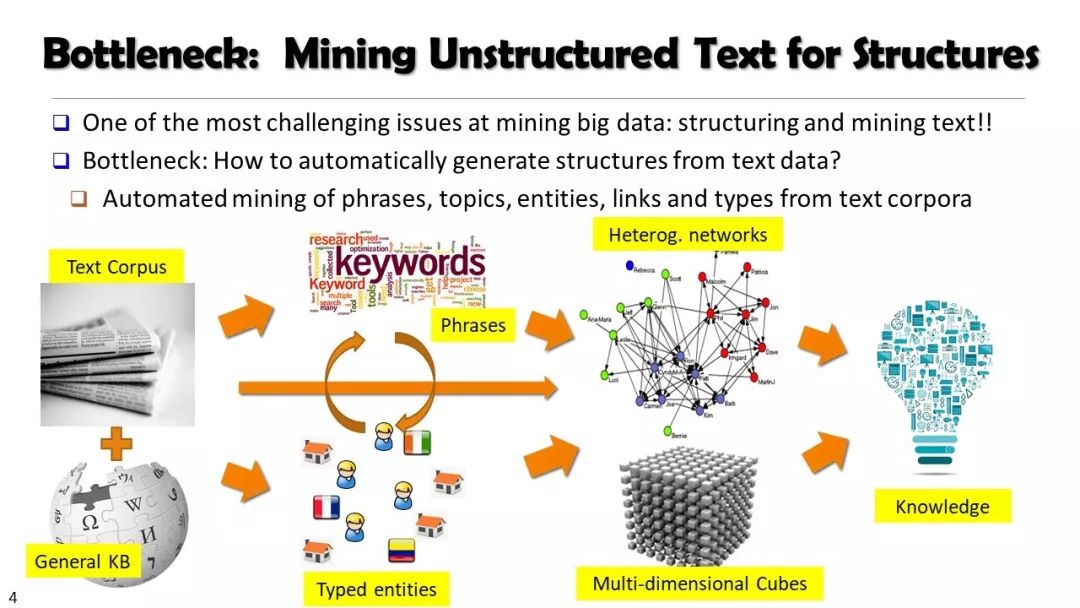
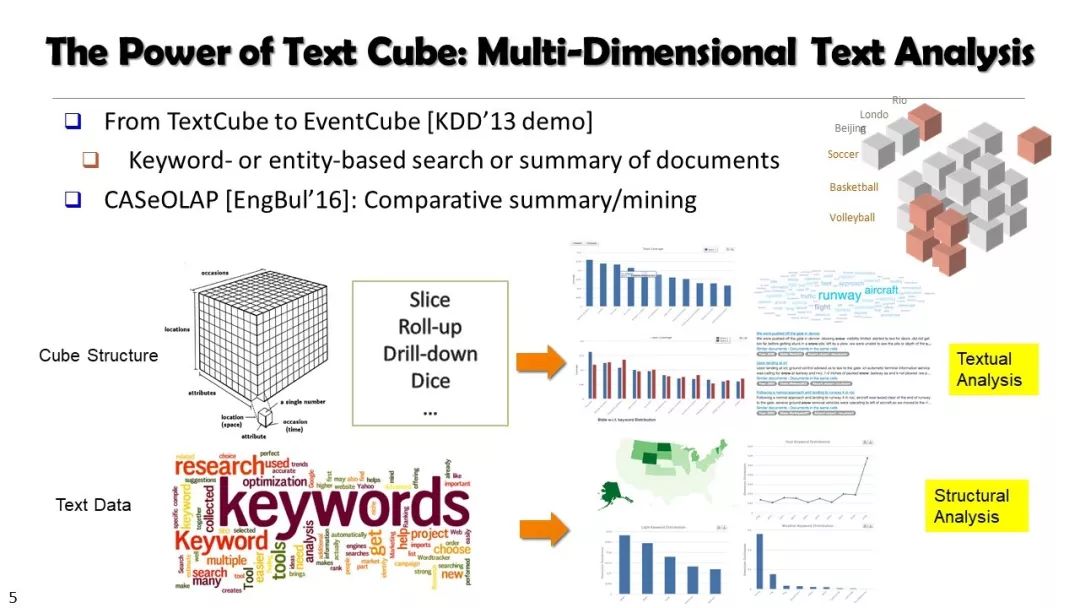
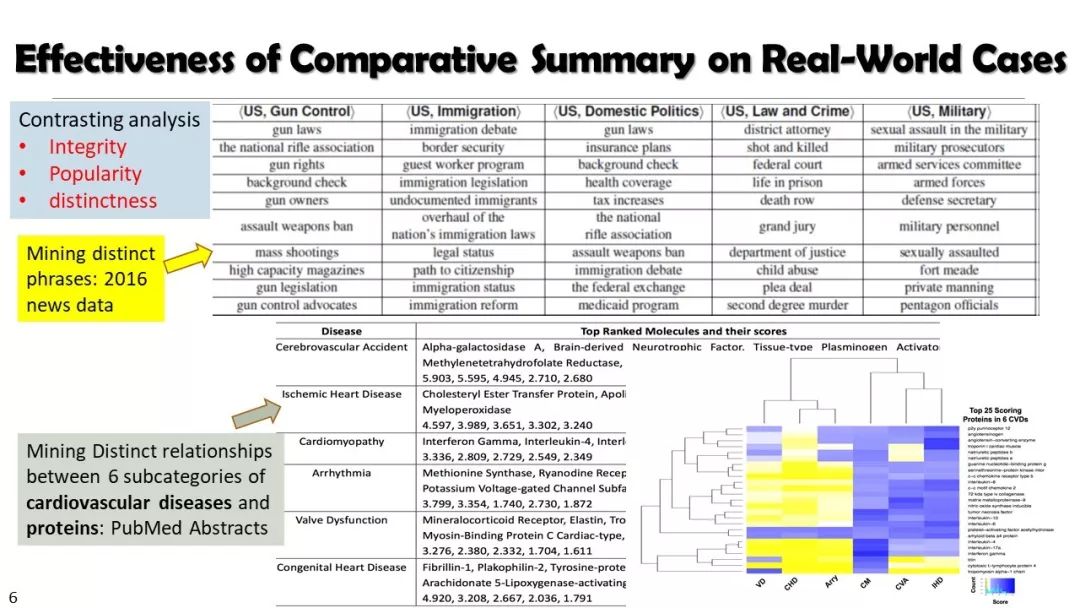
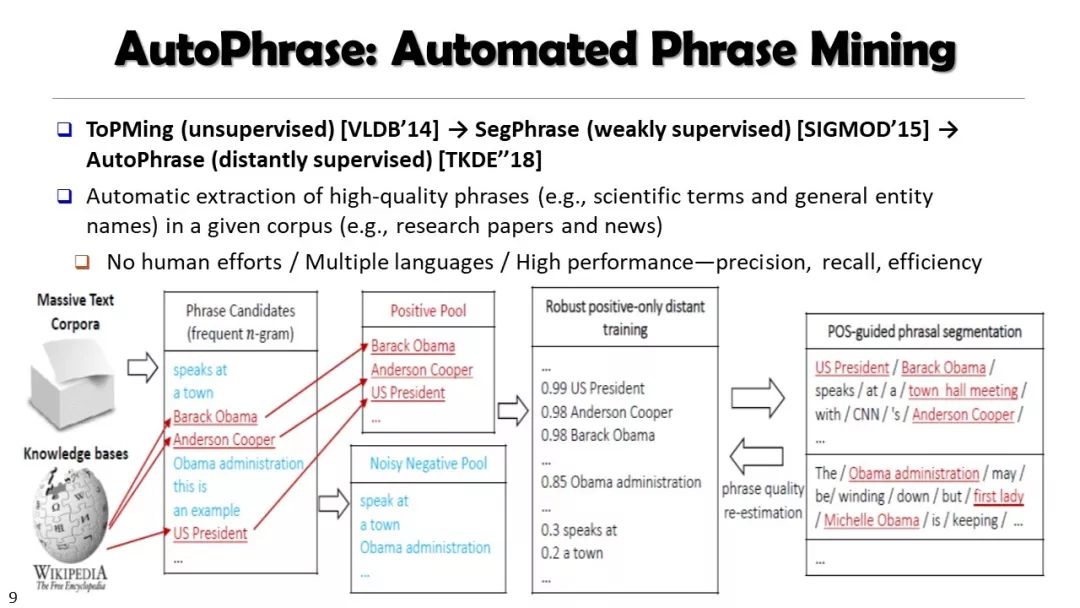
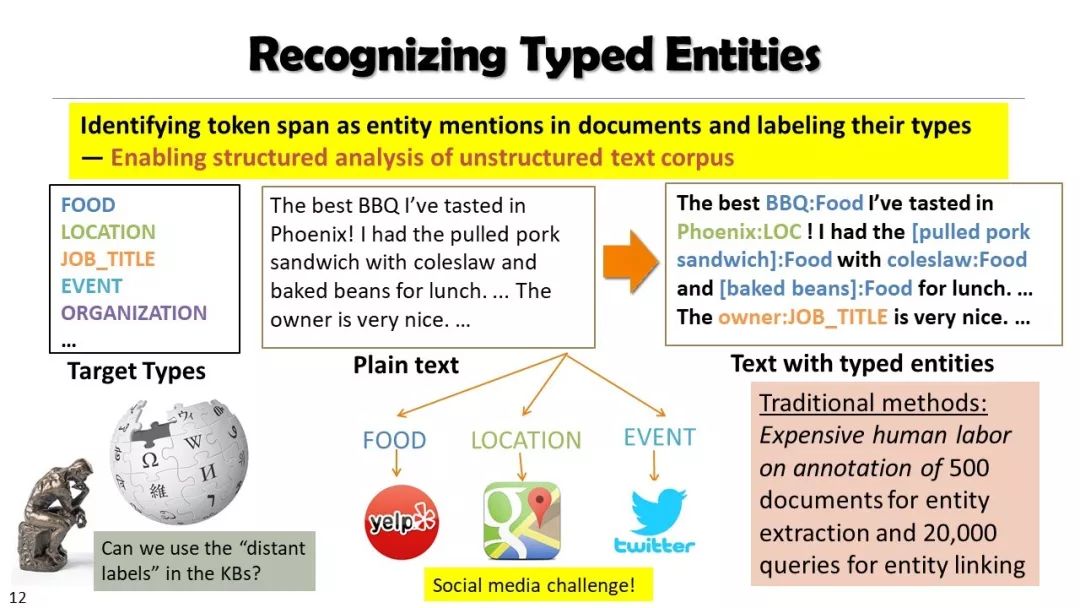
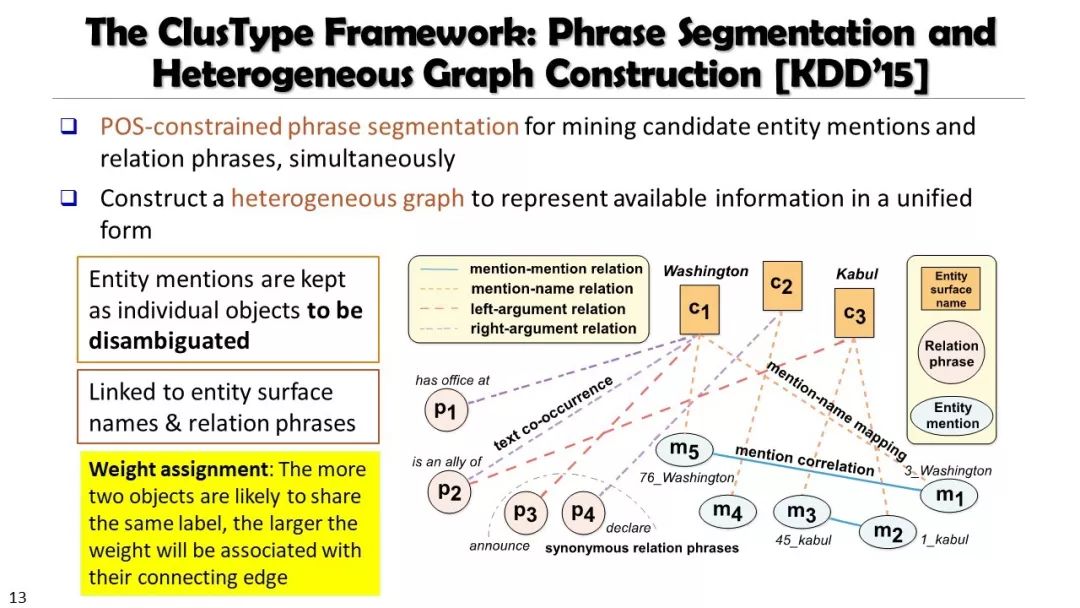
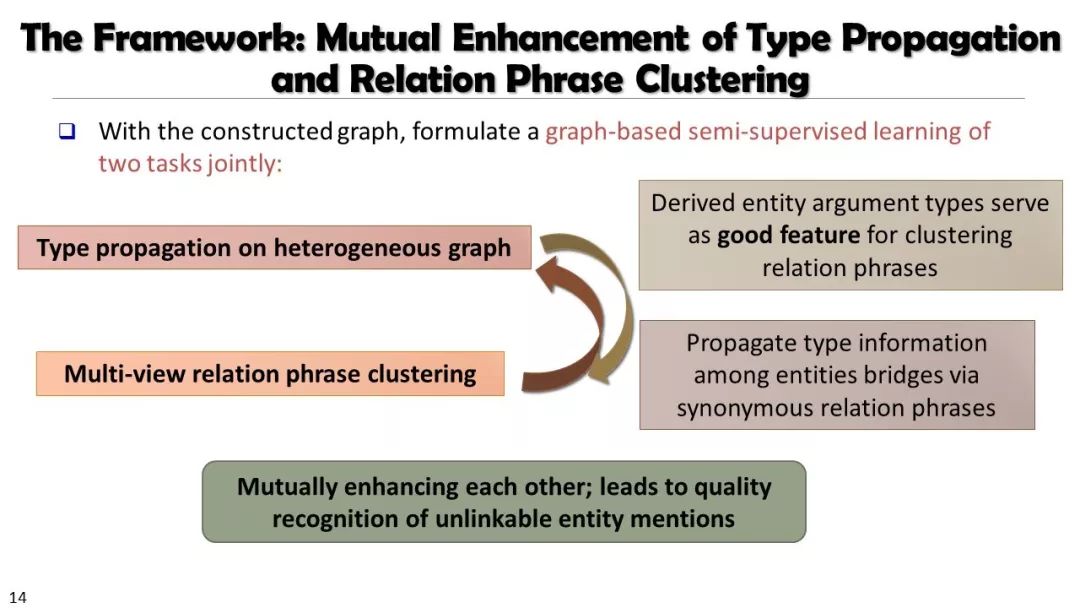
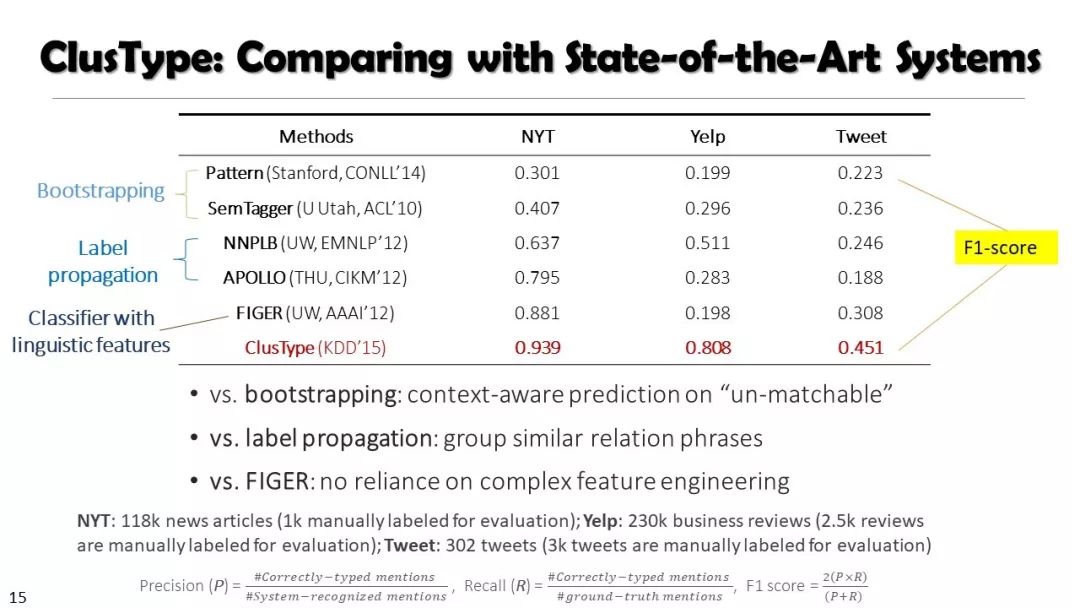
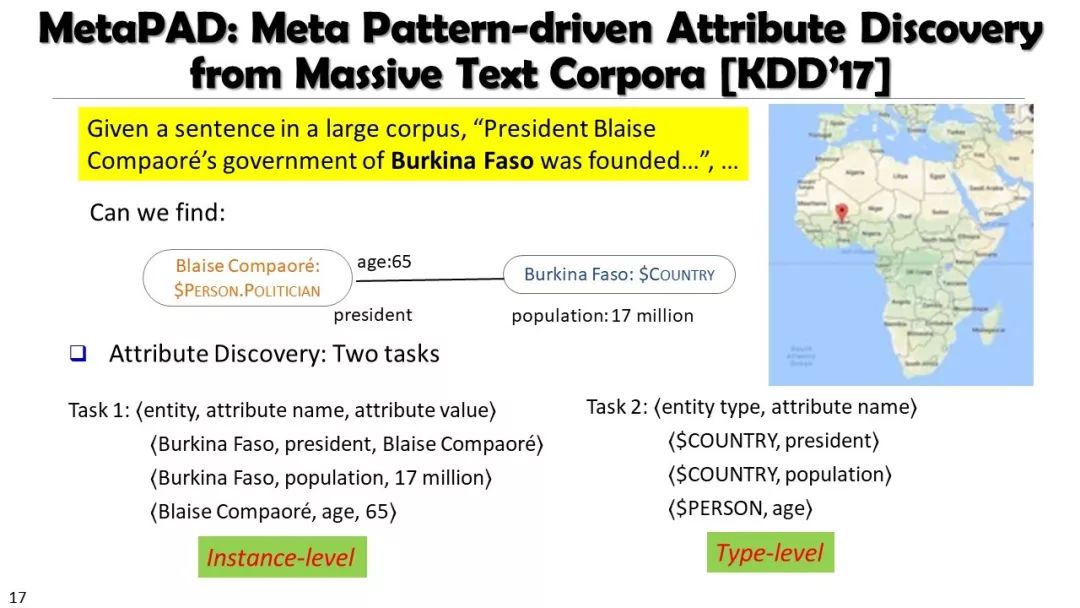
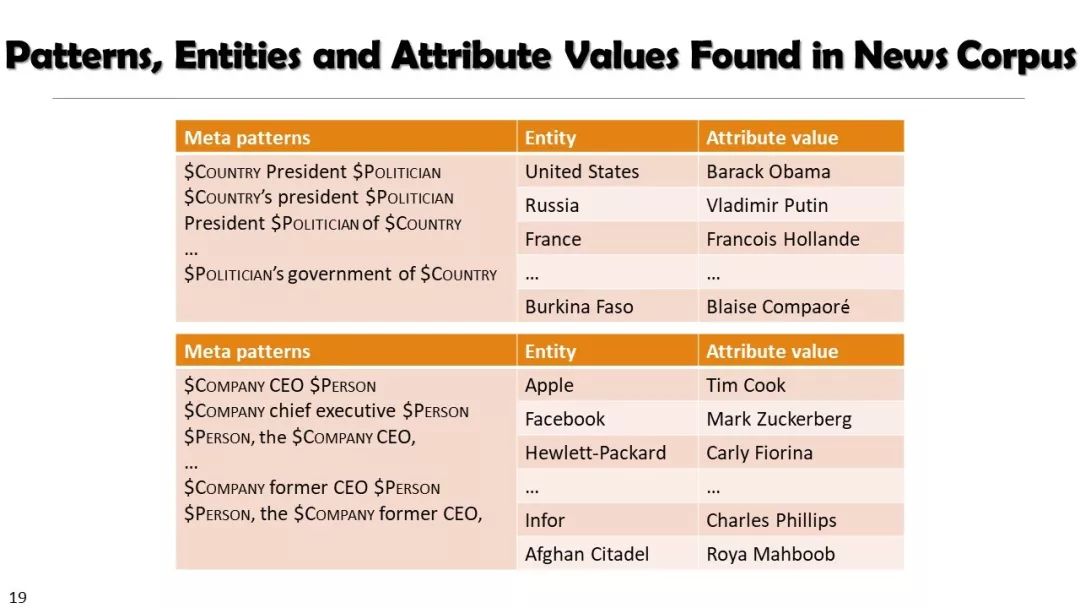
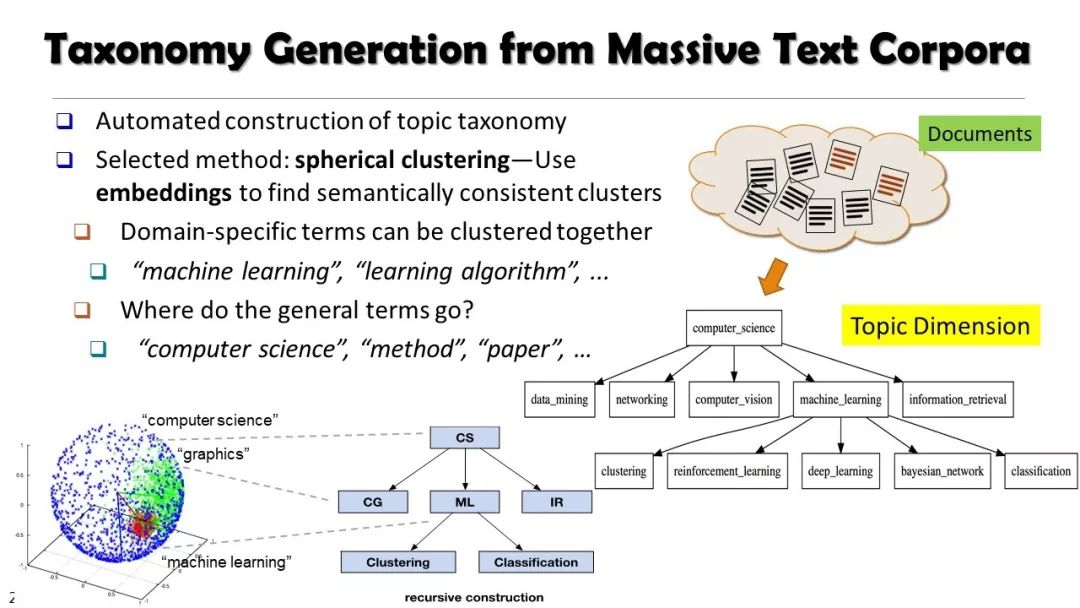
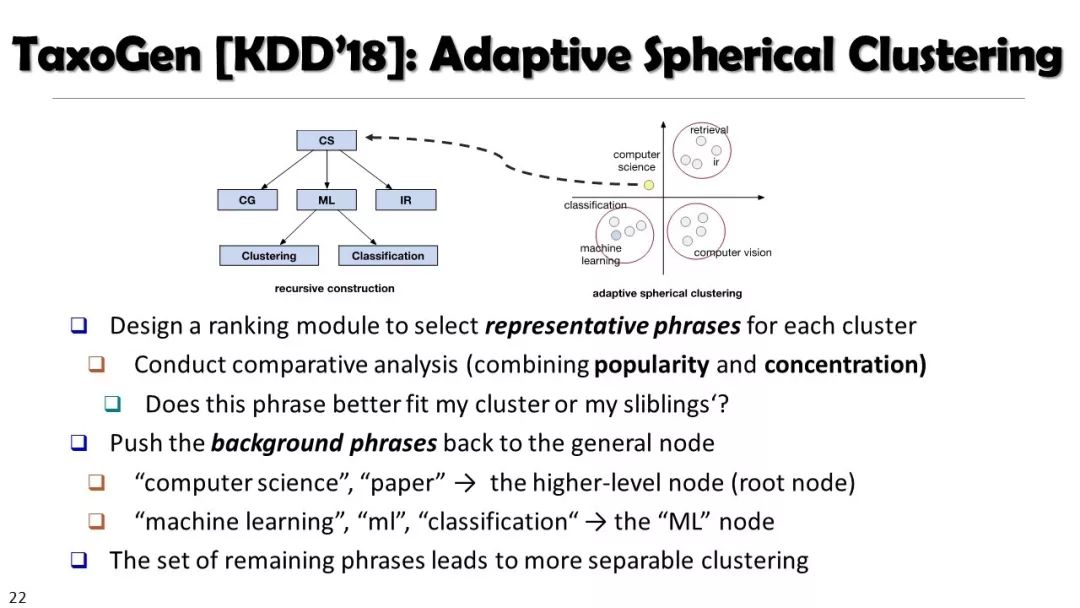
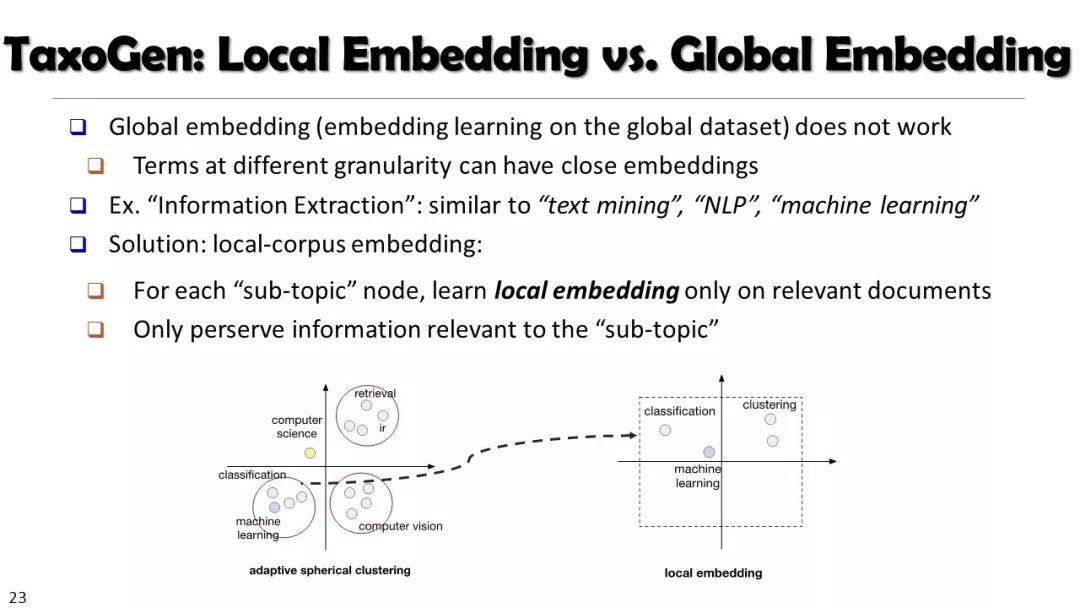
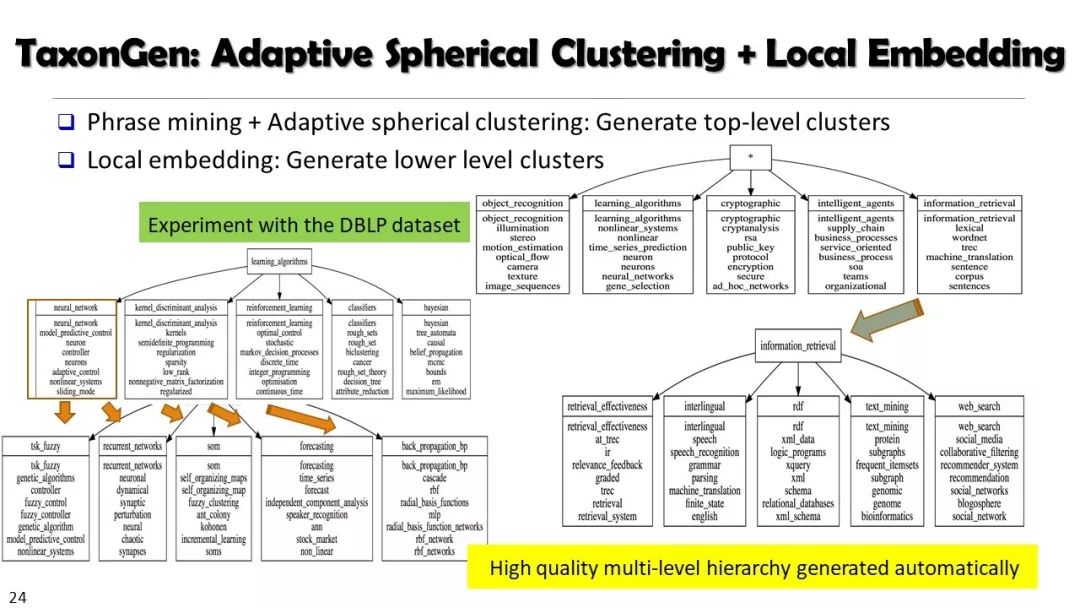
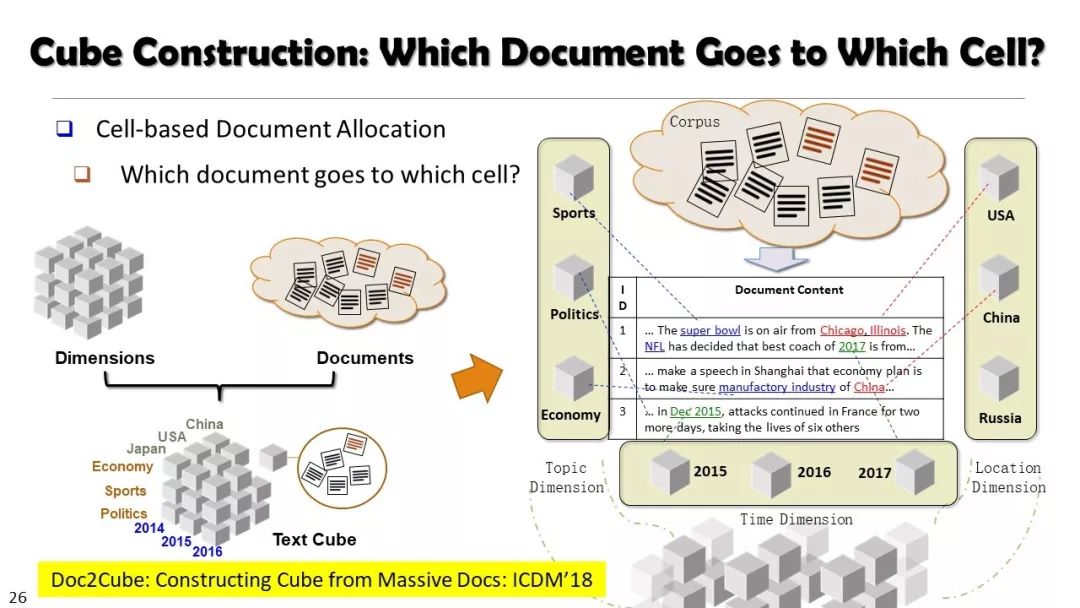
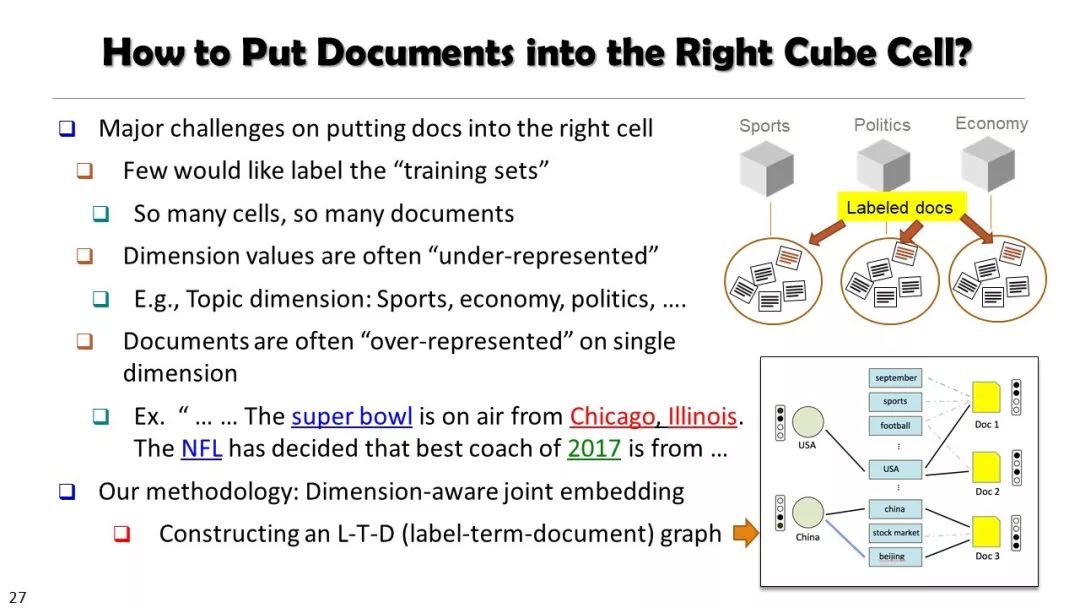
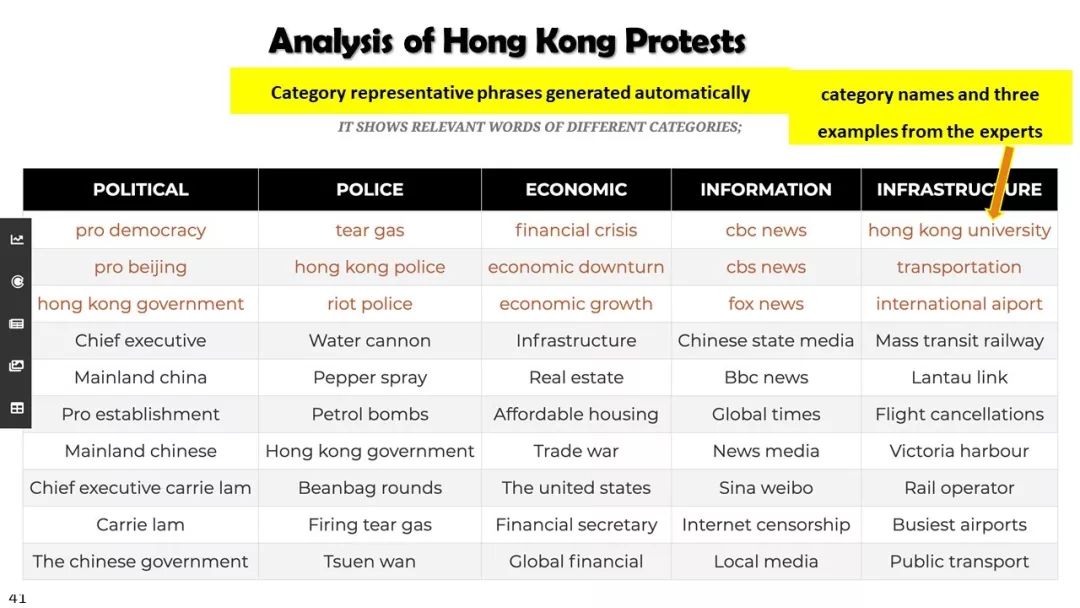
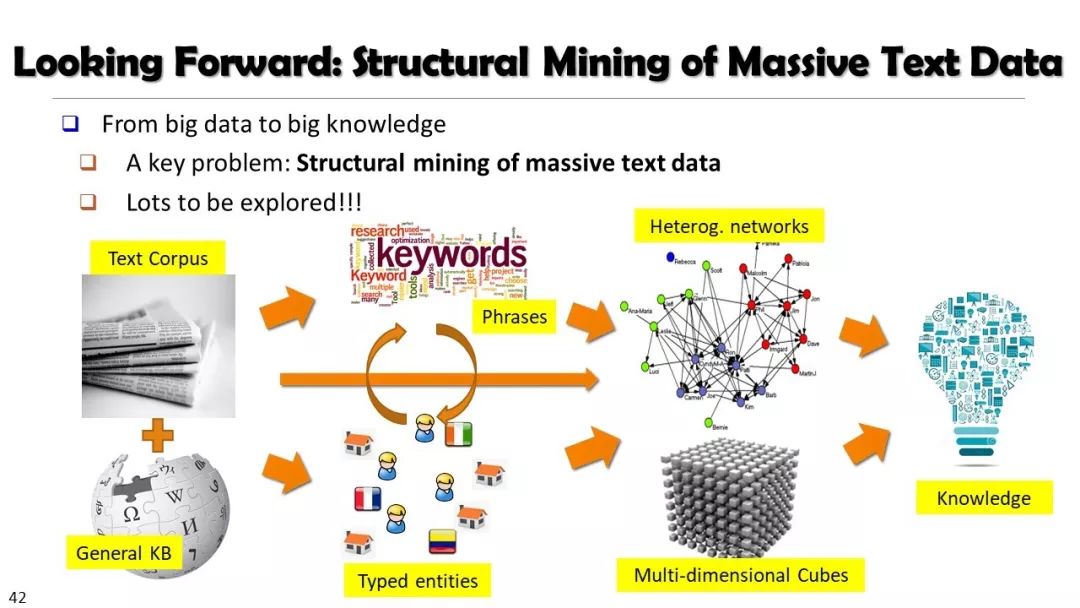
现实世界的大数据以自然语言文本的形式,在很大程度上是非结构化的、相互关联的、动态的。将如此庞大的非结构化数据转换为结构化知识是非常必要的。许多研究人员依赖于劳动密集型的标记和管理来从这些数据中提取知识,这可能是不可扩展的,特别是考虑到许多文本语料库是高度动态的和特定于域的。我们认为,大量的文本数据本身可能揭示了大量隐藏的模式、结构和知识。基于领域无关和领域相关的知识库,我们探索海量数据本身将非结构化数据转化为结构化知识的能力。通过将大量的文本文档组织成多维文本数据集,可以有效地提取和使用结构化的知识。在这次演讲中,我们介绍了一组最近开发的用于这种探索的方法,包括挖掘质量短语、实体识别和键入、多面分类构造以及多维文本立方体的构造和探索。结果表明,数据驱动方法是将海量文本数据转化为结构化知识的一个有前途的方向。


















便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复"textcube” 获取《从非结构化文本到知识立方TextCube:自动化构建和多维探索》专知资源链接索引~






