今日 Paper | 人体图像生成和衣服虚拟试穿;鲁棒深度学习;图像风格迁移等
为了帮助各位学术青年更好地学习前沿研究成果和技术,AI科技评论联合Paper 研习社(paper.yanxishe.com),推出【今日 Paper】栏目, 每天都为你精选关于人工智能的前沿学术论文供你学习参考。以下是今日的精选内容——
目录
ClothFlow: A Flow-Based Model for Clothed Person Generation
Table Structure Extraction with Bi-directional Gated Recurrent Unit Networks
SPACE: Unsupervised Object-Oriented Scene Representation via Spatial Attention and Decomposition
Cloud-based Image Classification Service Is Not Robust To Simple Transformations: A Forgotten Battlefield
Self-Contained Stylization via Steganography for Reverse and Serial Style Transfer
Don't Judge an Object by Its Context: Learning to Overcome Contextual Bias
node2vec: Scalable Feature Learning for Networks
Can the Exchange Rate Be Used to Predict the Shanghai Composite Index?
Coordination of Autonomous Vehicles: Taxonomy and Survey
A Survey on 3D Object Detection Methods for Autonomous Driving Applications
ClothFlow: 基于流程的人员生成模型
论文名称:ClothFlow: A Flow-Based Model for Clothed Person Generation
作者:Xintong Han / Xiaojun Hu / Weilin Huang / Matthew R. Scott
发表时间:2019/10/27
论文链接:https://paper.yanxishe.com/review/8611
推荐理由:
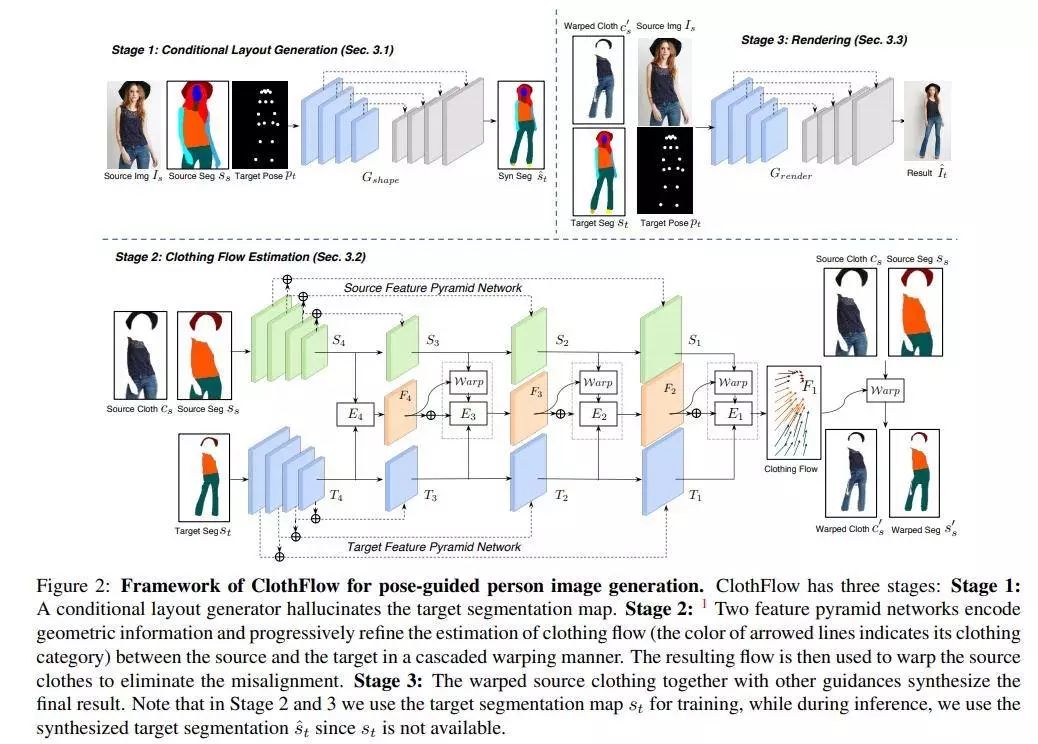
提出了一个基于外观流的生成模型ClothFlow,该模型可以合成穿衣人,用于定位引导的人的图像生成和虚拟试穿。ClothFlow通过估计源和目标服装区域之间的密集流动,有效地模拟了几何变化,自然地转移了外观,合成了新的图像,如图1所示。我们通过一个three-stage框架实现了这一点:1)以目标姿态为条件,我们首先估计一个人的语义布局,为生成过程提供更丰富的指导。2)级联流量估计网络建立在两个特征金字塔网络的基础上,准确地估计出对应服装区域之间的外观匹配。由此产生的稠密流扭曲源图像,灵活地解释变形。3)最后,生成网络以扭曲的服装区域为输入,呈现目标视图。我们在深度时尚数据集和VITON数据集上进行了大量的实验,分别用于定位引导的人物图像生成和虚拟实验任务。较强的定性和定量结果验证了该方法的有效性。
Pose-guided person generation 和Virtual try on 领域的处理主流方法:
※ Deformation-based methods (eg: affine ; TPS;NN)
※ DensePose-based methods
即基于变形的方法和基于密度的方法
几何变形的更好的外观转移,但是较大的几何变换,容易导致不准确、不自然的变换估计
基于密度的方法,映射2D图片到3D的人身体,结果看起来不够逼真。
因此作者提出的ClothFlow:a flow-based generative model ;解决衣服变形clothing deformation;从而更好的合成人穿衣的图片;



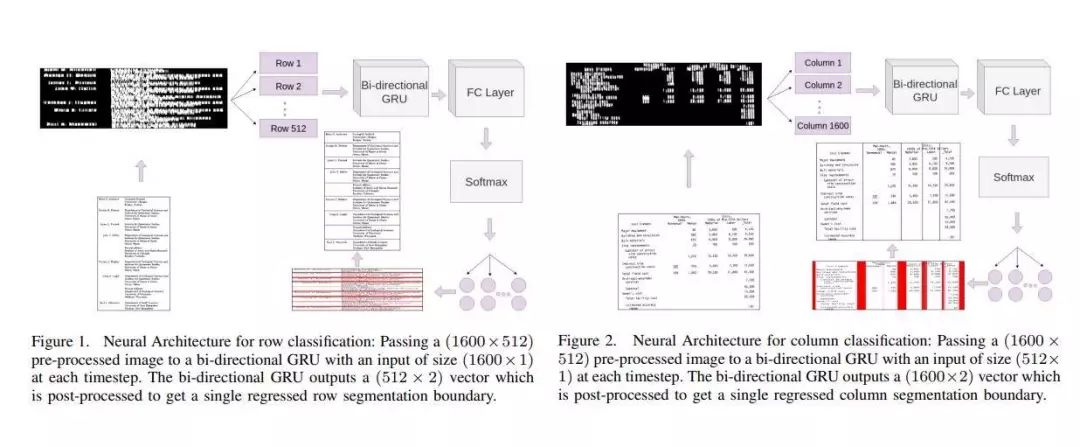
双向门控递归单元网络的表格结构提取
论文名称:Table Structure Extraction with Bi-directional Gated Recurrent Unit Networks
作者:Khan Saqib Ali /Khalid Syed Muhammad Daniyal /Shahzad Muhammad Ali /Shafait Faisal
发表时间:2020/1/8
论文链接:https://paper.yanxishe.com/review/8614
推荐理由:这篇论文要解决的是表格结构识别的问题。
表向读者呈现了汇总的结构化信息,这使表结构提取成为理解应用程序的重要组成部分。但是,表结构的识别是一个难题,这不仅是因为表布局和样式的变化很大,而且还因为页面布局和噪声污染水平的变化。已经进行了很多研究来识别桌子的结构,其中大部分是基于借助光学字符识别(OCR)将启发式方法应用于桌子的手抓布局特征的。由于表布局的变化以及OCR产生的错误,这些方法无法很好地概括。
在本文中,作者提出了一种基于鲁棒深度学习的方法,可以从文档图像中的检测表中高精度提取行和列。在提出的解决方案中,首先对表格图像进行预处理,然后将其馈送到具有门控循环单元(GRU)的双向循环神经网络,然后是具有最大软激活的完全连接层。网络从上到下以及从左到右扫描图像,并将每个输入分类为行分隔符或列分隔符。作者已经在公开的UNLV以及ICDAR 2013数据集上对作者的系统进行了基准测试,在该数据集上,其性能远远超过了最新的表格结构提取系统。这篇论文在公开的UNLV和ICDAR 2013数据集上进行了实验,验证了所提出的方法显著优于当前该领域的最佳方案。

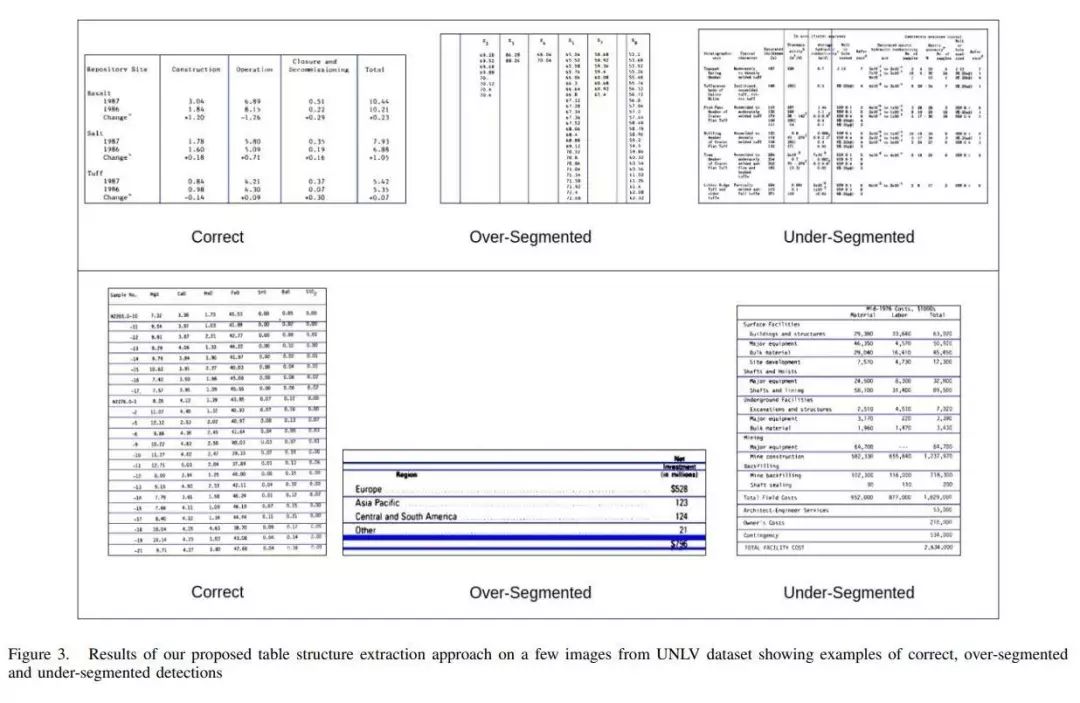
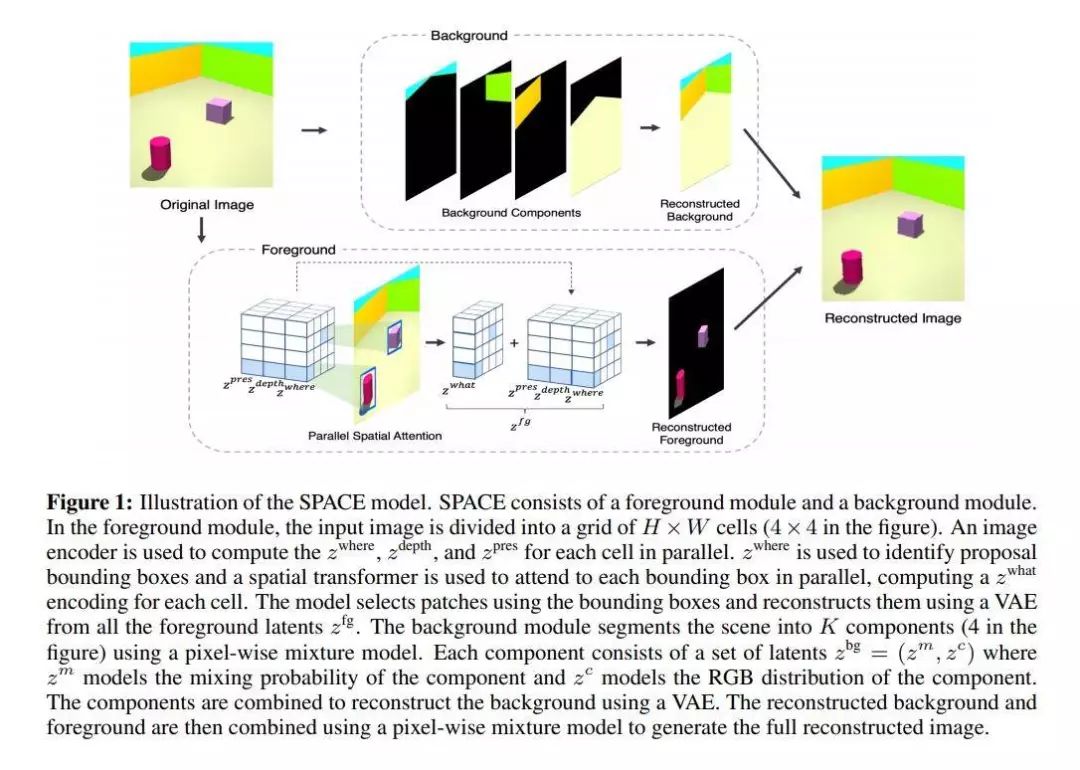
SPACE:通过空间注意和分解的无监督的面向对象的场景表示
论文名称:SPACE: Unsupervised Object-Oriented Scene Representation via Spatial Attention and Decomposition
作者:Lin Zhixuan /Wu Yi-Fu /Peri Skand Vishwanath /Sun Weihao /Singh Gautam /Deng Fei /Jiang Jindong /Ahn Sungjin
发表时间:2020/1/8
论文链接:https://paper.yanxishe.com/review/8615
推荐理由:这篇论文考虑的是多目标场景分解的问题。
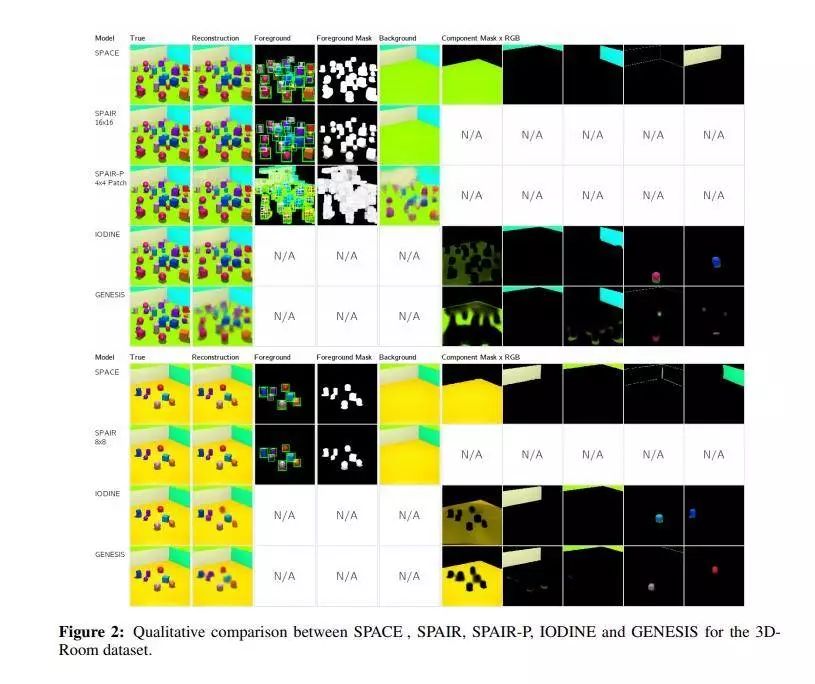
基于对象的场景表示学习的无监督方法可以分为基于空间注意力机制和基于场景混合这两类,然而这些方法都受限于可扩展性,阻碍了它们进一步应用于现实场景。这篇论文提出一个名为SPACE的生成潜在变量模型,以提供一套统一的概率建模框架来组合空间注意力与场景混合中的最佳方法。SPACE可以为前景对象提供精准的分解对象表示信息,同时分解复杂形态的背景片段。另外,SPACE也通过引入并行的空间注意力机制解决了扩展性问题,因而可以应用到含有大量对象的场景中。在Atari和3D-Rooms上的实验表明,SPACE与先前的方法SPAIR,IODINE和GENESIS相比具有更好的表现。作者们也提供了项目的网站(https://sites.google.com/view/space-project-page)。

基于云的图像分类服务对简单的转换不是很鲁棒:一个被遗忘的战场
论文名称:Cloud-based Image Classification Service Is Not Robust To Simple Transformations: A Forgotten Battlefield
作者:Goodman Dou /Wei Tao
发表时间:2019/6/19
论文链接:https://paper.yanxishe.com/review/8617
推荐理由:这篇论文考虑的是对基于云的图像分类服务的对抗样例生成问题。
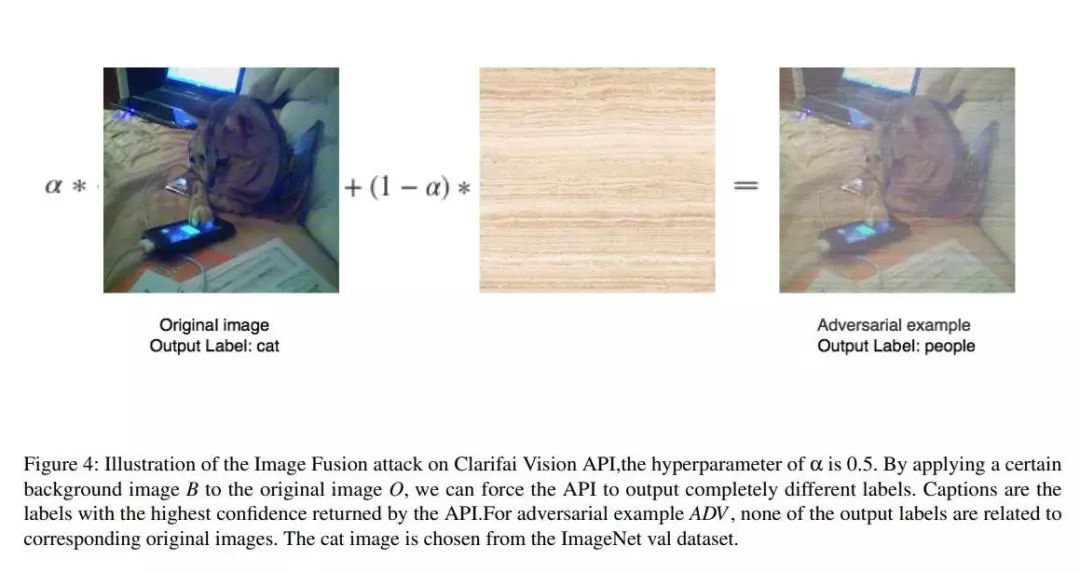
基于云的图像分类服务对于诸如高斯噪声、椒盐噪声、旋转和单色化之类的简单转换(ST)并不鲁棒。基于这一点,这篇论文提出了一个图像融合攻击(Image Fusion,IF)方法,利用OpenCV就可以实现,而且很难防御。这篇论文在Amazon,Google,Microsoft,Clarifai在内的四个流行云平台上评估了ST和IF方法,实验结果表明除了在Amazon上成功率在50%之外,ST在其他的平台上的攻击成功率都为100%,而IF方法在不同分类服务中的成功率均超过98%。



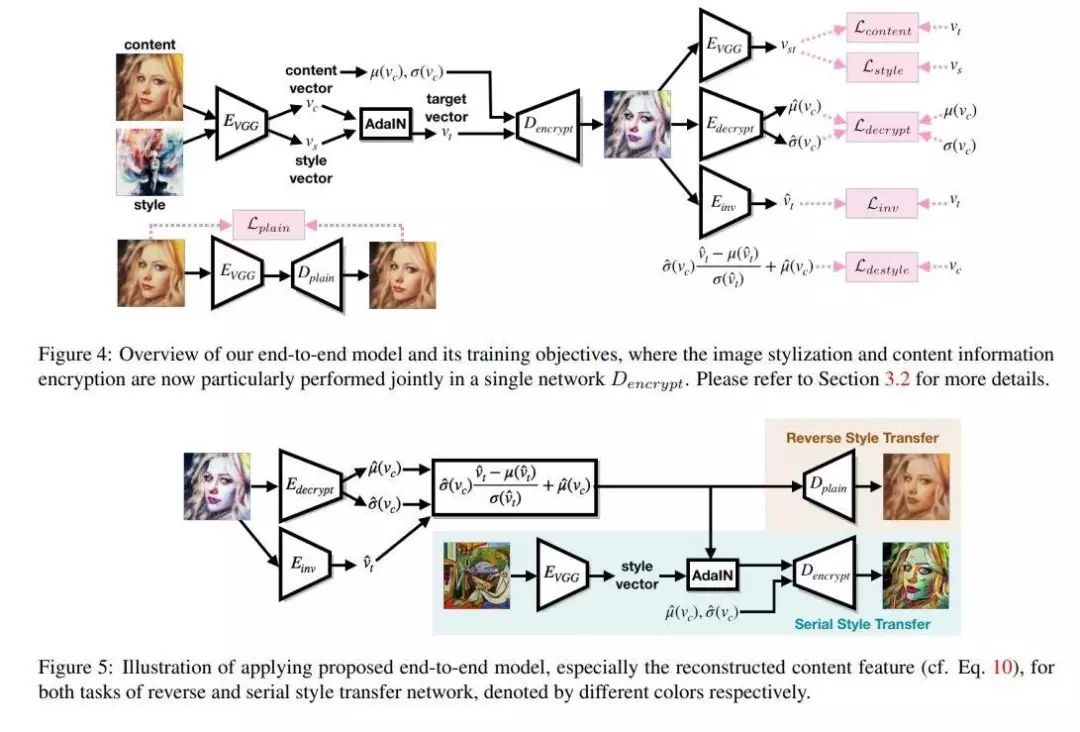
用于反向和串行风格迁移的通过隐写术进行的自包含样式化
论文名称:Self-Contained Stylization via Steganography for Reverse and Serial Style Transfer
作者:Chen Hung-Yu /Fang I-Sheng /Chiu Wei-Chen
发表时间:2018/12/10
论文链接:https://paper.yanxishe.com/review/8618
推荐理由:这篇论文考虑的是图像风格迁移的问题。
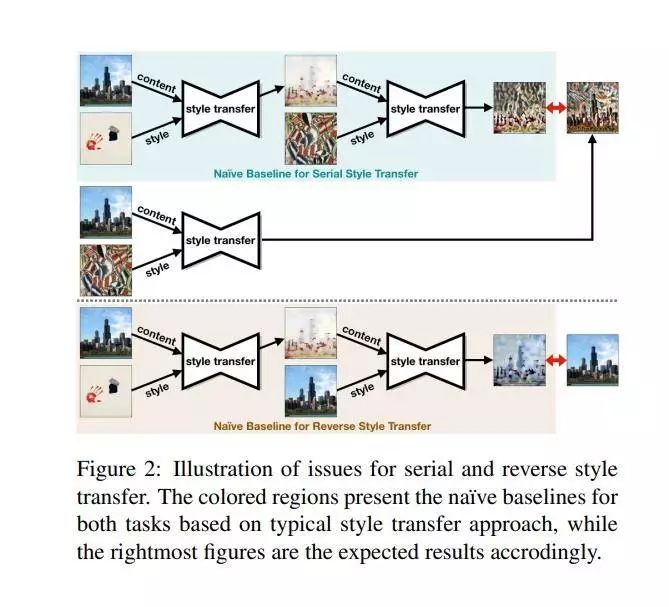
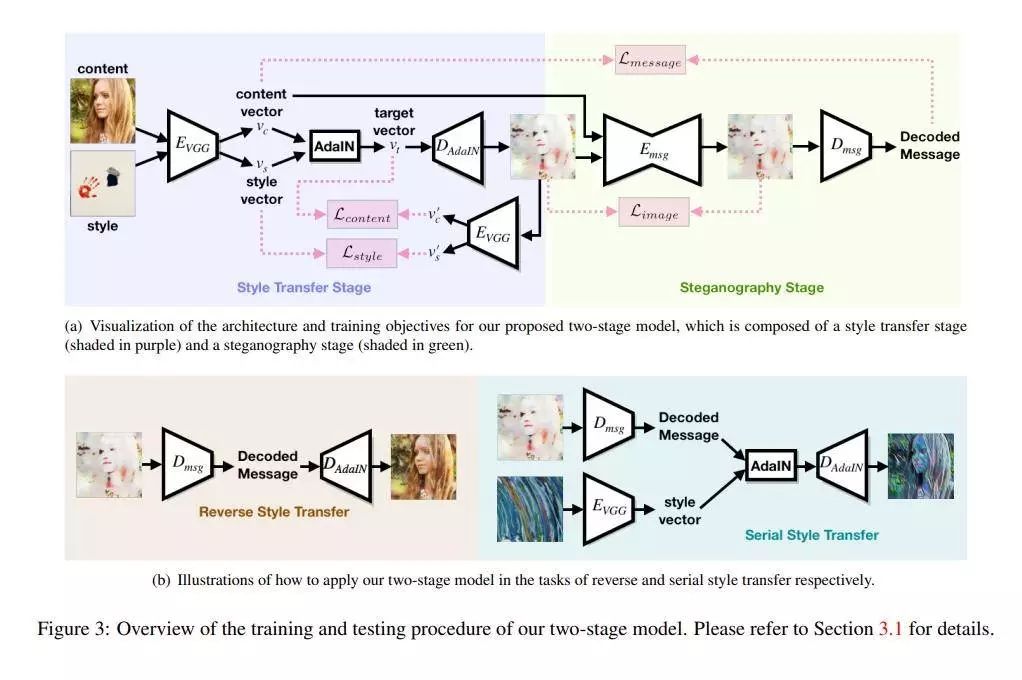
给定一个风格化的图像,使用典型的风格迁移方法进行去样式化或将其再次转换为另一种样式,通常会得到伪像或不良的结果。这篇论文认为这类问题是由于原始图像与其样式输出之间的内容不一致所导致的。这篇论文提出利用隐写术在迁移过程中保持输入图像内容信息,并提出了一个两阶段的方法和一个端到端的方法。实验结果表明这篇论文提出的方法不仅能生成与典型风格迁移方法所产生的图像质量相当的风格化图像,而且还可以有效消除重建原始输入时引入的伪像。



拓展阅读
由于篇幅有限,剩余五篇的论文推荐精选请扫描下方二维码继续阅读——
不要通过上下文来判断对象:学会克服上下文的偏见
论文名称:Don't Judge an Object by Its Context: Learning to Overcome Contextual Bias
node2vec 网络特征学习算法
论文名称:node2vec: Scalable Feature Learning for Networks
汇率可以用来预测上证指数吗?
论文名称:Can the Exchange Rate Be Used to Predict the Shanghai Composite Index?
自动驾驶车辆的协调:分类和综述
论文名称:Coordination of Autonomous Vehicles: Taxonomy and Survey
面向自动驾驶应用的三维目标检测方法综述
论文名称:A Survey on 3D Object Detection Methods for Autonomous Driving Applications

(扫码直达,可直接跳转下载论文)
阅读原文浏览剩余五篇论文推荐
↓↓↓


