【AAAI专题】上篇:BRAVE组系列研究进展之“视听模态的融合”



紫冬君将在接下来的3天连续推出BRAVE组系列研究进展之上篇“视听模态的融合”、中篇“视听模态的生成”、下篇“智能体之间的知识迁移”,今日聚焦上篇---“视听模态的融合”。研究组提出了有效将听觉信息融合在视频描述生成框架中的特征融合策略,并取得了理想的效果。
上篇:视听模态的融合

视频描述生成在很多领域中有着潜在应用,比如人机交互、盲人辅助和视频检索。近些年来,受益于卷积神经网络CNN,递归神经网络和大规模的视频描述数据集,视频描述生成已经取得比较理想的结果。
大多数视频描述生成框架可以分为一个编码器和一个解码器,编码器对视频特征进行编码形成一个固定长度的视频特征向量,解码器基于该视频特征生成对应的视频描述子。研究者们针对定长的视频特征描述子提出了一些方法,比如对视频帧进行池化操作,下采样固定长度的视频帧,在递归网络视频特征编码阶段提取最后一个时刻的状态表示。
虽然上述方法均可生成比较合理的视频描述,但是这些模型的视频特征编码都只侧重于视觉信息而忽略了音频信息。我们认为,忽视声音模态会损害模型性能。比如,一个人躺在床上唱歌。大部分传统的视频描述生成方法只关注视觉信息而忽略声音信息,可能会产生语义不完整的句子:“一个人躺在床上”。如果可以将音频信息结合到模型中,就可以产生语义完整的句子“一个人躺在床上唱歌”。
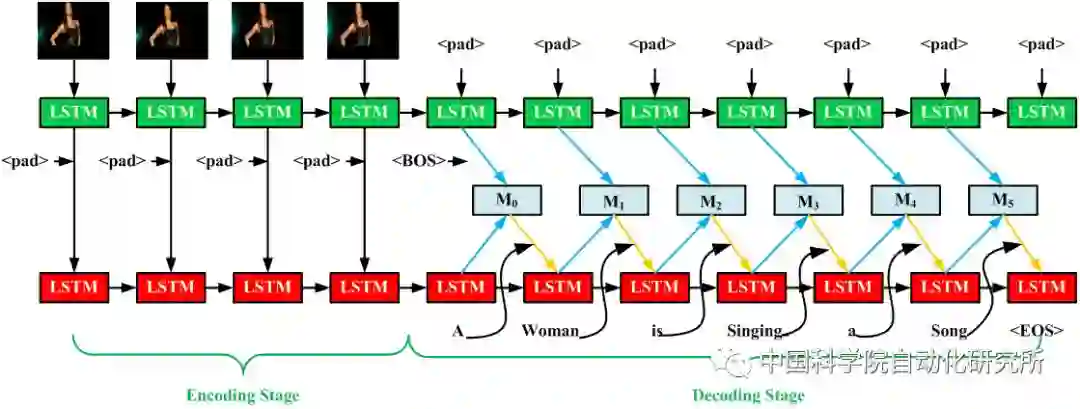
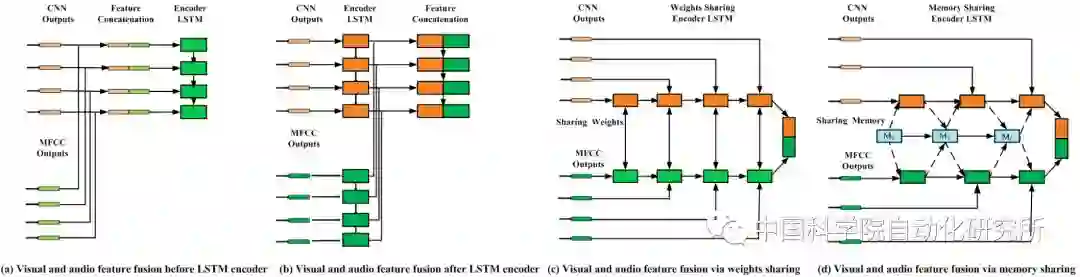
那么如何更合理地利用视听觉信息?我们提出并分析了三种视听觉特征深度融合框架,第一种为将视听觉信息简单并连在一起,第二种在视听特征编码阶段共享LSTM内部记忆单元,建立视听模态间的短时依赖性,第三种在视听特征编码阶段共享外部记忆单元,建立视听模态的长时依赖性。
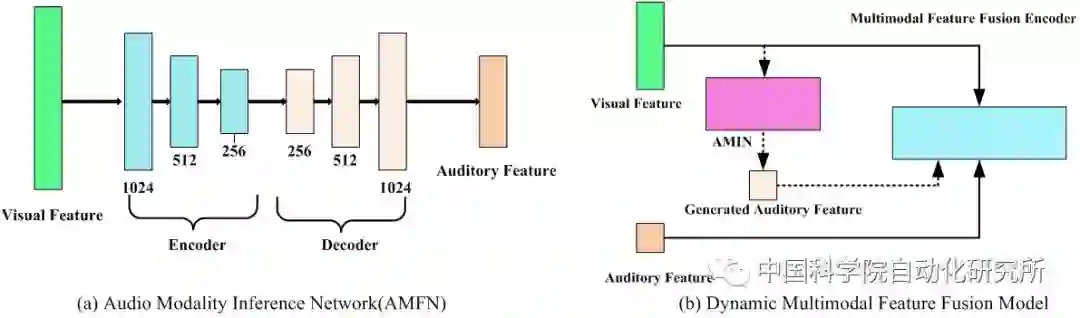
同时,为了处理听觉模态缺失问题,我们提出了一个动态多模态特征融合框架。其核心模块为由一个编码器和一个解码器组成的听觉推理模型。听觉推理模型具体为将视觉特征输入编码器进行编码,利用解码器解码出对应的听觉特征,通过在生成的听觉特征与真实的听觉特征之间增加L2范数约束来更新该模型参数,并实现视觉特征到听觉特征的准确映射。
a. 我们提出三种视听觉特征融合策略,旨在有效地将听觉信息融合在视频描述生成框架中。
b.我们提出一个听觉推理模型去解决听觉模态缺失问题,当听觉模态损害或缺失时,视觉模态可作为推理依据。
c. 我们的模型在MSR-VTT , MSVD数据集上取得了理想的效果。
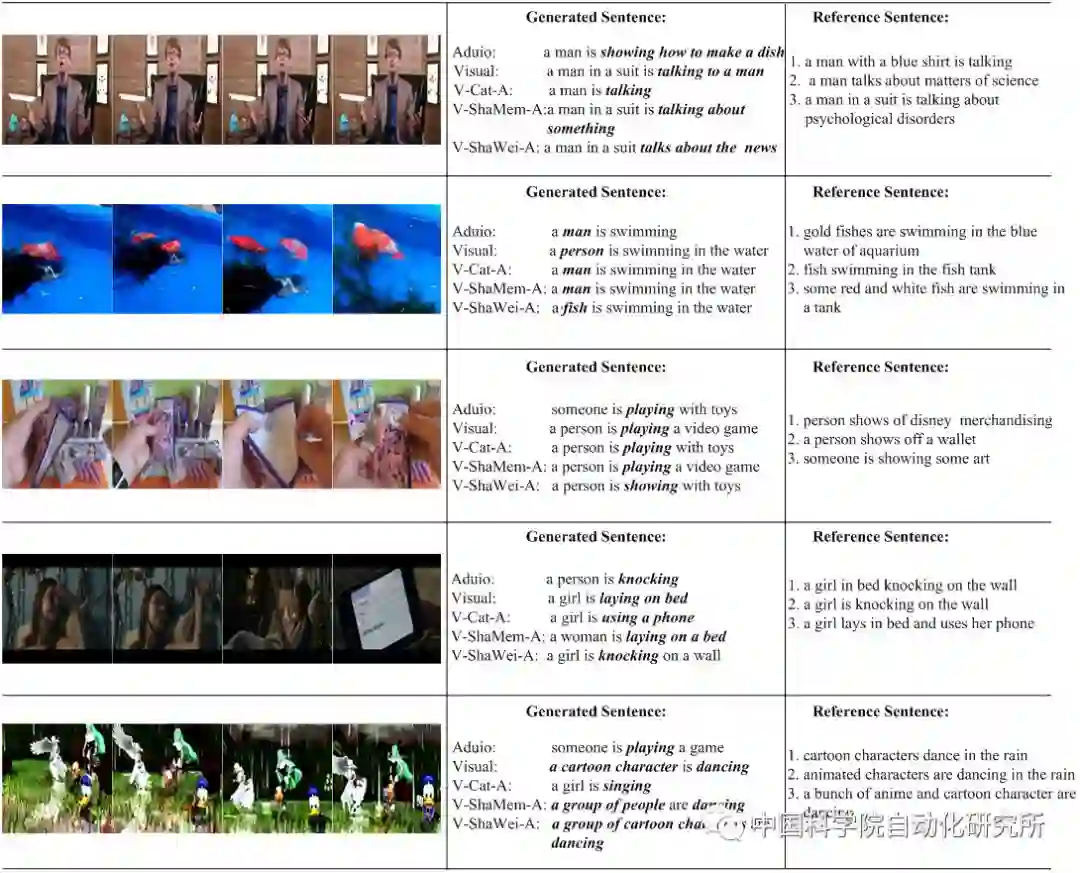
不同模型生成的视频描述

不同模型生成的视频描述
上篇:视听模态的融合
Wangli Hao, Zhaoxiang Zhang*, He Guan, Integrating both Visual and Audio Cues for Enhanced Video Caption, The Thirty-Second AAAI Conference on Artificial Intelligence, AAAI 2018, USA, February 2-7, 2018
中篇:视听模态的生成 (明天聚焦)
Wangli Hao, Zhaoxiang Zhang*, He Guan, CMCGAN: A Uniform Framework for Cross-Modal Visual-Audio Mutual Generation, The Thirty-Second AAAI Conference on Artificial Intelligence, AAAI 2018, USA, February 2-7, 2018
下篇:智能体之间的知识迁移(后天聚焦)
Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang*, DarkRank: Accelerating Deep Metric Learning via Cross Sample Similarities Transfer; The Thirty-Second AAAI Conference on Artificial Intelligence, AAAI 2018, USA, February 2-7, 2018

更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
来源:BRAVE研究组
编辑:欧梨成


中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!


