全面解析Inception Score原理及其局限性

作者丨尹相楠
学校丨里昂中央理工博士在读
研究方向丨人脸识别、对抗生成网络
本文主要基于这篇文章:A Note on the Inception Score,属于读书笔记的性质,为了增加可读性,也便于将来复习,在原文的基础上增加了一些细节。


很多关于 GAN 生成图片的论文中,作者评价其模型表现的一项重要指标是 Inception Score(下文简称 IS)。其名字中 Inception 来源于 Google 的 Inception Net,因为计算这个 score 需要用到 Inception Net-V3(第三个版本的 Inception Net)。
Inception Net 是图片分类网络,在 ImageNet 数据库上训练,ImageNet 数据库共有 1.2M 个 RGB 图片,分为 1000 类。Inception Score 只是把 Inception Net-V3 作为一个工具,理解 Inception Score 不需要知道 Inception Net-V3 的细节,各种深度学习框架中都已经包含了预训练好的 Inception Net-V3 了,直接拿来用就好了。
基本原理
众所周知,评价一个生成模型,我们需要考验它两方面性能:1. 生成的图片是否清晰;2. 生成的图片是否多样。生成的图片不够清晰,显然说明生成模型表现欠佳;生成的图片够清晰了,我们还要看是不是能生成足够多样的图片,有些生成模型只能生成有限的几种清晰图片,陷入了所谓 mode collapse,也不是好的模型。
Inception Score 是这样考虑这两个方面的:
1. 清晰度:把生成的图片 x 输入 Inception V3 中,将输出 1000 维的向量 y ,向量的每个维度的值对应图片属于某类的概率。对于一个清晰的图片,它属于某一类的概率应该非常大,而属于其它类的概率应该很小(这个假设本身是有问题的,有可能有些图片很清晰,但是具体属于哪个类却是模棱两可的)。用专业术语说, p(y|x) 的熵应该很小(熵代表混乱度,均匀分布的混乱度最大,熵最大)。
2. 多样性:如果一个模型能生成足够多样的图片,那么它生成的图片在各个类别中的分布应该是平均的,假设生成了 10000 张图片,那么最理想的情况是,1000 类中每类生成了 10 张。转换成术语,就是生成图片在所有类别概率的边缘分布 p(y) 熵很大(均匀分布)。
具体计算时,可以先用生成器生成 N 张图片,然后用公式 (1) 的经验分布来代替:
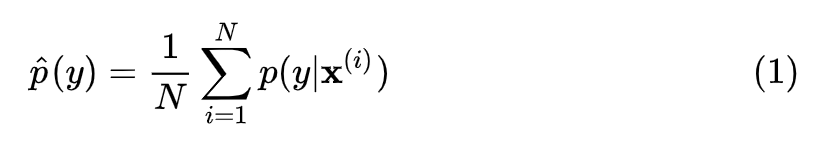
综合上面两方面,Inception Score 的公式为:
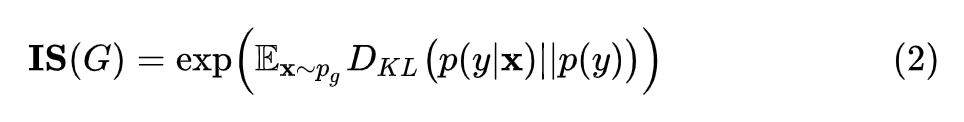
exp:仅仅是为了好看,没有具体含义。
x~Pg :表示从生成器中生图片。
p(y|x) :把生成的图片 x 输入到 Inception V3,得到一个 1000 维的向量 y ,也就是该图片属于各个类别的概率分布。IS 提出者的假设是,对于清晰的生成图片,这个向量的某个维度值格外大,而其余的维度值格外小(也就是概率密度图十分尖)。
p(y) :N 个生成的图片(N 通常取 5000),每个生成图片都输入到 Inception V3 中,各自得到一个自己的概率分布向量,把这些向量求一个平均,得到生成器生成的图片全体在所有类别上的边缘分布,见公式 (1)。
:对 p(y|x) 和 p(y) 求 KL 散度。KL 散度离散形式的公式如下:
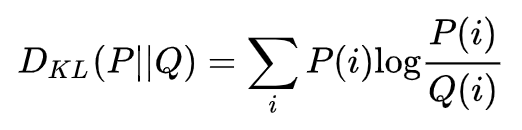
KL 散度用以衡量两个概率分布的距离,它是非负的,值越大说明这两个概率分布越不像。但这个距离不是对称的,观察公式, P(i) 很大 Q(i) 很小的地方对 KL 距离贡献很大,而 P(i) 很小 Q(i) 很大的地方对 KL 距离的贡献很小。
我们预期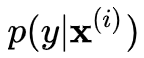
综合起来,只要 p(y|x) 和 p(y) 的距离足够大,就能证明这个生成模型足够好。因为前者是一个很尖锐的分布,后者是一个均匀分布,这俩距离本就应该很大。
公式 (2) 很不直观,在实际操作中可以改成如下形式:
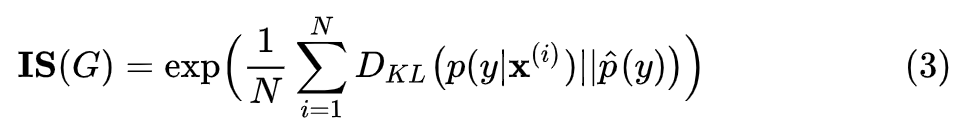
实际操作中,先用生成的大量样本代入公式 (1),求出,然后再对每个样本求出
的 KL 散度,最后求平均,再算一下指数即可。
Inception Score 的 pytorch 版本代码可以参考下面的链接,十分清晰易懂:
https://github.com/sbarratt/inception-score-pytorch
深入理解Inception Score
我们对公式 (2) 取对数刨除无用的 exp,并作简单的推导:
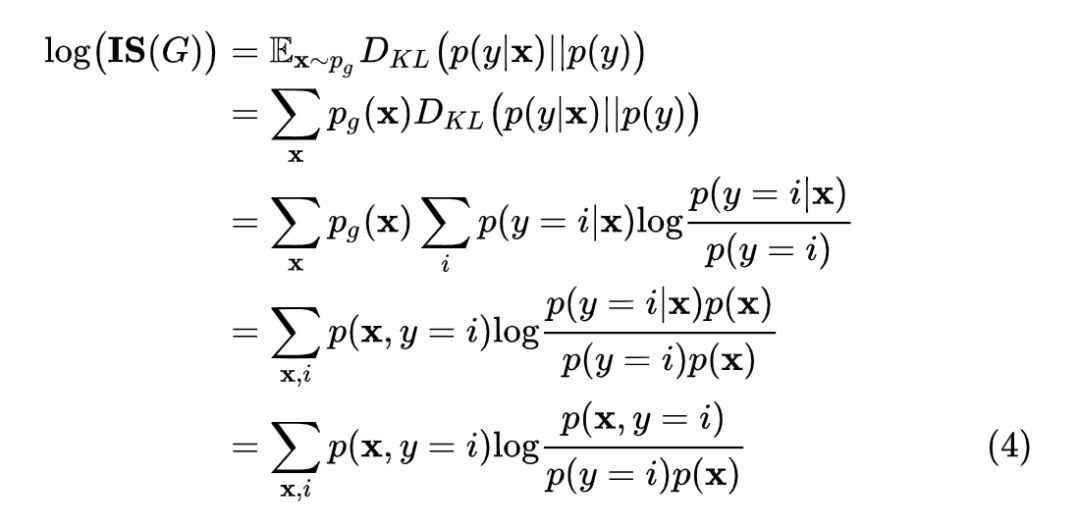
可以发现,公式 (4) 的结尾正是互信息的定义式,即:

注意,互信息是对称的,即 I(y;x)=I(x;y) 。而互信息的 Wikipedia 页面,给出了它和熵之间的关系推导。
熵,条件熵,信息增益和互信息
熵是衡量随机变量不确定性的量,对随机变量 x,其信息熵的公式为:
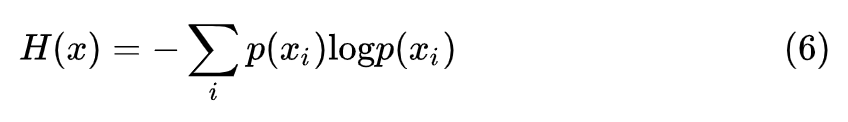
条件熵是衡量在给定条件下,随机变量不确定性的量。对随机变量 x,y 条件熵的公式为:
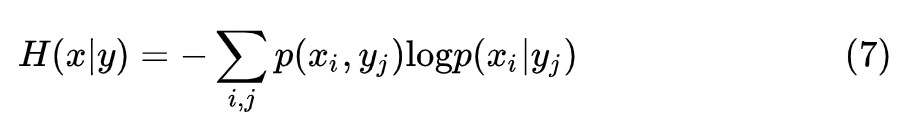
关于这两个公式的直观解释,请参阅数学之美第 6 章 [1]。
而对于互信息,我们可以作如下推导:
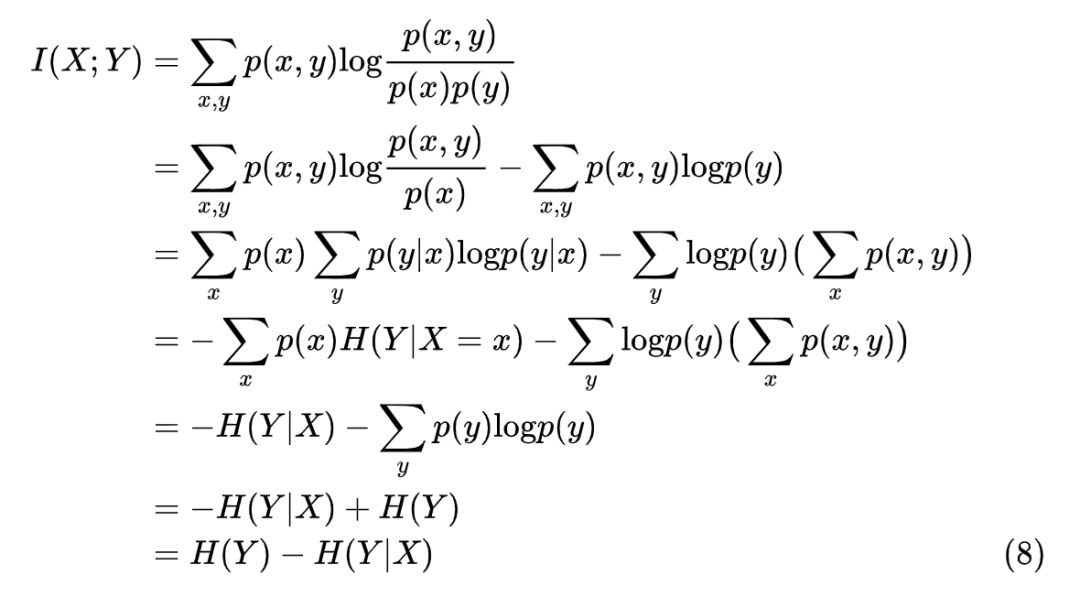
从公式 (8) 中发现,对于随机变量 y,其本来的不确定性是 H(y),而给定了条件 x 后,y 的不确定性变为了 H(y|x)。因此,互信息为:给定某个条件后,随机变量不确定性的减少程度,因此也叫信息增益。而这个指标同时反映的是两个变量的相关程度。
互信息和信息增益是等价的,一个侧重表达两个随机变量的相关程度,一个侧重给定某个条件后,随机变量不确定性的减少程度。
PS:协方差也可以用于表示两个随机变量的相关性,但是只能表示两个变量之间的线性相关性,但协方差的好处是不需要知道变量的概率分布函数,而这对互信息是必须的。具体见这个链接 [2]。
有了上面的推导,再代回到公式 (5):
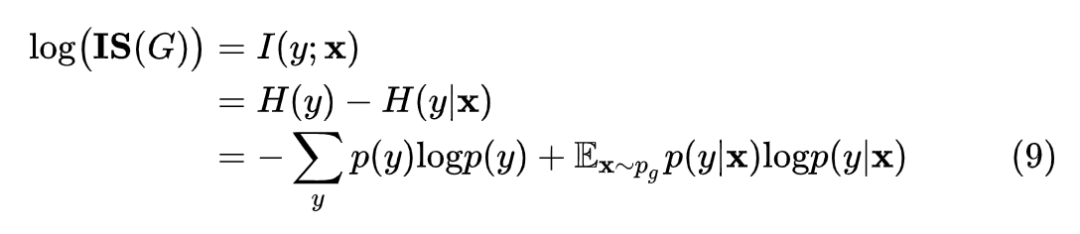
我们根据公式 (9) 发现,Inception Score 的真实意义是:生成的所有样本在各类别的分布函数的熵,与每个样本在各类别可能性的分布的熵(的期望)之差。第一项越大,说明生成的样本在各类上分布越平均,第二项越小,说明生成的样本属于某个类别的可能性越大,说明这个样本越清晰。
Inception Score的局限性
在 A Note on the Inception Score 中,作者首先举了一个一维的例子,用以说明 Inception Score 并不能反映生成模型的性能。
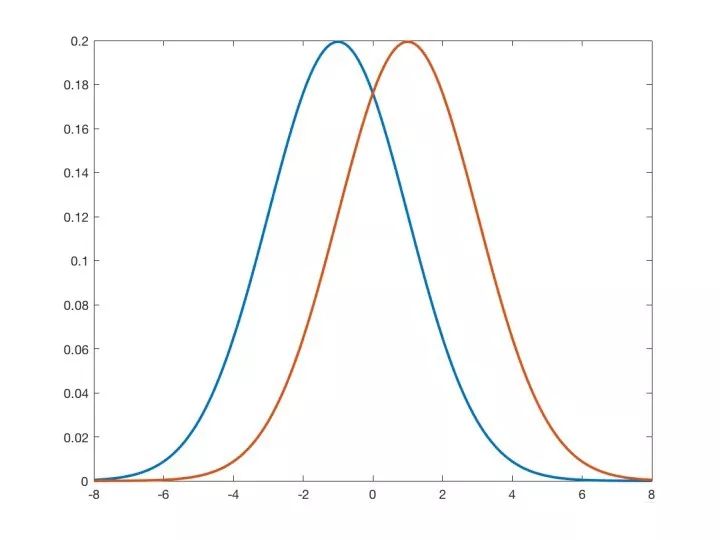
▲ 图1
假设真实数据以 1/2 的概率分别从两个正态分布 N(-1, 2) 和 N(1,2) 中采样(如图 1),各自对应的类别分别为 0 和 1。那么最优贝叶斯分类器为:
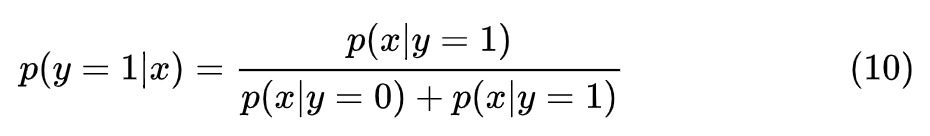
公式 10 的图像如图 2。即给出一个 x,分别算一下它在左正态分布和右正态分布的概率,代入上式,大于 0.5 表示来自右边的正态分布,小于 0.5 表示来自左边的正态分布。注意在 x=0 时,它来自左右两个分布的概率均为 0.5。
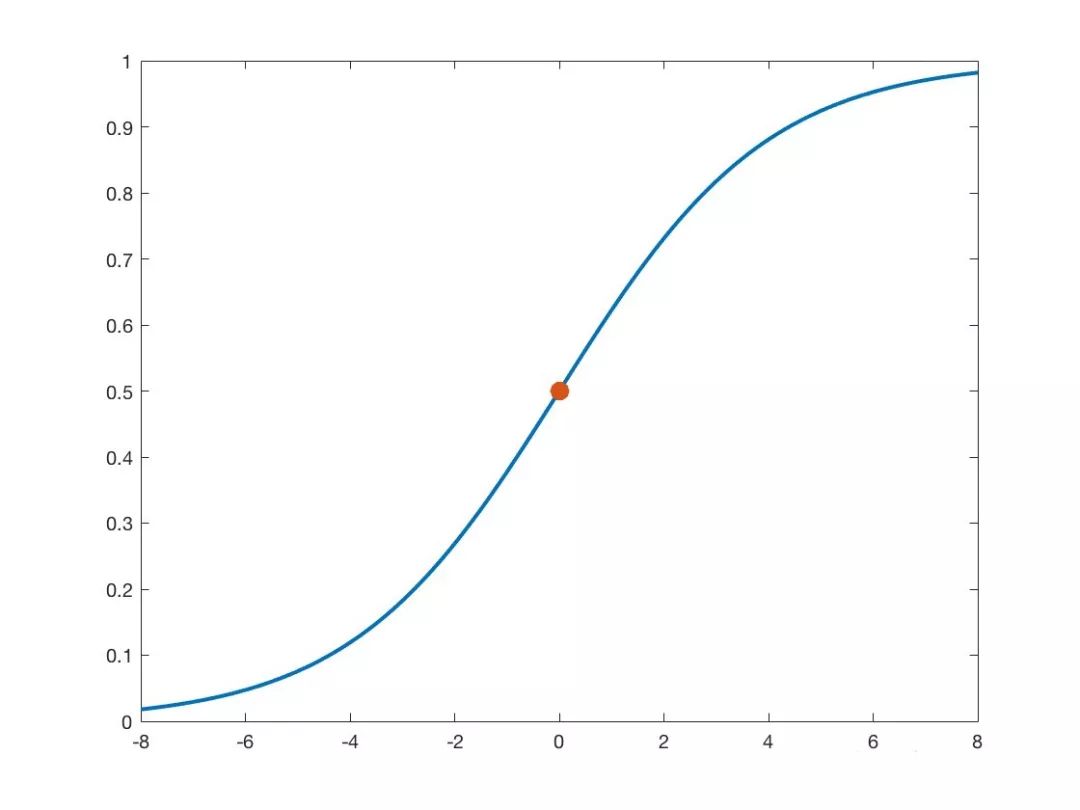
▲ 图2
而根据 Inception score 的计算公式 (9),我们可以设计这样的生成器:以相同概率随机生成 -∞ 和 +∞。为了方便阅读,这里重新复制一遍公式 (9):
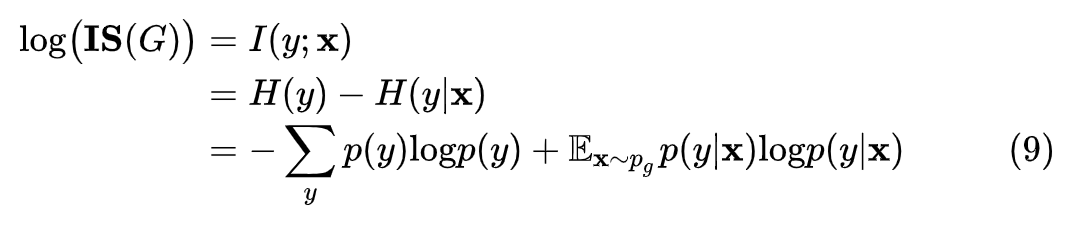
根据图 2 中最优判别器的图像,可以知道:
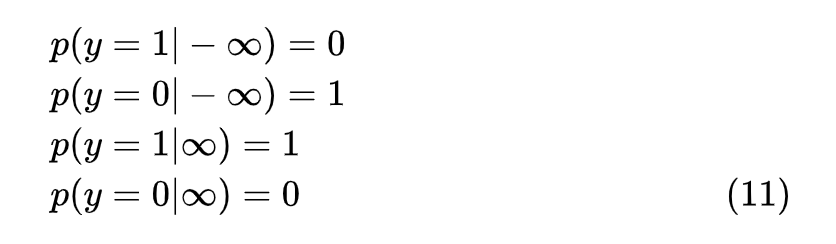
(11) 代入 (9) 的第二项,可以得到 H(y|x)=0,而生成 -∞ 和 +∞ 的概率都是 1/2,故 H(y)=log2。因此,Inception Score 可以取到最大值 2。
除此之外,还有很多分布都可以得到很高的 Inception Score,例如均匀分布 U(-100,100),正态分布 N(0, 20) ,因为它们都可以得到 H(y)=log2(关于坐标原点对称,所以生成两类的概率相同),同时得到一个很小的 H(y|x)=0(最优判别器下,大于 0 的数对应的概率都很大,小于 0 的数,概率都很小)。反而真正的分布,左右两个正态分布对应的 Inception Score 小于前面这些分布。
作者总结,Inception Score 主要有两个问题:
Inception Score 自身的问题
错误的使用场景
Inception Score自身的问题
1. Inception Score 对神经网络内部权重十分敏感。
作者利用 TensorFlow, Torch 和 Keras 等不同框架下预训练的 Inception V2 和 Inception V3 ,计算同一个数据库(50 k CIFAR-10 training images 和 50k ImageNet validation images)的 Inception Score。
发现尽管不同框架预训练的网络达到同样的分类精度,但由于其内部权重微小的不同,导致了 Inception Score 很大的变化,在 CIFAR-10 上 IV3 (inception v3) Torch 和 IV3 Keras 算出的 Inception Score 相差了 11.5% ,在 ImageNet 上,IV3 Torch 和 IV3 Keras 算出的 IS 相差 3.5%,这些差异,足以涵盖某些所谓 state-of-the-art 的模型所作出的提升。
2. 计算 Inception Score 的方式不对。
通常计算 Inception Score 时,会生成 50000 个图片,然后把它分成 10 份,每份 5000 个,分别代入公式 (3) 计算 10 次 Inception Score,再计算均值和方差,作为最终的衡量指标(均值+-方差)。
但是 5000 个样本往往不足以得到准确的边缘分布,尤其是像 ImageNet 这种包含 1000 个类的数据集,仅仅 5000 个样本是不够的。作者通过实验证明,把同一个数据集分成不同的份数,会影响最后的 Inception Score。因此,作者建议把 50000 个样本放到一起,来确定边缘分布
。
同时,作者建议去掉 Inception Score 提出者基于审美原因加进公式的 exp,根据上文,去掉后可以直接解释为互信息。改进后的 Inception Score 公式为:
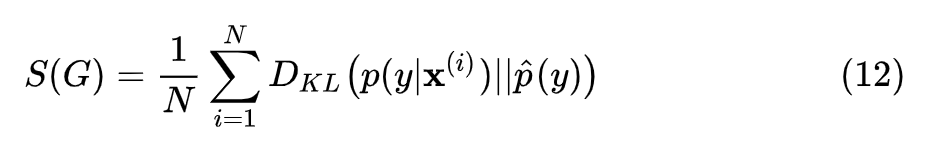
按照作者的改进,就不会出现把数据集划分为不同份数,计算的 Inception Score 不一致的现象了。对于方差,可以通过计算每一个生成数据的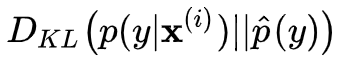
错误的使用场景
1. 分类模型和生成模型在不同的数据集上训练。
由于 Inception V3 是在 ImageNet 上训练的,用 Inception V3 时,应该保证生成模型也在 ImageNet 上训练并生成 ImageNet 相似的图片,而不是把什么生成模型生成的图片(卧室,花,人脸)都往 Inception V3 中套,那种做法没有任何意义。
Inception Score 基于两个假设:
Inception V3 可以准确估计 p(y),即样本在所有类别上的边缘分布;
Inception V3 可以准确估计 p(y|x) ,从而计算出条件熵,用条件熵反映图片的真实程度。
对于假设 1,作者计算了 CIFAR-10 的边缘分布,取了排名前 10 的预测类。把这 10 类和 CIFAR-10 的 10 类相比较,发现,它们并没有对应关系。再一次说明了生成模型的训练数据需要和 Inception Net 或者别的什么分类网络的训练数据一致。不能在一个数据集上训练分类模型,用来评估另一个数据集上训练的生成模型。
对于假设 2,Inception 网络通过 p(y|x) 计算出条件熵,条件熵越低表示生成的图片越真实,这也是有问题的。作者计算了 CIFAR 10 训练集的条件熵是 4.664 bit,而在随机噪声图片上,条件熵是 6.512 bit,仅仅比真实训练集图片高了一点点。
而在 ImageNet 的 validation set上,Inception net 算出的条件熵是 1.97 bit,也就是说 CIFAR 训练数据比起 ImageNet 更接近随机噪声,这显然是不科学的,因为 CIFAR 数据再不济也是真实图片,应该和 ImageNet 的条件熵更接近才对。再一次说明了,不能在一个数据集上训练分类模型,用来评估另一个数据集上训练的生成模型。
2. 优化 Inception Score (不直接地&隐式地)。
Inception Score 只能是粗糙的指导,如果直接优化这个 Inception Score,会导致生成对抗样本(只会刷分,其实并不真实)。但同时也应该注意到,间接地优化这个分数,同样会导致生成对抗样本,例如用这个指标来确定是否停止训练,调整超参数,甚至调整网络架构。
作者在附录中提出了一种可以刷 Inception Score 的方法:把生成样本输入分类模型中,用梯度下降来修改输入的样本,让它在某一类的概率达到非常大,这样,条件熵就降下来了,同时让不同样本优化不同的类,循环遍历所有的类,这样就能保证边缘分布是均匀分布,即生成的图片把每个类都均匀覆盖了。但是,这会导致生成毫无意义的图片。
3. 没有反映过拟合。
根据 Inception Score 的计算原理,我们可以发现:如果神经网络记住了所有的训练集图片,然后随机输出,那么它会得到一个很高的 Inception Score。但是这种生成模型是没有意义的。
因此在用 Inception Score 评估生成模型的性能时,应该加上别的指标,证明模型没有过拟合,即模型输出的图片和训练集中任何图片都不同,单纯用 Inception Score 评估性能是不全面的。
总结
本文全面讲解了 Inception Score 的原理和它存在的一些问题:
IS大,不一定生成的图片就真实;
分类模型参数的轻微变动将影响 IS;
使用 IS 时,分类模型和生成模型应该在同一个数据集上训练;
通常计算 IS 的方法是有漏洞的:估计
的样本数据量太小,导致同一堆数据,分割的份数不同算出的 IS 不同;
以 IS 为优化目标会导致产生对抗样本;
IS 无法反映生成模型过拟合情况。
综上,IS 是一个浑身硬伤的评价指标,能不用还是不要用了……
经常与 IS 并列的还有 Fréchet Inception Distance,关于它的简介请移步本人的另一篇文章 [3]。限于水平,这篇文章会比较水,没能对 Fréchet Distance 做出理论推导或者直观解释,只是引用了一下公式,但从公式中仍然可以看出,它比 IS 更加有道理一点。
相关链接
[1] https://github.com/Tongzhenguo/ebooks/blob/master/数学之美.pdf
[2] https://stats.stackexchange.com/questions/81659/mutual-information-versus-correlation
[3] https://zhuanlan.zhihu.com/p/54213305

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐


