滴滴KDD 2019 论文详解:基于深度学习自动生成客服对话

在这篇论文中,滴滴基于辅助要点序列提出了Leader-Writer网络来帮助解决客服工单摘要生成问题,能让客服工单摘要的自动化生成更具完整性、逻辑性与正确性。
作者 | 滴滴 AI Labs
编辑 | Pita
世界数据挖掘领域顶级学术会议KDD2019继续在美国阿拉斯加州安克雷奇市举行。本次KDD大会首次采用双盲评审制,共吸引了全球范围内约1879篇论文投递。其中,Applied Data Science track收到约 700 篇论文投稿,最终45篇被接收为Oral论文,100篇被接收为Poster论文;而Research track 共收到了 1179 篇投稿,最终111篇被接收为Oral论文,63篇被接收为Poster论文。
今年,滴滴共有三篇Oral论文入选KDD2019,研究内容涵盖基于深度学习方法自动化地生成工单摘要、基于深度强化学习与半马尔科夫决策过程进行智能派单及模仿学习和GAN在环境重构的探索。
本文是对滴滴AI Labs团队Oral论文《Automatic Dialogue Summary Generation for CustomerService》的详细解读,在这篇论文中,滴滴基于辅助要点序列提出了Leader-Writer网络来帮助解决客服工单摘要生成问题,能让客服工单摘要的自动化生成更具完整性、逻辑性与正确性。

研究背景
滴滴的客服每天需要处理大量的用户进线。客服人员在解答或处理用户问题的时候,需要按照以下流程严格执行:1) 了解用户问题与诉求;2) 提供解决方案或者安抚用户情绪;3) 记录工单摘要。
工单摘要对于滴滴客服系统非常重要,它有两个目的:
当工单在内部流转,被其他客服处理的时候,工单摘要可以辅助客服来快速了解用户问题、解决方案、以及用户反馈等信息,进而调整自己的服务策略;
质检人员会检查工单摘要,评估客服提供的方案是否有效,用户是否认可,进而来判断客服的服务质量;
在自动化工单摘要系统上线前,工单摘要主要由客服手工撰写,耗费客服大量的时间。而客服每日解决的用户进线量很大,这导致大量客服资源的占用;另外,手工撰写的工单摘要存在标准不统一、错词漏句等情况,错误或者不规范的工单摘要会给使用工单摘要的其他客服人员的工作带来负面影响。
本文主要研究如何利用深度学习方法,自动化的生成工单摘要,提高客服工作效率,进而节约客服资源。
问题挑战
相对于一般的文本摘要问题,客服工单摘要有其特殊性。我们需要保证工单摘要满足以下三个条件:
完整性:即工单摘要需要包括所有的要点;一般情况下,摘要至少要包括用户问题描述、解决方案、用户反馈这几个要点。在一些场景下,还需要包括用户联系方式、反馈时效等要点。
逻辑性:即工单摘要中的要点需要按正确的逻辑顺序组织起来。工单摘要应该先记录用户问题,再记录解决方案,最后记录用户反馈以及后续跟进策略等。顺序不正确会导致摘要难以让人理解。
正确性:即工单摘要中的核心要点需要保证是正确的,例如用户反馈部分中的”认可解决方案”与“不认可解决方案“。由于两者从文本相似度很高,利用End-to-End方案学习效果通常比较差。
目前的抽取式和生成式的文本摘要方案均不能很好的解决这些问题;针对以上挑战我们提出了自己的解决方案。
解决方案
我们提出利用辅助要点序列(Auxiliary keypoint sequence)来解决以上这些挑战。要点(key point)是工单摘要中一个片段的主题,例如“问题描述”。我们通过人工总结工单摘要,整理得到滴滴场景下51个要点;详见表1
表1:滴滴场景下的工单摘要要点(部分)
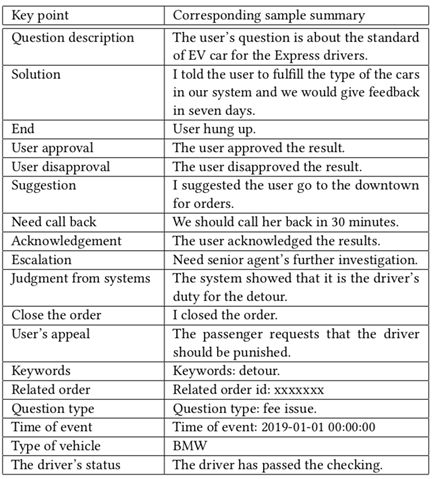
我们利用规则,从人工撰写的工单摘要中抽取出摘要中的要点。一个摘要中的所有要点构成了要点序列(Key point sequence)。如果一个摘要在要点序列上是完整的、有逻辑的、且正确的,那么对应的工单摘要则是完整的、有逻辑的、且正确的。同时,为了更好的区分“用户认可”和“用户不认可”这种文本相似度高的要点,我们将对立的要点记为两个不同的要点。
我们将工单摘要生成问题建模成一个多任务学习问题。首先模型根据对话信息生成要点序列;然后再利用对话信息和生成的要点序列生成每个要点对应的子摘要;最后根据要点序列中的逻辑拼接子摘要即可获得完整的工单摘要。整个流程如图1所示。
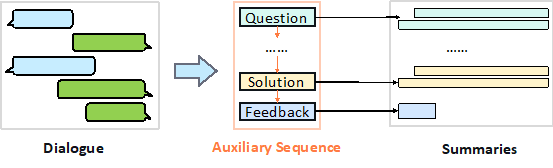
图1:解决方案示意图
通过引入辅助要点序列,可以带来如下好处:
模型通过对辅助要点序列的学习,可保证生成的工单摘要的完整性、逻辑性与正确性,保证工单摘要的质量;
辅助要点序列的词典集合小(滴滴场景下为51),序列长度一般较短(不超过10),容易生成准确的要点序列;
生成每个要点的子摘要,其长度也要显著短于完整摘要,可提高摘要的质量。
基于辅助要点序列,我们提出了Leader-Writer网络来解决工单摘要生成问题。具体而言,Leader-Writer网络具有层次化对话编码器 (Hierarchical Transformer Encoder),要点序列生成网络 (Leader-net) 和子摘要生成器 (Writer-net),并基于要点序列生成和子摘要序列生成的交叉熵损失和强化学习损失函数进行联合训练。图2是模型网络结构图,接下来分模块介绍其实现过程。
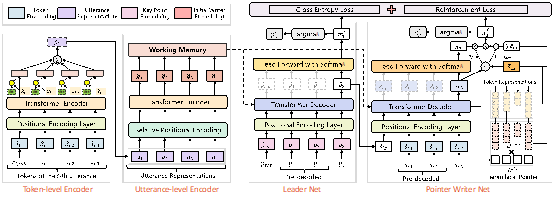
图2:Leader-Writer网络架构图
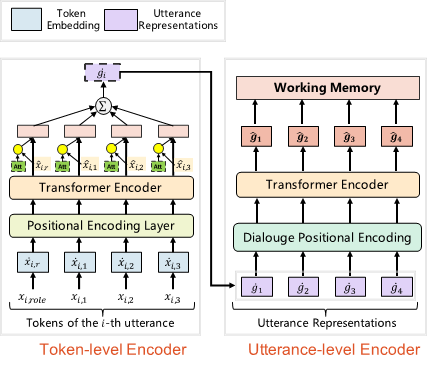
1. 层次化对话编码网络(Hierarchical Transformer Encoder)
层次化对话编码器包括词级别(token-level)和句子级别(utterance-level)的编码器,词级别的编码器通过Transformer编码每一句对话中的单词的embedding进行编码并通过注意力机制(attention)聚合得到每句话的表示;句子级别的编码器也是一个Transformer编码器,通过编码聚合的句子表示,获取上下文相关的句子表示,并作为解码部分中对话信息的表示。这里句子级别的编码器引入了相对位置embedding,相对于传统Transformer模型采用的绝对位置embedding使整体效果提升。
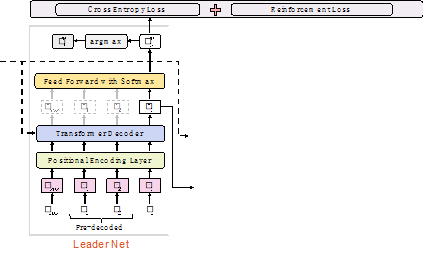
2. 要点序列生成网络(Leader-net)
要点序列生成器(Leader)是一个标准的Transformer解码器,以要点序列做为监督信息,根据对话信息解码要点序列。在损失函数中,我们同时考虑了交叉熵损失和自我批判的(self-critical)[1] 的强化学习损失。
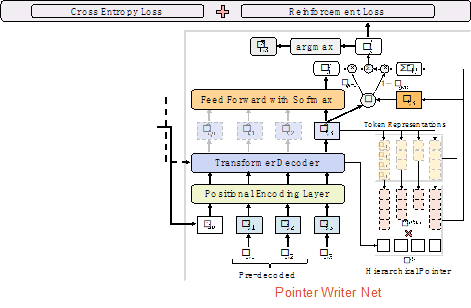
3. 子摘要生成网络(Writer-net)
子摘要生成器(Writer)则是考虑指针机制(Pointer-generator)的Transformer解码器。通过指针机制,子摘要生成器可以拷贝原始对话中的部分信息,例如数字和电话号码等。需要注意的是,由于模型中采用了层次化编码器对对话进行编码,在指针机制中,为了保证能选择到对话中的词,需要考虑层细化的指针机制。要点序列中的不同位置可能具有相同的要点,例如“问题描述 -> 解决方案 -> 不认可 -> 解决方案 –> 认可”中,两个“解决方案”对应的子摘要内容不同。为了解决该问题,我们采用要点序列生成器的解码状态作为子摘要生成器的解码起始状态。基于多任务学习的设置,我们独立了考虑了要点序列生成和子摘要生成的损失。
4. 训练与预测:
在训练阶段,Leader-Writer模型利用要点序列与对应的子摘要做为监督信息,学习模型参数。在预测阶段,Leader-Writer模型首先根据对话信息生成要点序列,然后根据要点序列的每个要点的解码状态生成最后的子摘要,最后拼接摘要后,获取最后的工单摘要。
实验与结果
我们对比了一系列的基于深度神经网络的文本摘要方案,包括:
基于LSTM的Seq2seq的文本摘要模型[2] ;
基于LSTM+ Attention的文本摘要模型[3] ;
基于Transformer的文本摘要模型[4] ;
基于Pointer-Generator的文本摘要模型[5] ;
以及基于Hierarchical Transformer的文本摘要模型。
同时我们也实现了Leader-writer模型的三个变种,包括:
Hierarchical Encoder+Leader-net+Writer-net的网络架构(不考虑强化学习损失,Writer-net不引入Pointer Generator机制);
Hierarchical Encoder+Leader-net+Pointer Writer-net的网络架构(不考虑强化学习损失);
Hierarchical Encoder+Leader-net+Pointer Writer-net+Self-criticalloss的网络架构。
通过实验,我们的Leader-Writer网络在工单摘要生成上取得了比目前领先方法更好的效果,同时我们生成的摘要在完整性和逻辑性上比对比方法效果更好;而在核心要点上的正确性,我们的方法在准确性上也优于对比方法。针对具有复杂逻辑的对话内容(即更长的要点序列),我们的方法也在总体摘要效果和完整性、逻辑性和正确性上远远优于对比方法的效果。
论文全文:https://www.kdd.org/kdd2019/accepted-papers/view/automatic-dialogue-summary-generation-for-customer-service
* 封面图来源:https://blog.prototypr.io/why-customer-service-is-such-a-bad-user-experience-6a5516079868






