这款AI语音模型让派大星承认自己是钢铁侠,造假小扎对口型,火到挤爆服务器|在线可玩
行早 发自 凹非寺
量子位 报道 | 公众号 QbitAI
你敢信,派大星当众宣称自己是钢铁侠,漫威宇宙和比基尼海滩梦幻联动:

I am Iron Man!
这深沉憨厚又有点喜感的嗓音,是派大星本星没错了。
而小扎也疯狂乱入,直接抢了派大星的台词,喊海绵宝宝去抓水母:
hi,spongebob,shall we go to catch jellyfishes?
没错,这又是AI的杰作。
这个名叫FakeYou的语音伪造模型,最近火爆到服务器都被挤挂掉了:
像这位网友一样给马男波杰克写段台词:
suck a *. why are you still here?! did you eat my muffin? you are a worthless piece of no good shit who deserves to die. what are YOUU doing here? what are you doing here.
一键就可以还原他“致郁”的声音:

这“What are youuuu doing”的发音,确实够传神了:

目前上传的人物语音模型已经有很多,包括海绵宝宝、摩根·弗里曼、辛普森一家、马男波杰克、灭霸等等。
demo在线可玩,快来试试~
操作也很简单,只需两步:
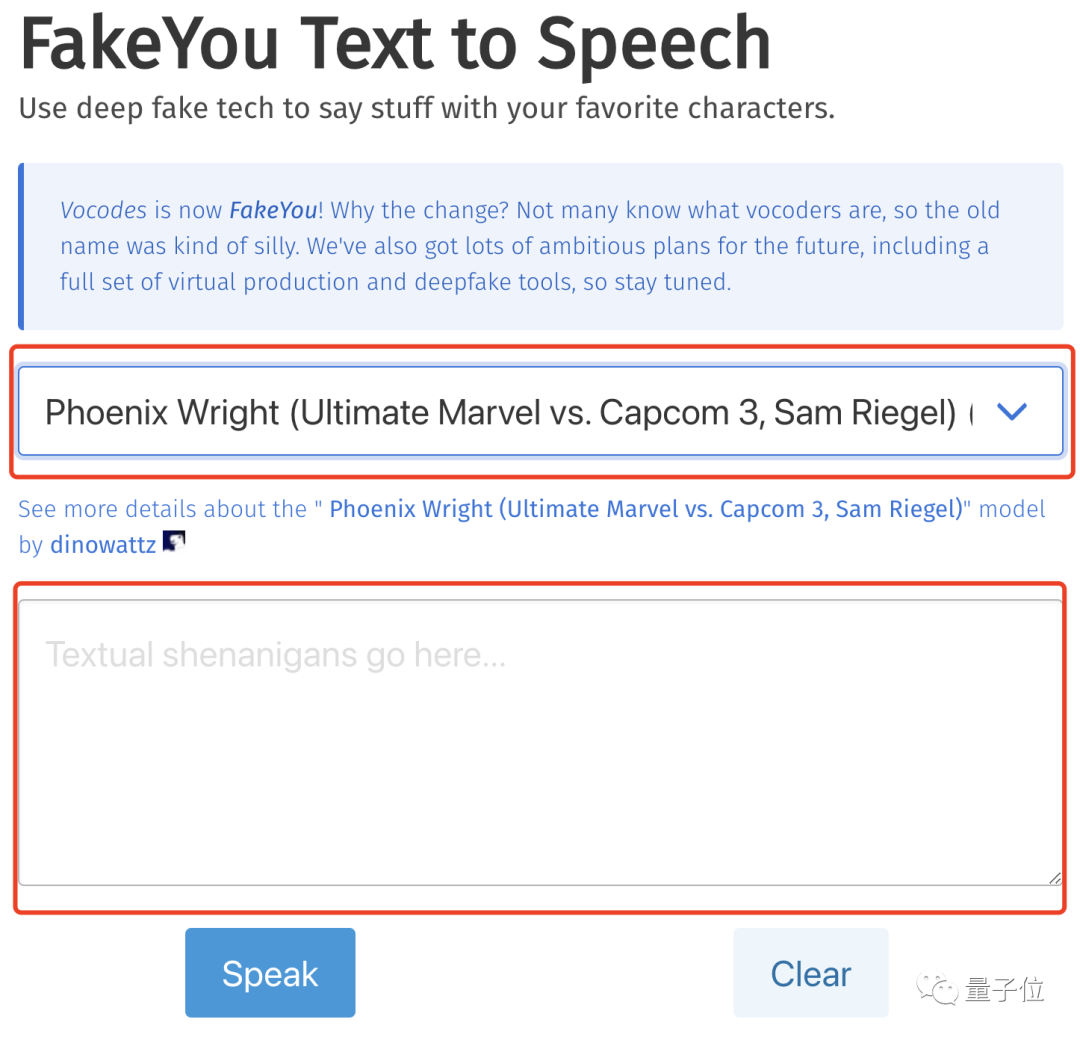
在图中第一个红框中的下拉菜单中选择你喜欢的人物,然后在下面的文本框中输入你希望TA说的话,再点击“Speak”就ok了~
另外,如果你还想让TA对上口型,FakeYou也在线提供了相关功能。选择不同的视频model,上传音频文件就可以了:

FakeYou如何Fake
那FakeYou是怎么实现文本转语音和对口型的呢?
对于文本转语音的任务,FakeYou提到了一系列的模型,主要是其中值得一提的是MelGAN。
它的整体结构也比较简单,工作流是这样的:

首先将输入的文本转化为梅尔声谱图,然后再利用GAN去学习图中的特征,提取声音的信息。
最后再通过傅里叶逆变换还原出原始声波。
而对口型任务使用的则是Wav2Lip模型,与之前的对口型模型的区别在于,Wav2Lip使用预训练的判别器,在检测唇同步时已经相当准确。
并将口型的真值和遮住口型的部分输入网络,用残差网络相连。
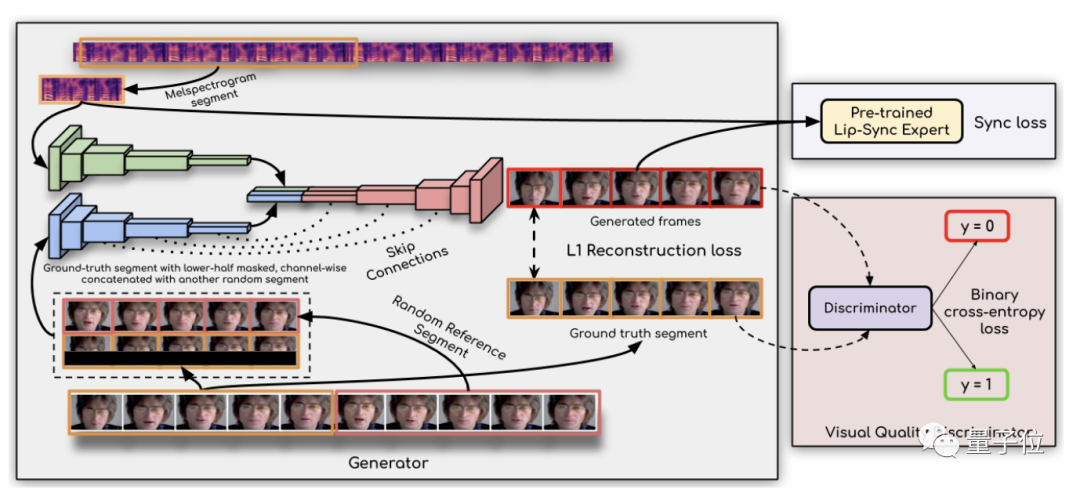
同时还使用了视觉判别器来提高视觉质量和同步精度,进一步提高模型质量。
FakeYou创作者
FakeYou的创作者主要是毕业于南方理工州立大学Brandon Thomas,他是一名来自亚特兰大的工程师。

自这款demo改名为FakeYou之后,就受到很多网友的喜爱。因此有很多社区中的网友也来贡献“声音”。目前FakeYou中已经有几百个用于制作的语音模型。
如果没能找到合适的人物语音模型,也可以自己添加,来丰富FakeYou。
如果你也有想让影视或者动漫中的人物说出你想听的话,可以参考文末的在线demo链接~
参考链接:
[1]https://fakeyou.com/
[2]https://arxiv.org/abs/1910.06711
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~




