“只需看两次”——对卫星图像进行快速目标识别的新方法
编者按:CV中的目标物体识别进步非常快,但是想对卫星图像进行目标识别仍然困难重重。美国研究者就提出了一种方法——You Only Look Twice,能清晰地看到卫星图像中的汽车、飞机场上的飞机及建筑物,并开放了代码(见文末)。以下是论智带来的编译。
在大范围图像中对小目标进行检测是卫星图像分析的主要问题。虽然深度学习方法为基于地面的目标检测提供了许多方法,将这种技术转化为图片是非常重要的步骤。其中最大的挑战就是所有像素的数量和每张图片的地理内容:一张DigitalGlobe(美国的一家商业空间图像和地理空间内容提供商,并操控数台遥感航天器)卫星图片涵盖了64m2以上的土地,有超过2.5亿个像素。另一个挑战是,我们想要观察的对象物体非常小(经常在10像素左右),这对传统的计算机视觉技术来说是一项很复杂的任务。为了解决这个问题,我们提出了一个流程,即“You Only Look Twice”(只需看两眼),它能以每秒大于0.5平方米的速度对卫星图像进行评估扫描,可以快速地在不同范围内对目标物体进行检测,同时只需较少的训练数据。我们在图片的原始分辨率下对图片进行评估,同时生成的车辆定位F1分数大于0.8。之后我们又系统地测试了降低分辨率和目标物体尺寸后的效果,最后得出当尺寸降至5像素时,系统的识别率仍然很高。
遇到的挑战
深度学习方法在传统目标检测上的应用是非常重要的。而卫星图像的特殊性使能够解决空间前景内容、能进行旋转变换以及大范围搜索的算法成为必要的。除了安装细节,算法还必须满足以下四个条件:
小空间范围(small spatial extent):与ImageNet数据集中的清晰大图不同,卫星图像中的目标物体通常很小,并且分布较密集。在卫星成像领域,分辨率通常被定义为“地面采样距离(GSD)”,它描述了一个像素的实际距离。商业用途的图像尺寸在DigitalGlobe的30厘米GSD到卫星成像的3—4米GSD左右。这意味着,即使在最高的分辨率下,汽车之类的小目标也只有15像素左右大小。
完全的旋转不变性(rotation invariance):从空中看到的物体可能会有各种朝向。比如,船行进的方向可能有许多中,但是像ImageNet中的大树却总是垂直的。
训练样本频率(training example frequency):训练数据相对不足。
极高分辨率(ultra high resolution):输入的图像非常大,常常有百万像素。所以简单地对输入图像尺寸进行下采样不合适。

DigitalGlobe在巴拿马运河附近拍摄的8×8km(约16000×16000像素)的图像,GSD为50cm。红框表示416×416像素大小的区域
You Only Look Twice
为了解决模型无法检测像素过小的目标、难以生成全新比例的图像等限制,我们提出了一种经过优化的为卫星图像目标检测框架:You Only Look Twice(YOLT)。我们扩展了Darknet神经网络框架,同时更新了一些C函数库一共地理空间图像分析,并且整合了外部Python库。我们选择Python用户社群来进行预处理和后处理。在更新完C代码和进行预处理和后处理之间,参与者无需对C有深入了解。
网络结构
为了减少模型的粗糙度同时增强检测密集物体时的精确度,我们所使用的是一个具有22层的网络,并且以16为系数进行降采样。所以输入一张416×416像素的图片会生成一个26×26的网格。该网络受30层的YOLO启发,经过优化后专为检测小型密集对象。密集网格对散布型场景(如机场)可能不太重要,但是对高密度场景(如停车场)非常重要。

空中成像的目标物体检测对标准网络架构的挑战。两张图片来自统一数据集。左图中的模型将4000×4000像素的测试图像降采样到416×416,图中共有1142辆车,没有一辆被识别出来。右图中的模型同样是416×416,漏报率过多是由于车辆密度太大,13×13的网格无法将它们分辨出来
为了提高模型识别小物体的准确度,我们还加入了一个穿透层,与最后的52×52图层连接起来成为最后的卷积层,可以让探测器获得扩展后的特征向量更细微的特征。
测试过程
在测试时,我们将不同尺寸的测试图片分割成可操作的小图,并将每个小图在训练过的模型上进行实验。如下图所示:

测试过程是从左图移动到右图,重叠部分在右下图中用红色表示。重叠部分的非极大抑制对于改善小图边缘的目标检测是非常有必要的
许多卫星成像的性能都依赖于其内部拍摄全局大图的能力。所以,小型图像芯片远不如由卫星平台自己拍摄的大型图像。物体检测的最后一步就是将成百上千张测试芯片连接到最后的图像层中。
目标检测结果
最初,我们想只训练一个分类器,让其能够辨认交通工具、基础设施等许多种类的物体。但是结果并不理想,在对机场的识别中,我们发现这样的结果:

这一通用模型产生了较差的结果。检测到的飞机被红框圈起来,可以看到还有几架被遗漏。另外蓝框内是被模型误解的“跑道”
要解决这一问题,我们试着利用卫星成像中的规模信息,运行两个不同的分类器:一个用于识别交通工具和建筑,另一个用来检查机场。第一种分类器的尺寸为200m,第二种为2500m。我们将测试照片分成合适尺寸的小图,然后将每张小图输入到分类器中。最终将多个分类器的结果结合成最后一张图像,我们发现检测率在0.3和0.4之间的生成的F1分数最高。以下是目标检测器在各个类别下的表现:
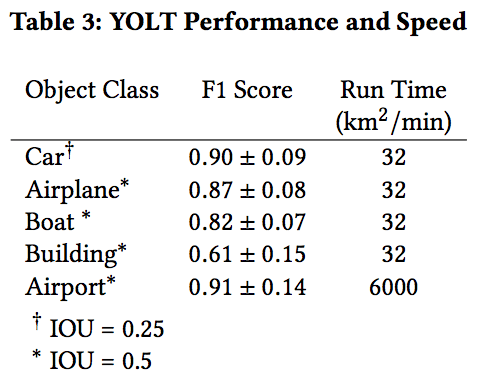
可以看到,YOLT在机场、飞机和船几个类别中表现得很好
细节表现分析
接着,我们在COWC数据集上测试了YOLT对汽车的检测结果,下图是在每个场景中模型的F1分数以及对汽车数量计算的精确度:
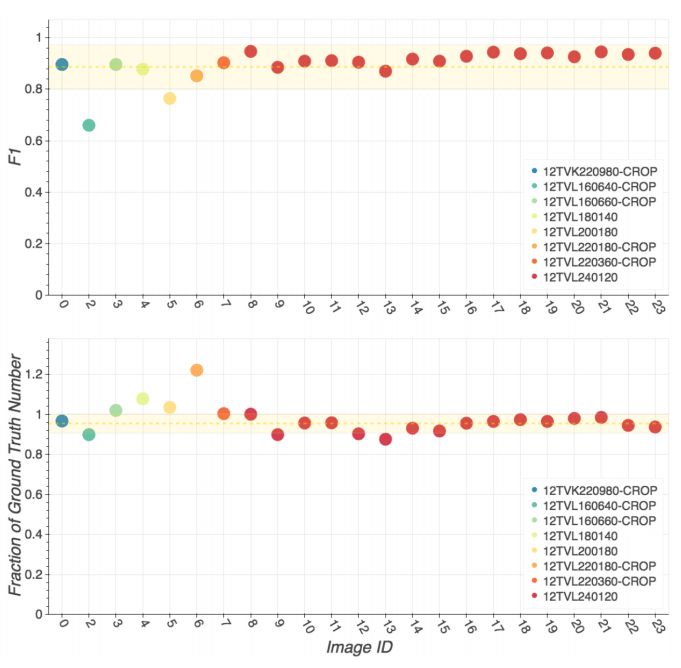
上面的图示COWC中每个测试场景的F1分数,下面的图是将检测次数作为标准数值的一部分
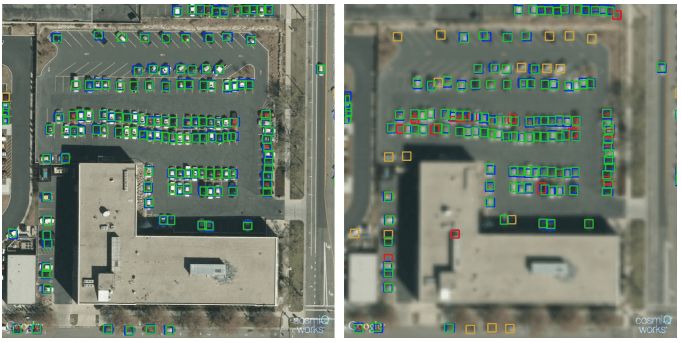
不同分辨率下的目标检测。左图的GSD为15cm,F1分数为0.94。右图的GSD为90cm,F1分数为0.84
结语
目标检测算法在定位类似ImageNet数据集中的图片上取得了巨大进步,但是这类算法通常不适合用于卫星图片中的目标检测。为了解决这一限制,我们提出了一种完全卷积的神经网络模型(YOLT),它能快速定位卫星图片中的汽车、建筑和机场。最终的F1分数从0.6到0.9不等,取决于不同的检测种类。代码目前已在GitHub上开放,地址:github.com/CosmiQ/yolt
论文地址:arxiv.org/pdf/1805.09512.pdf






