疫情期间网民情绪识别比赛后记

写在前面
前阵子参加了 DataFountain 举办的 疫情期间网民情绪识别[1] 比赛,最终成绩排在第 20 名,成绩不是太好,本文就是纯粹记录一下,遇到太年轻的想法,请大牛笑笑就好。
前排大佬的方案还没出来,在这边抛泥引玉一下。
赛题介绍
给定微博ID和微博内容,设计算法对微博内容进行情绪识别,判断微博内容是积极的、消极的还是中性的。这其实就是个典型的文本分类问题,把一段短文本分成三类。
数据样例
| 微博id | 微博发布时间 | 发布人账号 | 微博中文内容 | 微博图片 | 微博视频 | 情感倾向 |
|---|---|---|---|---|---|---|
| 4456072029125500 | 01月01日 23:50 | 存曦1988 | 写在年末冬初孩子流感的第五天,我们仍然没有忘记热情拥抱这2020年的第一天。带着一丝迷信,早... | ['https://ww2.sinaimg.cn/orj360/005VnA1zly1gah... | [] | 0 |
| 4456074167480980 | 01月01日 23:58 | LunaKrys | 开年大模型…累到以为自己发烧了腰疼膝盖疼腿疼胳膊疼脖子疼#Luna的Krystallife#? | [] | [] | -1 |
| 4456054253264520 | 01月01日 22:39 | 小王爷学辩论o_O | 邱晨这就是我爹,爹,发烧快好,毕竟美好的假期拿来养病不太好,假期还是要好好享受快乐,爹,新年快乐... | ['https://ww2.sinaimg.cn/thumb150/006ymYXKgy1gahft9xvnbj31o00u0jxt.jpg... | [] | 1 |
| 4456061509126470 | 01月01日 23:08 | 芩鎟 | 新年的第一天感冒又发烧的也太衰了但是我要想着明天一定会好的? | ['https://ww2.sinaimg.cn/orj360/005FL9LZgy1gahgp9gv71j31z41hce82.jpg'] | [] | 1 |
| 4455979322528190 | 01月01日 17:42 | changlwj | 问:我们意念里有坏的想法了,天神就会给记下来,那如果有好的想法也会被记下来吗?... | [] | [] | 1 |
基本模型
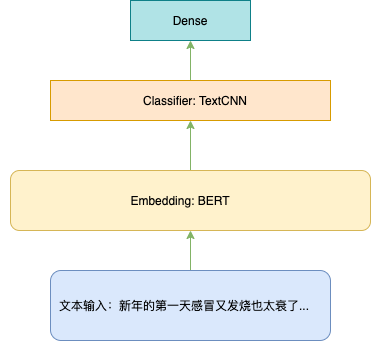
首先文本数据 shape = (None, max_len) 经过 Embedding 层后,shape = (None, max_len, embedding_dim) 此时文本被表征为一系列的向量,后接 TextCNN 后可以变成 shape = (None, dim) 目的是把一系列的向量编码成一个向量,并且这个向量包含了整个文本的语义信息,最后接 softmax 就可以得到三分类的概率分布了。
有的同学就会说了,你说的词 Embedding 我知道呀,就是把文本中词(或字)的序列变成向量的序列并且保留了语义信息,然后丢分类器里面分类,那你说的 BERT 是什么鬼?其实介绍 BERT 的文章网上有很多啦,如果你想搞关于文本分类的任务,不能不了解 BERT。那些东西搞得你云里雾里,是不是就不能用了?也不是,如果你现在先不了解 BERT 我可以告诉你,你只要记住,他用起来的时候,其实和 Embedding 一样,输入是你的文本,输出也是一系列的向量 shape = (None, max_len, embedding_dim)。
我觉得如果要完全理解复杂的理论,还是要多看多做多想,不能糊弄自己。如果刚开始理解不了,可以尝试先用起来,做的任务多了,再回过头来看,可能又有新的理解了。这是我的笨办法。
关于模型的构建,直接看代码会更加清晰一些:
class SentimentClfModel(tf.keras.Model):
def __init__(self, config, **kwargs):
super(SentimentClfModel, self).__init__(**kwargs)
self.config = config
self.bert_model_config = transformers.BertConfig. \
from_pretrained(self.config.bert_path+'bert-base-chinese-config.json')
self.bert_model = transformers.TFBertModel. \
from_pretrained(self.config.bert_path+'bert-base-chinese-tf_model.h5',
config=self.bert_model_config)
self.textcnn = TextCNN(kernel_sizes=self.config.kernel_size, filter_size=self.config.filter_size,
activation=self.config.activation, dropout_rate=self.config.dropout_rate)
self.linear = Dense(len(self.config.kernel_size) * self.config.filter_size, activation=self.config.activation)
self.layer_norm = LayerNormalization(axis=-1, center=True, scale=True)
self.dropout = Dropout(self.config.dropout_rate)
self.out = Dense(len(self.config.labels), activation='softmax')
def call(self, inputs):
input_ids, input_mask, token_type_ids = inputs
embedding, _ = self.bert_model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
textcnn_out = self.textcnn(embedding)
linear_out = self.linear(textcnn_out)
add_norm = self.layer_norm(add([textcnn_out, linear_out]))
add_norm = self.dropout(add_norm)
output = self.out(add_norm)
return output
def compute_output_shape(self, input_shape):
return (None, len(self.config.labels))
Trick 1 - F1 指标优化
简单的后处理优化
这个 idea 来源与包大人的这篇公众号文章 Kaggle进阶:显著提分trick之指标优化[2] ,同时 baseline 模型也是包大人提供的,包大人的公众号干货满满,你还不关注一下。
对于类别不均衡问题,交叉熵得到的结果不是最优的,此时我们得到一个估计的概率分布向量 。
现在我们假设有权重向量 , 使得 F1-macro 指标最大。
函数 是衡量指标,在这里具体是 F1-macro。如果我们能求出 就可以对概率分布向量 进行后处理优化。
具体代码如下:
from functools import partial
import numpy as np
import scipy as sp
from sklearn.metrics import f1_score
class OptimizedMacroF1Rounder:
def __init__(self, num_labels):
self.coef_ = 0
self.num_labels = num_labels
def _f1_loss(self, coef, X, y):
X_p = np.copy(X)
pred = np.argmax(X_p * coef, axis=1)
macro_f1 = f1_score(y, pred, average="macro")
return -macro_f1
def fit(self, X, y):
loss_partial = partial(self._f1_loss, X=X, y=y)
initial_coef = [0.1, 0.7, 0.2]
self.coef_ = sp.optimize.minimize(loss_partial, initial_coef, method='nelder-mead')
def predict(self, X, coef):
X_p = np.copy(X)
X_p = X_p * coef
X_p = np.argmax(X_p, axis=1)
return X_p
def predict_proba(self, X, coef):
X_p = np.copy(X)
X_p = X_p * coef
return X_p
def coefficients(self):
return self.coef_.x
端到端的优化 F1-loss
因为 F1 不可导,所以无法用作损失函数,那我们是否可以光滑化 F1 函数去逼近真正的 F1 呢?是可以的,感兴趣的同学可以读一读苏老师的这篇文章 函数光滑化杂谈:不可导函数的可导逼近[3],直接甩链接不是因为我懒,是因为苏老师讲的比我好多了。
苏老师是我最爱的宝藏博主之一,平时很多有用有趣的 idea 都会在博客上更新,而且在下面留言他回答问题特别热心。
需要注意的是先用普通的交叉熵训练到差不多了,然后再用f1的相反数作为loss来微调。
这种方法效果不一定好,看别人比赛说用了有提升,我自己用的时候就大翻车,后来放弃了,这也太真实了。
Trick 2 - 伪标签
这个 trick 其实也很简单,就是最后把你做的最好的模型,用来预测测试数据,然后再用这些数据和你原本的数据混在一起训练模型。注意必须保证训练的时候你制造伪标签的数据必须在训练集里面。这部分操作完整代码会有体现。
训练流程
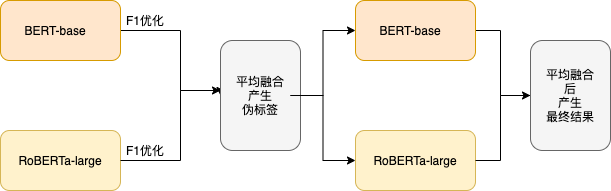
-
训练 BERT-base 和 RoBERTa-large 得到后分别进行 F1 指标优化 -
利用优化后的概率取平均输出伪标签 -
使用伪标签 + 原有训练数据再训练以上两个模型再取结果的平均值。
训练这么多参数的模型,一般显卡是跑不起的,在此介绍一个优质的算力平台 openbayes[4]。
在这边你只需要上传数据和代码,设置算力容器的运行环境,把数据集绑定容器后运行代码就可以直接训练模型,不需要自己配置环境,而且都是界面化操作,非常友好。
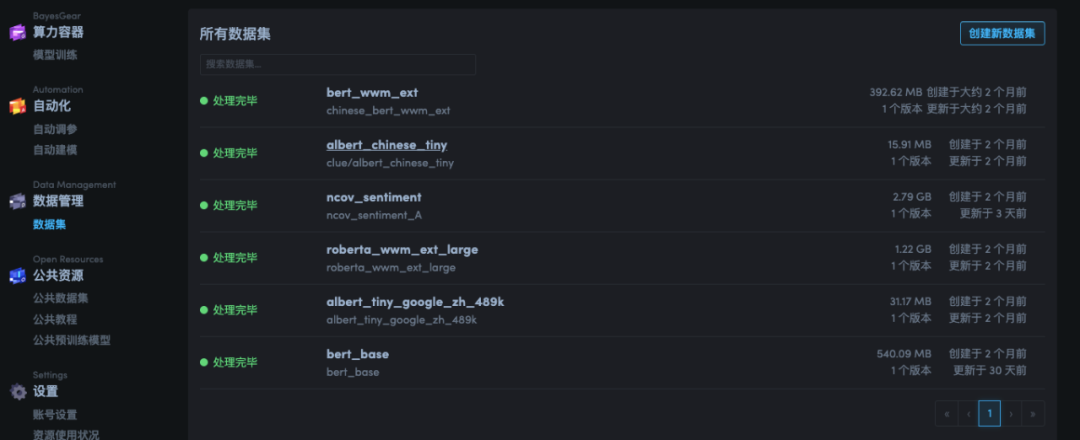
创建数据集
参考这里 数据集管理[5] 把需要用到的训练数据和预训练模型都上传。
上传完毕后可以看到自己的数据集
创建算力容器
创建算力容器[6]有两种方式,一种是直接点选算力容器根据提示创建后,进入 jupyter lab 即可,比较简单。
还有一种是命令行的方式,需要安装 bayes 命令行工具[7] 。根据文档安装完毕并登陆完成后,可以在本地提交需要运行的代码。
cd 到你的工作目录 执行
bayes gear init ${container_id}
进行容器的初始化, 你的文件夹里面就创建了 openbayes 容器相关的文件

其中 .openbayesignore 与 .gitignore 类似,用来配置你不想上传的文件规则。
如果有依赖包需要安装,创建一个文件 openbayes_requirements.txt 原理和 requirements.txt 一样,里面写要安装的包,创建容器时会自动安装。
然后重点讲下 .openbayes.yml 这个是 openbayes 的配置文件,打开它填写里面的信息来配置 绑定的数据
data_bindings:
- data: lumos/ncov_sentiment/1
path: /input0
- data: lumos/bert_base/1
path: /input1
## resource
# 指使用什么算力容器,通过命令 bayes gear resource 可以看到支持的算力类型
#
resource: t4
## env
# 指使用什么运行时环境,通过命令 bayes gear env 可以查看支持的运行时环境
#
env: tensorflow-2.0.0
## command
# 只有在创建「脚本执行」时需要,指任务执行时的入口命令
#
command: "python train.py --model=BERT_base --use_multi_gpu=False --use_pl=True"
data 需要对应的是 你的用户id/数据集名称/数据集版本号 path 对应的是引入此数据集在容器中的路径,例如这里第一个数据集对应的就是 /openbayes/input/input0
resource 选择对应的算力容器资源 单卡 t4
env 选择对应的深度学习训练框架环境 这里使用 tensorflow 2.0
command 你需要执行的入口命令 这里启动训练脚本
执行训练任务
一起准备就绪后 执行
bayes gear run task -f
就可以等待上传代码后执行脚本,命令行中同步跟踪执行日志
登陆 web 界面查看容器,可以监控资源利用率和查看日志
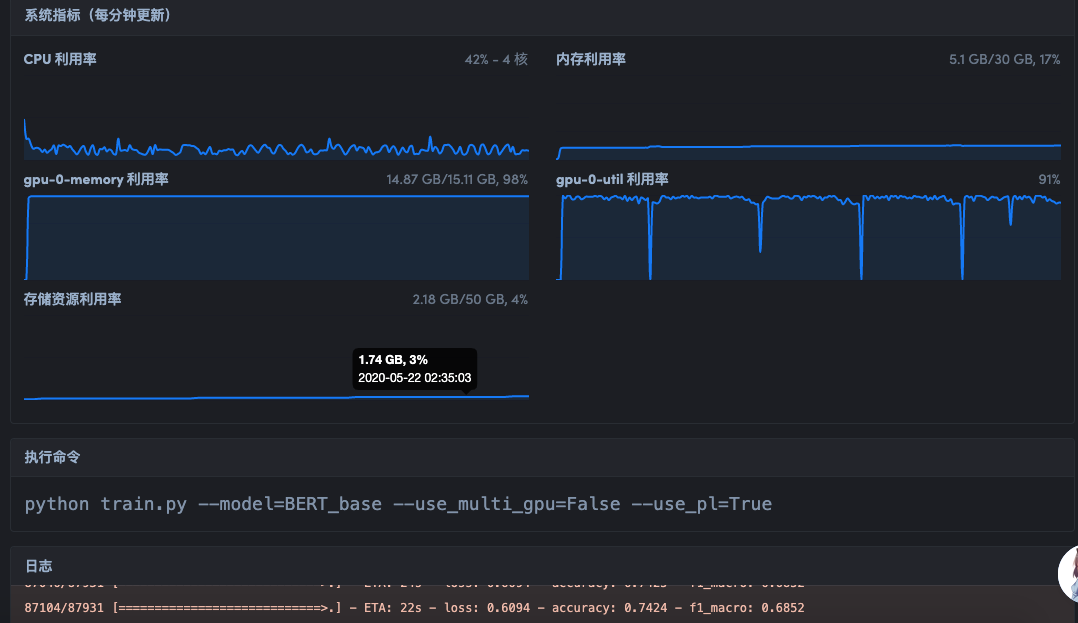
可以看到 gpu 利用率打满,芜湖,起飞~
技巧丑陋却有用
有的同学会问,我不接 TextCNN, 我想接 LSTM GRU 行不行?接,都可以接。
你可能会遇到一个问题,如果循环跑 k-fold 的时候你跑完一个 fold 可能显存 OOM,能跑完一个 fold 证明显存是够用的,只是没清干净。
我试了很多方法,什么 K.clear_session() gc.collect() 这些方法根本没用。最后我研究了一下 python 脚本执行完了之后资源肯定会释放的,那么我们可以用 shell 脚本来调 python 脚本,预先准备好要训练的数据,然后用 shell 把参数穿进 python 控制 k-fold 运行即可。
#!/bin/bash
python roberta_gru_pl_data.py;
for f in {0..4}
do
python roberta_gru_pl_finetune.py ${f}
done
echo "5 fold training finished"
这里 roberta_gru_pl_data.py 先生成了 k-fold 要用到的数据,然后训练脚本根据 fold number 读入数据进行训练,重复 k 次。这种方法虽然丑陋了点,但是解决了显存无法释放的问题。
代码分享
代码放在 https://github.com/ZhiWenMo/ncov_sentiment_classification
基于 tensorflow 2.0 亲自测试过,感兴趣的同学自取~
预训练模型下载地址:
https://huggingface.co/bert-base-chinese
https://huggingface.co/hfl/chinese-roberta-wwm-ext-large
虽然模型方面没什么创新,但是代码里面基本涉及到分类的一般套路包括:数据预处理、自定义层、子类化构建模型和多卡训练等等,希望能帮助到一些感兴趣的同学啦。
文末总结
本文记录了我的参赛过程,没什么创新,就是用了一些 trick。
感谢大赛举办的大牛老师准备数据。
感谢 openbayes 提供算力资源。
参考资料
比赛网址: https://www.datafountain.cn/competitions/423
[2]Kaggle进阶:显著提分trick之指标优化: https://mp.weixin.qq.com/s/jH9grYg-xiuQxMTDq99olg
[3]函数光滑化杂谈:不可导函数的可导逼近: https://spaces.ac.cn/archives/6620#how_to_cite
[4]openbayes: https://openbayes.com/
[5]数据集管理: https://openbayes.com/docs/datasets/#%E6%95%B0%E6%8D%AE%E9%9B%86%E7%9A%84%E5%88%9B%E5%BB%BA%E5%92%8C%E6%95%B0%E6%8D%AE%E7%9A%84%E4%B8%8A%E4%BC%A0
[6]创建算力容器: https://openbayes.com/docs/bayesgear/#%E5%AE%B9%E5%99%A8%E7%9A%84%E6%89%A7%E8%A1%8C%E6%A8%A1%E5%9E%8B
[7]bayes 命令行工具: https://openbayes.com/docs/cli/
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。