本文更新了近三年来人工智能加速器和处理器的研究进展。本文收集和总结了目前已公开公布的具有峰值性能和功耗数字的商用加速器。性能和功率值绘制在散点图上,并再次讨论和分析该图上趋势的多个维度和观察结果。今年的论文中包含了两个基于加速器发布日期的新趋势图,以及一些神经形态的、光子的和基于忆阻的推断加速器的附加趋势。
https://github.com/areuther/ai-accelerators
引言
就像去年一样,初创公司和老牌科技公司发布、发布和部署人工智能(AI)和机器学习(ML)加速器的速度一直很缓慢。这并非没有道理;对于许多已经发布加速器报告的公司来说,他们已经花了三到四年的时间进行研究、分析、设计、验证和验证他们的加速器设计权衡,并构建了为加速器编程的软件堆栈。对于那些发布了后续版本加速器的公司来说,他们报告的开发周期更短了,尽管仍然至少是两三年。这些加速器的重点仍然是加速深度神经网络(DNN)模型,应用空间从极低功耗嵌入式语音识别和图像分类到数据中心规模的训练,而定义市场和应用领域的竞争继续作为现代计算向机器学习解决方案的更大的工业和技术转移的一部分。
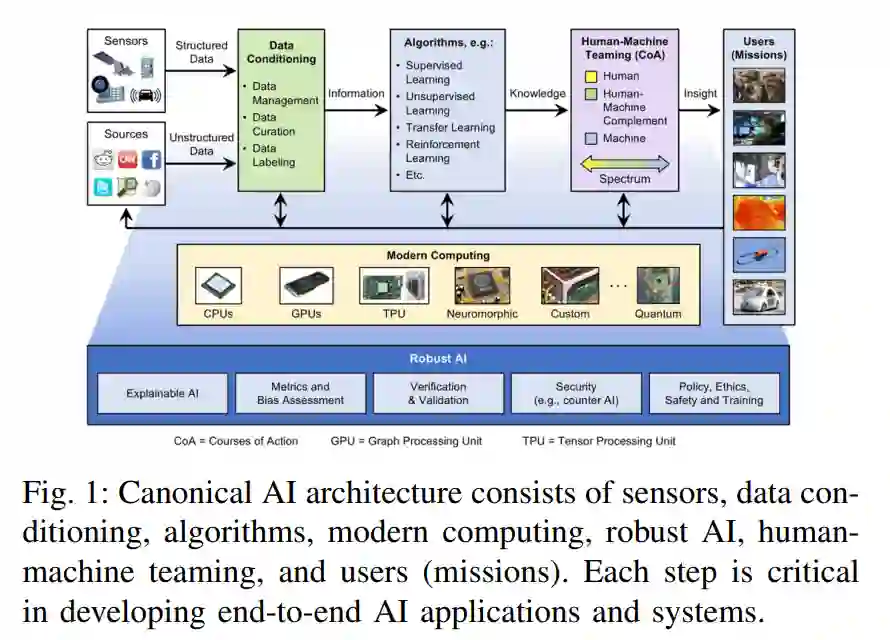
AI生态系统将嵌入式计算(边缘计算)、传统高性能计算(HPC)和高性能数据分析(HPDA)的组件聚集在一起,这些组件必须一起工作,有效地为决策者、作战人员和分析人员提供使用的能力。图1捕捉了这种端到端AI解决方案及其组件的架构概述。在图1的左侧,结构化和非结构化数据源提供了实体和/或现象学的不同视图。这些原始数据产品被送入数据调节步骤,在这个步骤中,它们被融合、聚合、结构化、积累并转换为信息。数据调节步骤生成的信息输入到大量有监督和无监督算法中,如神经网络,这些算法提取模式,预测新事件,填充缺失数据,或在数据集中寻找相似性,从而将输入信息转换为可操作的知识。然后将这些可操作的知识传递给人类,以便在人机协作阶段进行决策过程。人机组合阶段为用户提供了有用的和相关的洞察力,将知识转化为可操作的情报或洞察力。
支撑这个系统的是现代计算系统。摩尔定律的趋势结束了[2],许多相关的定律和趋势也结束了,包括德纳尔比例(功率密度)、时钟频率、核心计数、每时钟周期的指令和每焦耳(库米定律)的指令[3]。借鉴片上系统(SoC)的趋势,首先出现在汽车应用、机器人和智能手机上,通过为常用的操作内核、方法或功能开发和集成加速器,技术进步和创新仍在不断进步。这些加速器的设计在性能和功能灵活性之间达到了不同的平衡。这包括深度机器学习处理器和加速器[4]-[8]的创新爆发。在这一系列的调查论文中,我们将探讨这些技术的相对好处,因为它们对于将AI应用到具有重大限制(如尺寸、重量和功率)的领域(无论是在嵌入式应用程序还是在数据中心)具有特别重要的意义。
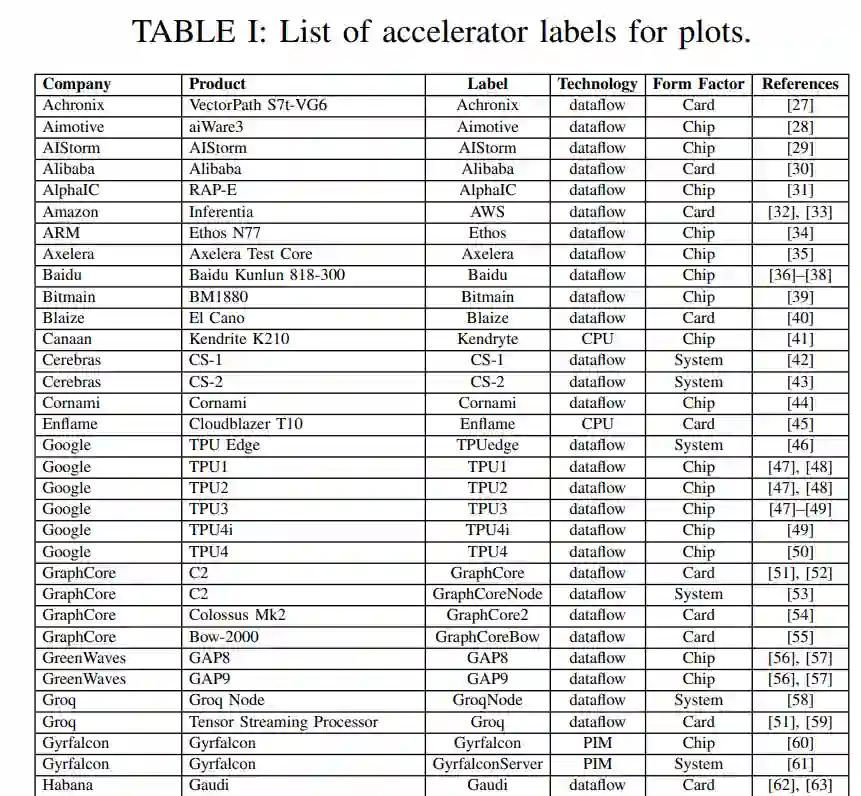
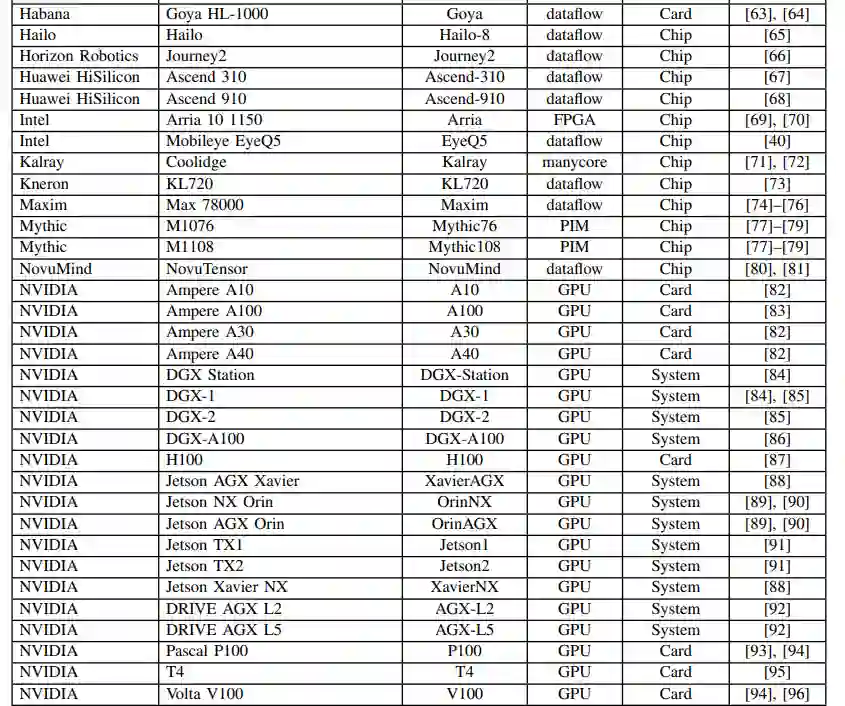
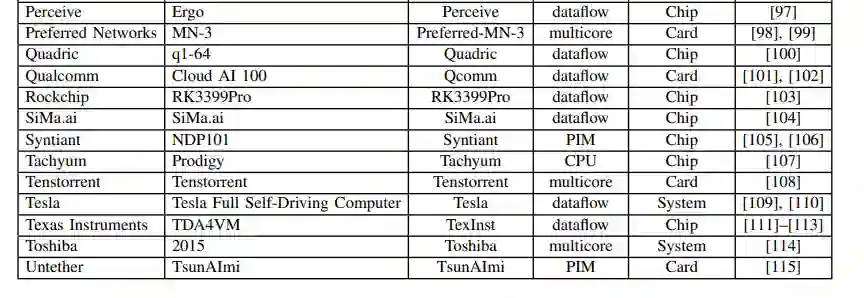
本文是对过去三年IEEE-HPEC论文[9]-[11]的更新。与过去几年一样,本文继续去年的重点关注加速器和处理器,它们面向深度神经网络(DNN)和卷积神经网络(CNNs),因为它们的计算量相当大。由于多种原因,包括国防和国家安全AI/ML边缘应用严重依赖于推理,本调查将重点放在用于推理的加速器和处理器上。我们将考虑加速器支持的所有数值精度类型,但对其中大多数来说,它们的最佳推理性能是int8或fp16/bf16 (IEEE 16位浮点或谷歌的16位脑浮点)。
有许多综述[13]-[24]和其他论文,涵盖了AI加速器的各个方面。例如,这项多年调查的第一篇论文包括某些AI模型的FPGA的峰值性能;然而,上述的一些调查深入地涵盖了FPGA,因此它们不再包括在本次综述中。这项多年的综述工作和本文的重点是收集一个全面的人工智能加速器的列表,其计算能力,电力效率,并最终在嵌入式和数据中心应用中使用加速器的计算效率。随着这一重点,本文主要比较神经网络加速器是有用的政府和工业传感器和数据处理应用。在前几年的论文中包含的一些加速器和处理器在今年的调查中被排除在外。它们被丢弃了,因为它们被同一家公司的新加速器超越了,它们不再被提供,或者它们不再与主题相关。
处理器概述
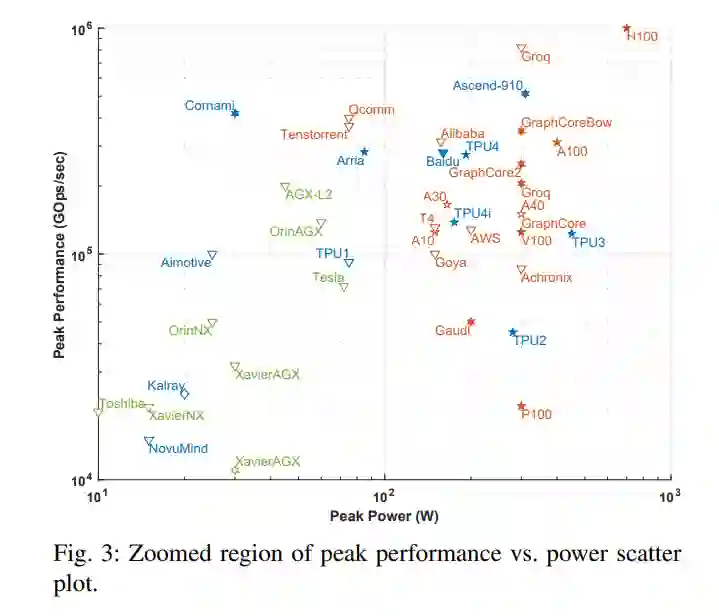
人工智能的许多最新进展至少可以部分归功于计算硬件[6]、[7]、[25]、[26]的进步,使计算量大的机器学习算法成为可能,特别是dnn。这项调研从公开的材料中收集性能和电力信息,包括研究论文、技术贸易出版物、公司基准等。虽然有很多途径可以获取公司和初创公司(包括那些处于静默期的公司)的信息,但这些信息有意被排除在本次调研之外;当这些数据公开时,将包括在本次调研中。这些公共数据的关键指标如图2所示,它绘制了最近的处理器能力(截至2022年7月),映射出峰值性能与功耗的关系。虚线框描述了图3中放大并绘制的非常密集的区域。
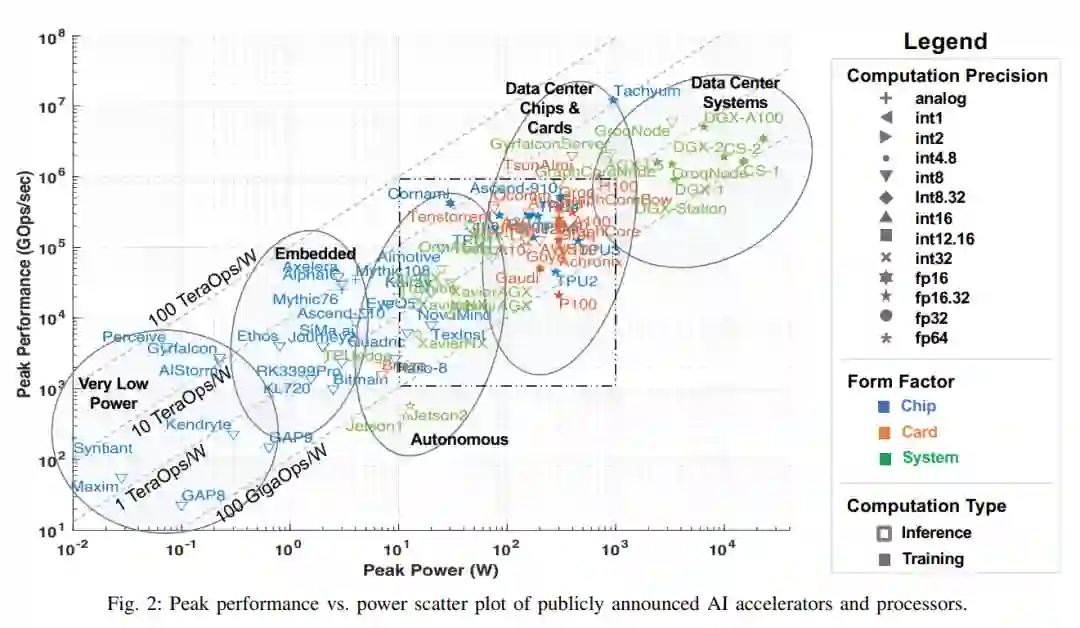
观察与趋势
-
Int8继续是嵌入式、自主和数据中心推理应用的默认数值精度。对于大多数具有合理数量的类的AI/ML应用程序,这种精度是足够的。但是,有些加速器也使用fp16和/或bf16进行推断。为了训练,变成了整数表示。
-
在这类和嵌入式类别中,发布片上系统(SoC)解决方案是非常常见的,通常包括低功耗CPU内核、音频和视频模拟-数字转换器(adc)、加密引擎、网络接口等。soc的这些附加特性不会改变峰值性能指标,但它们对报告的芯片峰值功率有直接影响,所以在比较它们时请记住这一点。
-
嵌入式部分的变化不大,这可能意味着计算性能和峰值功率足以满足该领域的应用程序类型。
-
在自治和数据中心芯片和卡片领域,密度变得非常拥挤,这需要在图3中进行放大。在过去的几年里,包括德州仪器在内的几家嵌入式计算微电子公司已经发布了AI加速器,而NVIDIA也发布并宣布了几个更强大的汽车和机器人应用系统。在数据中心卡中,为了突破PCIe v4 300W的功率限制,PCIe v5规格备受期待。
-
最后,高端训练系统不仅发布了令人印象深刻的性能数据,而且这些公司还宣布了高度可扩展的互联技术,可以将数千张卡片连接在一起。这对于像Cerebras、GraphCore、Groq、Tesla Dojo和SambaNova这样的数据流加速器尤其重要,这些加速器是显式/静态编程的,或者是“放置和路由”到计算硬件上的。它使这些加速器能够适应非常大的模型,如transformer[129]。