95后达摩院实习生击败微软,打破NLP最难任务世界纪录

新智元报道
新智元报道
编辑:金磊,元子
【新智元导读】阿里AI在常识QA领域的权威数据集CommonsenseQA上刷新世界纪录,超过微软取得第一名,显著提升AI的常识推理能力。而这项技术,是一名叫做叶志秀的95后“实习生”,在达摩院科学家指导下完成的实习成果!来新智元和群,一起讨论。
正所谓长江后浪推前浪,又一个“别人家的孩子多优秀”系列。
最近,一个年轻人火了:95后的实习生在常识QA领域的权威数据CommonsenseQA上刷新了世界纪录!
这位年轻人名叫叶志秀,他的这项工作是在达摩院科学家指导下完成的,并超越了微软,取得了第一名的好成绩。
CommonsenseQA是为了研究基于常识知识的问答而提出的数据集,比此前的SWAG、SQuAD数据集难度更高。目前最流行的语言模型BERT在SWAG、SQuAD上的性能已经接近或超过人类,但在CommonsenseQA上的准确率还远低于人类。
阿里巴巴达摩院语音实验室提出了AMS方法,显著提升BERT模型的常识推理能力。AMS方法使用与BERT相同的模型,仅预训练BERT,在不提升模型计算量的情况下,将CommonsenseQA数据集上的准确率提升了5.5%,达到62.2%。

CommonsenseQA相关论文已在arXiv上发表,并获得NAACL 2019最佳资源论文。
链接:
https://arxiv.org/pdf/1811.00937.pdf

作者:
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant(以色列特拉维夫大学、艾伦人工智能研究所)
摘要:
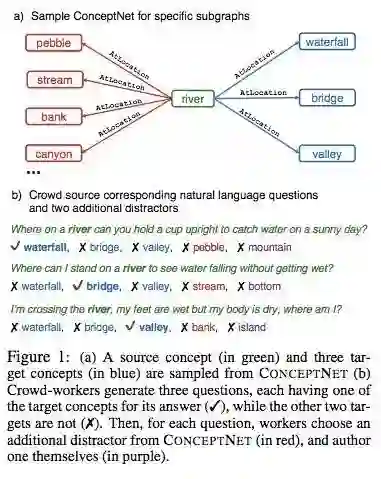
人们通常利用丰富的世界知识和特定语境来回答问题。近期研究主要聚焦于基于关联文档或语境来回答问题,对基础知识几乎没有要求。为了研究使用先验知识的问答,我们提出了一个关于常识问答的新型数据集 CommonsenseQA。为了捕捉关联之外的常识,我们从 ConceptNet (Speer et al., 2017) 中抽取了多个目标概念,它们与某个源概念具备同样的语义关系。
我们让众包工人编写提及源概念的选择题,并区分每个目标概念之间的差别。这鼓励众包工人编写具备复杂语义的问题,而问答这类问题通常需要先验知识。我们通过该步骤创建了 12247 个问题,并用大量强基线模型做实验,证明该新型数据集是有难度的。我们的最优基线基于BERT-large (Devlin et al., 2018),获得了 56% 的准确率,低于人类准确率(89%)。
下图是构建 CommonsenseQA 数据集的过程示例:
自然语言理解(NLP,Natural Language Processing)被誉为人工智能皇冠上的明珠,而常识推理是其中难度最高的任务之一。
我们所谓的常识,指的是与生俱来、毋须特别学习便已经拥有的判断能力,或是众人皆知、无须解释或加以论证的知识。例如:打雷要下雨(磊欧);下雨要打伞(嘞奥)。
虽然在机器翻译、阅读理解等常用NLP任务上,AI的表现已接近人类水平,甚至在某些场景下已经超过人类水平,然而一旦涉及到常识推理方面就成了白痴。比如我们看到行人打着伞就能自然的想到外面可能在下雨;而AI可能会分辨出所有伞的种类,却无法做出“外面在下雨”的推断。
在包含1.2万多个常识问题的CommonsenseQA数据集上,现在已经能够达到56.7%的准确率,依然远低于人类的89%准确率。借用图灵奖获得者Yann LeCun的话,就是“最聪明的AI在常识方面都不如一只猫。”
但好在,如今这位阿里达摩院95后实习生的研究,将AI在常识推理方面的能力,向猫的水平推进了一步!
或许不久的将来,将会出现可以听懂人话的“猫”。就像,加菲一样?👇