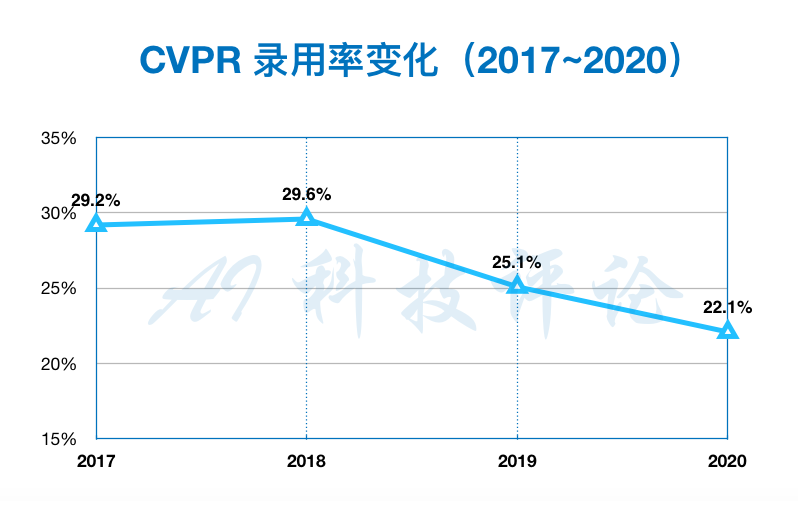
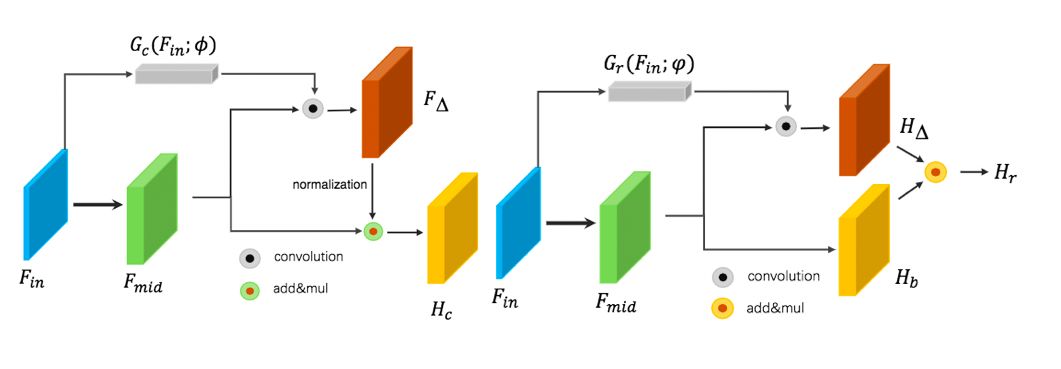
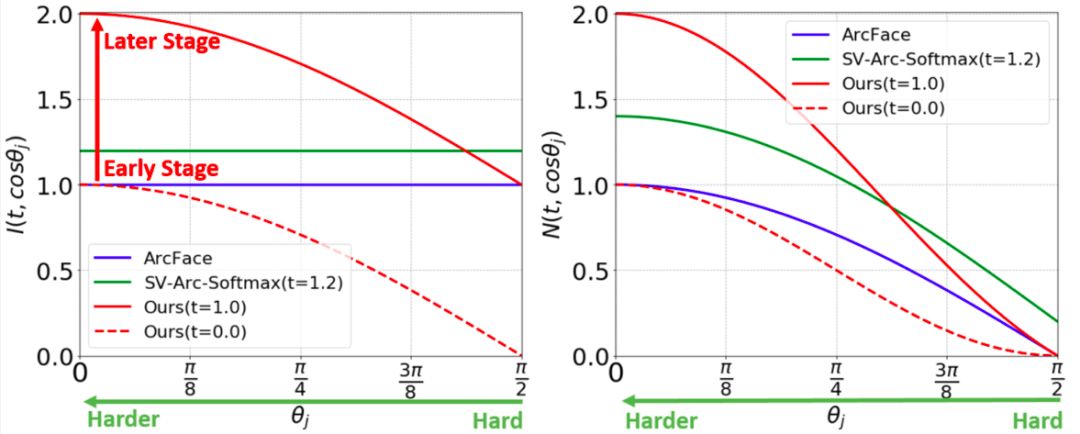
4、自适应课程学习人脸识别函数 论文:CurricularFace: Adaptive Curriculum Learning Loss for Deep Face Recognition 人脸识别中常用损失函数主要包括两类,基于间隔或者难样本挖掘。前一类方法对所有样本都采用一个固定的间隔值,忽略了样本自身的难易信息。后一种方法则在整个网络训练周期都强调困难样本,可能导致网络无法收敛问题。 在工作中,优图基于课程学习的思路,提出了一种新的自适应课程学习损失函数。在训练初始阶段,方法主要关注容易的样本;随着训练进行,逐渐关注较难的样本。同时,在同一个训练阶段,不同的样本根据其难易程度被赋予不同的权值。在常用的多个人脸识别benchmark上,该方法相较于SOTA方法都取得了稳定一致的提升。
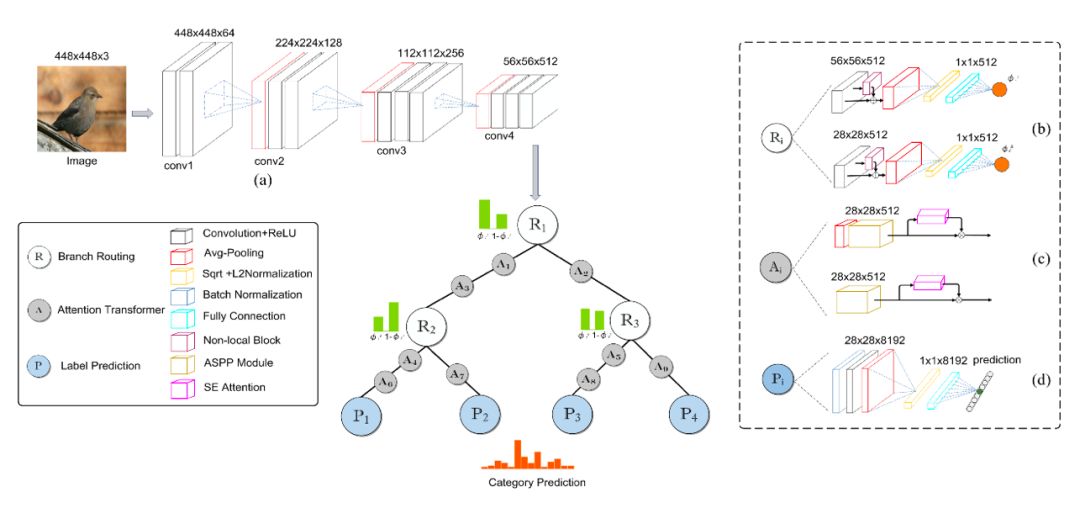
5、基于注意力卷积二叉神经树的细粒度视觉分类 论文:Attention Convolutional Binary Neural Tree for Fine-Grained Visual Categorization 本文由腾讯优图实验室和中科院软件所联合提出。细粒度视觉分类(Fine-Grained Visual Categorization,FGVC)因样本类间差异更加细微,往往只能借助微小的局部差异才能区分出不同的类别,使其成为一项重要但具有挑战性的任务。 本文提出了一种基于注意力机制的卷积二叉神经树结构。具体来说,将传统的决策树与神经网络结合,在树的内部节点中使用路由来确定树内从根到叶的计算路径,并且在树的边上添加了卷积操作增强表示学习,最终决策融合了所有叶节点的预测。该模型以一种由粗到细的层次方式学习具有判别力的特征。 此外,采用非对称的策略来增加多尺度特征提取,增强样本的区分性特征表示。采用SGD优化方法以端到端的方式训练整个网络。该方法在CUB-200-2011,Stanford Cars 和 Aircraft数据集上进行了评估,显著优于当前其他的弱监督细粒度方法。
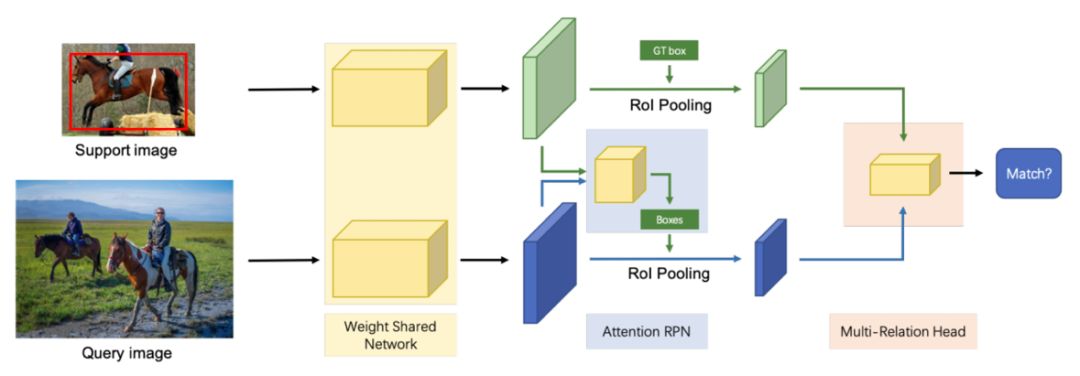
6、基于注意力机制及多关系检测器的小样本物体检测 论文:Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector 本文由香港科技大学和腾讯优图实验室联合提出。目标检测网络已经被广泛应用到安保,自动驾驶,医学图像等各个领域。然而传统的目标检测网络需要使用大量高质量的训练样本对模型进行训练。这些训练样本需要大量的人力物力进行标注,往往无法快速获得,所以无法将目标检测模型快速部署到新样本的检测中,而小样本目标检测方法可以很好地解决这一问题。联合团队提出了一种基于深度孪生网络的小样本目标检测模型,通过基于注意力机制的候选框网络,多关系检测器以及三元组对比训练方法对网络进行改进,使得网络能够不对新物体重新训练即可应用于新类别检测。此外,文章中提供了一个1000类的小样本物体检测数据集,希望可以方便该领域的研究。该联合团队的工作主要有以下贡献: 首先,使用注意力机制对物体检测候选框进行筛选。将待检测新物体的特征作为滤波器在输入图片上进行卷积,以此找出潜在的候选框区域。 然后,使用多关系检测器对这些候选框进行分类以及位置调整。多关系检测器对候选框和新物体进行像素级、区域级和全图级的多级关系匹配,以此找出匹配程度最高的区域作为检测输出。 最后,构建(目标样本,正样本,负样本)训练样本三元组对模型进行训练,使得网络能够同时学习到相同物体间的相似性和不同物体间的差异性,从而大大提升网络在新样本上的检测性能。 该方法在多个数据集上均取得了最好的结果,且无需在新物体上进行任何训练。其基本框架图如下:
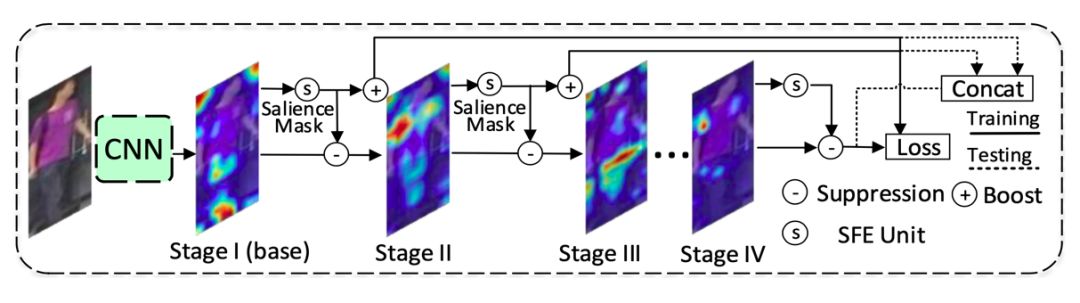
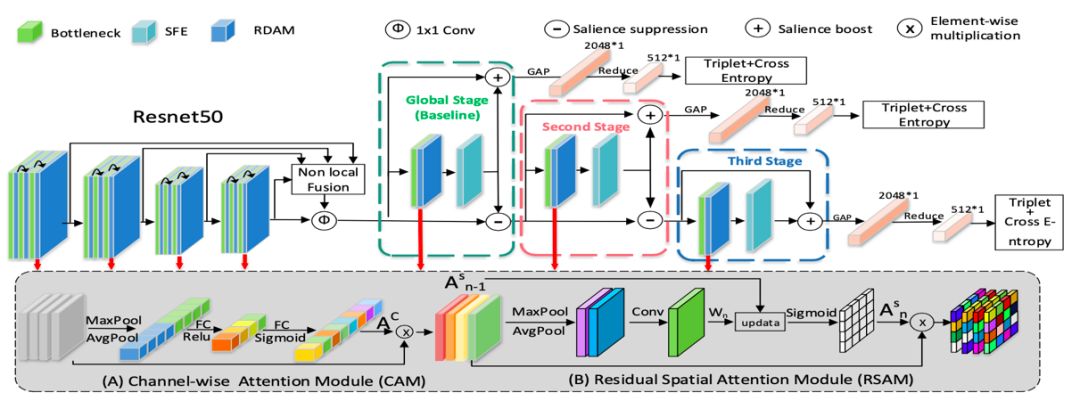
7、基于显著性引导级联抑制网络的行人重识别 论文:Salience-Guided Cascaded Suppression Network for Person Re-identification 本文由北京大学、腾讯优图和南方科技大学联合提出。利用注意力机制对全局和局部特征进行建模,作为最终的行人表征,已成为行人再识别(Re-ID)算法的主流趋势。这些方法潜在的局限性是,它们侧重于提取最突出的特征(显著性特征),但重新识别一个人可能依赖于不同情况下显著性特征所掩盖的各种其他的线索,比如身体、衣服甚至鞋子等。为了解决这一局限性,联合团队提出了一种新的显著性引导级联抑制网络(SCSN),该网络使模型能够挖掘多样化的显著性特征,并通过级联的方式将这些特征集成融合到最终的特征表示中。联合团队的工作主要有以下贡献: 第一、我们观察到,以前网络学习到的显著性特征可能会阻碍网络学习其他重要信息。为了解决这一局限性,引入了级联抑制策略,该策略使网络能够逐级挖掘被其他显著特征掩盖的各种潜在的、有用的特征,并融合各级提取的特征作为最后的特征表示; 第二、提出一个显著特征提取(SFE)单元,该单元可以抑制在上一级联阶段学习到的显著特征,然后自适应地提取其他潜在的显著特征,以获得行人的不同线索; 第三、开发了一种有效的特征聚合策略,充分增强了网络提取潜在显著特征的能力。 实验结果表明,该方法在四个大规模数据集上的性能优于现有最好的方法。特别是,该方法在CUHK03数据集上比目前最好的方法提升7.4%。其基本框架图如下:
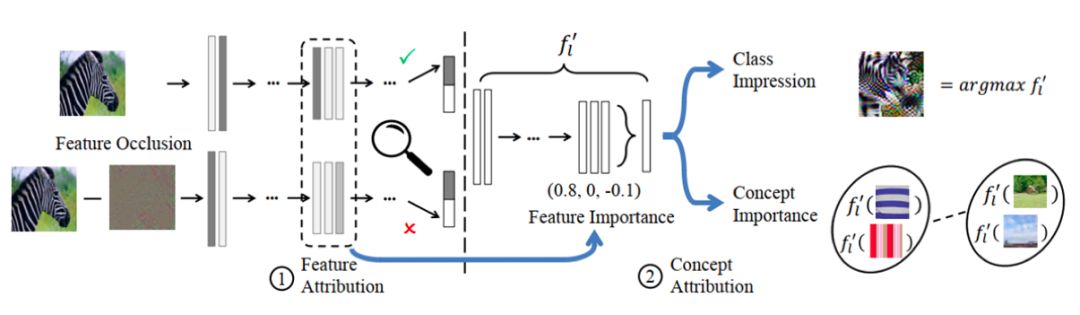
8、概念归因的卷积神经网络的全局解释 论文:Towards Global Explanations of Convolutional Neural Networks with Concept Attribution 本文由腾讯优图实验室和香港中文大学合作完成。卷积神经网络(CNN)的广泛应用,使得解释其行为变得越来越重要。其中,全局解释因其有助于理解整个样本类别的模型预测,最近引起了极大关注。但是,现有方法绝大多数都依赖于模型的局部逼近和对单个样本预测的独立研究,这使得它们无法反映出卷积神经网络的真实推理过程。联合团队提出了一种创新的两阶段框架,即对可解释性的攻击(AfI),以更忠实地解释卷积神经网络。AfI根据用户定义的概念的重要性来解释模型决策。它首先进行特征遮挡分析,该过程类似于攻击模型以得出不同特征的重要性的过程,于是有能力学习全局解释。然后,通过语义任务将特征重要性映射到概念重要性,下图展示了AfI的框架结构。实验结果证实了AfI的有效性及其相比于现有方案的优越性。本文中还演示了其在提供卷积神经网络理解方面的用例,例如基础模型预测和模型认知中的偏差。
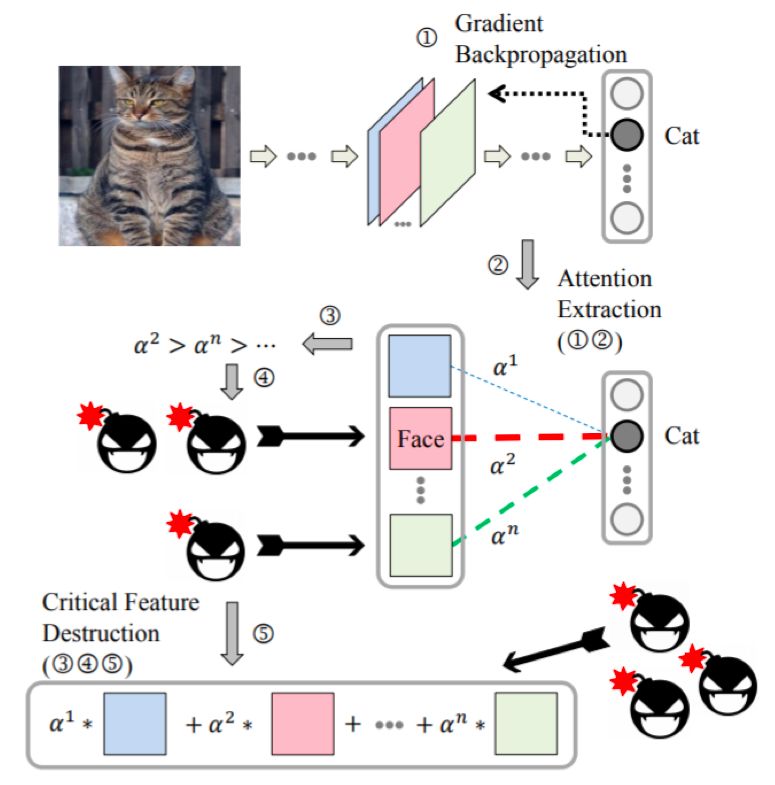
9、基于注意力机制提高对抗可迁移性 论文:Boosting the Transferability of Adversarial Samples via Attention 本文由腾讯优图实验室和香港中文大学合作完成。深度学习模型的广泛部署使得在实践中评估模型的鲁棒性成为必需,尤其是对于安防领域和安全敏感领域例如自动驾驶和医疗诊断。攻击是一种重要的衡量模型鲁棒性的方式,其中针对深度网络图像分类器生成对抗图像是最基本和公认的任务之一。 最近,针对图像分类器的基于迁移的黑盒攻击引起了越来越多的兴趣。这种攻击方式,攻击者需要基于本地代理模型来制作对抗性图像,而没有来自远端实际目标的反馈信息。在这种具有挑战性的设置下,由于对所使用的本地模型的过度拟合,合成的对抗性样本通常无法获得良好的成绩。因此,文章中提出了一种新颖的机制来减轻过度拟合的问题,从而增强黑盒攻击的可迁移性。不同的网络架构例如VGG16,ResNet,Inception在识别图片时会有相似的图像注意力,比如都倾向于注意猫脸来识别猫。基于此,通过模型提取特征的注意力梯度来规范对抗性示例的搜索。这种基于注意力规约的对抗样本搜索使得联合团队可以优先考虑攻击可能被各种体系结构共同关注的关键特征,从而促进结果对抗实例的可迁移性。在ImageNet分类器上进行的大量实验证实了文章中策略的有效性,进一步在白盒和黑盒两种条件下对比了最新方法,该攻击策略都表现出了一致的优越性。下图呈现了我们的基于注意力机制的模型攻击框架。