学术派 | 用深度学习实现 2D 到 3D 的转换

面临的挑战
数据集质量
3D介质中包含大量不符合真实视差关系的双目视图受相机参数的影响,同类场景的视差在不同的 3D 介质中不统一
帧间抖动
场景多样化,需要保证视差预测的连续性与准确性重构视图的遮挡区域空洞的填补
3D 效果的评价指标难以量化
同类场景具有不同的并且满足真实世界的视差关系3D 效果依靠人工评价,过于主观
模型原型思路
通过对大量用户的调研发现,除去特效场景刺激眼球外,3D 介质的 3D 感知越符合真实世界越受用户喜爱,因此在模型构建上必须符合真实世界的 3D 观感——双目视觉
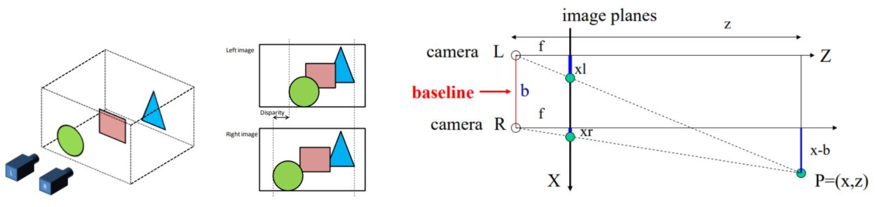
图1双目相机成像与视差原理
如图 1 左所示,两个相机拍摄同一场景生成的图像会存在差异,这种差异叫视差,其产于与真实的三维空间。视差不能通过平移消除,同时离相机近的物体视差偏移较大,反之越小。
人的左右眼就如同图中的左右相机一样,分别获取对应图像后,通过大脑合成处理这种差异,从而获取真实世界的 3D 感知,通过图 1 右可得出视差与相机焦距和轴间距间的关系:
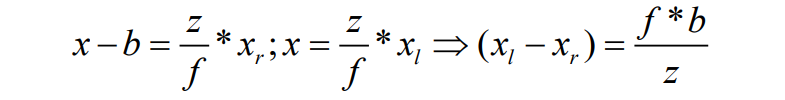
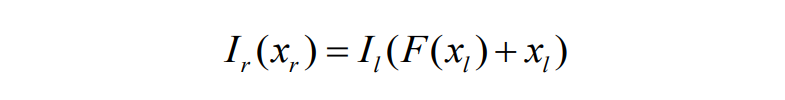
通过公式(2)可知,只需要将 图1左 作为训练输入,图1右 作为参考,即可建立深度学习模型,通过大量双目图片对训练估计出函数𝐹。这样就可在已知相机参数 (𝑏,𝑓) 的前提下获取对应的深度值𝑧,完成单目深度估计的任务。
通过公式(1)与公式(2)可以发现,深度与视差成反比,因此深度估计和视差估计的方法可以互用。Deep3D[1] 虽然通过视差概率估计实现2D到3D介质的转换,但固定视差的设定,难以适应不同分辨率2D介质输入;
方法[2]没有充分利用双目信息作指导,景深不够细;monodepth[3] 在方法[2]的基础上,充分利用了双目信息进行对抗指导,学习到更多深度细节;
SfmLearner[4] 这类方法引入帧间时序信息,结构较复杂,运行速度慢。因此通过实现及适用性考虑最终我们选择以 monodepth 为 baseline,其框架结构如图2所示:
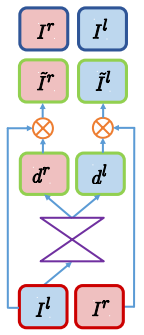
解决相机问题
在 Baseline 模型的基础上,如果直接使用混合的 3D 电影数据集进行训练,模型将无法收敛或预测不稳定,一个最主要的问题是不同电影使用不同相机参数的摄像机进行拍摄,即使两个非常相似的电影场景,在不同的两部电影中也会有不同的景深分布,表现在模型训练中即为不同的视差值。
与此同时,不同电影的后处理方式,以及会聚相机的引入,会进一步增加建模的难度。在分析相似案例的处理方法中,我们发现可以通过引入条件变分自编码器(CVAE),在训练过程中,把每一组训练集(左右视图)通过网络提取其相机参数等信息,并作为后验信息通过 AdaIN[5] 的形式引入到单目(左视图)视差图预测中,同时参考[6]中的“双轮训练”,保证了测试时随机采样相机参数分布的正确性。
解决抖动问题
在解决数据集问题后,进行连续帧预测时,发现存在预测不稳定及抖动的问题。在解决视频生成过程(尤其是连续帧深度图预测)的抖动问题中,目前最为常见的方案包含基于帧间 ConvLSTM 的[7]和[8]和基于光流的[9]和[10]。其中,[8]在不同尺度的编码和解码的过程中均加入 ConvLSTM,隐式的利用时间域上特征的相关性来稳定的预测深度图,而[7]则仅在网络输出的最后一层引入 ConvLSTM。
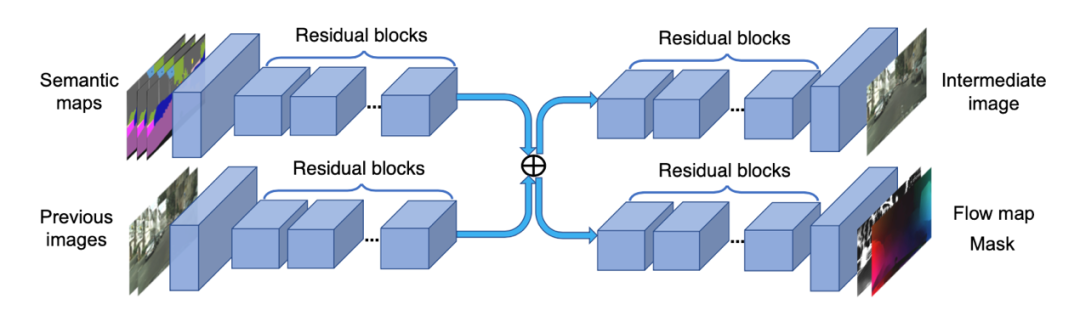
其中,在中间高维特征合并处引入上文提及的 CVAE 模块,用以引入后验相机参数信息。最终,在解决相机参数导致数据集问题的同时,模型能够得到稳定且连续的视差图输出。
解决“空洞”填补问题
由于新视角的生成,会使部分原本被遮挡的区域在新视角中显露出来,这些信息仅从左视图中是无法获取的,即使通过前后帧的光流信息也很难还原。在生成新视角的后处理过程中,我们参考[11]的模型框架设计,通过视差图来指导获取产生的“空洞”区域,通过图像修补技术解决新视角的“空洞”问题。
3D 效果测评 由于拍摄条件不同会导致 3D 效果不同,所以在 2D 转 3D 效果测评中,我们用大量人力对预测的视差图和成片在 VR 中的 3D 效果进行综合性的评测。视差图估计如图4:

图4 各种场景下的单目视差估计
应用扩展
不仅如此,视差图的预测也能转化为相对深度值,被应用到其他方面,例如 3D 海报。3D 海报是一张 2D 图片加上其深度关系图,通过一系列的新视点渲染,得到一组动态的,人能感知的立体影像。如图5与图6所示:


References
[1]Xie J, Girshick R, Farhadi A. Deep3d: Fully automatic 2d-to-3d video conversionwith deep convolutional neural networks[C]//European Conference on ComputerVision. Springer, Cham, 2016: 842-857.
[2]Garg R, BG V K, Carneiro G, et al. Unsupervised cnn for single view depthestimation: Geometry to the rescue[C]//European Conference on Computer Vision.Springer, Cham, 2016: 740-756.
[3] Godard C, Mac Aodha O, Brostow G J. Unsupervisedmonocular depth estimation with left-right consistency[C]//Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition. 2017: 270-279.
[4] Zhou T, Brown M, Snavely N, et al. Unsupervised learningof depth and ego-motion from video[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition. 2017: 1851-1858.
[5] Huang X, Belongie S. Arbitrary style transfer inreal-time with adaptive instance normalization[C]//Proceedings of the IEEEInternational Conference on Computer Vision. 2017: 1501-1510.
[6] Zhu J Y, Zhang R, Pathak D, et al. Toward multimodal image-to-imagetranslation[C]//Advances in neural information processing systems. 2017:465-476.
[7] Zhang H, Shen C, Li Y, et al. Exploitingtemporal consistency for real-time video depth estimation[C]//Proceedings ofthe IEEE International Conference on Computer Vision. 2019: 1725-1734.
[8] Tananaev D, Zhou H, Ummenhofer B, et al. TemporallyConsistent Depth Estimation in Videos with RecurrentArchitectures[C]//Proceedings of the European Conference on Computer Vision(ECCV). 2018: 0-0.
[9] Lin J, Gan C, Han S. Tsm: Temporal shift module forefficient video understanding[C]//Proceedings of the IEEE InternationalConference on Computer Vision. 2019: 7083-7093.
[10] Wang T C, Liu M Y, Zhu J Y, et al. Video-to-videosynthesis[J]. arXiv preprint arXiv:1808.06601, 2018.
[11]Yu J, Lin Z, Yang J, et al. Free-form imageinpainting with gated convolution[C]//Proceedings of the IEEE InternationalConference on Computer Vision. 2019: 4471-4480.
欢迎加入 DataFunTalk 人工智能 技术交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信(微信号:DataFunTalker),回复:人工智能,逃课儿会自动拉你进群。
关于我们:

一个在看,一段时光!👇



