![]()
「论文访谈间」是由 PaperWeekly 和中国中文信息学会社会媒体处理专委会(SMP)联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
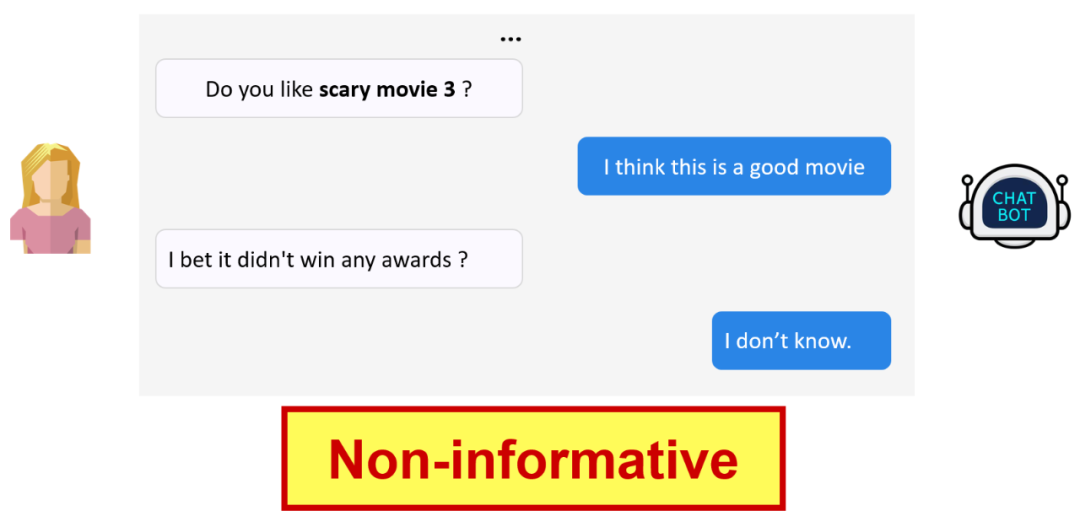
目前,对话系统(Dialogue Systems)已经在工业界和学术界引起普遍关注。序列到序列(Sequence-to-Sequence)模型被广泛使用于相关研究中。但是这类模型倾向于生成低信息量的回复,如图 1 所示。
![]()
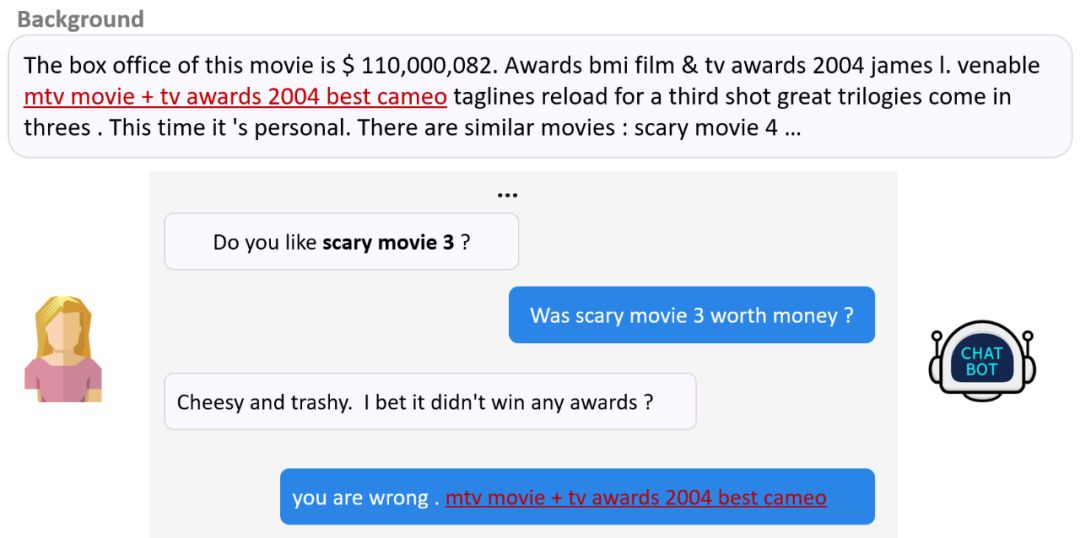
近些年来,有些研究通过改进目标函数或者引入话题信息来尝试解决这一问题,也有研究通过引入背景知识来解决这一问题,我们称之为基于背景知识的对话。如图 2 所示,其任务目标为同时基于外界背景知识与对话上下文,生成自然、高信息量的回复。
![]()
目前,基于背景知识的对话方法可以为两大类:生成式方法和抽取式方法。两类方法各有优缺点。
![]()
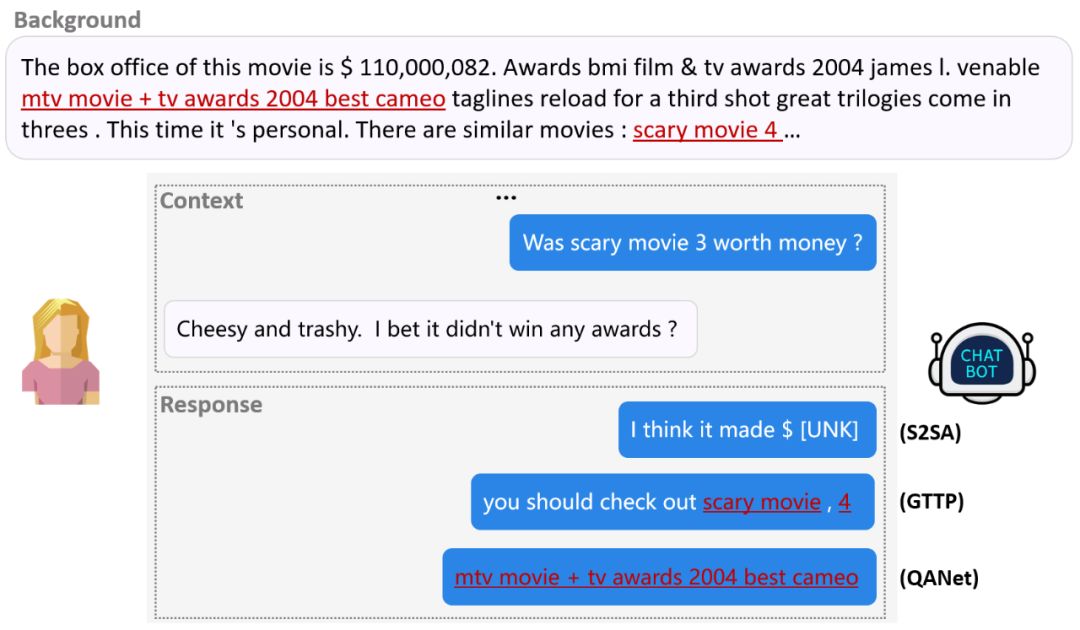
如图 4 所示,生成式方法以每个时间步生成一个词(token by token)的方式生成回复。
图 3 给出 seq2seq+attention (S2SA) 与 seq2seq+copy(GTTP)在这一场景下生成的回复。
我们可以发现此种方法的优点是善于生成流利、自然的回复;缺点是逐词生成的方式容易打碎一个完整的语义单元(scary movie 4 被逗号截断),并且定位正确背景知识的能力不强。
![]()
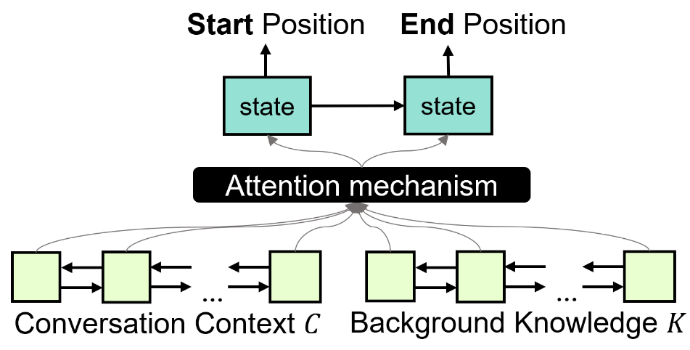
如图 5 所示,抽取式方法直接从背景知识里抽取一个语义单元(span)作为回复。图 3 给出 QANet 在此场景下的回复。可以发现此类方法的优点是定位背景知识准确;缺点是回复生硬,缺乏流利性。
![]()
针对上述研究的局限性,
山东大学的陈竹敏课题组提出参考感知网络,Reference-aware Network (RefNet),其同时结合生成式方法和抽取式方法的优点并规避其糟粕
。
研究发现,RefNet 可以生成高信息量同时又不失流利的回复,并可以在自动评测与人工评测上超过现有的生成式与抽取式方法。
他们的研究成果 RefNet:A Reference-aware Network for Background Based Conversation 被人工智能顶级会议 AAAI-20 以 Oral 论文收录。
![]()
论文标题:RefNet: A Reference-aware Network for Background Based Conversation
论文来源:AAAI 2020
论文链接:https://arxiv.org/abs/1908.06449
代码链接:https://github.com/ChuanMeng/RefNet
![]()
![]()
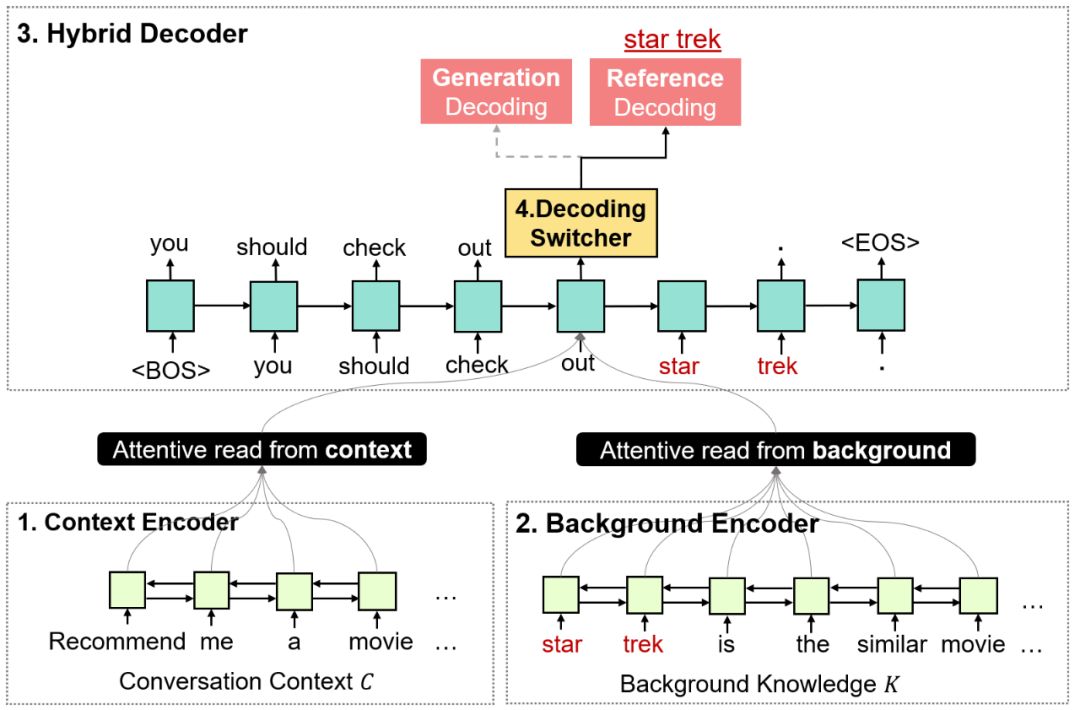
给定对话上下文 C(对话历史)与背景知识 K,RefNet 的任务是生成回复 X。
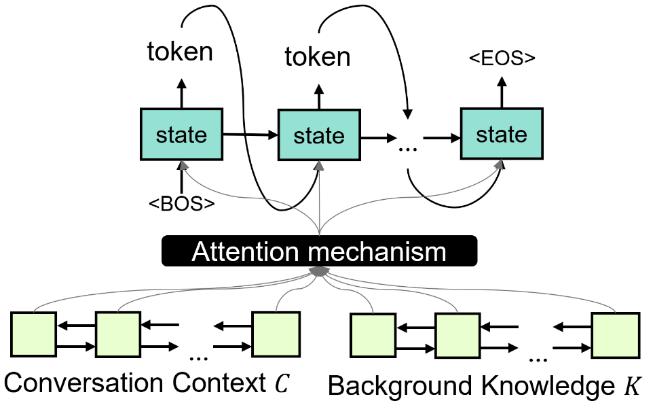
如图 6 所示,RefNet 包含了四个模块,分别为:知识编码器(Background Encoder)、语境编码器(Context Encoder)、解码选择器(Decoding Switcher)、混合解码器(Hybrid Decoder)。
其中,知识编码器、语境编码器分别通过双向循环神经网络把背景知识与对话上下文编码成隐状态表示。之后,二者的隐状态表示会作为混合解码器的输入。
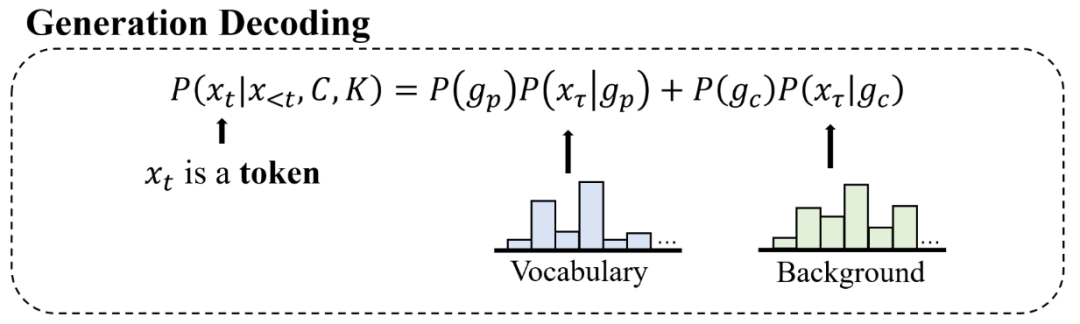
在解码的每个时间步,解码选择器都会在参考解码(Referencing Decoding)与生成解码(GenerationDecoding)之间做出选择;根据解码选择器的决定,混合解码器要么去背景知识中抽取一个完整语义单元(参考解码),要么生成一个词(生成解码)。
此外,在生成解码模型下,解码选择器还将进一步决定具体的生成解码方式,要么执行生成预测解码(从预先定义的词表中预测一个词),要么执行生成拷贝解码(从背景知识中拷贝一个词)。
经过一定数量的解码时间步(每个时间步均执行解码选择器和混合解码器),我们可以得到最终的回复序列。回复序列将由生成解码生成的词与参考解码抽取的语义单元共同按序合成。
我们具体来看解码选择器的实现。
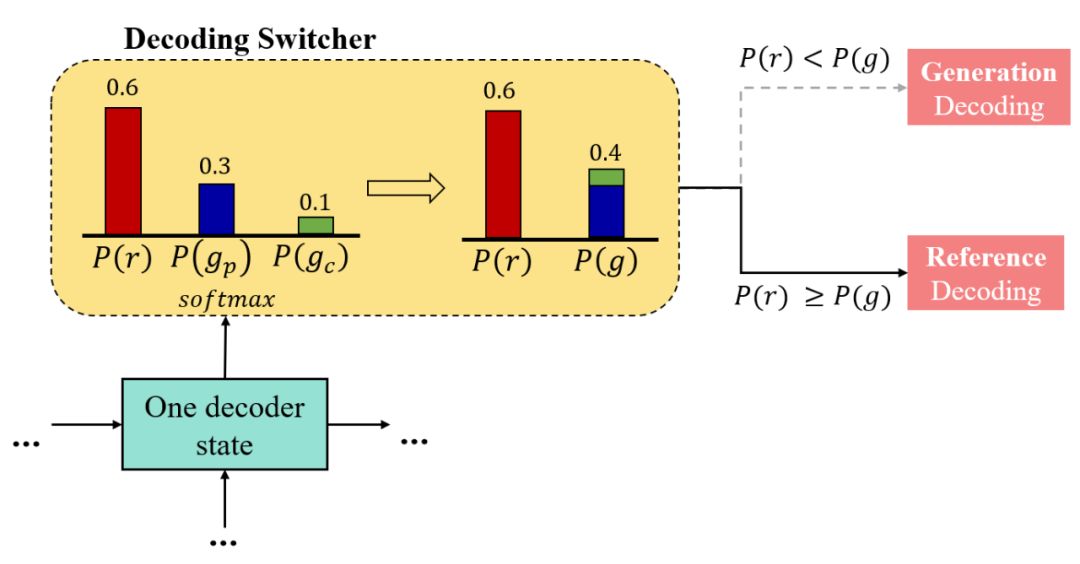
如图
7 所示,在每一个时间步,解码选择器将预测一个在参考解码
r,生成预测解码
和生成拷贝解码
上的概率分布,即
。
我们将生成预测解码概率
和生成拷贝解码概率
加和得到生成解码概率 P(g)。
在训练阶段,我们可得知每个时间步应该执行参考解码还是生成解码,因此可引入一个解码选择器损失函数对解码选择器生成的概率分布进行监督优化。
在推理测试阶段,对于每个时间步,我们首先计算
P(r)
与
,如果
P(r)>=P(g),我们执行参考解码从背景知识中抽取一个语义单元;
如果 P(r)<P(g),我们执行生成解码生成一个词。
![]()
我们再具体来看参考解码与生成解码的具体实现。
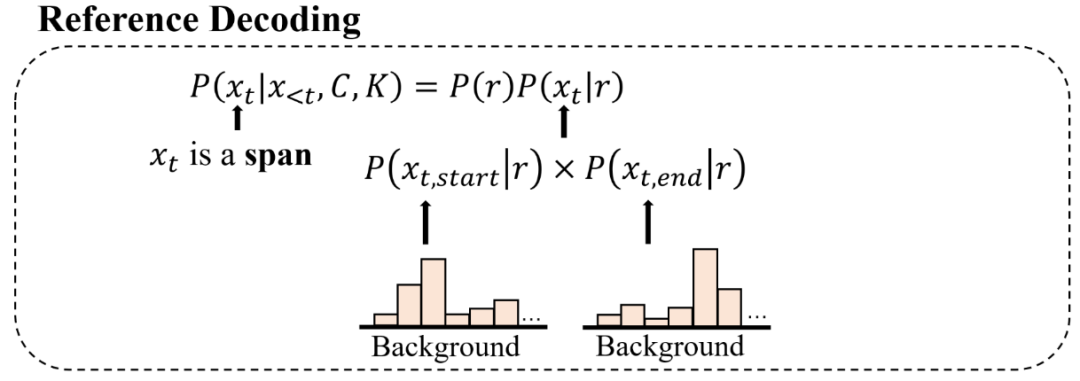
假设当前在时间步 t 要输出
,执行参考解码时,模型将从背景知识中抽取一个语义单元,即
是一个语义单元。
模型将预测
的开始位置
和终止位置
,见图 8。
![]()
▲ 图8. 参考解码
执行生成解码时,模型将生成一个词,即当前输出的
是一个词。
模型将通过生成预测解码(从预先定义的词表中预测一个词)和生成拷贝解码(从背景知识中拷贝一个词)来共同决定
,见图 9。
![]()
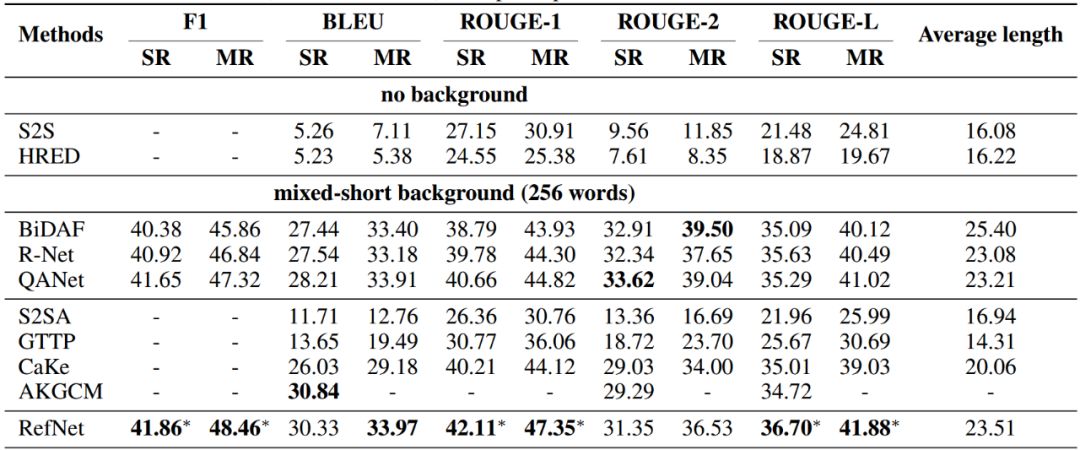
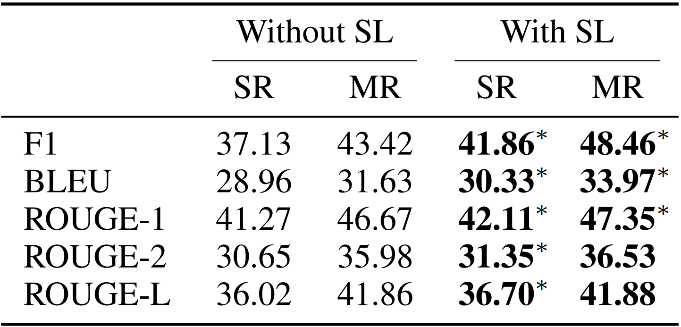
论文在 Holl-E 数据集上与最新的生成式与抽取式基线模型进行了自动指标评测,见图 10。可以发现,除了在 BLEU 指标上与 AKGCM 不相上下以外,RefNet 在所有指标上显著超过了所有生成式模型。其次,RefNet 也在大多数情况下超过了抽取式模型。
![]()
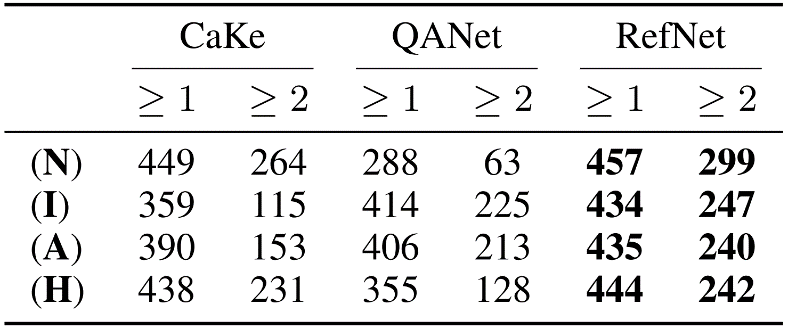
为了进一步增强实验结果的说服力,论文也进行了人工评测,见图 11。论文将 RefNet 与最强的生成式模型CaKe和最强的抽取式模型 QANet 在输出回复的自然性(N)、信息性(N)、合适性(A)和类人性(H)4 个指标上进行评测,见图 11。
实验结果表面,RefNet 在所有指标上超过了两个强有力的基线模型。
有意思的是,RefNet 甚至在自然性(N)上超过了最强的生成模型 CaKe,这说明 RefNet 的解码选择器在每个时间步对于生成和抽取的决策十分得当,使得生成的词和抽取的语义单元以合理、自然的方式组成最终回复。
此外,QANet 虽然在信息性上取得了不错的分数,但是在自然性和类人性上表现最差,这说明仅仅通过抽取的方法远远不能满足对话任务的需要。
![]()
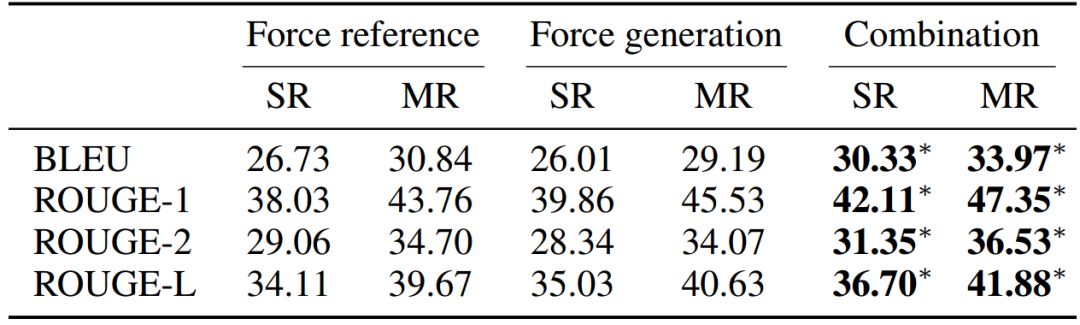
此外,论文还进行了分析实验。首先,论文对比了 RefNet 在只进行生成(Force generation)或者只进行抽取(Force reference)的设置下的实验结果,见图 12。实验结果说明两种模式是互补的,二者结合起来可以进一步提升结果。
此外,RefNet 引入了一个解码选择器损失函数,其对解码选择器的输出分布进行了监督学习以辅助模型在每个时间步对生成与抽取的选择。因此,论文也对比了有无此损失函数的实验结果,见图 13。实验结果表明,额外地监督带来了进一步提升。
![]()
![]()
论文最后比较了 RefNet 与最强的生成式模型 CaKe 与抽取式模型和 QANet 的实际输出样例,见图14。
在这个样例中,RefNet 成功定位并抽取了语义单元“$279,167,575”,并将其与自然的描述“it made”与“at the box office”进行合理地组合构成最终的回复。QANet 抽取了正确的语义单元,但是回复内容非常生硬;Cake 定位了错误的背景知识。
![]()
总的来说,这一工作提出的 RefNet,其同时结合了生成式与抽取式方法的精华,通过解码选择器与混合解码器协调并实现生成与抽取。
实验证明 RefNet可以生成高信息量同时又不失流利的回复。RefNet 的一个限制是需要提前进行语义单元(span)的标注来实现监督学习。
所以对于未来的工作,设计一种弱监督的学习方式去自动学习语义单元的抽取很有必要,这将方便将 RefNet 移植到其他数据集与任务。
孟川,山东大学计算机科学与技术学院研究生。研究方向为基于知识的人机对话。目前担任 COLING 国际学术会议程序委员会委员。
任鹏杰,荷兰阿姆斯特丹大学博士后研究员,2018年博士毕业于山东大学。主要研究方向为自然语言处理和推荐系统,已经在 TKDE, TOIS, SIGIR, WWW, AAAI, CIKM, COLING, ECAI 计算机学报等发表论文 40 余篇。
陈竹敏,山东大学计算机科学与技术学院教授。主要研究方向为信息检索和自然语言处理,承担国家自然科学基金等项目 13 项,在 SIGIR, WWW, AAAI, CIKM, COLING, WSDM, ECAI 等国际会议,及 TKDE, TOIS, JASIST, IRJ 计算机学报等国际期刊上发表论文 80 余篇。
Christof Monz,荷兰阿姆斯特丹大学副教授,主要研究方向为自然语言处理,目前担任荷兰阿姆斯特丹大学语言技术实验室主任,已经发表论文 100 余篇。
马军,山东大学计算机科学与技术学院教授。中国中文信息学会理事,中国计算机学会理论专委会理事,大数据专委会委员,社会媒体处理专委会常务委员,中文信息检索专委会委员,中文信息技术专委会委员。主要研究方向为信息检索和推荐系统,承担国家自然科学基金等项目 20 余项,已经发表论文 200 余篇。
Maarten de Rijke,荷兰皇家艺术与科学院院士,荷兰阿姆斯特丹大学教授。他在信息检索、机器学习、自然语言处理和数据挖掘的顶级会议和期刊上共发表了 670 篇文章,其中包括 SIGIR、WWW、KDD,ICML, NIPS,ACL,ACM TOIS 和 IEEE TKDE。特别是在专家发现,在线学习, 模态逻辑以及问答系统领域做出了卓越贡献。Maarten de Rijke 还多次担任信息检索领域各种会议的大会或程序委员会主席,其中包括 SIGIR, WWW, WSDM和CIKM等。
![]()
点击以下标题查看更多往期内容:
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()