CVPR2020 | 旷视提出Re-ID新方法,优化解决遮挡行人重识别问题
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:旷视研究院
IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 将于 6 月 14-19 日在美国西雅图举行。近日,大会官方论文结果公布,旷视研究院 16 篇论文被收录,研究领域涵盖物体检测与行人重识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D感知,GAN与图像生成,计算机图形学,语义分割,细粒度图像等众多领域,取得多项领先的技术研究成果,这与即将开源的旷视AI平台Brain++密不可分。
本文是旷视CVPR2020论文系列解读第 3 篇,为了获得遮挡ReID更加鲁棒的对齐能力,本文提出了一种新的框架,来学习具有判别力特征和人体拓扑信息的高阶关系。
IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 将于 6 月 14-19 日在美国西雅图举行。近日,大会官方论文结果公布,旷视研究院 16 篇论文被收录,研究领域涵盖物体检测与行人重识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D感知,GAN与图像生成,计算机图形学,语义分割,细粒度图像等众多领域,取得多项领先的技术研究成果,这与即将开源的旷视AI平台Brain++密不可分。
本文是旷视CVPR2020论文系列解读第 3 篇,为了获得遮挡ReID更加鲁棒的对齐能力,本文提出了一种新的框架,来学习具有判别力特征和人体拓扑信息的高阶关系。

-
论文名称:High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification -
论文链接:https://arxiv.org/abs/2003.08177
-
导语 -
简介 -
方法 -
语义特征提取 -
高阶关系学习 -
高阶人体拓扑学习 推理与训练
-
实验 -
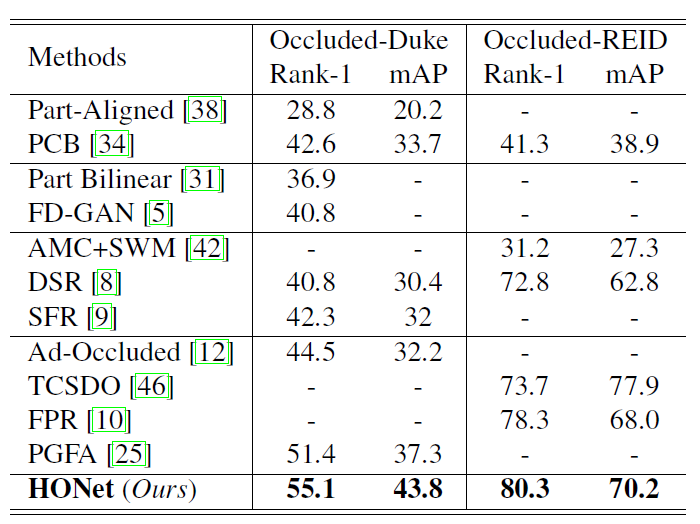
遮挡(Occluded)数据集结果 -
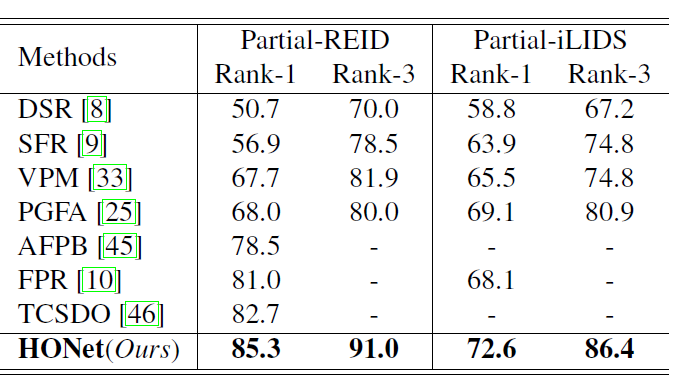
半身(Partial)数据集结果 -
全身(Holistic)数据集结果 -
结论 -
参考文献 -
往期解读
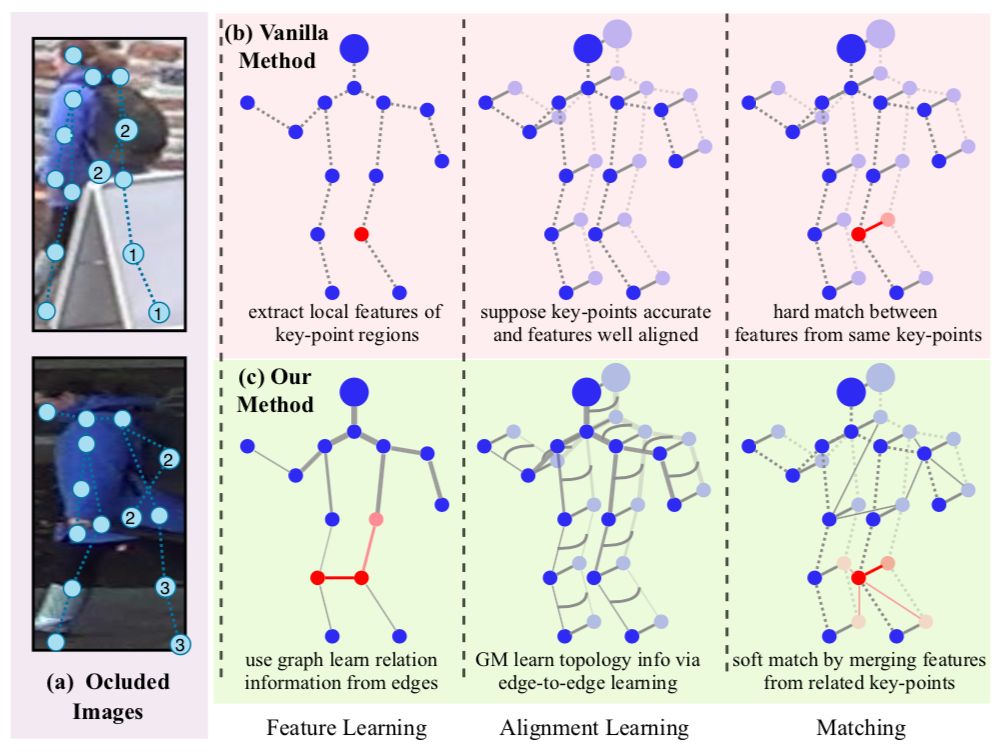
简介
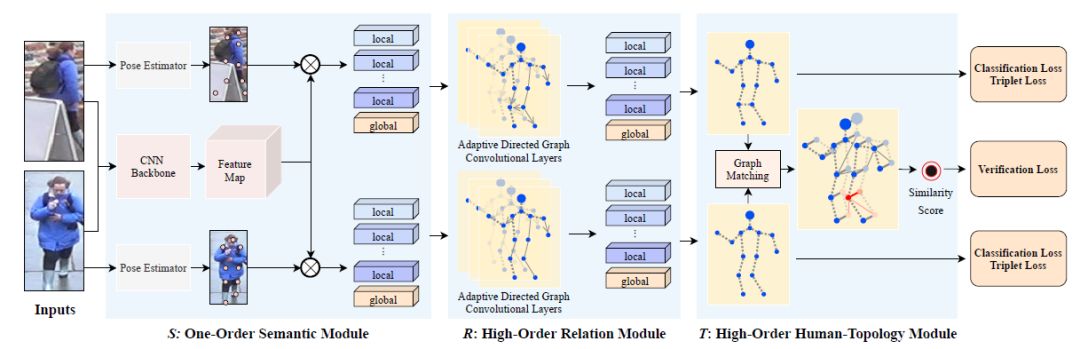
方法
语义特征提取
高阶关系学习
高阶人体拓扑学习
训练与推理
实验
遮挡(Occluded)数据集结果
半身(Partial)数据集结果
全身(Holistic)数据集结果
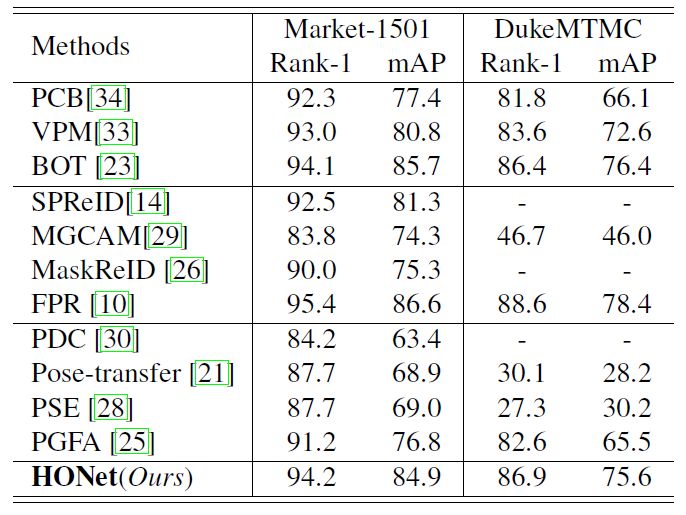
结论
参考文献
-
Shaogang Gong, Marco Cristani, Shuicheng Yan, and Chen Change Loy. Person Re-Identification. 2014. -
Liang Zheng, Yi Yang, and Alexander G Hauptmann. Per- son re-identification: Past, present and future. arXiv preprint arXiv:1610.02984, 2016. -
Jiaxuan Zhuo, Zeyu Chen, Jianhuang Lai, and Guangcong Wang. Occluded person re-identification. In 2018 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2018. -
Jiaxu Miao, Yu Wu, Ping Liu, Yuhang Ding, and Yi Yang. Pose-guided feature alignment for occluded person re-identification. In ICCV, 2019. -
Lingxiao He, Jian Liang, Haiqing Li, and Zhenan Sun. Deep spatial feature reconstruction for partial person re- identification: Alignment-free approach. pages 7073–7082, 2018. -
Lingxiao He, Yinggang Wang, Wu Liu, Xingyu Liao, He Zhao, Zhenan Sun, and Jiashi Feng. Foreground-aware pyra- mid reconstruction for alignment-free occluded person re- identification. arXiv: Computer Vision and Pattern Recogni- tion, 2019.
重磅!CVer-ReID 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-Re-ID 微信交流群,目前已汇集270人!互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Re-ID+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
麻烦给我一个在看!
登录查看更多
相关内容




相关VIP内容
相关资讯