
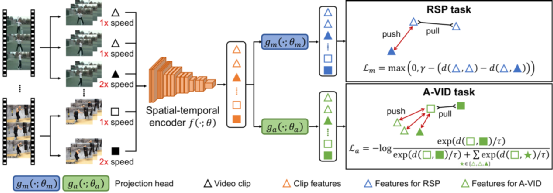
我们研究了无监督的视频表示学习,该学习旨在仅从未标记的视频中学习运动和外观特征,可以将其重用于下游任务,例如动作识别。然而,由于以下原因,这项任务极具挑战性:1)视频中的高度时空信息;2)缺少用于训练的标记数据。与静态图像的表示学习不同,难以构造合适的自我监督任务来很好地对运动和外观特征进行建模。最近,已经进行了几种尝试以通过视频回放速度预测来学习视频表示。但是,为视频获取精确的速度标签并非易事。更关键的是,学习的模型可能倾向于集中于运动模式,因此可能无法很好地学习外观特征。在本文中,我们观察到相对回放速度与运动模式更加一致,从而为表示学习提供了更加有效和稳定的监督。因此,我们提出了一种感知播放速度并利用两个视频片段之间的相对速度作为标签的新方法。这样,我们就能很好地感知速度并学习更好的运动功能。此外,为了确保学习外观特征,我们进一步提出了以外观为中心的任务,其中我们强制执行模型以感知两个视频剪辑之间的外观差异。我们表明,优化两个任务可以共同持续改善两个下游任务(即动作识别和视频检索)的性能。值得注意的是,对于UCF101数据集上的动作识别,在不使用标记数据进行预训练的情况下,我们达到了93.7%的准确性,这优于ImageNet监督的预训练模型。
https://arxiv.org/abs/2011.07949
成为VIP会员查看完整内容
相关内容

Arxiv
6+阅读 · 2020年10月12日
Arxiv
4+阅读 · 2018年9月23日
相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2020年10月12日
Arxiv
4+阅读 · 2018年9月23日