近期必读的五篇AAAI 2021【对比学习】相关论文和代码
1. A Simple and Effective Self-Supervised Contrastive Learning Framework for Aspect Detection
作者:Tian Shi, Liuqing Li, Ping Wang, Chandan K. Reddy
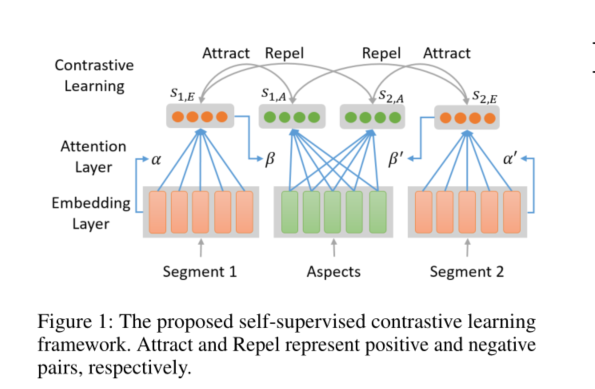
摘要:无监督aspect检测(Unsupervised aspect detection, UAD)的目的是自动提取可解释的aspect,并从在线评论中识别aspect特定的片段(例如句子)。但是,最近的基于深度学习的主题模型,特别是基于aspect的自动编码器,遇到了一些问题,例如提取嘈杂的aspect以及将模型发现的aspect映射到感兴趣的aspect的情况很差。为了解决这些挑战,在本文中,我们首先提出一种自监督的对比学习框架和一种基于注意力的模型,该模型具有用于UAD任务的新型平滑自注意(smooth self-attention, SSA)模块,以便学习aspect和review segments的更好表示。其次,我们引入了高分辨率选择性映射(high-resolution selective mapping, HRSMap)方法,以将模型发现的aspect有效地分配给感兴趣的aspect。我们还建议使用知识蒸馏技术来进一步提高aspect检测性能。在公开可用的基准用户评论数据集上,我们的方法优于几种最近的非监督和弱监督方法。实验中aspect的解释结果表明,提取的aspect有意义,覆盖范围广,并且可以轻松映射到感兴趣的aspect。消融研究和注意力权重可视化还证明了SSA和知识蒸馏方法的有效性。
网址:
https://www.zhuanzhi.ai/paper/413f80976f8dfccbb2f263f7e9e4ca1b
2. Contrastive and Generative Graph Convolutional Networks for Graph-based Semi-Supervised Learning
作者:Sheng Wan, Shirui Pan, Jian Yang, Chen Gong
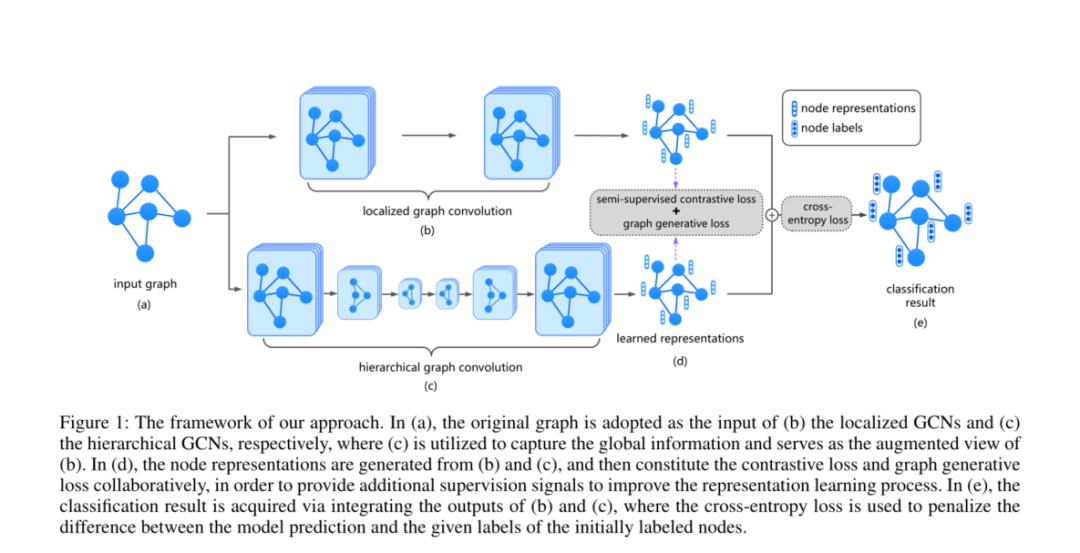
摘要:基于图的半监督学习(SSL)旨在通过图将少量标记数据的标签转移到其余大量未标记数据。作为最流行的基于图的SSL方法之一,最近提出的图卷积网络(GCN)通过将神经网络的声音表达能力与图结构相结合而取得了显着进步。然而,现有的基于图的方法不能直接解决SSL的核心问题,即缺乏监督,因此它们的性能仍然非常有限。为了解决这个问题,本文提出了一种新颖的基于GCN的SSL算法,通过利用数据相似性和图结构来丰富监督信号。首先,通过设计一个半监督的对比损失,可以通过最大化相同数据的不同视图或相同类数据之间的一致性来生成改进的节点表示。因此,丰富的未标记数据和稀缺而有价值的标记数据可以共同提供丰富的监督信息,以学习判别性节点表示形式,有助于改善后续的分类结果。其次,通过使用与输入特征有关的图生成损失,将数据特征与输入图形拓扑之间的潜在确定性关系提取为SSL的补充监督信号。与其他最新方法相比,在各种实际数据集上进行的大量实验结果坚定地证明了我们算法的有效性。
网址:
https://www.zhuanzhi.ai/paper/5412a20822b5c15ed13a6975d5f69421
3. Contrastive Transformation for Self-supervised Correspondence Learning
作者:Ning Wang, Wengang Zhou, Houqiang Li
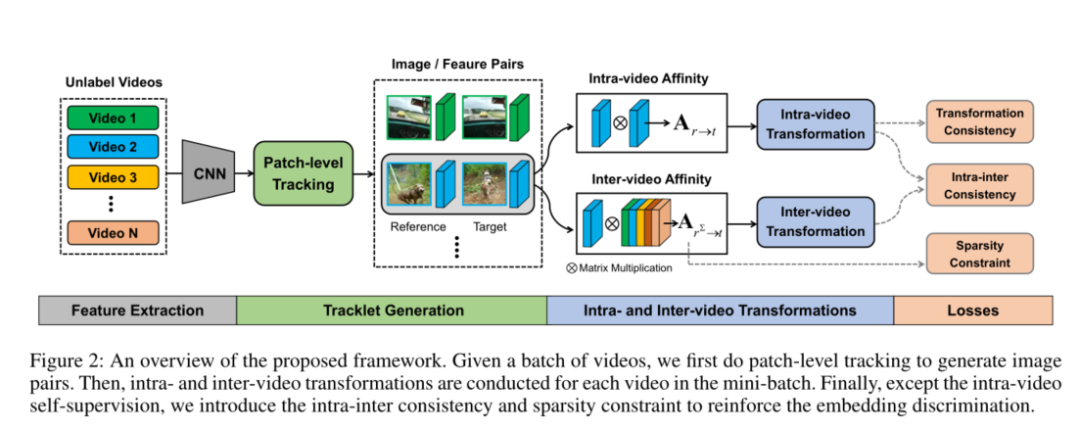
摘要:在本文中,我们专注于使用未标记的视频来进行视觉对应性自监督学习。我们的方法同时考虑了视频内和视频间表示关联,以进行可靠的对应估计。视频内学习通过帧对相似性在单个视频内的各个帧之间转换图像内容。为了获得实例级分离的判别表示,我们在视频内分析的基础上,构建了视频间亲和性,以促进跨不同视频的对比转换。通过强制视频内和视频间级别之间的转换一致性,可以很好地保留细粒度的对应关系,并有效地增强实例级的特征辨别力。我们的简单框架优于包括视频目标跟踪(VOT),视频目标分割(VOS),姿势关键点跟踪等在内的可视任务的自监督通信方法。值得一提的是,与完全监督的亲和力表示(例如ResNet)并执行与针对特定任务(例如VOT和VOS)设计的最新有监督算法相比,我们的方法也具有相应的竞争力。
网址:
https://www.zhuanzhi.ai/paper/449c58a142a4110ee7f089d12b51fdac
4. Gradient Regularized Contrastive Learning for Continual Domain Adaptation
作者:Peng Su, Shixiang Tang, Peng Gao, Di Qiu, Ni Zhao, Xiaogang Wang
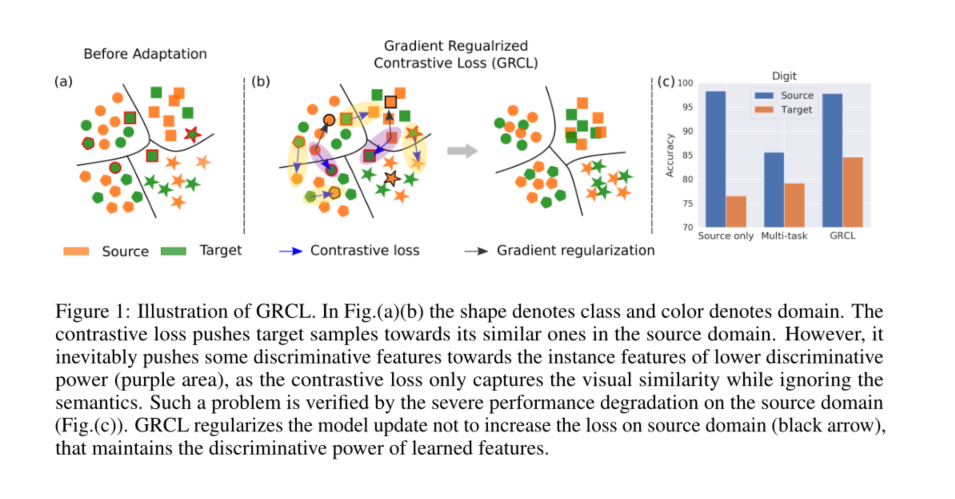
摘要:人类可以利用学习经验来快速适应环境变化。但是,适应动态环境的能力较弱仍然是AI模型面临的主要挑战。为了更好地理解此问题,我们研究了连续域自适应问题,其中模型带有标记的源域和一系列未标记的目标域。这个问题有两个主要障碍:领域转移和灾难性遗忘。在这项工作中,我们提出了梯度正则化对比学习(Gradient Regularized Contrastive Learnin)来解决上述障碍。在我们方法的核心中,梯度正则化扮演两个关键角色:(1)强制进行对比损失的梯度,不增加源域上的监督训练损失,从而保持学习特征的判别力;(2)规范了新域上的梯度更新,而不会增加旧目标域上的分类损失,这使模型能够适应传入的目标域,同时保留先前观察到的域的性能。因此,我们的方法可以通过标记的源域和未标记的目标域共同学习语义上的区别和领域不变的特征。与最新技术相比,在Digits,DomainNet和Office-Caltech基准测试中的实验证明了我们方法的强大性能。
网址:
https://arxiv.org/abs/2007.12942
5. Self-supervised Pre-training and Contrastive Representation Learning for Multiple-choice Video QA
作者:Seonhoon Kim, Seohyeong Jeong, Eunbyul Kim, Inho Kang, Nojun Kwak
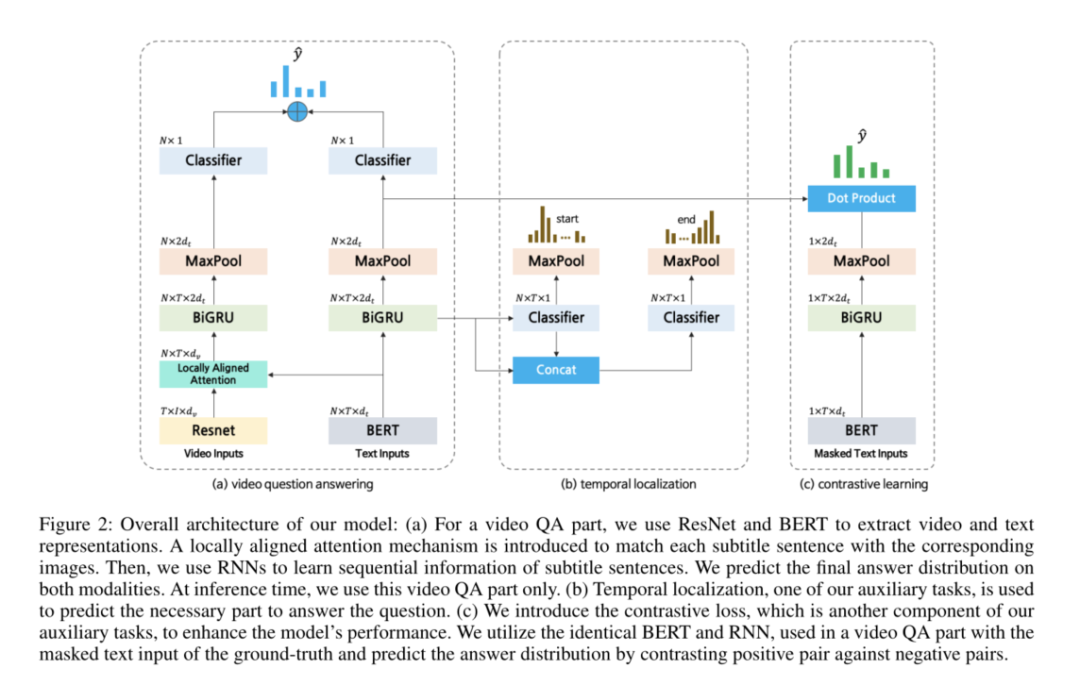
摘要:视频问答(Video QA)要求对视频和语言模态有深入的了解,才能回答给定的问题。在本文中,我们提出了一种新的针对多选视频问答的训练方案,该方案以自监督的预训练阶段和主要阶段的监督对比学习作为辅助学习。在自监督的预训练阶段,我们将预测正确答案的原始问题格式转换为预测相关问题的格式,以提供具有更广泛上下文输入的模型,而无需任何其他数据集或注释。为了在主要阶段进行对比学习,我们在与真实答案相对应的输入中添加了掩码噪声,并将真实答案的原始输入视为正样本,而将其余答案视为负样本。通过将正样本映射到更接近被屏蔽的输入,我们表明模型性能得到了改善。我们进一步采用局部对齐的注意力来更有效地专注于与给定的对应字幕句子特别相关的视频帧。我们在与多选Video QA相关的基准数据集TVQA,TVQA +和DramaQA上评估了我们提出的模型。实验结果表明,我们的模型在所有数据集上均达到了最先进的性能。我们还将通过进一步的分析来验证我们的方法。
网址:
https://www.zhuanzhi.ai/paper/9f96c0b41030c4317a9576a7a3c0a53b
请关注专知公众号(点击上方蓝色专知关注)
后台回复“AAAI2021CL” 就可以获取《5篇顶会AAAI 2021 对比学习(Contrastive Learning)相关论文》的Pdf下载链接~






