加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
标题:
Multi-Task Template Matching for Object Detection, Segmentation and Pose Estimation Using Depth Image
s
作者:Kiru Park, Timothy Patten, Johann Prankl and Markus Vincze
摘要
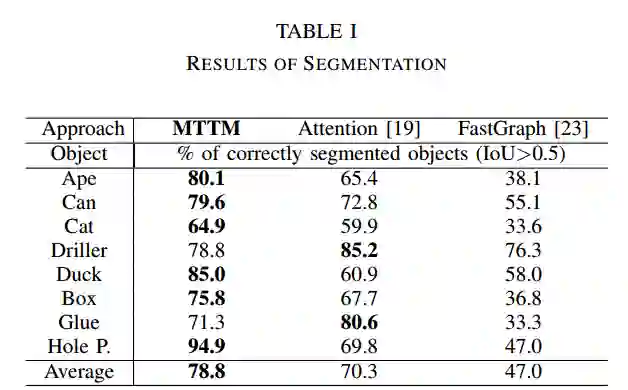
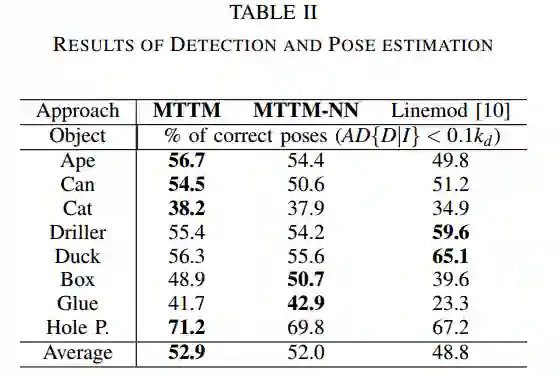
在有限数量的样本下,模板匹配可以准确估计新对象的姿态。然而,估计被遮挡物的位姿仍然是一件具有挑战性的事。此外,深度图像比彩色图像更适合应用于机器人领域常见的无纹理对象情况。在这篇文章中,我们提出了一种新的框架,多任务模板匹配(MTTM),它可以在使用对象区域的相同特征图预测分割掩码和场景中检测到的对象与模板之间的位姿转换时,从深度图像中找到目标对象最近的模板。提出的特征比较网络通过比较模板的特征图和场景的剪切特征来计算分割掩码和位姿预测。该网络的分割结果通过排除不属于该对象的点,提高了位姿估计的鲁棒性。实验结果表明,尽管仅使用深度图像,MTTM的结果仍优于基线方法对被遮挡对象进行分割和位姿估计。
图1 使用遮挡数据集[2]的样例结果。上:对给定ROI中心(绿色点)的分割结果。下:使用NN模板位姿的初始校准结果,以及五轮迭代之后的ICP结果。绿色的点和3D框表示地面真值位姿模型的点和边框。MTTM的预测掩码使ICP在物体被部分遮挡的情况下迭代结果更具有鲁棒性。
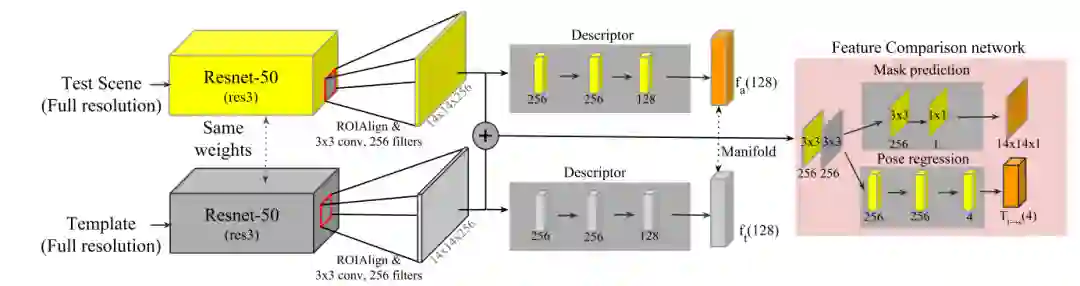
图2 MTTM的网络结构。黄色标识的层表示在测试时所需要的计算,因为模板特征已经经过预计算并存储在数据库中(灰色框)。
图3 在同一图像中,两个相似ROI的匹配结果。从不同类别检索NN模板会使掩码预测剧烈变化。颜色仅用于可视化。
图4 使用真实模板的MTTM样例结果。仅仅使用真实图像代替数据库,没有其他进一步的训练。为了更好的可视化效果,采用了彩色图像而不是实际的深度输入。学习到的特征可以应用于在训练网络时没有展示的物体。绿色边框代表地面真值位姿,红色边框代表预测位姿。
Template matching has been shown to accurately estimate the pose of a new object given a limited number of samples. However, pose estimation of occluded objects is still challenging. Furthermore, many robot application domains encounter texture-less objects for which depth images are more suitable than color images. In this paper, we propose a novel framework, Multi-Task Template Matching (MTTM), that finds the nearest template of a target object from a depth image while predicting segmentation masks and a pose transformation between the template and a detected object in the scene using the same feature map of the object region. The proposed feature comparison network computes segmentation masks and pose predictions by comparing feature maps of templates and cropped features of a scene. The segmentation result from this network improves the robustness of the pose estimation by excluding points that do not belong to the object. Experimental results show that MTTM outperforms baseline methods for segmentation and pose estimation of occluded objects despite using only depth images
-End-
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
觉得有用麻烦给个在看啦~ ![]()