中文自动转SQL,准确率高达92%,这位Kaggle大师刷新世界纪录丨GitHub
郭一璞 发自 南大仙林
量子位 报道 | 公众号 QbitAI
在追一科技主办的首届中文NL2SQL挑战赛上,又一项超越国外水平的NLP研究成果诞生了。
在NL2SQL这项任务上,比赛中的最佳成绩达到了92.19%的准确率,超过英文NL2SQL数据集WikiSQL目前91.8%的最高成绩。
达成这一成绩的队伍的名字很有野心,名叫“不上90不改名字”,团队成员包括来自国防科技大学的博士张啸宇、硕士赛斌,来自昂钛客AI的王苏宏,他们拿下了本届比赛的冠军,抱走了8万奖金。

冠军团队从来自CMU、北大、清华、上交、南大、中科大等多所高校和移动、平安、搜狗等公司的1457支参赛队伍中脱颖而出,超过92%的成绩,让比赛评委、复旦大学教授肖仰华惊喜的说:“结果完全超出预期”。
而另一位评委、比赛主办方追一科技的CTO刘云峰说,该任务的准确率从比赛初期最好成绩60%多提升到超过92.19%的水平,提升幅度超出了他们原本的想象。
而且由于本次比赛用到的中文数据集难度比WikiSQL英文数据集要高,证明在同样设定下,冠军团队的方案已经超过了国外机构最佳算法(state-of-the-art)在中文任务上的表现。
NL2SQL最佳方法揭秘
NL2SQL,也就是把自然语言“翻译”成机器能理解的SQL语句,在人机交互中有巨大的价值,这样的成绩意味着,92.19%的情况下,你说的话都能被机器准确的理解,并给到你想要的答案。
那么,既然机器能理解人话,那从纷繁复杂的数据库中找到资料也是更为容易的事情了。
肖仰华教授说,现在阻碍大数据价值变现的最大难题就是访问数据门槛太高,依赖数据库管理员写复杂的SQL,而且考虑到中文的表述更加多样,中文NL2SQL要比英文难很多。

△ 肖仰华教授
因此,解决了从中文人类语言到SQL这种计算机语言的转化问题,那些和你对话的AI系统们,就会变得更“聪明”,更容易理解你的问题并找到答案,App里的智能客服、家里的智能音箱们一问三不知的情况也会少很多。
针对中文NL2SQL的问题,冠军团队的张啸宇在比赛答辩中揭秘了实现的方法:

△ 冠军队队长张啸宇
WikiSQL排行榜上的第一名、来自微软Dynamics 365团队的X-SQL有一些问题,模型框架不完全适配,在value抽取上colume特征不显著,容易抽取混乱。
针对这些问题,冠军团队提出了M-SQL,将原本X-SQL的6个子任务改为8个子任务,并且增加三个子模型,S-num、Value抽取、Value匹配,一次性将query中含有的所有Value抽取出来。
之后进行了一些细节提升,比如在数据预处理方面,将数据、年份、单位、日期、同义词进行修正,统一query的范式;在query信息表达方面,用XLS标记替换CLS标记,这样在线下验证集上准确率提高了0.3个百分点。
用到的预训练模型,则是哈工大发布的BERT-wwm-ext模型。
最终的成果,张啸宇觉得非常满意:“我觉得机器转的比我好,大言不惭的说,已经超过了人类的水平。”
冠军团队
“不上90不改名字”队伍的队长张啸宇是一名国防生,也是一位竞赛热爱者,专注NLP领域。他在2018年莱斯杯军事阅读理解挑战赛上获得第二名;在2019年的Kaggle PetFinder比赛上获得金牌,现在是榜上有名的Kaggle Master了。
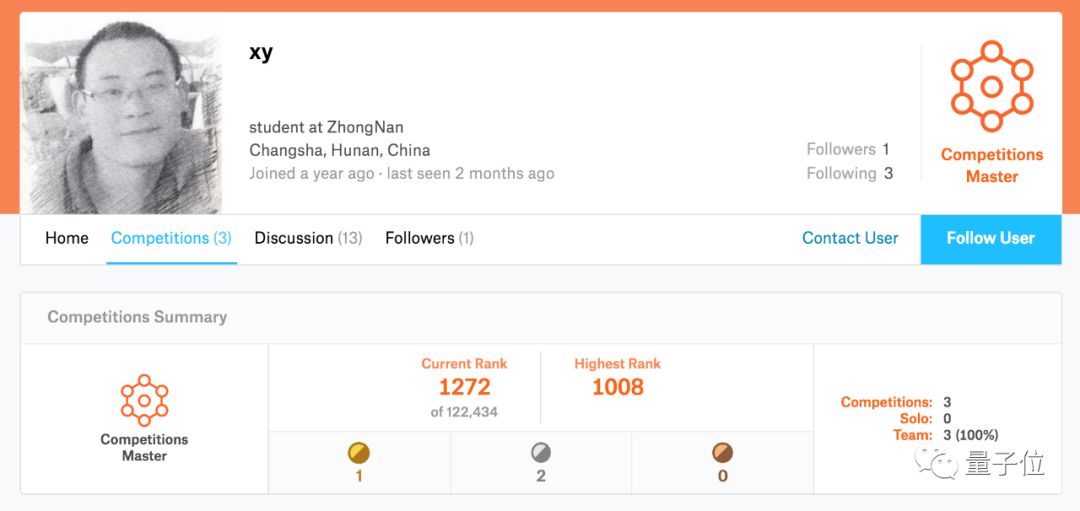
另一位队员赛斌则是他在国防科大的同学,王苏宏则是他在Kaggle社区结识的一位队友,目前也是Kaggle排行榜上前1000名的用户。
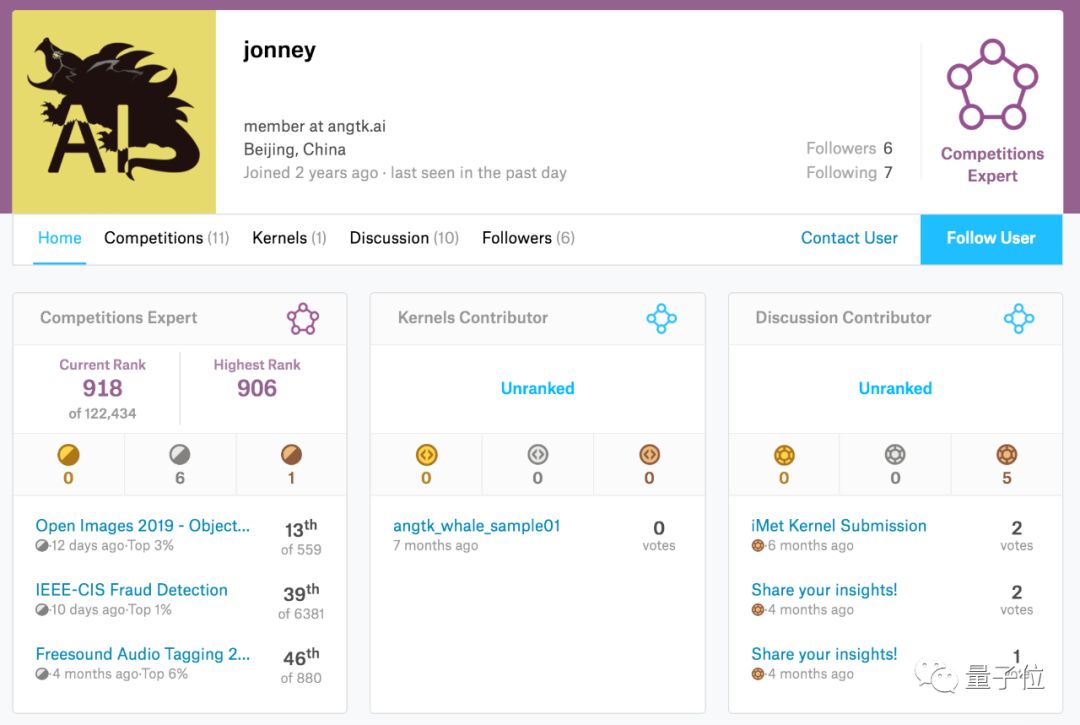
虽然取得了冠军,不过这个团队筹备比赛的时间却比其他队伍晚了一些,他们开始准备的时候,其他团队已经进行了两个星期。
剩下的时间只有一个月了。在这一个月的准备时间里,三人每天都在线上协同商量方案,平均下来基本每天都要工作五六个小时。
对于第一名的成绩,他们感到毫不意外。毕竟在排行榜上已经是第一名,准确度也在这项任务上实现了业界领先,夺得第一当之无愧。
最后,关于比赛的经验,张啸宇总结地非常简单:多敲代码,多看paper。
帮技术的“锤子”,找场景的“钉子”
追一科技总部在深圳,另外在北京、上海、南京、香港、新加坡、白俄罗斯也有研发团队或分公司。
成立3年来,追一已经完成了来自招商局资本、创新工场、晨兴资本、高榕资本、纪源资本的4轮投资,总计融资额7000万美元,招商银行信用卡、中国移动、南方电网、中国人保、腾讯都是追一的客户。
从融资规模上来看,可以说这家腾讯系的AI公司已经是 国内NLP领域的领头羊了。
技术方面,追一在各项NLP任务上都有所突破,拿到了CoQA、CMRC2018 中文机器阅读理解等挑战的冠军。
而在NL2SQL这个任务上,曾经在腾讯达到T4职级的刘云峰说,中文NL2SQL在比赛之前只有追一和微软两家,通过这场比赛,如果能达到众人拾柴火焰高的目的,就可以将这项技术推广出去了:
“客户这边有一个钉子,但是不知道用什么锤子来砸;但是我们这些搞AI的公司有一个锤子,不知道去哪里找钉子。通过这个比赛我们可以很好地把钉子和锤子匹配在一起,给技术找到落地的场景。”
从NLP到计算机视觉
值得注意的是,本次比赛虽说是在NLP领域的赛事,但仍然吸引了不少计算机视觉方面的研究者参赛,闯入决赛的队伍“大佬带我飞”中的两名成员就是CV方面的研究生。

△ 追一科技CTO刘云峰
评委追一科技CTO刘云峰认为,在工业落地时,现在越来越呈现出多模态融合的趋势,视觉和NLP结合的越来越多,需要同时处理多种信号,人机交互的时候也不仅仅用到NLP方面的技术,也需要用到视觉方面的技术,追一科技作为一家NLP公司,本身也有视觉、语音方面的技术团队。
“AI公司主要做企业服务,一个企业不会只要一个方向(的技术),他同时要NLP、视觉的时候不会找两家公司,因为他自己没法把两个技术融合在一起。”
因此刘云峰判断,未来头部AI公司一定是全栈AI公司,虽然会有最拿手的技术,但不会只布局一个领域的技术。
最后,本届比赛的数据集之后也会公开,或许这会是NLP领域下一个竞相角逐的高地。
传送门
冠军团队方案:
https://github.com/nudtnlp/tianchi-nl2sql-top1
参考资料:
https://tianchi.aliyun.com/competition/entrance/231716/introduction
https://github.com/salesforce/WikiSQL
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
大会启幕!预见智能科技新未来
量子位MEET 2020智能未来大会启幕,将携手优秀AI企业、杰出科研人员呈现一场高质量行业盛会!详情可点击图片:

2019中国人工智能年度评选启幕,将评选领航企业、商业突破人物、最具创新力产品3大奖项,并于MEET 2020大会揭榜,欢迎优秀的AI公司扫码报名!


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !




