一位twitter博主借助DALL·E模型,成功给视频中的人物虚拟换装。
DALL·E 是 OpenAI 推出的文本转图像模型,生成效果奇幻且逼真。升级为 DALL·E 2 后,生成图像具有更高的分辨率和更低的延迟。值得注意的是,DALL·E 2 还添加了一个图像编辑功能,可以修改图像的部分区域,例如在下图中 3 的位置加一只柯基犬:
![]()
现在,twitter 用户 Karen X. Cheng 把 DALL·E 2 的这个编辑功能用在了视频换装上,我们看到视频中的女生在往前走的过程中换了多套衣服,并且丝滑切换,无缝衔接。
![]()
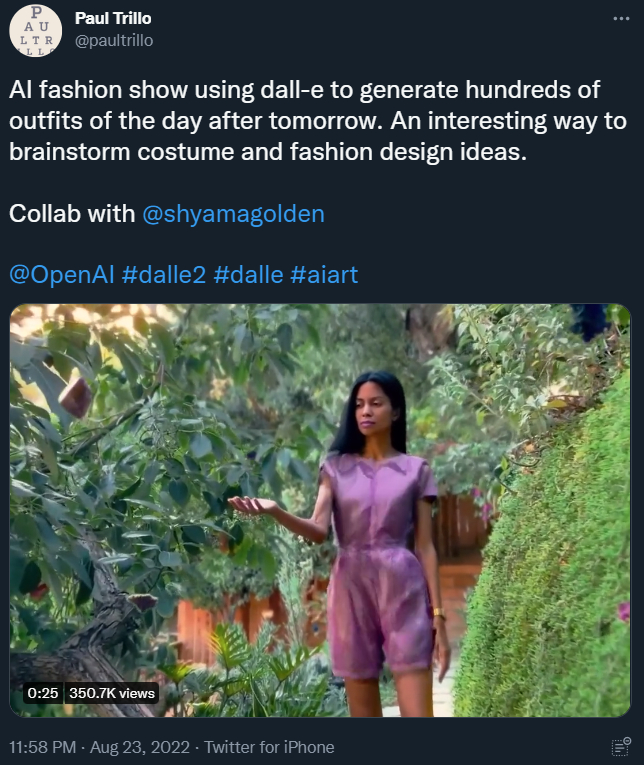
要了解这个视频用到的方法,我们首先要了解一下 DALL·E 生成「数字化」服装的能力。日前,一位名为 Paul Trillo 的 twitter 用户此前展示了他与艺术家 Shyama Golden 合作完成的上百套设计服装。
![]()
相比于大多数用 AI 进行服装设计的研究,DALL·E 2 的优点就是让设计者可以使用文本描述来扩展设计空间,其文本到图像的强大生成能力可以完成很多新奇的设计思路。
而 Karen X. Cheng 发布的换装视频不仅生成了多套服装,还能在人行走运动的过程中丝滑切换,我们来具体看一下她是怎么做的。
视频作者 Karen X. Cheng 首先涂抹掉现有服装的一部分,然后在上面涂上颜色。这一步她也考虑过涂抹掉整个衣服,但生成结果看起来没有那么好,因此选择保留衣服原有的一小部分,这样一来,DALL·E 能够更好地匹配颜色和照明。
如下动图所示,衣服上身被涂抹掉,最后生成了三种不同类型的上衣。
![]()
然后一个关键的难题是 DALL·E 在生成图像方面表现卓越,但在视频上就不太行了,要让 DALL·E 生成的图像实现帧与帧之间的一致性是很困难的。这里 Karen X. Cheng 列举了一些早期试验的失败案例,下面动图在换装时,很明显能看到不同衣服之间存在交叉部分:
![]()
可能有人会问,让 DALL·E 在每一帧中生成不同的衣服,衣服存在交叉部分问题就可以解决了。但作者想要的效果是同一套衣服坚持几帧,以实现较好的展示效果,但这是 DALL·E 目前做不到的。
经过一番实验,作者发现了一个可用的工具 EbSynth,该工具主要是将视频素材转换为各种风格的动画。简单来说,就是从一段视频中选出几张图,然后根据自己的喜好,换成你想要的风格,整个视频就能全部变成你期望的画风了。效果如下所示:
![]()
EbSynth 擅长风格转换,如果把 DALL·E 生成静态图和 EbSynth 转换视频风格的功能结合起来,就能够形成视频中无缝换装的效果:
![]()
最后作者还用到了 DAIN(视频补帧)工具,该工具可以给一些动作场面添加新的帧,让整个视频看起来更加流畅。作者用实验证明了这一点
![]()
这样 Karen X. Cheng 就完成了整个换装视频。有网友表示希望作者开设一门课程,专门介绍这项研究,详细解读一下。
![]()
![]()
看来以后穿搭博主的视频也可以用上 DALL·E 这样的 AI 模型了。
参考链接:https://twitter.com/karenxcheng/status/1564626773001719813
掌握「声纹识别技术」:前20小时交给我,后9980小时……
《声纹识别:从理论到编程实战》中文课上线,由谷歌声纹团队负责人王泉博士主讲。
课程视频内容共 12 小时,着重介绍基于深度学习的声纹识别系统,包括大量学术界与产业界的最新研究成果。
同时课程配有 32 次课后测验、10 次编程练习、10 次大作业,确保课程结束时可以亲自上手从零搭建一个完整的声纹识别系统。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com