ICML 2020 | 五篇精选论文,洞悉微软亚洲研究院机器学习前沿

编者按:机器学习顶级会议 ICML 2020 于7月13日至18日线上举行。本届 ICML 微软亚洲研究院共有10篇论文入选。我们精选了五篇论文,从鲁棒特征学习、统一预训练模型、机器学习优化、文本切分等领域带你一览机器学习最新成果。
Informative Dropout: 基于形状偏好的鲁棒特征学习
Informative Dropout for Robust Representation Learning: A Shape-bias Perspective
论文链接:https://proceedings.icml.cc/static/paper_files/icml/2020/528-Paper.pdf
目前 CNN 模型的一个主要问题是在不同场景下缺乏鲁棒性,比如,当训练数据和测试数据来自不同的 domain 时,模型的表现会下降;当模型去学习识别某些类别的物体时,其学到的表征难以直接迁移到其它类别的物体上;当输入的图片受到损坏(corruption)时,或者受到噪声干扰时,模型的输出会变得不稳定。
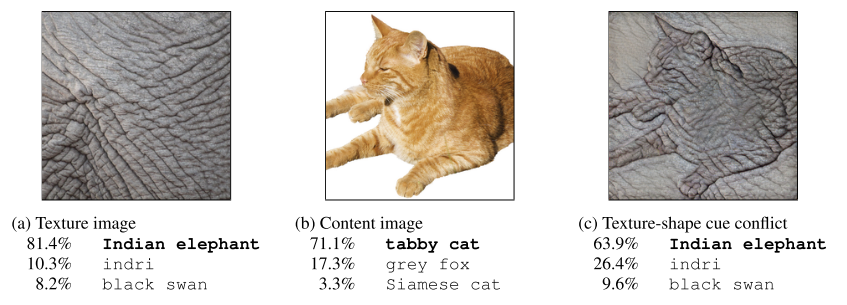
图1:CNN 模型偏好纹理信息而非形状信息
CNN 的一个特性是偏好通过图片的纹理(texture)信息,而非形状(shape)信息去做决定。近期有工作表明 CNN 的低鲁棒性和其纹理偏好(texture-bias)有着密切的联系。在这篇工作中,我们展示了通过减少纹理偏好,学习一个更偏好形状的网络,来增加其在各个场景下的鲁棒性。
首先,我们设计了一个轻量级的、广泛适用的模块 InfoDrop:从传统的显著性检测(saliency detection)和人眼跟踪(human eye tracking)出发,发现通过衡量图片局部的自信息(self-information)可以区分纹理信息和形状信息(前者信息量较小,后者信息量较大),并用类似 Dropout 的方式将局部信息冗余的位置(即texture)去掉,从而使得网络学到的表征更侧重于形状信息。进一步,在训练结束之后将 InfoDrop 模块去掉,并在原始数据上进行微调,发现网络仍然表现出较好的形状偏好。
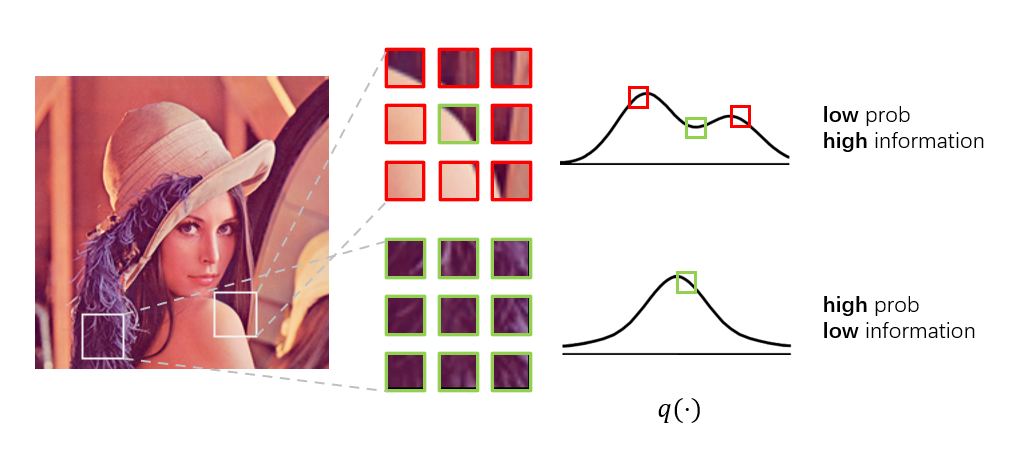
图2:Informative Dropout 根据局部的自信息来区分纹理信息和形状信息
我们将这一模块应用到各种任务(包括domain generalization、few-shot classification、random corruption、adversarial perturbation)中,发现结果都有不同程度的提升,从而展示了网络可以通过增加 shape-bias 的方式,来增强对各种 distribution shift 以及 image corruption & perturbation 的鲁棒性。
Optimization from Structured Samples for Coverage Functions
论文链接:https://proceedings.icml.cc/static/paper_files/icml/2020/3418-Paper.pdf
在传统的研究和实践中,机器学习和优化是两个不同的计算机科学子领域,有不同的目标。机器学习的目标是从数据中找出规律,建立模型,一般用来支持数据分类或预测等任务。传统意义上的优化一般是指在给定的模型及参数设置中,解决某些最优化的分配或调度问题,比如城市道路网络中的最优路径选取和推荐、供应链网络的最优分配、社交网络传播中的影响力最大化等问题。而在很多实际的任务中,经常需要先用机器学习方法建立模型,然后再在模型上解决优化问题,这就是从数据到模型,再从模型到优化的经典流程。

图3:从数据到模型,从模型到优化的经典流程
这种两步走的分而治之的策略看似自然,但是对于从数据到优化的组合任务并不一定能保证很好的效果。Balkanski 等人在理论计算机科学的顶级会议 STOC‘2017 给出了一个看似意外的结果:对于一类集合覆盖函数 f(S),机器学习能达到理论意义上很好的学习效果,即对绝大多数集合 S 都能学到和真实值 f(S) 很相近的值,而如果对已知函数 f(S) 优化找到使函数值最大的集合 S, 经典的贪心算法就能达到常数近似比,但存在这样的覆盖函数 f,如果要从多项式个抽样数据 {(S_i,f(S_i )} 做最终优化(不管是否经过模型学习的阶段),都不存在任何多项式算法能够达到常数近似比。他们称从采样数据到优化的任务为 OPS(Optimization from Samples)。
Balkanski 等人的研究指出了分治策略和一般的 OPS 任务的内在局限性。但在实际问题中类似 OPS 的任务是普遍存在的,如何克服 OPS 的难解性得到好的方法呢?在论文中我们提出了一个成为 OPSS(Optimization from Structured Samples)的解决方案,即如果能从抽样数据中得到更多的结构信息,那么可以达到很好的优化效果。
具体地说,每一个覆盖函数 f_G 可以用一个二部图 G=(L,R,E) 表示,其中 L,R 为左右两个结点集合,E 为连接左右集合中结点的边集。左集合中每个结点子集 S⊆L 在右集合 R 中的邻居 N_G (S) 为 S 的覆盖。覆盖函数 f_G 就定义为对所有左集合的子集 S⊆L,f_G (S)=|N_G (S)|,即 S 的覆盖的大小。在很多应用中,抽样数据不只是 {(S_i,f_G (S_i )},而是带有覆盖结构信息的 {(S_i,N_G (S_i )}。我们证明当子集 S_i 满足三个合理分布的假设条件时,可以设计一个 OPSS 算法从多项式个采样 {(S_i,N_G (S_i )} 中,算法可以找到达到常数近似的近似最优解,同时还证明这个常数近似比存在不可逾越的上界,说明了在这种采样结构下 OPSS 存在的内在局限性。我们还进一步论证了三个分布的假设条件缺一不可,去掉任何一个条件,都会存在一个分布使得 OPSS 不再有常数近似比。
这一结果给出了如何将机器学习和优化相结合的一个方向,即要根据最终的优化目标,寻求合理的采样数据方案,利用采样数据中的结构信息,将模型学习和最终的优化有机结合。
融合不同文本切分方式的序列生成
Sequence Generation with Mixed Representations
论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2020/07/3729-Paper.pdf
文本切分(Tokenization)是基于神经网络的文本模型的第一步,对于模型的最终表现也有着重要的影响。当下最流行的是基于子词(subword)的切分方式,例如BPE、SentencePiece(SP)、WordPiece(WP)等。每种方式各有千秋,最终结果也不尽相同。人们更多关注的是如何得到一种新的切分方式,却并未考虑如何将已有的切分方式更好地利用。本篇论文提出了一种新的模型框架来同时利用不同的文本切分方法。为了更好地融合不同切分结果以增强数据的多样性,我们还提出了一种新的协同教学(co-teaching)的训练方法。实验证明这些方法在低资源语言的翻译任务上能够大幅提升模型的结果,同时在摘要生成任务上也有效。
以 SP 和 BPE 两种切分方式为例,我们提出的模型框架如图4所示。在模型中,两个编码器分别编码 BPE 和 SP 的切分结果,并且内部通过 Mix-attention 机制进行信息融合。具体来说,在左侧的编码器中,Mix-Attn 的 query 是经 BPE 处理后的数据,而 key 和 value 是经过 SP 处理后的数据;在中间的编码器中,mix-attn 的 query 是经 SP 处理的数据,而 key 和 value 是 BPE 处理后的数据。解码器端则通过两个编码器-解码器注意力模块(SP-enc-attention和BPE-enc-attention)进行不同切分表征的信息融合。这样的方式成功利用了两种不同切分方式的数据结果,并且在解码器端可以生成两种不同的翻译结果。
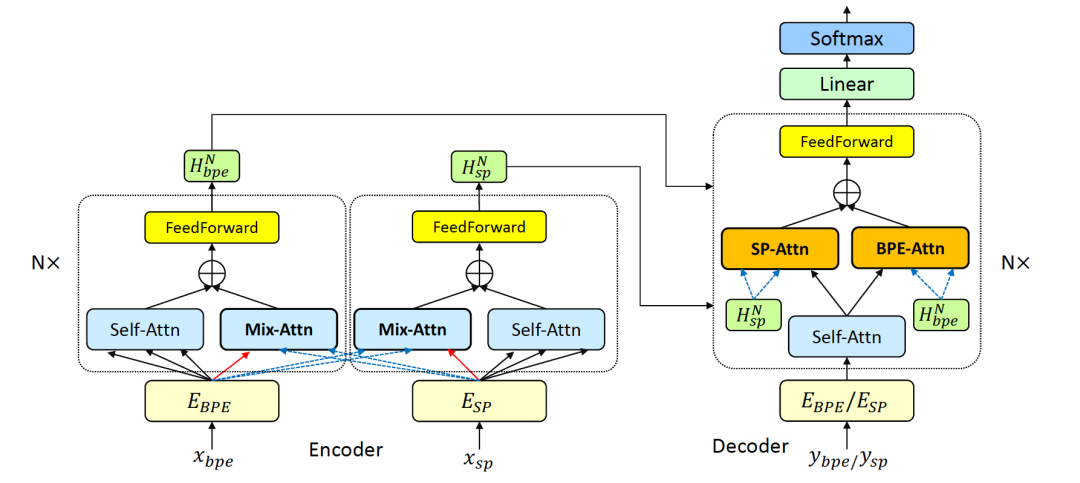
图4:模型框架。新增的 mix-attention,SP-attn,BPE-attn 在图中加粗表示。Mix-attention 的 Q 为红色箭头输入。三者的 K 和 V 均为蓝色虚线输入,以此得到融合的表征向量。
协同教学(co-teaching)训练算法基于数据蒸馏的思想,作用于两种不同切分方式的解码结果上。简单来说,即将不同切分方式得到的解码结果在训练集上进行数据蒸馏,然后用另一种切分方式进行处理,以提供新的训练数据。
表1主要展示在6个 IWSLT-2014 的低资源语言对的翻译,共12个方向的任务上进行的实验结果。结果表明我们的模型和算法能大幅提升这些翻译任务的性能,增幅达到1.5个 BLEU 以上。
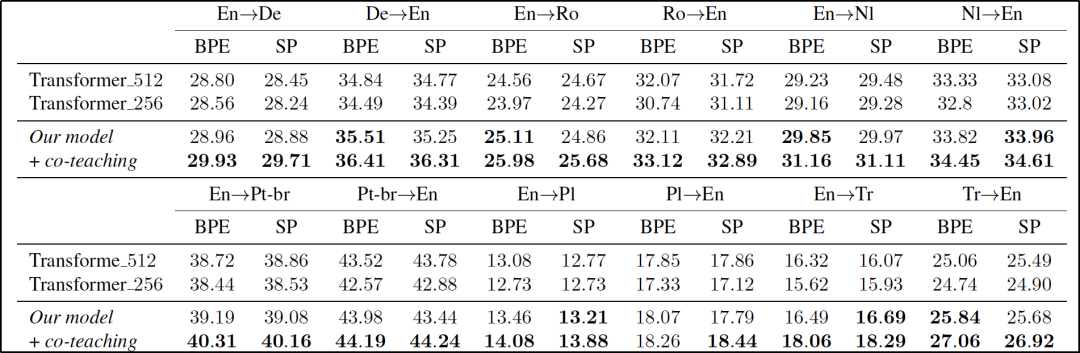
表1:IWSLT-2014 上12个翻译方向上的模型结果,其中标粗的部分表示显著优于512维的 Transformer 基础模型
UniLMv2:统一预训练伪掩码语言模型
UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
论文链接:https://arxiv.org/abs/2002.12804
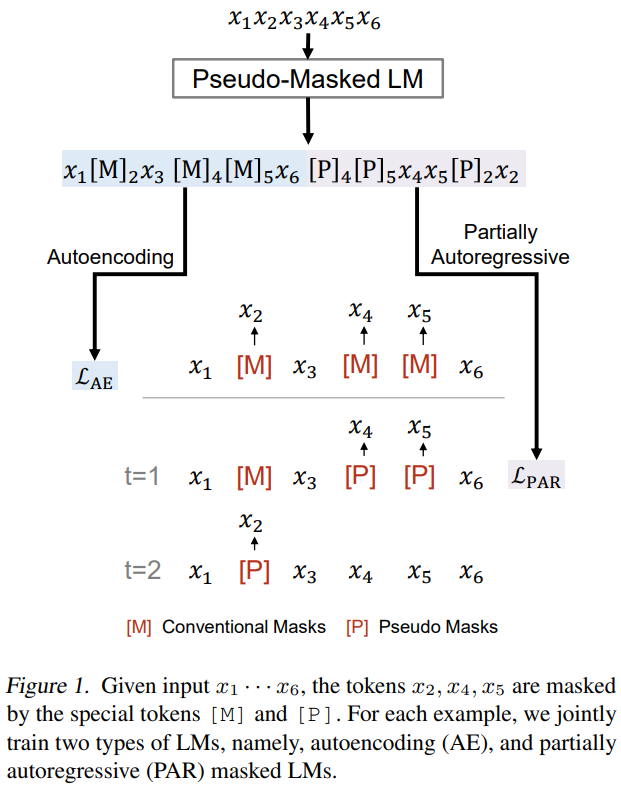
图5:在两个语言建模任务中共享模型参数,并且重用给定上下文标记的编码结果
基于大规模语料的预训练语言模型在各种自然语言处理任务带来了巨大的提升。受UniLMv1 ([NeurIPS-19]Unified Language Model Pre-training for Natural Language Understanding and Generation)的启发,本篇论文提出“伪掩码语言模型”(PMLM),可以同时对两种不同的语言建模目标进行高效训练,从而使其更好地适用于语言理解(如文本分类、自动问答)和语言生成(如文本摘要、问题生成)任务。
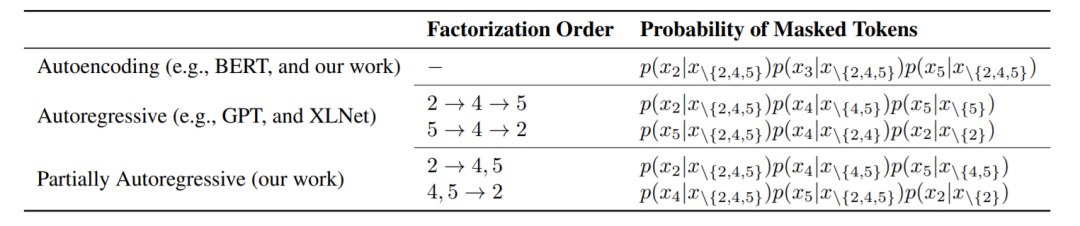
表2:三类语言模型预训练目标
如2表所示,我们将语言模型预训练目标分为三类。第一类依赖于自编码语言建模(Autoencoding, AE)。例如在 BERT 中使用的掩码语言建模(MLM)随机的在文本序列中遮盖一部分单词,在 Transformer 的双向编码结果之上,对每个被遮盖的单词进行分别还原。第二类方法基于自回归建模(Autoregressive, AR)。不同于 AE,目标单词被依次预测,且依赖于先前的结果。第三类是我们提出的半自回归语言建模(Partially Autoregressive, PAR),对短语级别进行依赖建模,从而避免了 AR可能带来的过度局部依赖问题。
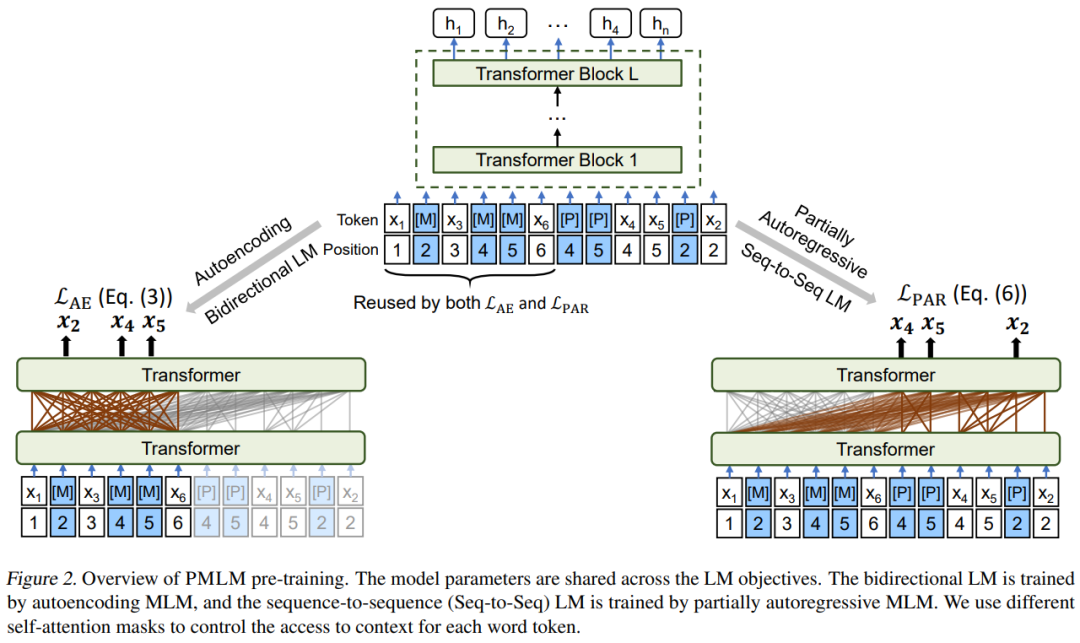
图6:伪掩码语言模型(PMLM)
在新提出的伪掩码语言模型(PMLM)中,我们对 AE 以及 PAR 这两个语言建模目标进行了融合。在共享模型参数的基础上,尽可能对上下文的编码结果进行了复用,以达到高效训练的目的。通过构造合理的自注意力模型掩码与位置编码,PMLM 可以在一次计算中同时对两种语言建模任务进行训练,且无需进行上下文编码的冗余计算。
在自动问答、复述判别、情感分类、文本摘要、问题生成等一系列任务上的测评,说明了这一方法的有效性。
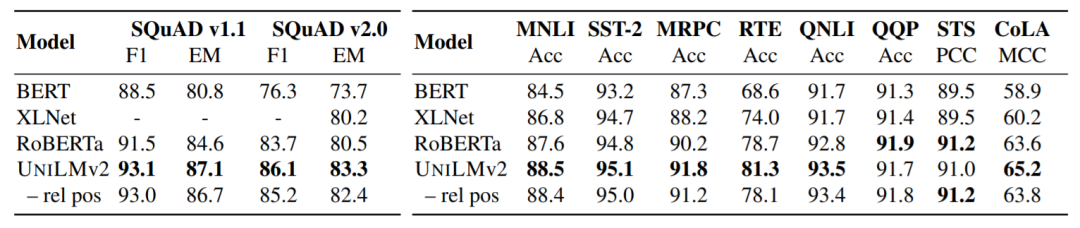
表3:预训练模型在 SQuAD 与 GLUE 上的实验结果
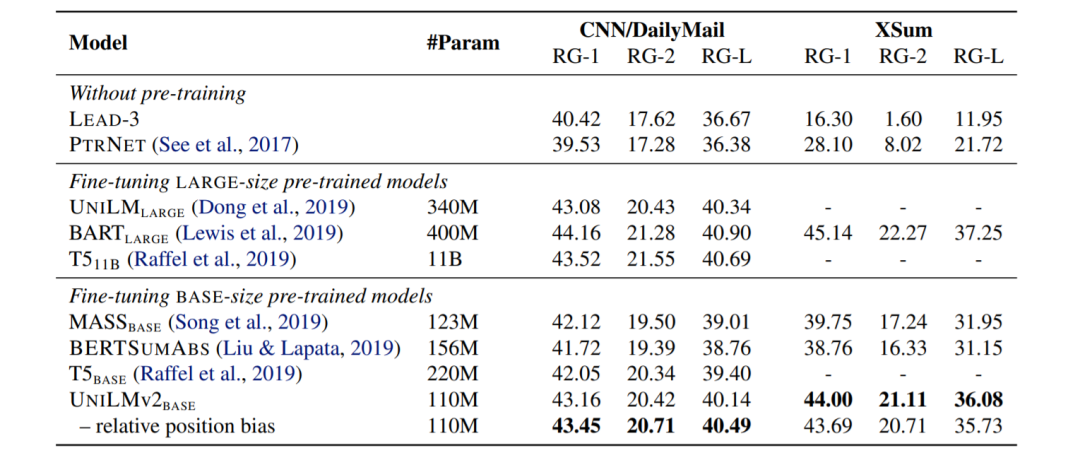
表4:文本摘要任务实验结果
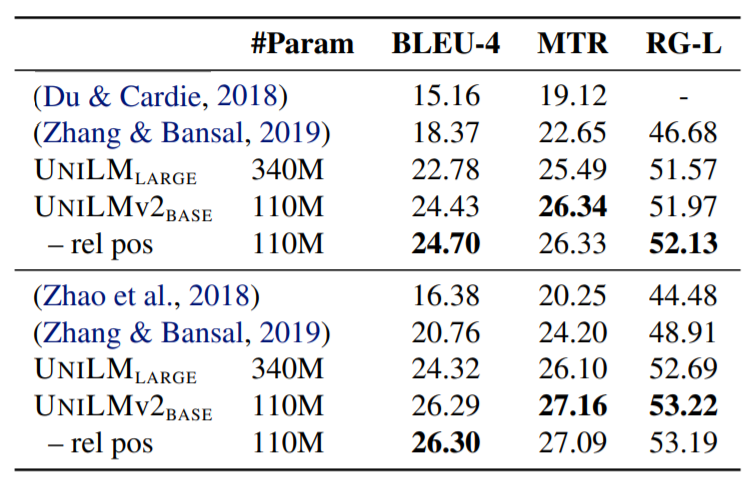
表5:问题生成任务实验结果
为基于粒子的变分推理开发的方差缩减和拟牛顿法
Variance Reduction and Quasi-Newton for Particle-Based Variational Inference
论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2020/07/5434-Paper.pdf
许多机器学习任务最终都可归结为从未归一化密度函数中采样,例如贝叶斯学习。对于此任务,近年来发展起来的基于粒子的变分推理(particle-based variational inference, ParVI)方法(“粒子”指可以被不断更新的样本)比传统方法——马尔可夫链蒙特卡罗(MCMC)方法——具有更快的收敛速度和更高的样本效率等优势,但其在针对大规模数据或目标分布较为病态等复杂采样任务上的收敛仍然不够快。本篇论文将利用优化领域中的方差缩减和拟牛顿法提高各 ParVI 方法在这些复杂任务上的表现。(此工作是与斯坦福大学 Michael H. Zhu 及清华大学朱军教授合作完成)
首先需要注意的是,ParVI 方法并不是样本空间上的优化方法(而是需要合理地布置一组粒子使得它们可以很好地代表目标分布),因此直接将方差缩减和拟牛顿法用在粒子的更新规则上是不合理的。另一方面,ParVI 方法都可以被视作是对粒子分布与目标分布之间的 KL 散度在沃瑟斯坦空间(Wasserstein space;二阶矩有限的分布的集合)上的梯度流(gradient flow)的模拟,类似于在沃瑟斯坦空间上通过梯度下降方法最小化 KL 散度。
由于沃瑟斯坦空间具有黎曼流形的结构,因此我们考虑利用黎曼流形优化方法中的方差缩减和拟牛顿法。为此需要沃瑟斯坦空间上的指数映射、平行移动等几何结构。虽然它是一个无穷维流形,即无法在其坐标空间上实现这些映射,但我们发现这些映射所对应的分布(即沃瑟斯坦空间上的点)的变化可以通过操作其一组粒子(即一组样本)实现。最终所得到的方差缩减和拟牛顿法框架可以用于各 ParVI 方法,且不会增加 ParVI 方法每次更新的均摊时间复杂度但会提高收敛速度。
在大规模且较为病态的数据集上的贝叶斯线性回归(如图7所示)和贝叶斯逻辑回归(如图8所示)上的实验结果表明,所提方法(SQN-VR)在各个分布差别衡量指标下都有最快的收敛速度和最好的结果。

图7:在大规模且较为病态的数据集上的贝叶斯线性回归

图8:在大规模且较为病态的数据集上的贝叶斯逻辑回归
你也许还想看: