技术动态 | 揭开知识库问答 KB-QA 的面纱 8 · 深度学习下篇(二)
作者,四川大学博士生,刘大一恒。本文已经获得 ChatbotMagazine 公众号授权。
内容速览
☛ 引入注意力机制的KB-QA
☛ 深度学习篇总结
在上一篇 技术动态 | 揭开知识库问答 KB-QA 的面纱 7 · 深度学习下篇(一)中我们介绍了关于如何将记忆网络应用到KB-QA中的文章。今天我们将给大家介绍另一篇使用深度学习另一种经典模型进行KB-QA的文章,带注意力机制的循环神经网络(Recurrent Neural Networks with Attention Mechanism)。这也是深度学习用于自然语言处理领域(Deep Learning for NLP)中相当火热的方法,就让我们一起来看看如何将它应用到KB-QA中吧。
引入注意力机制的KB-QA

文章QuestionAnswering over Knowledge Base with Neural Attention Combining Global KnowledgeInformation由中科院自动化所刘康老师等人在2016年发表在arxiv上,是一篇相对较新的文章。该文章和我在深度学习上篇分享的文章类似,也是使用深度学习对向量建模方法进行提升,不同于之前使用CNN提取问句特征,而该文章使用双向LSTM并结合问题引入注意力机制提取问句特征,在WebQuestion上取得了42.6的F1-Score,击败了之前的Multi-Column CNN。
深度学习提升向量建模方法的大体框架都很接近:根据问题确定主题词,根据主题词确定候选答案,通过候选答案和问题的分布式表达相似度得分确定最终答案。而方法的核心在于学习问题和候选答案的分布式表达,其实相关的方法都是在这两个部分做文章。这篇文章的想法在于,对于不同的答案,我们关注问题的焦点是不同的,我们根据候选答案的信息,来引入注意力机制,对同一个问题提取出不同的分布式表达。
比如对于问题 "who is the president of France?",其中之一的答案是实体“Francois Holland”,我们通过知识库可以知道Francois Holland 是一个总统,因此我们会更加关注问句中的 “president” 和 “France” 单词,而根据Francois Holland的类型person,我们会更关注问句中的疑问词who。
(如果你之前没有接触过注意力机制也没有关系,可以直接往下看,也可以看看关于注意力机制最经典的文章,Yoshua Bengio等人在2015年ICLR发表的NeuralMachine Translation by Jointly Learning to Align and Translate,该文章提出的encoder-decoder with attention mechanism模型几乎可以横扫大部分的NLP问题)
该方法的整体框架如下图所示:
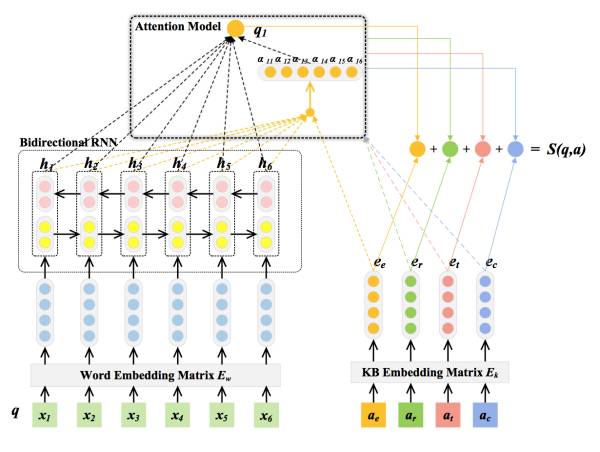
具体来说,可分为以下三个步骤:
1.将候选答案转化为分布式表达
我们从多个方面考虑答案的特征:答案实体、答案上下文环境(知识库中所有与答案实体直接相连的实体)、答案关系(答案与问题主题词之间的实体关系)、答案类型。每一种特征都可以用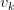
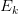
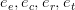
2.将自然语言问题转化为分布式表达
将问句中的每一个单词经过Embedding矩阵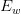
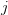
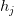
3.在得分函数中引入注意力机制
我们希望我们问句的分布式表达对于四种不同的答案特征有不同的表达(根据答案的特征对于问题有不同的关注点),第
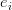
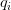
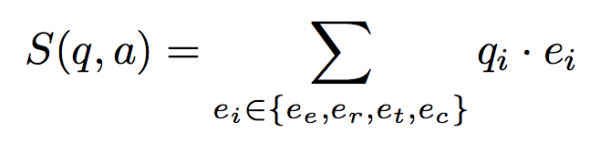
对于一般的LSTM,我们通常将最后一个时刻的输出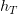
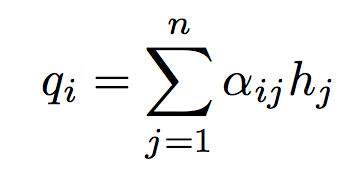
其中的权重系数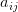
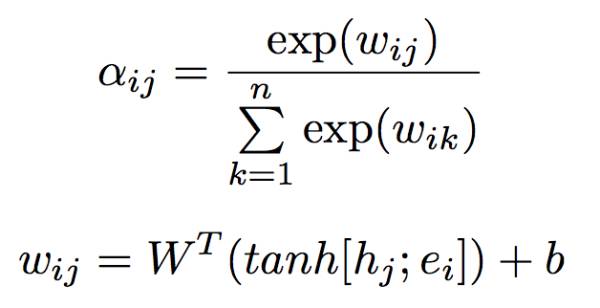
4.OOV问题
特别一提的是,在测试的过程中,我们的候选答案可能从未在训练集中出现过,因此它对应的分布式表达是没有被我们的模型训练过的(这个问题称为the problem of out of vocabulary, OOV,之前的文章很少有考虑过这个问题的)。为了解决该问题,作者利用TransE对知识库进行训练,训练实体和实体关系对应的Embedding矩阵
(关于TransE:TransE是知识图谱补全的经典方法,它借鉴了word-embedding的思想,能够将知识库中的实体和实体关系用分布式向量表达。其主要思想是对于一个知识三元组(s,r,o),我们希望主语实体的分布式表达e(s)加上关系实体的分布式表达e(r)能够尽量接近宾语实体的分布式表达e(o),因此我们可以构建类似的margin-rank损失函数通过正样本和采样负样本进行训练。TransE提出之后还出现了大量的改进算法,诸如TransH、TransR、TransG、TranSparse、TransD等等。之后如果有机会我会专门写文章或专栏对知识图谱补全相关的方法进行介绍)
在实验环节,作者对模型进行了分析,分析使用注意力机制(记作ATT)、利用知识库全局信息使用TransE训练实体embedding(记作GKI)以及bi-LSTM对性能的影响,在WebQuestion测试集上F1-Score的结果如下:
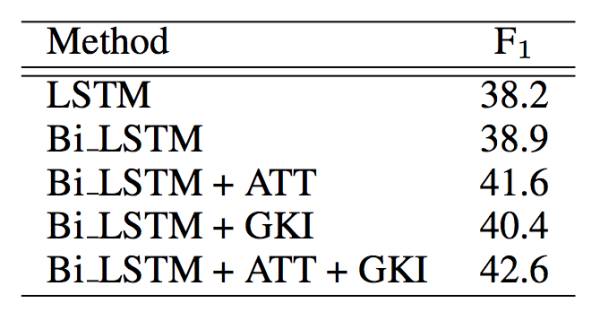
可以看出ATT和GKI这两个机制都对模型性能有一定的提升,最终模型取得了42.6的F1-score,击败了几乎所有的深度学习提升向量建模的方法(记忆网络是42.2而Multi-column CNN是41.3)。当然这个方法在WebQuestion上的F1-Score距离我们在深度学习中篇所提到的语义解析方法(F1-Score 52.5)还有一定的距离,但论文中也提到相比该方法设置大量的人工特征(很多特征是对训练集观察得到的),这个方法具有更强的适应性和可扩展性。(深度学习中篇详情请关注公众号ChatbotMagazine,翻查公众号历史记录。)
注意力机制还有另外一个好处,那就是可视化,通过可视化每个单词的权重,可以得到一些可解释性,如下图:
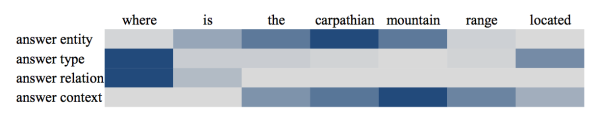
图中颜色越深表示权重越大,我们可以通过该图看出一些符合人类直觉的解释(如对应答案的类别,我们会更加关注疑问词等等)。
深度学习篇小结
我们在KB-QA深度学习篇(一)、(二)中,为大家介绍了使用CNN、RNN、记忆网络、双向LSTM、注意力机制等深度学习的火热方法与KB-QA结合的几篇经典文章。我们可以看到深度学习具有传统方法所不具有的高效性、可扩展性、适应性、鲁棒性等优点。我相信,未来几年,KB-QA已离不开深度学习。(KB-QA系列文章详情请翻查公众号历史记录。)
此外,个人认为使用更加复杂的记忆网络是未来深度学习解决KB-QA的一个很有前景的途径。记忆网络的框架给了我们很多的提升空间:引入更多的技巧,使用更合理的模型作为记忆网络的组件,在记忆选择中引入推理机制,注意力机制和遗忘机制,将多源的知识库存入记忆等等。
- End -
ChatbotMagazine 是智言科技(深圳)有限公司旗下的一个技术分享栏目,智言科技是一家专注于基于知识图谱问答系统研发的 AI 公司。欢迎扫描二维码关注 ChatbotMagazine 公众号。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




